您现在的位置是:首页 >技术教程 >软件工程---期末复习题网站首页技术教程
软件工程---期末复习题
选择题
1、具有风险分析的软件生命周期模型是( C )。
A、瀑布模型
B、喷泉模型
C、螺旋模型
D、增量模型
螺旋模型是一种迭代的软件开发模型,强调风险管理和迭代开发。在螺旋模型中,项目经理和开发团队通过多个迭代周期来逐步开发和完善软件系统。每个迭代周期包括四个主要阶段:计划、风险分析、工程开发和评审。
2、软件工程的基本要素包括方法、工具和( A )。
A、过程
B、软件系统
C、硬件环境
D、人员
软件工程的基本要素包括方法、工具和过程,并且人员也是一个重要的要素。
3、软件的复杂性是( A ),它引起人员通信困难、开发费用超支、开发时间超时等问题。
A、固有的
B、人为的
C、可消除的
D、不可降低的
软件系统的设计和实现通常涉及到大量的细节和相互关联的部分,这导致了软件本身的复杂性。软件的复杂性是由系统需求、功能规模、交互关系、数据处理等方面的固有特性所决定的。
4、软件过程包括五个框架活动——沟通、策划、建模、构建和部署。其中,哪个活动主要涉及确定软件系统的需求、功能和性能等方面的规范和描述?( C )
A、沟通
B、策划
C、建模
D、构建
E、部署
建模活动主要涉及确定软件系统的需求、功能和性能等方面的规范和描述。在软件过程中,建模活动通过使用不同的建模技术和工具,如需求建模、系统建模、数据建模等,来对软件系统进行抽象和描述,以便于后续的开发、测试和部署工作。
5、“软件危机”是指( C )。
A、计算机病毒的出现
B、利用计算机进行经济犯罪活动
C、软件开发和维护中出现的一系列问题
D、人们过分迷恋计算机系统
6、以下哪个不属于瀑布模型的优点?( D )
A、适用于小型项目
B、强调文档化和可追溯性
C、提供了明确的开发流程
D、强调迭代和快速原型开发
瀑布模型是一种线性的开发模型,按照固定的阶段顺序进行开发,不支持迭代和快速原型开发。瀑布模型的优点包括适用于小型项目、强调文档化和可追溯性、提供了明确的开发流程。
7、以下哪个不瀑布模型的缺点?( D )
A、难以适应需求变化
B、开发周期较长
C、不适用于大型项目
D、不适用于团队协作
瀑布模型的缺点包括难以适应需求变化、开发周期较长、不适用于大型项目。然而,瀑布模型并没有明确指出不适用于团队协作。在实际项目中,瀑布模型可以适用于团队协作,但要求各个团队成员在各个阶段按顺序进行工作,以确保项目的顺利进行。
8、在结构化分析方法中,( C )表达系统内部数据运动的图形化技术。
A、数据字典
B、实体关系图
C、数据流图
D、状态转换图
数据流图(Data Flow Diagram,DFD)是一种图形化的工具,用于描述系统中数据的流动和处理过程。数据流图能帮助分析人员和开发人员更好地理解和描述系统的功能和数据流程,从而进行需求分析、系统设计和功能实现。
9、在软件开发过程中,原型模型和瀑布模型是两种常见的开发方法。以下哪个描述是正确的?( A )
A、原型模型采用迭代和增量的方式进行开发,允许快速原型验证和反馈,适用于需求不明确或经常变化的项目。瀑布模型是一种线性顺序的开发方法,按照预先定义的阶段顺序进行开发。
B、原型模型和瀑布模型都是一种迭代的开发方法,根据项目需求的复杂性和规模选择使用。原型模型更适合小型项目,而瀑布模型适用于大型项目。
C、原型模型和瀑布模型是完全相同的开发方法,只是名称不同而已。
D、原型模型和瀑布模型都是一种敏捷开发方法,强调团队合作和持续交付。它们在开发过程中没有本质上的区别。
B错误,原型模型和瀑布模型适用的项目规模和复杂性没有直接关联。
C错误,原型模型和瀑布模型是两种不同的开发方法,不仅仅是名称的差异。
D错误,原型模型和瀑布模型虽然都有敏捷的特点,但它们在开发过程和方法上有本质的区别。
10、随着软硬件环境变化而修改软件的过程是( B )。
A、校正性维护
B、适应性维护
C、完善性维护
D、预防性维护
适应性维护是指根据软硬件环境的变化对软件进行修改的过程。适应性维护旨在确保软件在新的环境下继续正常运行,并充分利用新的技术和功能。
11、关于极限编程(XP)的优点,以下哪个说法是正确的?( A )
A. 提供高度灵活性和响应变化能力
B. 强调个人技能而忽视团队合作
