您现在的位置是:首页 >学无止境 >大数据分析案例-基于XGBoost算法构造房屋租赁价格评估模型网站首页学无止境
大数据分析案例-基于XGBoost算法构造房屋租赁价格评估模型

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
喜欢大数据分析项目的小伙伴,希望可以多多支持该系列的其他文章
1.项目背景
对于没有经验的人,租房平台是一个短期房屋和公寓出租的互联网市场。例如,它使您可以在外出时将房屋出租一周,或将备用卧室出租给旅行者。该公司本身已从2008年成立时迅速成长为估值接近400亿美元的公司,目前的市值超过全球任何一家连锁酒店。
租房平台房东面临的挑战之一是确定最佳的每晚租金价格。在许多地区,潜在的租户都会看到很多房源,并且可以按价格,卧室数量,房间类型等条件进行过滤。由于租房平台是一个市场,房东每晚收取的费用与市场的动态密切相关。
假设我们想在租房平台上租一个房间。作为房东,如果我们试图以高于市场价格的价格收费,那么租房者将选择更多负担得起的替代品,而我们不会赚钱。另一方面,如果我们将每晚租金设置得太低,我们将错过潜在的收入。
我们如何才能达到中间的“最佳位置”?我们可以使用的一种策略是:
1)找到一些与我们相似的列表,
2)平均与我们最相似的商品的标价,
3)并将我们的挂牌价设为此计算出的平均价格。
但是,一遍又一遍地手动执行操作将非常耗时,在大数据时代,我们将使用机器学习模型,以自动执行此过程,而不是手动进行操作。
2.项目简介
2.1项目说明
本项目通过使用机器学习算法来构建房屋租赁价格评估模型,避免了以往只能靠专业人员过往经验来评估的误差,用算法模型来评估结果更为科学可靠,同时通过本次实验,找出影响房屋价格的因素。
2.2数据说明
本数据来源于链家网,数据集为江西省南昌市各地区的房屋租赁价格数据,具体此段信息如下:
| 变量名称 | 含义 |
| name | 房屋信息标签 |
| address | 地区 |
| price | 价格 |
| lease method | 租赁类型 |
| layout | 几室几厅 |
| derection | 房屋装修情况 |
| area | 房屋面积 |
| orientation | 房屋朝向 |
| floor | 楼层 |
