您现在的位置是:首页 >技术教程 >MySQL 查询分析网站首页技术教程
MySQL 查询分析
一个低效查询引发的思考
上次在做银行对账,上传对账单后,出现对账超时的情况。查看日志发现,最后一条日志记录停在了对 c2c_zwdb.t_file_count 的查询 sql 上。使用 show processlist 命令来查看当前 SQL 的执行情况,如下:
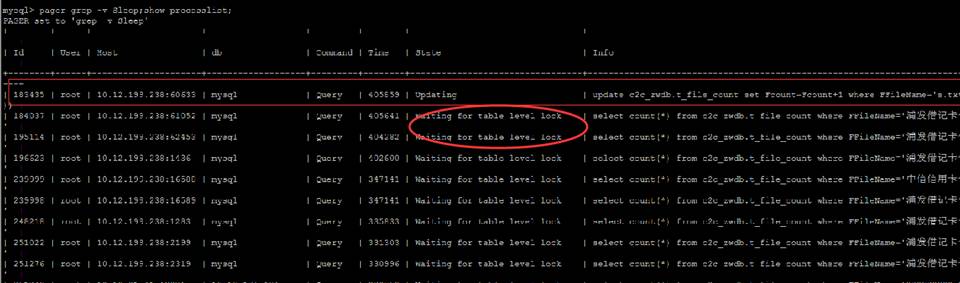
由上图可知,原来是发生锁表了 waiting for table level lock。
引发锁表的 sql 语句就是上图中 status 为 updating 的语句为:
update c2c_zwdb.t_file_count set Fcount=Fcount 1 where FFileName='1001_招商银行 (1).txt' and Ftype=2
该条 update 语句还未执行完,给表 c2c_zwdb.t_file_count 加的写锁还没释放,又执行 select 读操作,select 语句会等待表级锁,导致阻塞而使银行对账超时。
为什么这条 update 语句执行了如此久还没执行完呢?这个语句不够高效,当在数据量很大的情况下,执行效率更慢。
定位 MySQL 性能瓶颈的方法很多,主要为这两种:慢查询与 explain 命令。
一 慢查询
慢查询,顾名思义,就是查询超过指定时间 long_query_time 的 SQL 语句查询称为"慢查询"。 慢查询帮我们找到执行慢的 SQL,方便我们对这些 SQL 进行优化。
慢查询开启方法
long_query_time 是用来定义慢于多少秒的才算"慢查询"。查询 long_query_time 的值如下:

我们可以将其设置设置 long_query_time=2,如下。

开启慢查询的方法,一是可以通过在配置文件 my.cnf 或 my.ini 中设置配置参数,二是可以通过命令行设置变量来即时启动慢查询日志,个人比较喜欢第二种即时性的。由下图可知,记录慢查询日志已开启,slow_query_log=ON。

slow_query_log 是否打开记录慢查询日志
slow_query_log_file 日志存放位置
MySQLdumpslow命令
接下来看看慢查询日志的格式是怎么样。例如,在 MySQL 中运行 select sleep(3);
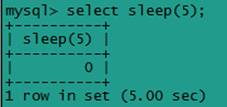
打开慢查询日志文件 MySQL-slow.log 的信息格式如下,说明这条 sql 语句执行用时 5.000183s,锁了 0s,查询返回 1 行,一共查了 0 行。