C. 仅适用于小型项目
D. 降低软件质量和可维护性
极限编程(XP)注重高度灵活性和快速响应变化的能力。它通过迭代开发、持续交付和频繁反馈的方式,使团队能够适应需求变化,并在项目进展中及时调整。
12、软件工程的敏捷理念强调以下哪个重要方面?( C )
A. 高度规范化的流程和文档
B. 个人技能的发展和提升
C. 自组织团队的控制力
D. 长期的计划和预测
软件工程的敏捷理念强调4个关键问题:
- 自组织团队对所开展工作具有控制力的重要性;
- 团队成员之间以及开发参与者和客户之间的交流与合作;
- 对“变更代表机遇”的认识;
- 强调快速交付让客户满意的软件。
13、Scrum是一种敏捷软件开发框架,强调(自组织、迭代开发和持续反馈)。它通过迭代开发周期,称为(sprint),来持续交付可工作的软件增量。每个(sprint)的工作内容由(团队)自行决定,并通过(产品Backlog)来确定和调整优先级。团队在每天的(每日站会)会议中分享工作进展、遇到的问题和计划。Sprint结束后,进行(回顾会议)会议以评审已完成的工作并进行反馈,以及回顾会议以识别改进机会。
14、需求分析中开发人员要从用户那里了解( A )。
A、软件做什么
B、用户使用界面
C、输入的信息
D、软件的规模
15、软件详细设计的主要任务是确定每个模块的( A )。
A、算法和使用的数据结构
B、外部接口
C、功能
D、编程
16、为了提高模块的独立性,模块内部最好是( C )。
A、逻辑内聚
B、时间内聚
C、功能内聚
D、通信内聚
17、需求分析是( A )。
A、软件开发工作的基础
B、软件生存周期的开始
C、由系统分析员单独完成的
D、由用户自己单独完成的
18、极限编程(XP)模型在处理增量原型方面与螺旋模型有何不同?(ABCD)
A、迭代周期的长度
B、风险管理的方法
C、客户参与程度
D、项目控制的重点
迭代周期的长度:极限编程(XP)模型的迭代周期通常较短,而螺旋模型的迭代周期相对较长。
风险管理的方法:螺旋模型更注重风险管理和风险驱动的开发,而极限编程通过测试驱动开发(TDD)和持续集成等方法来管理风险。
客户参与程度:极限编程强调与客户的密切合作和持续交流,客户作为团队的一员参与到开发过程中。而螺旋模型中的客户参与相对较少。
项目控制的重点:极限编程采用简单的规则和实践来控制项目,如规划游戏、持续集成和团队内部的自我组织。螺旋模型更注重阶段之间的控制和规划。
19、软件维护时(maintenance) ,为扩充功能和改善性能而进行的修改,主要对已有的软件系统增加一些在系统分析和设计阶段中没有规定的功能与性能特征,这种为改善性能、可维护性或其他软件属性而进行的维护一般被称为( C )。
A、适应性维护
B、纠错性维护
C、完善性维护
D、逆向(再生)工程
适应性维护:指为了适应环境变化或新需求而对软件进行修改的维护类型,通常是通过添加新功能或进行适应性调整来应对变化。
纠错性维护:指修复已经发现的软件缺陷或错误的维护类型,旨在使软件恢复到预期的功能状态。
完善性维护:指对已有软件进行修改以改进其性能、可读性、可维护性或其他非功能特征的维护类型。
逆向(再生)工程:指对已有软件系统进行分析和研究,以获取其内部结构、功能和设计原理等信息的过程。
20、软件测试分成几个步骤,其中的( A )是在模拟的环境下,运行黑盒测试的方法,验证被测软件是否满足需求规格说明书列出的需求。任务是验证软件的功能和性能及其他特性是否与用户的要求一致。
A、确认(有效性)测试
B、集成(组装)测试
C、模块(单元)测试
D、并行(平行)测试
确认(有效性)测试:确认测试是一种验证软件是否符合需求的测试方法,旨在确保软件满足用户的期望和规格说明书的要求。
集成(组装)测试:集成测试是在将多个模块或组件组装在一起后进行的测试,以验证它们在联合工作时是否正常运行。
模块(单元)测试:模块测试是对软件中的独立模块或单元进行测试,以验证其功能的正确性和预期行为。
并行(平行)测试:并行测试是指在相同环境中同时运行两个或多个版本的软件,以比较它们之间的性能、功能和其他特性的差异。
21、软件设计(Software Design)是软件开发的关键步骤,直接影响软件质量。下述( B )不是软件设计阶段所应包含的工作?