| elevator | 是否有电梯 |
| water | 用水情况 |
| power | 用电情况 |
| gas | 是否有天然气 |
2.3技术工具
Python版本:3.9
代码编辑器:jupyter notebook
3.算法原理
XGBoost(Extreme Gradient Boosting)是一种基于决策树集成的机器学习算法,它使用梯度提升方法(Gradient Boosting)来训练决策树。XGBoost的主要优点是速度快,准确性高,可扩展性好,因此在机器学习和数据科学领域中非常流行。
下面是XGBoost的算法原理:
1.损失函数:
XGBoost的目标是最小化损失函数,其中损失函数由两个部分组成:正则化项和目标函数。正则化项用于防止过拟合,目标函数用于衡量模型预测结果与实际结果之间的误差。常见的目标函数包括平方误差损失函数、Logistic损失函数等。
2.决策树:
XGBoost使用决策树作为基本模型,而不是使用传统的线性模型。决策树由节点和叶子节点组成,每个节点表示一个特征,每个叶子节点表示一个类别或一个实数值。决策树是通过递归地将数据集分割为越来越小的子集来构建的。
3.梯度提升:
XGBoost使用梯度提升方法训练决策树模型。梯度提升是一种迭代的方法,每次迭代都训练一个新的决策树模型,它的预测结果与前面所有模型的预测结果相加得到最终的预测结果。在每一次迭代中,XGBoost计算残差的梯度,并用残差更新目标函数。然后,XGBoost使用这个更新后的目标函数训练一个新的决策树模型。
4.正则化:
XGBoost通过正则化方法防止过拟合。常用的正则化方法包括L1正则化和L2正则化。L1正则化可以使得一些决策树的权重为0,从而剪枝一些不必要的决策树。L2正则化可以使得决策树的权重变得更加平滑,从而提高模型的泛化能力。
5.优化算法:
XGBoost使用了一些优化算法来提高训练速度和准确性。其中最重要的优化算法是加权梯度下降算法(Weighted Gradient Descent)。加权梯度下降算法可以根据损失函数的梯度和二阶导数来自适应地调整学习率,从而提高模型的准确性。
XGBoost算法的具体步骤如下:
-
初始化模型。设定迭代次数,学习率和决策树的深度等超参数。
-
对于每一次迭代:
