您现在的位置是:首页 >技术交流 >高逼格的 SQL 写法:行行比较网站首页技术交流
高逼格的 SQL 写法:行行比较
简介高逼格的 SQL 写法:行行比较
码农code之路 2023-06-01 08:28 发表于天津
-
环境准备
-
需求背景
-
循环查询
-
OR 拼接
-
混查过滤
-
行行比较
-
总结
环境准备
数据库版本:MySQL 5.7.20-log

建表 SQL
DROP TABLE IF EXISTS `t_ware_sale_statistics`;
CREATE TABLE `t_ware_sale_statistics` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`business_id` bigint(20) NOT NULL COMMENT '业务机构编码',
`ware_inside_code` bigint(20) NOT NULL COMMENT '商品自编码',
`weight_sale_cnt_day` double(16,4) DEFAULT NULL COMMENT '平均日销量',
`last_thirty_days_sales` double(16,4) DEFAULT NULL COMMENT '最近30天销量',
`last_sixty_days_sales` double(16,4) DEFAULT NULL COMMENT '最近60天销量',
`last_ninety_days_sales` double(16,4) DEFAULT NULL COMMENT '最近90天销量',
`same_period_sale_qty_thirty` double(16,4) DEFAULT NULL COMMENT '去年同期30天销量',
`same_period_sale_qty_sixty` double(16,4) DEFAULT NULL COMMENT '去年同期60天销量',
`same_period_sale_qty_ninety` double(16,4) DEFAULT NULL COMMENT '去年同期90天销量',
`create_user` bigint(20) DEFAULT NULL COMMENT '创建人',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`modify_user` bigint(20) DEFAULT NULL COMMENT '最终修改人',
`modify_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最终修改时间',
`is_delete` tinyint(2) DEFAULT '2' COMMENT '是否删除,1:是,2:否',
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_business_ware` (`business_id`,`ware_inside_code`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC COMMENT='商品销售统计';
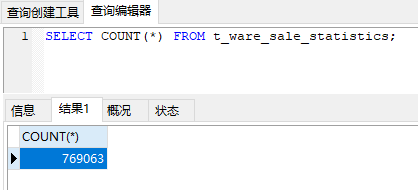
初始化数据
准备了 769063 条数据
需求背景
业务机构下销售商品,同个业务机构可以销售不同的商品,同个商品可以在不同的业务机构销售,也就说:业务机构与商品是多对多的关系
假设现在有 n 个机构,每个机构下有几个商品,如何查询出这几个门店下各自商品的销售情况?
具体点,类似如下

如何查出 100001 下商品 1000、1001、1003 、 100002 下商品 1003、1004 、 100003 下商品 1006、1008、1009 的销售情况
相当于是双层列表(业务机构列表中套商品列表)的查询;业务机构列表和商品列表都不是固定的,而是动态的
是双层列表(业务机构列表中套商品列表)的查询;业务机构列表和商品列表都不是固定的,而是动态的
那么问题就是:如何查询多个业务机构下,某些商品的销售情况
问题经我一描述,可能更模糊了,大家明白意思了就好!
循环查询
这个很容易想到,在代码层面循环业务机构列表,每个业务机构查一次数据库,伪代码如下:

具体的 SQL 类似如下

SQL 能走索引

实现简单,也好理解,SQL 也能走索引,一切看起来似乎很完美
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结