A、软件(体系)结构
B、软件过程(构件)
C、用户接口
D、软件风险分析
22、下面哪一个选项不属于系统测试(B)。
A、回归测试
B、安全测试
C、性能测试
D、压力测试
回归测试:回归测试是在进行系统修改或更新后执行的测试,旨在确保新的修改不会影响现有功能的正确性。
安全测试:安全测试是验证系统在安全方面的漏洞和弱点的测试,以保护系统免受未经授权的访问、数据泄露或其他安全威胁。
性能测试:性能测试是评估系统在各种负载和压力条件下的性能表现,包括响应时间、吞吐量和资源利用率等方面。
压力测试:压力测试是通过将系统置于负载或压力的最大限度下进行测试,以评估系统的稳定性和可靠性,以及在超负荷条件下的性能表现。
23、软件工程是一门迅速发展的新兴学科,现已经成为计算机科学的一个重要分支。软件工程是一种层次化的技术,软件工程包括( C )三个要素。
A、技术、方法和工具
B、封装、继承、多态
C、方法、工具和过程
D、过程、模型、方法
24、软件质量是难于定量度量的软件属性,但是仍然能够提出许多重要的软件质量指标,这些指标主要从管理的角度对软件质量进行度量。在这些因素中,软件系统在硬件故障、操作错误等意外情况下仍然能够做出适当反应的程度称为软件的( B )。
A.可靠性
B.健壮性
C.可用性
D.完整性
25、软件测试分成几个步骤,其中的( D )通常应该先进行“桌前检查"和/或“步行检查",再以白盒法为主,辅以黑盒法进行动态测试。该类测试可以并行进行。
A、确认(有效性)测试
B、验收(接收)测试
C、模块(单元)测试
D、并行(平行)测试
26、数据流图(DFD: Data Flow Diagram)描绘系统的逻辑模型。它是软件开发( D )阶段经常使用的工具。
A、软件维护
B、软件测试
C、详细(过程)设计
D、需求分析
数据流图可以通过图形化的方式描述系统的功能、数据流动和处理过程,帮助分析人员和开发团队理解系统的需求和功能。在需求分析阶段,数据流图可以用于捕捉和表示用户需求、业务过程以及数据在系统中的流动和处理。
27、软件需求确定以后,进入由软件设计、编码 (Coding) 和( B )三个关联阶段构成的软件开发 (development) 阶段。
A、需求分析
B、软件测试
C、系统定义
D、软件维护
28、如果需求不明确,我们最好采用( A )来明确需求。
A、原型模型
B、瀑布模型
C、增量模型
D、螺旋模型
原型模型是一种迭代开发方法,它通过构建初步的原型来帮助用户和开发团队更好地理解需求,并在需求澄清的过程中进行迭代和改进。通过原型模型,用户可以提供反馈和建议,开发团队可以根据反馈进行调整和完善,从而逐渐明确和理解需求。
29、模块内聚性是模块独立性的重要度量因素,在下述的几类内聚性中,具有最弱内聚性的一类是( D )。
A、顺序型内聚
B、通信型内聚
C、功能型内聚
D、偶然型内聚
顺序型内聚:模块内的成分按照顺序连接,前一个成分的输出作为后一个成分的输入。这种内聚性是一种比较强的内聚性,模块的功能被划分为一系列顺序执行的步骤。
通信型内聚:模块内的成分之间通过共享数据进行通信。这种内聚性表示模块内的成分之间通过传递消息或共享数据来实现某个共同的功能。
功能型内聚:模块内的成分执行一组相关的功能,彼此之间紧密联系,共同完成一个明确的任务或功能。这种内聚性是一种比较强的内聚性。