a. 计算负梯度。根据当前模型在训练数据上的表现,计算每个样本的负梯度,用于构建下一棵决策树。
b. 构建决策树。根据负梯度的大小,构建一棵新的决策树。
c. 计算叶子节点权重。对于每个叶子节点,计算它的权重,以最小化损失函数。
d. 更新模型。将新的决策树加入模型,并根据学习率更新模型参数。
-
返回最终的模型。
XGBoost的优点在于它的泛化能力强,可以处理高维度、稀疏数据,并且有很好的防止过拟合的机制。同时,它的速度也非常快,可以处理大规模的数据集。因此,XGBoost已经成为了机器学习领域中应用最广泛的算法之一。
4.项目实施步骤
4.1理解数据
首先使用pandas导入租房数据集并查看前五行
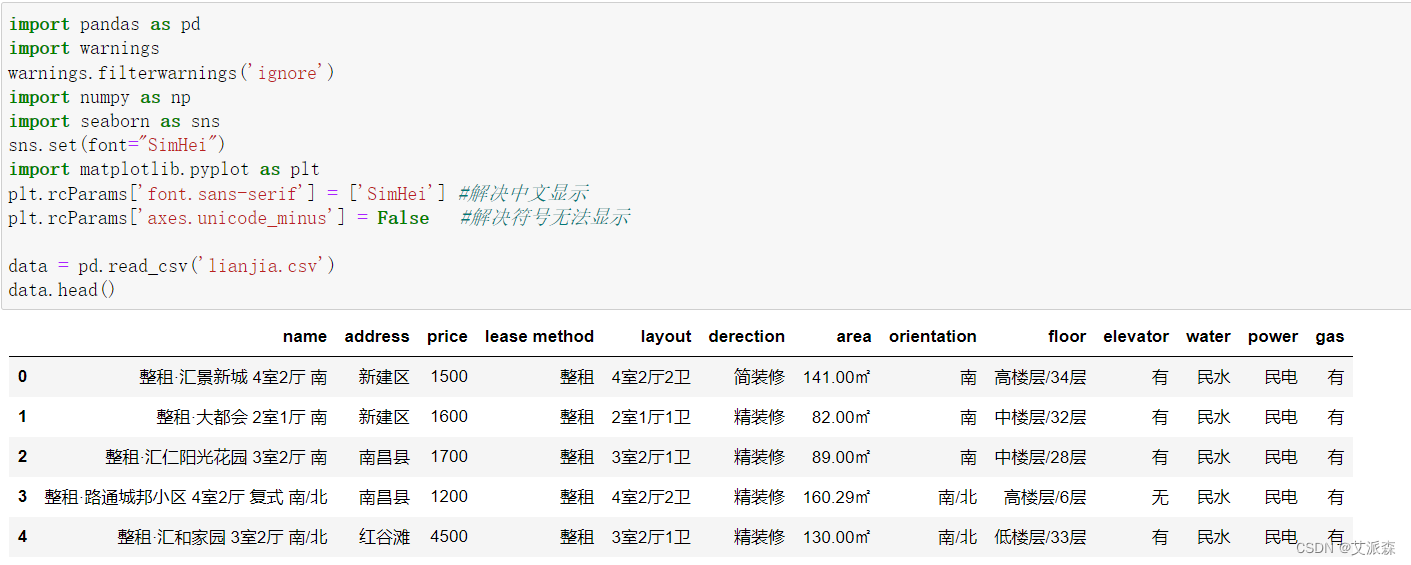
查看数据大小

原始数据共有1500行,13列
查看数据基本信息
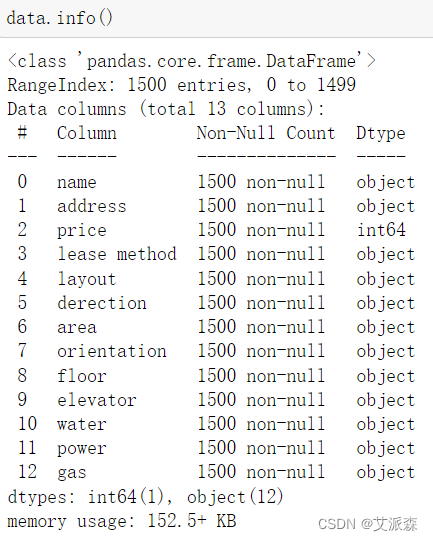
可以看出处理价格这一列,其他变量均为字符类型
查看数值型数据描述性统计
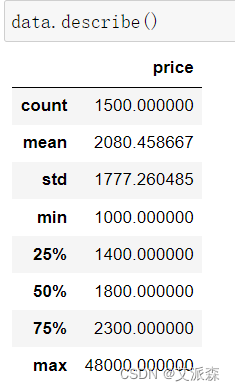
从结果可看出价格这一变量的均值、最大最小值、方差、四分位数等信息。
查看非数值数据描述性统计
从结果中可看出这些非数值行变量的个案总数、唯一值的个数、出现频率最高的值以及其出现的次数。
4.2数据预处理
数据预处理主要包括缺失值、重复值、异常值等数据的处理。
先看一下价格的分布情况,因为它是后面建模等因变量
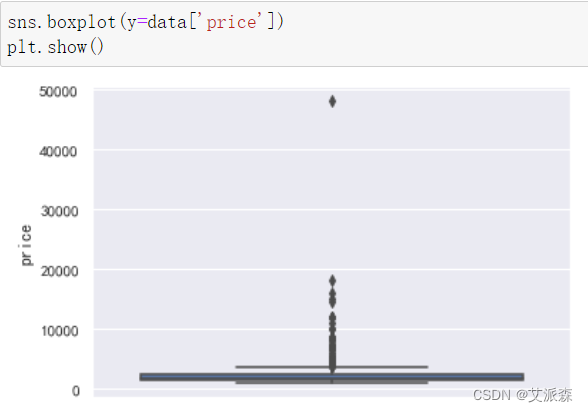
从箱型图可看出价格的分布很不均衡,故我在这里筛选出价格小于10000的数据进行分析
同时对缺失值和重复值进行删除处理
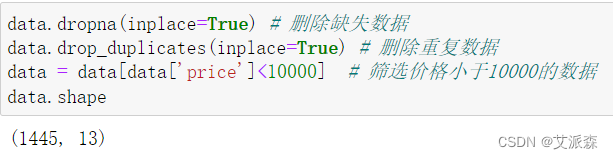
从结果可看出,共有55条数据被我们删除掉了。
4.3探索性数据分析
4.3.1电梯对于房价的影响

从结果中可看出,除了新建区和高新区,大部分地区有电梯的房价是比无电梯的房价贵的,说明有无电梯还是影响着房价。
4.3.2装修情况对于房价的影响
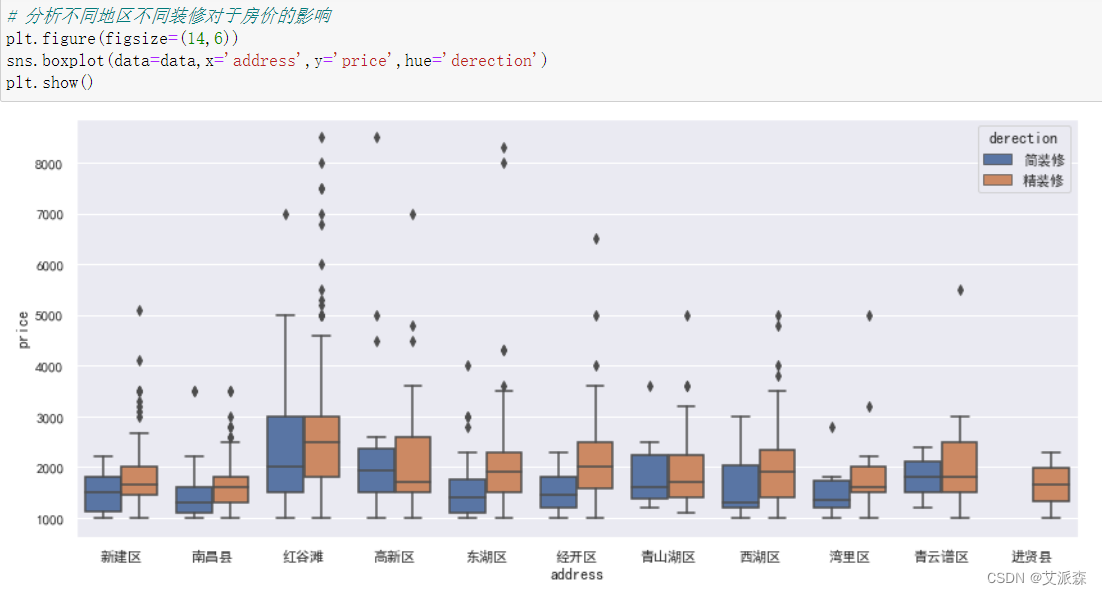
从结果看出,几乎所以的地区都是精装修的房价大于简装修的房价,说明房屋装修情况对房价的影响也很大。