随着 MySQL 数据库服务器运行时间的增加,可能会有越来越多的 SQL 查询被记录到了慢查询日志文件中,这时要分析慢查询日志就显得不是很容易了。MySQL 提供的 MySQLdumpslow 命令,可以很好地解决这个问题。
MySQLdumpslow 的主要功能是统计不同慢 sql 的:
- 执行次数(count)
- 执行最长时间(time)
- 累计总耗费时间(time)
- 等待锁的时间(lock)
- 发送给客户端的行总数(rows)
- 扫描的行总数(rows)
进入 MySQL/bin 目录,输入 MySQLdumpslow -help 或--help 可以看到这个工具的参数。
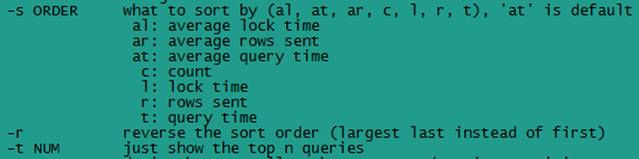
-s,是表示按照何种方式排序,c、t、l、r 分别是按照执行次数、执行时间、等待锁时间、返回的记录数来排序,ac、at、al、ar 表示相应的平均值;
- -r,是前面排序的逆序;
- -t,是 top n 的意思,即为返回排序后前面多少条的数据;
- -g,后边可以写一个正则匹配模式,大小写不敏感的;
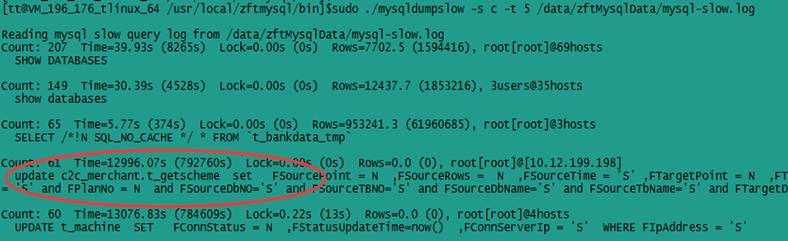
比如,执行./MySQLdumpslow -s c -t 5/data/zftMySQLData/MySQL-slow.log,得到执行次数最多的前 5 个查询,如下图所示。
执行./MySQLdumpslow -s r -t 10 /data/zftMySQLData/MySQL-slow.log,得到返回记录数最多的前 10 个查询。
使用 MySQLdumpslow 命令可以非常明确的得到各种我们需要的查询语句,对 MySQL 查询语句的监控、分析、优化是 MySQL 优化的第一步,也是非常重要的一步。
二 explain 分析查询
在分析查询性能时,EXPLAIN 关键字同样很管用。EXPLAIN 关键字一般放在 SELECT 查询语句的前面,使用 EXPLAIN 关键字可以模拟优化器执行 SQL 查询语句,从而知道 MySQL 是如何处理 SQL 语句的。这可以帮助分析查询语句效率低下的原因或是表结构的性能瓶颈。通过 explain 命令可以得到:
– 表的读取顺序
– 数据读取操作的操作类型
– 哪些索引可以使用
– 哪些索引被实际使用
– 表之间的引用
– 每张表有多少行被优化器查询
Explain的用法
Explain tablename 或
Explain [EXTENDED] SELECT select_options
前者可以得出一个表的字段结构等等,后者主要是给出相关的一些索引信息,本文要讲述的重点是后者。
首先看看 explain 的输出参数:
这些参数中,各个参数的含义如下,
Id:本次 select 的标识符。在查询中每个 select 都有一个顺序的数值。
Select_type:select 类型,主要是区别普通查询和联合查询、子查询之类的复杂查询。主要有这几种:
- SIMPLE:这个是简单的 sql 查询,不使用 UNION 或者子查询。
- PRIMARY:子查询中最外层的 select。
- UNION:UNION 中的第二个或后面的 SELECT 语句。
- DEPENDENT UNION:UNION 中的第二个或后面的 SELECT 语句,取决于外面的查询。
- UNION RESULT:UNION 的结果。
- SUBQUERY:子查询中的第一个 SELECT。
- DEPENDENT SUBQUERY:子查询中的第一个 SELECT,取决于外面的查询。
- DERIVED:派生表的 SELECT(FROM 子句的子查询)。
Table:输出行所引用的表。
Type:联合查询所使用的类型。
type 显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,得保证查询至少达到 range 级别,最好能达到 ref。
possible_keys:指出 MySQL 能使用哪个索引在该表中找到行。如果是空的,没有相关的索引。这时要提高性能,可通过检验 WHERE 子句,看是否引用某些字段,或者检查字段不是适合索引。
Key:显示 MySQL 实际决定使用的键。如果没有索引被选择,键是 NULL。
key_len:显示 MySQL 决定使用的键长度。如果键是 NULL,长度就是 NULL。文档提示特别注意这个值可以得出一个多重主键里 MySQL 实际使用了哪一部分。
Ref:显示哪个字段或常数与 key 一起被使用。
Rows:这个数表示 MySQL 要遍历多少数据才能找到,在 innodb 上是不准确的。 Extra:如果是 Only index,这意味着信息只用索引树中的信息检索出的,这比扫描整个表要快。
如果是 where used,就是使用上了 where 限制。
如果是 impossible where 表示用不着 where,一般就是没查出来啥。
如果此信息显示 Using filesort 或者 Using temporary 的话会很吃力,WHERE 和 ORDER BY 的索引经常无法兼顾,如果按照 WHERE 来确定索引,那么在 ORDER BY 时,就必然会引起 Using filesort,这就要看是先过滤再排序划算,还是先排序再过滤划算。
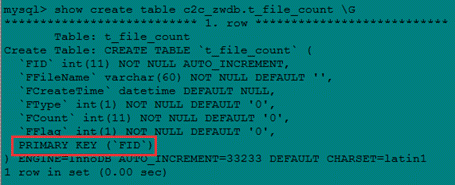
现在我们再用 explain 来看看前面案例的 sql 执行情况。首先,先看看 t_file_count 的表结构如下,该表的索引是 FId。
未执行完的 sql 语句是 update c2c_zwdb.t_file_count set Fcount=Fcount 1 where FFileName='1001_招商银行 (1).txt' and Ftype=2
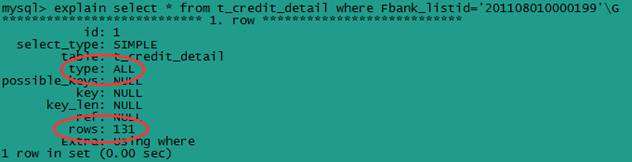
将其转换为 select 语句,select count(*) from c2c_zwdb.t_file_count where FFileName='1001_招商银行 (1).txt' and Ftype=2。执行explain命令如下:

由上图可见,type=all,key=NULL,该 sql 未使用索引,是一个效率非常低的全表扫描,在数据量很大的情况下,性能情况可想而知。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结