偶然型内聚:模块内的成分之间没有明确的关联,它们被放在同一个模块中是由于历史原因、技术限制或其他非功能性因素。这种内聚性是一种较弱的内聚性,模块内部的成分之间缺乏明确的联系或目标。
30、软件测试分成几个步骤,其中的集成测试一般要在( C )完成后才能进行。
A、确认(有效性)测试
B、验收(接收)测试
C、模块(单元)测试
D、并行(平行)测试
31、瀑布模型本质上是一种( A )。
A、线性顺序模型
B、顺序迭代模型
C、线性迭代模型
D、增量开发模型
瀑布模型是软件开发过程中最早被提出的一种经典模型,它采用线性顺序的方式进行软件开发。在瀑布模型中,各个阶段按照顺序依次进行,每个阶段的输出作为下一个阶段的输入,形成了一个明确的开发流程。
32、( D )是软件投入市场前由支持软件预发行的客户对FLURPSS进行测试,是软件的多个用户在实际使用环境下进行的测试,开发者通常不在测试现场。
A、验收测试
B、功能测试
C、α测试
D、β测试
验收测试:验收测试是在软件开发完成后,由用户或客户进行的测试,以确认软件是否满足其要求和期望。验收测试是软件开发的最后阶段,开发者和用户共同参与。
功能测试:功能测试是验证软件的功能是否按照规格说明书和需求定义进行设计和实现的测试。它主要关注软件的功能是否符合预期,功能测试可以在开发过程的各个阶段进行。
α测试:α测试是在软件开发的早期阶段由开发者或内部测试团队进行的测试。它主要用于发现和修复软件中的缺陷和问题,在软件投入市场前的内部测试阶段进行。
β测试:β测试是软件的多个用户在实际使用环境下进行的测试,通常由终端用户或特定目标用户参与,开发者通常不在测试现场。
33、在程序的规格说明书中,对输入条件有一句话“…输入数据x可以是0到100…”,如果你是测试人员,你该如何定义等价类( A )。
A、一个有效等价类和两个无效等价类
B、一个有效等价类和一个无效等价类
C、两个有效等价类和一个无效等价类
D、三个有效等价类
34、软件维护(maintenance)时,为扩充功能和改善性能而进行的修改,主要对己有的软件系统增加一些在系统分析和设计阶段中没有规定的功能与性能特征。这种为改善性能、可维护性或其他软件属性而进行的维护一般被称为( C )
A、适应性维护
B、纠错性维护
C、完善性维护
D、逆向(再生)工程
35、下列哪种维护类型是针对已有软件系统增加一些在系统分析和设计阶段中没有规定的功能与性能特征,为改善性能、可维护性或其他软件属性而进行的维护?( C )
A、更正性维护
B、适应性维护
C、完善性维护
D、预防性维护
完善性维护:针对已有软件系统增加功能与性能特征的维护类型
更正性维护:修复已有软件系统中的错误或缺陷
适应性维护:为了适应环境变化或用户需求变更而对软件进行修改
预防性维护:为了预防潜在的问题或故障而进行的维护活动
36、软件测试分成几个步骤,其中的( A )是在模拟的环境下,运用黑盒测试方法,验证被测软件是否满足需求规格说明书列出的需求。任务是验证软件的功能和性能及其他特性是否与用户的要求一致。
A、确认(有效性)测试
B、集成(组装)测试
C、模块(单元)测试
D、并行(平行)测试
37、软件设计 (Software Design) 是软件开发的关键步骤,直接影响软件的质量。下述( B )不是软件设计阶段所应包含的工作?
