您现在的位置是:首页 >其他 >《DETRs Beat YOLOs on Real-time Object Detection》将DETR加速至实时SOTA网站首页其他
《DETRs Beat YOLOs on Real-time Object Detection》将DETR加速至实时SOTA
DETRs Beat YOLOs on Real-time Object Detection

最近看到百度写的一篇还算不错的DETR论文,通过简化DINO的encoder层将模型加速到实时水平,翻译了下,以作记录。
论文地址:https://arxiv.org/pdf/2304.08069.pdf
开源地址:https://github.com/PaddlePaddle/PaddleDetection
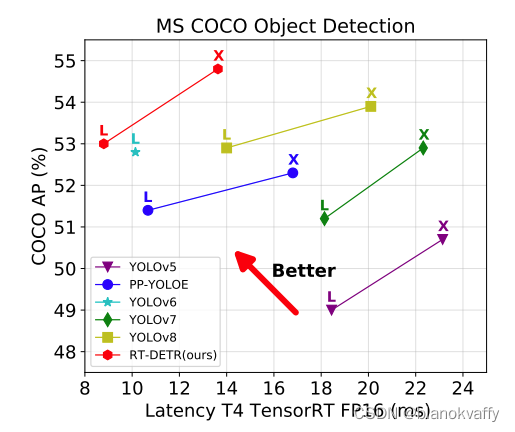
模型结构
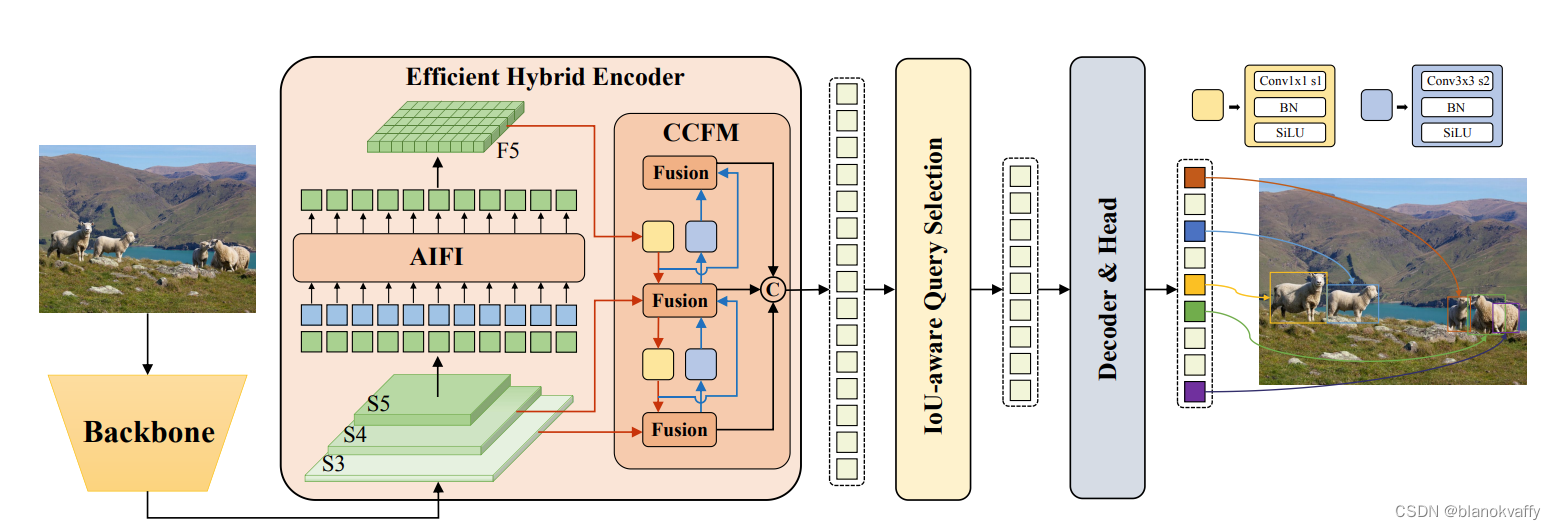
RT-Detr网络首先利用骨干网络{S3,S4,S5}的最后三个阶段的特征作为encoder的输入。encoder通过尺度内特征交互(AIFI,按文中的说法其实就是一个transformer layer)和跨尺度特征融合模块(CCFM)将多尺度特征转换为图像特征序列。IoU感知查询选择用于选择固定数量的图像特征以用作解码器的初始对象查询。最后,具有辅助预测头的decoder(与DINO的decoder相同)迭代地优化对象查询,以生成框和置信度分数。