4.3.3各地区的评价租房价格
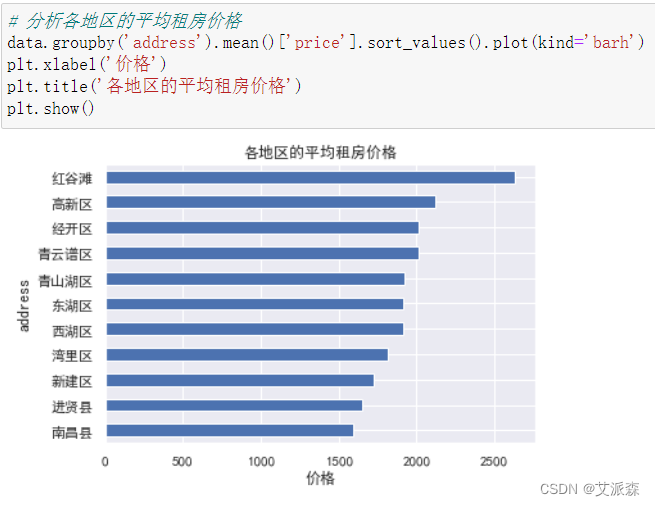
从结果看出,红谷滩的房价是最高的,高于第二名500,南昌县的房价是最低的。
4.3.4租房价格的分布
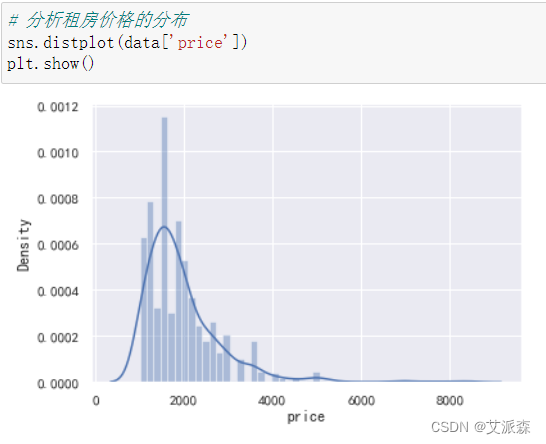
从结果看出,租房价格普遍集中在1000-3000之间。
4.4特征工程
由于原始数据中绝大部分变量都是字符型,所以在这里需要对数据进行编码处理,便于模型的建立。然后我们删除了name变量,因为它的值是由其他变量组成;删除了lease method变量,因为它的值均为整租;删除了layout变量,因为它的值可以用area面积来代替。
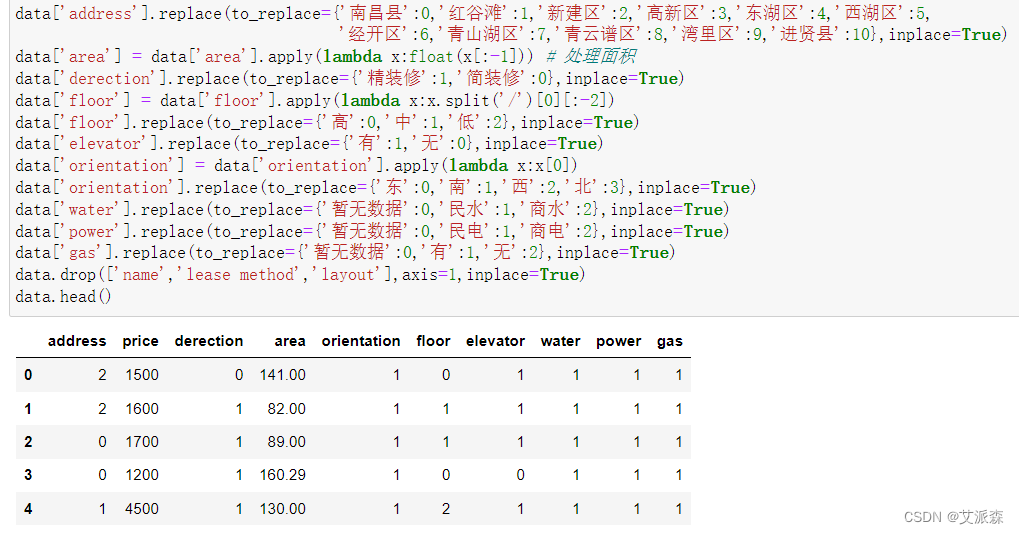
接着对原始数据集进行拆分处理,其中测试集比例为0.2

4.5模型构建
首先定义一个训练模型并评估的函数

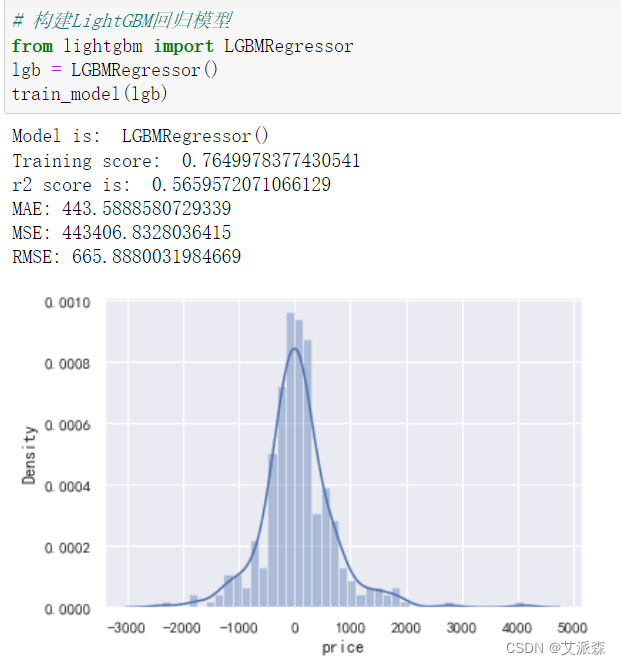
构建LightGBM回归模型
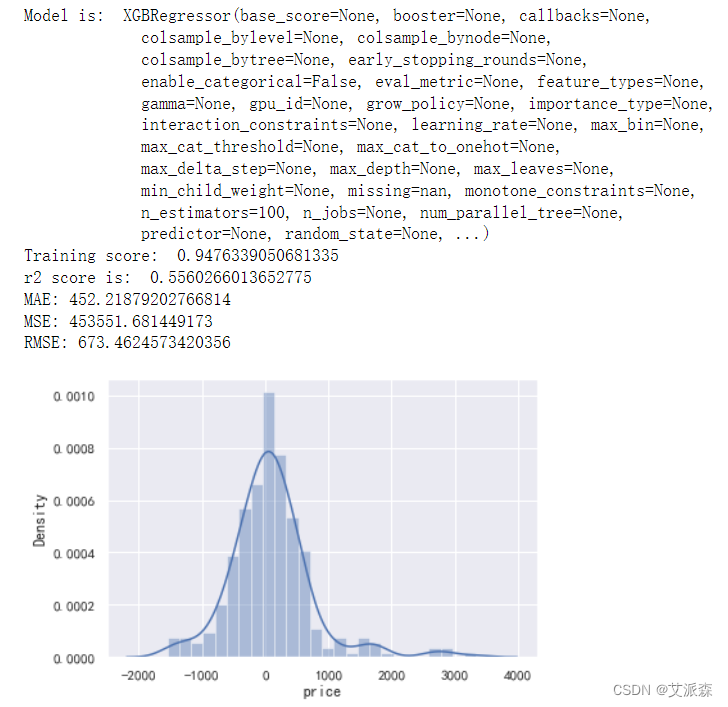
构建XGBoost模型

构建随机森林模型
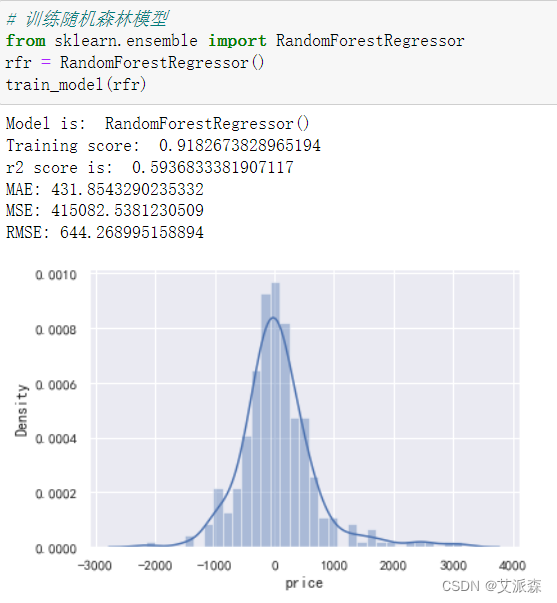
对比三个模型效果,这里我采用模型得分即training score作为标准,其中XGBoost模型的得分最高,故我们选用其作为最终的模型。
打印特征重要性评分,找出影响房价最重要的因素。
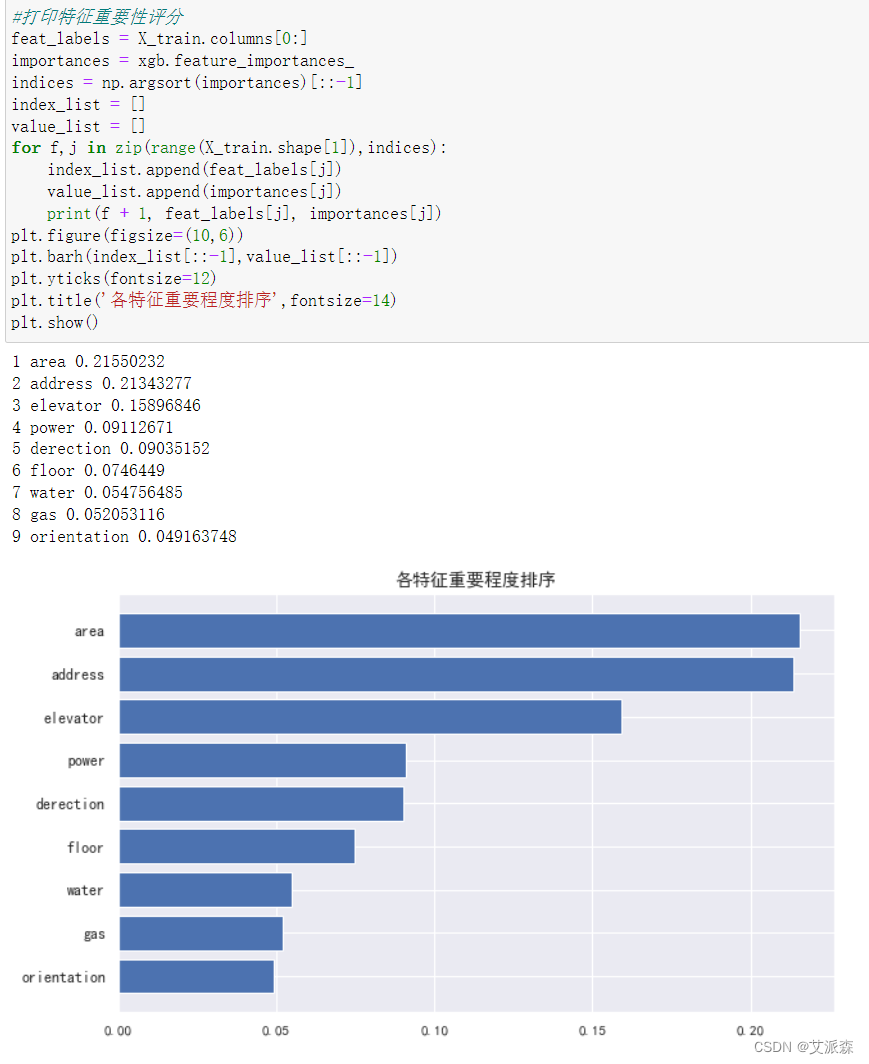
从结果看出,area面积、address地区、elevator电梯是影响房价的三大因素。
4.6模型预测
使用xgboost模型进行预测并可视化
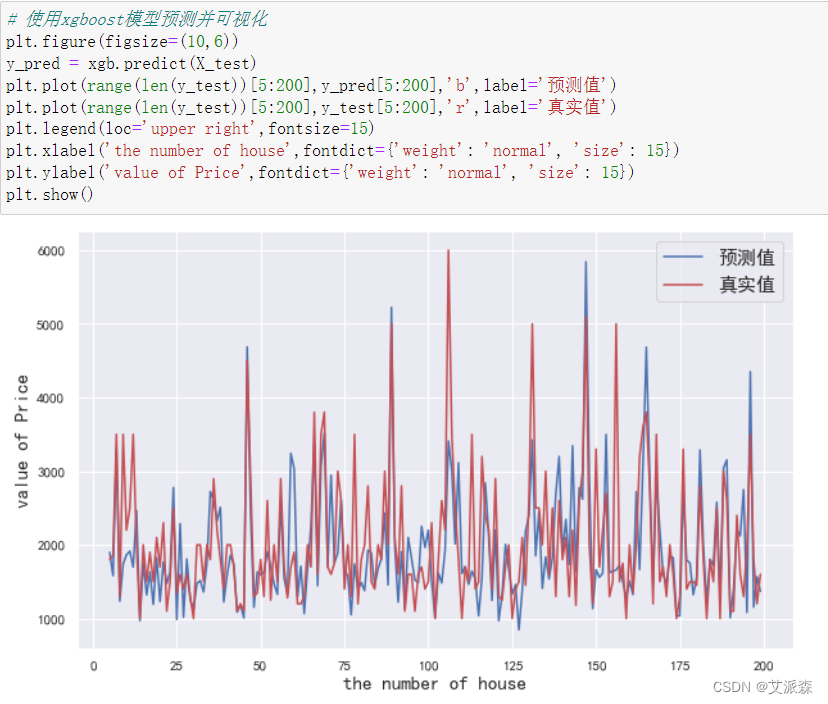
可以发现模型拟合的效果一般,还有待提高。
5.实验总结
本次实验通过对江西省南昌市的租房价格分析并建立价格评估模型,得出以下结论:
1.有无电梯和装修情况对于房价影响较大。
2.房价最高的地区为红谷滩,最低的地区为南昌县。
3.lightgbm、xgboost、随机森林三个算法中,xgboost模型效果最好。