A、软件(体系)结构
B、软件过程(构件)
C、用户接口
D、软件风险分析
软件过程一般指软件开发过程中的活动、任务和方法,与软件设计阶段的具体设计工作有所区别。
38、采用甘特(Gantt)图表示软件项目进度安排。下列说法中不正确的是( C )。
A、一种按照时间进度标出工作活动,常用于项目管理的图表。
B、以图示的方式通过活动列表和时间刻度形象地表示出活动顺序与持续时间。
C、纵轴表示时间,横轴表示活动,线条表示活动完成情况。
D、直观地表明任务计划在什么时候进行,及实际进展与计划要求的对比。
甘特图的纵轴表示活动,横轴表示时间。
39、软件工程是一门迅速发展的新兴学科,现已成为计算机科学的一个重要分支。软件工程是一种层次化的技术,软件工程包括( C )三个要素。
A、技术、方法和工具
B、封装、继承、多态
C、方法、工具和过程
D、过程、模型、方法
40、软件质量是难于定量度量的软件属性,但是仍然能够提出许多重要的软件质量指标,这些指标主要从管理的角度对软件质量进行度量。在这些因素中,软件系统在硬件故障、操作错误等意外情况下仍能作出适当反应的程度称为软件的( B )
A、可靠性
B、健壮性
C、可用性
D、完整性
41、软件测试分为几个步骤,其中的( D )通常应该先进行“桌前检查”和/或“步行检查”,再以白盒法为主,辅以黑盒法进行动态测试。该类测试可以并行进行。
A、确认(有效性)测试
B、验收(接收)测试
C、模块(单元)测试
D、并行(平行)测试
42、数据流图(DFD:Data Flow Diagram)描绘系统的逻辑模型。它是软件开发( D )阶段经常使用的工具。
A、软件维护
B、软件测试
C、详细(过程)设计
D、需求分析
43、软件需求确定以后,进入由软件设计、编码(Coding)和( B )三个关联阶段构成的软件开发(develupmeni)阶段。
A、需求分析
B、软件测试
C、系统定义
D、软件维护
44、可行性研究又称为可行性分析,目的是避免盲目投资,减少不必要的损失。下列( C )不是可行性分析阶段的任务。
A、确定项目规模和目标
B、确定资源(人力、硬件、软件等)需求
C、建立新系统的高层逻辑模型
D、提出实现高层逻辑模型的各种方案,并推荐可行的方案
可行性研究是在项目初期进行的一项工作,旨在评估项目的可行性和可行性方案的可行性。在可行性分析阶段,主要任务包括确定项目规模和目标、确定资源需求(人力、硬件、软件等)、提出实现方案并推荐可行的方案。
"建立新系统的高层逻辑模型"不是可行性分析阶段的任务,而是在系统设计阶段进行的工作,用于描述系统的逻辑结构和组成部分。
45、 如果需求不明确,我们最好采用( A )来明确需求。
A、原型模型
B、瀑布模型
C、增量模型
D、敏捷模型
46、若有一个计算类型的程序,它的输入量只有一个X,其范围是[-1,0,1,0],现从输入的角度考虑一组测试用例:-0.5,0.5,1.5。设计这组测试用例的方法最可能是( C )
A、条件覆盖法
B、等价分类法
C、边界值分析法
D、错误推测法
47、如果一个模块完成的功能必须在同一时间内执行(如系统初始化),但这些功能只是因为时间因素关联在一起,则称为( C )
A、控制内聚
B、通信内聚
C、时间内聚
D、功能内聚
- 时间内聚是指模块中的功能被组织在一起,是因为它们必须在同一时间内执行,而不是因为它们在逻辑上紧密相关。
- 控制内聚是指模块中的功能紧密相关,共同实现一个控制目标。
- 通信内聚是指模块中的功能紧密相关,共同处理相同的输入和输出数据。
- 功能内聚是指模块中的功能紧密相关,共同实现一个特定的功能或者完成一个明确的任务。
48、软件测试分成几个步骤,其中的组装(集成)测试(Integration testing)一般要在( C )完成后才能进行。