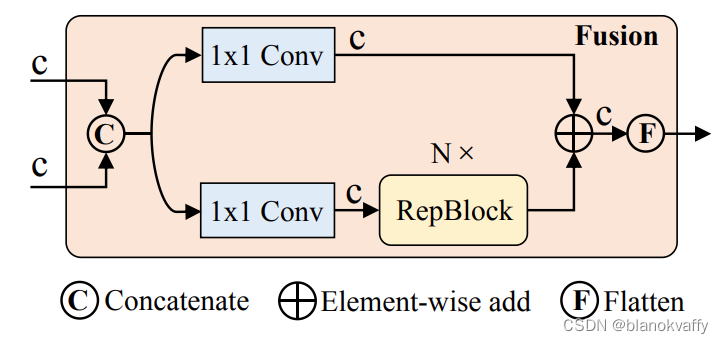
主要创新点
1、 简化DINO的encoder
这篇文章认为导致DINO速度较慢的主要原因在于DINO中采用deformable attn进行多尺度特征融合的六层encoder层,encoder占据了DINO模型49%的FLOPS,却只提供了11%的AP提升。为了克服这一障碍,这篇文章分析了多尺度deformable attn encoder中存在的计算冗余,并设计了一组变体来证明尺度内和尺度间特征的同时交互在计算上是低效的。
这篇文章提出五种encoder结构来取代原生的encoder,如下图所示:
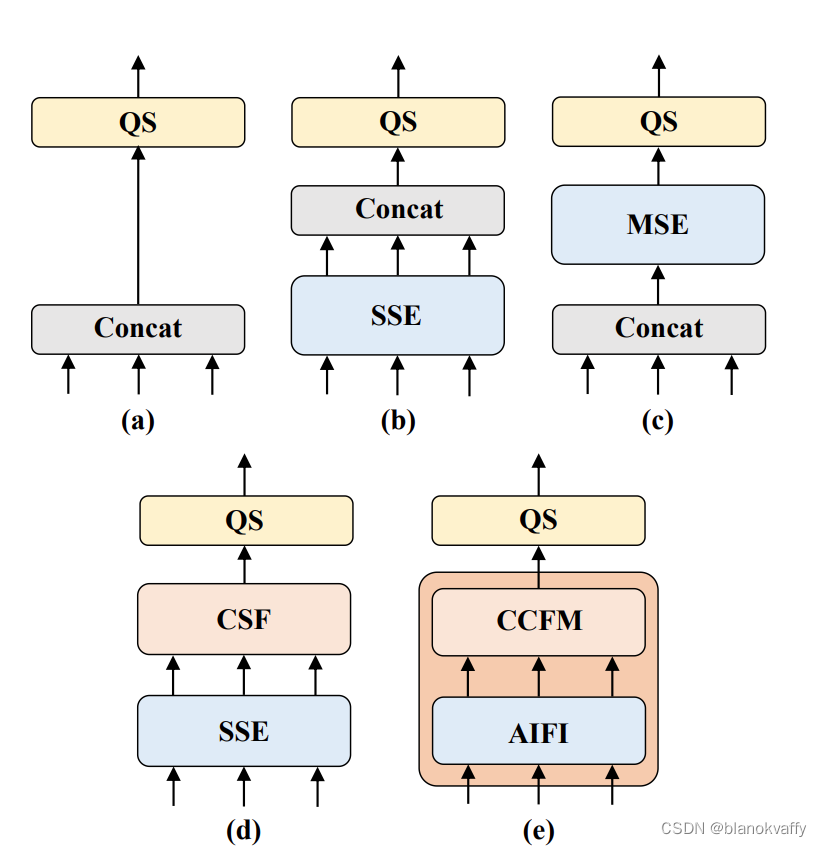
分别为作为基线的没有任何encoder的A,对不同尺度特征分别进行attn的B、采用多尺度deformable attn 的C、对不同尺度特征分别进行attn随后进行多尺度融合(利用PANET等FPN)的D、还有进一步优化了基于D的多尺度特征的尺度内交互和跨尺度融合,采用了本文设计的高效混合编码器的E。五种encoder结构的COCO MAP分别为:
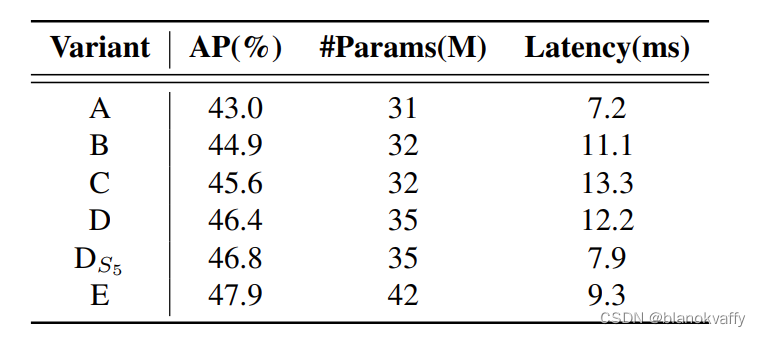