4.area面积、address地区、elevator电梯是影响房价的三大因素
心得与体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
源代码
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import seaborn as sns
sns.set(font="SimHei")
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
data = pd.read_csv('lianjia.csv')
data.head()
data.shape
data.info()
data.describe()
data.describe(include='O')
data.isnull().sum()
any(data.duplicated())
sns.boxplot(y=data['price'])
plt.show()
data.dropna(inplace=True) # 删除缺失数据
data.drop_duplicates(inplace=True) # 删除重复数据
data = data[data['price']<10000] # 筛选价格小于10000的数据
data.shape
# 分析不同地区有无电梯对于房价的影响
plt.figure(figsize=(14,6))
sns.boxplot(data=data,x='address',y='price',hue='elevator')
plt.show()
# 分析不同地区不同装修对于房价的影响
plt.figure(figsize=(14,6))
sns.boxplot(data=data,x='address',y='price',hue='derection')
plt.show()
# 分析各地区的平均租房价格
data.groupby('address').mean()['price'].sort_values().plot(kind='barh')
plt.xlabel('价格')
plt.title('各地区的平均租房价格')
plt.show()
# 分析租房价格的分布
sns.distplot(data['price'])
plt.show()
# 特征工程
data['address'].replace(to_replace={'南昌县':0,'红谷滩':1,'新建区':2,'高新区':3,'东湖区':4,'西湖区':5,
'经开区':6,'青山湖区':7,'青云谱区':8,'湾里区':9,'进贤县':10},inplace=True)
data['area'] = data['area'].apply(lambda x:float(x[:-1])) # 处理面积
data['derection'].replace(to_replace={'精装修':1,'简装修':0},inplace=True)
data['floor'] = data['floor'].apply(lambda x:x.split('/')[0][:-2])
data['floor'].replace(to_replace={'高':0,'中':1,'低':2},inplace=True)
data['elevator'].replace(to_replace={'有':1,'无':0},inplace=True)
data['orientation'] = data['orientation'].apply(lambda x:x[0])
data['orientation'].replace(to_replace={'东':0,'南':1,'西':2,'北':3},inplace=True)
data['water'].replace(to_replace={'暂无数据':0,'民水':1,'商水':2},inplace=True)
data['power'].replace(to_replace={'暂无数据':0,'民电':1,'商电':2},inplace=True)
data['gas'].replace(to_replace={'暂无数据':0,'有':1,'无':2},inplace=True)
data.drop(['name','lease method','layout'],axis=1,inplace=True)
data.head()
from sklearn.model_selection import train_test_split