可以看到分别进行尺度内和尺度间特征的D、E在mAP和延迟上均取得了更好的结果。E在D的基础上进一步减少了计算冗余,只在S5特征上执行尺度内交互。这篇文章认为,将自注意操作应用于具有更丰富语义概念的高级特征可以捕捉图像中概念实体之间的联系,这有助于后续模块对图像中对象的检测和识别。同时,避免由于语义概念的缺乏以及与高级特征的交互所造成的发生重复和混淆的风险。
本文所提出的高效encoder可以表示为:
Q
=
K
=
V
=
F
l
a
t
t
e
n
(
S
5
)
Q=K=V=Flatten(S_{5})
Q=K=V=Flatten(S5)
F
5
=
R
e
s
h
a
p
e
(
A
t
t
n
(
Q
,
K
,
V
)
)
F_5=Reshape(Attn(Q,K,V))
F5=Reshape(Attn(Q,K,V))
O
u
t
p
u
t
=
C
C
F
M
(
F
5
,
S
4
,
S
3
)
Output=CCFM(F_5,S_4,S_3)
Output=CCFM(F5,S4,S3)
2、 IoU感知查询选择
DETR中的对象查询是一组可学习的嵌入向量,它们由decoder优化,并由预测头映射到分类分数和边界框。DINO的对象查询是利用分类分数从encoder中选择前K个特征来初始化对象查询。然而,由于分类得分和位置置信度的分布不一致,一些预测框具有高分类得分,但不接近GT框,这导致选择了分类得分高、IoU得分低的框,而分类得分低、IoU分数高的框被丢弃。