X = data.drop('price',axis=1)
y = data['price']
# 划分数据集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
print('训练集大小',X_train.shape[0])
print('测试集大小',X_test.shape[0])
from sklearn.metrics import r2_score,mean_absolute_error,mean_squared_error
# 定义一个训练模型并对模型各个指标进行评估的函数
def train_model(ml_model):
print("Model is: ", ml_model)
model = ml_model.fit(X_train, y_train)
print("Training score: ", model.score(X_train,y_train))
predictions = model.predict(X_test)
r2score = r2_score(y_test, predictions)
print("r2 score is: ", r2score)
print('MAE:', mean_absolute_error(y_test,predictions))
print('MSE:', mean_squared_error(y_test,predictions))
print('RMSE:', np.sqrt(mean_squared_error(y_test,predictions)))
# 真实值和预测值的差值
sns.distplot(y_test - predictions)
# 构建LightGBM回归模型
from lightgbm import LGBMRegressor
lgb = LGBMRegressor()
train_model(lgb)
# 构建XGBoost回归模型
from xgboost import XGBRegressor
xgb = XGBRegressor()
train_model(xgb)
# 训练随机森林模型
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor()
train_model(rfr)
# 使用xgboost模型预测并可视化
plt.figure(figsize=(10,6))
y_pred = xgb.predict(X_test)
plt.plot(range(len(y_test))[5:200],y_pred[5:200],'b',label='预测值')
plt.plot(range(len(y_test))[5:200],y_test[5:200],'r',label='真实值')
plt.legend(loc='upper right',fontsize=15)
plt.xlabel('the number of house',fontdict={'weight': 'normal', 'size': 15})
plt.ylabel('value of Price',fontdict={'weight': 'normal', 'size': 15})
plt.show()
#打印特征重要性评分
feat_labels = X_train.columns[0:]
importances = xgb.feature_importances_
indices = np.argsort(importances)[::-1]
index_list = []
value_list = []
for f,j in zip(range(X_train.shape[1]),indices):
index_list.append(feat_labels[j])
value_list.append(importances[j])
print(f + 1, feat_labels[j], importances[j])
plt.figure(figsize=(10,6))
plt.barh(index_list[::-1],value_list[::-1])
plt.yticks(fontsize=12)
plt.title('各特征重要程度排序',fontsize=14)
plt.show()






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结