这会削弱检测器的性能。为了解决这个问题,本文提出了IoU感知查询选择,通过约束模型在训练期间为具有高IoU分数的特征产生高分类分数,并为具有低IoU得分的特征产生低分类分数。因此,与由根据分类得分的模型选择的前K个编码器特征相对应的预测框具有高分类得分和高IoU得分。本文将DETR的二分匹配重新表述如下:
L
(
y
^
,
y
)
=
L
b
b
o
x
(
b
^
,
b
)
+
L
c
l
s
(
c
^
,
c
,
I
o
U
)
L(hat y,y)=L_{bbox}(hat b,b) + L_{cls}(hat c,c,IoU)
L(y^,y)=Lbbox(b^,b)+Lcls(c^,c,IoU)
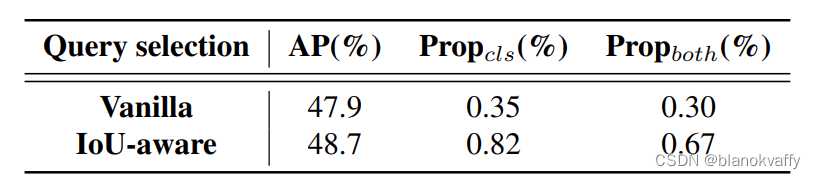
通过IoU感知查询选择,在COCO MAP有了显著提升。
结果
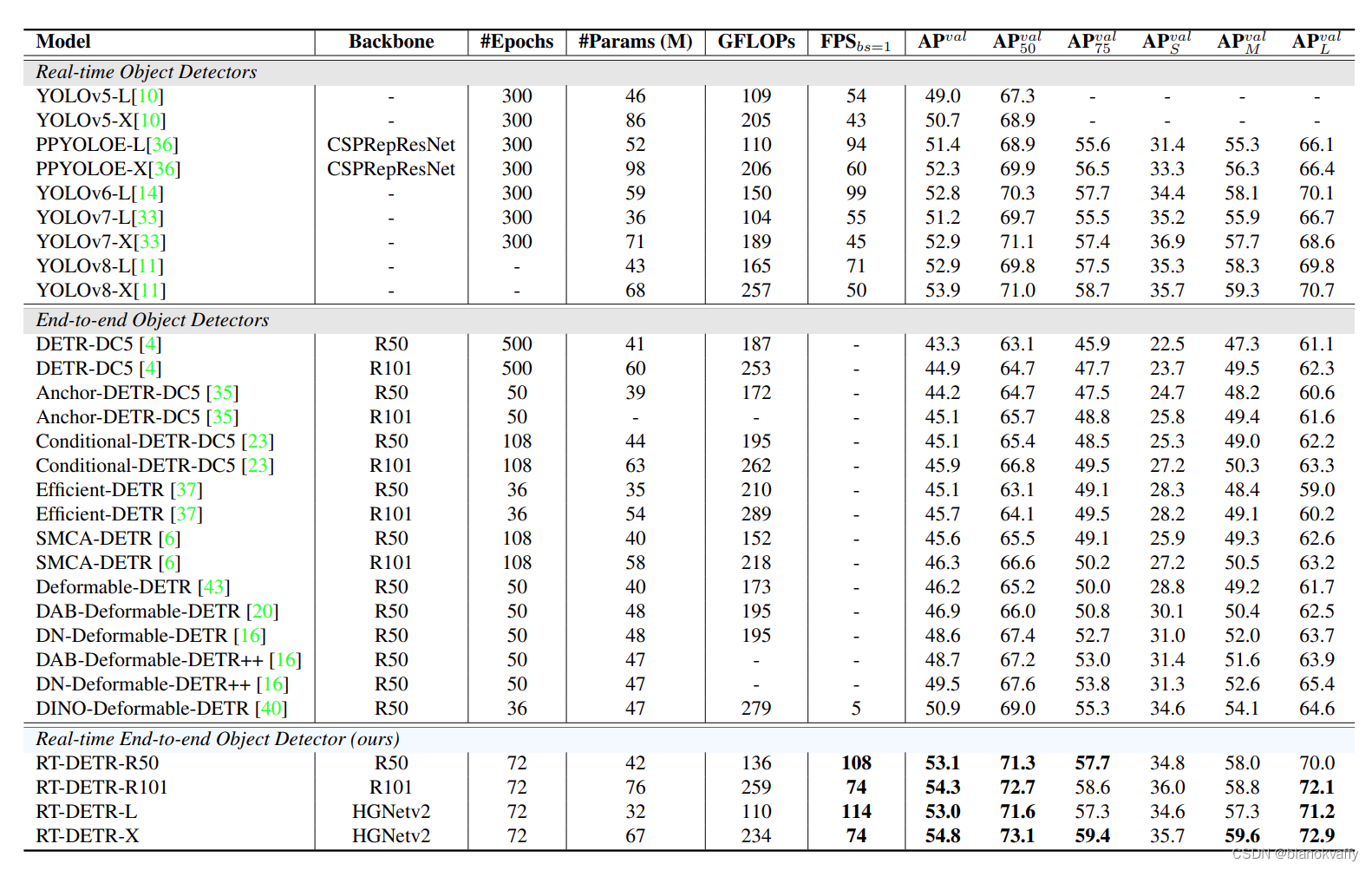
本文提出的RT-detr训练和测试均在(640,640)上进行,并且训练了72个epoch,咋看一下感觉和DINO(1333,800的输入)的对比并不十分公平。同时,如果将这种简化的encoder应用在mask DINO上,不知道是否也会有如此惊艳的效果。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结