A、确认(有效性)测试
B、验收(接收)测试
C、模块(单元)测试
D、并行(平行)测试
49、瀑布模型本质上是一种( A )。
A、线性顺序模型
B、顺序迭代模型
C、线性迭代模型
D、增量开发模型
- 常见的顺序迭代模型有螺旋模型(Spiral Model)和增量螺旋模型(Incremental Spiral Model)。
- 常见的线性迭代模型有喷泉模型(Fountain Model)和增量模型(Incremental Model)。
- 常见的增量开发模型有原型模型(Prototype Model)和敏捷开发模型(Agile Model)。
50、软件设计是软件开发的关键步骤,直接影响到软件的质量。软件设计复审是和软件设计本身一样重要的环节,其最主要的目的是( C )。
A、减少测试工作量
B、减少编程工作量
C、避免后期付出高代价
D、缩短软件开发周期
51、结构化程序设计(SP:Structured Program)由荷兰科学家Di jkstra首先提出,它是具有一定限制的程序设计方法,下述的( D )不是结构化程序设计所要求遵循的基本原则:
A、只使用三种程序基本结构
B、使用自顶向下,逐步求精的方式编程
C、保持模块的单入口、单出口
D、有限制地使用switch语句
结构化程序设计要求尽量避免使用复杂的控制结构,如switch语句。它主张使用三种基本结构(顺序结构、选择结构和循环结构)来构建程序,并通过自顶向下、逐步求精的方式进行编程。此外,结构化程序设计还强调模块化,即保持模块的单入口、单出口,以提高程序的可读性和可维护性。
52、模块的内聚性最高的是( D )。
A、逻辑内聚
B、时间内聚
C、偶然内聚
D、功能内聚
53、单元测试的测试用例主要根据( D )的结果来设计。
A、需求分析
B、源程序
C、概要设计
D、详细设计
54、类构件的重用方式有多态重用、继承重用和(A)。
A、实例重用
B、重载重用
C、代码重用
D、方法重用
55、在白盒测试技术测试用例的设计中,( B )是最强的覆盖标准。
A、语句覆盖
B、路径覆盖
C、条件组合覆盖
D、判定覆盖
- 路径覆盖是一种白盒测试方法,它要求测试用例能够覆盖软件程序的所有可能路径。
- 语句覆盖要求测试用例能够覆盖软件程序的每个语句,但并不保证覆盖所有可能的路径。
- 条件组合覆盖是一种基于条件的覆盖标准,要求测试用例能够覆盖所有条件的组合情况。它通常用于测试具有复杂条件逻辑的程序。
- 判定覆盖是一种要求测试用例覆盖所有可能的判定结果的覆盖标准,它关注程序中的判断语句和判断结果。
56、在白盒测试技术测试用例的设计中,( A )是最弱的覆盖标准。
A、语句覆盖
B、路径覆盖
C、条件组合覆盖
D、判定覆盖
57、软件开发的结构化生命周期方法将软件生命周期划分成( A )。
A、计划阶段、开发阶段、运行阶段
B、计划阶段、编程阶段、测试阶段
C、总体设计、详细设计、编程调试
D、需求分析、功能定义、系统设计
58、可行性研究主要从以下几个方面进行研究:( A )
A、技术可行性,经济可行性,操作可行性
B、技术可行性,经济可行性,系统可行性
C、经济可行性,系统可行性,操作可行性
D、经济可行性,系统可行性,时间可行性
软件开发的结构化生命周期方法将软件生命周期划分成计划阶段、开发阶段、运行阶段。计划阶段包括问题定义、可行性研究和需求分析;开发阶段包括概要设计、详细设计、编码和测试;运行阶段包括部署和维护。
59、黑盒测试在设计测试用例时,主要研究( A )。
A、需求规格说明于概要设计说明
B、详细设计说明
C、项目开发计划
D、概要设计说明与详细设计说明
60、根据缺陷排除效率的定义,假设一个软件项目在发布前发现了100个缺陷,而发布后又发现了50个缺陷。计算该项目的缺陷排除效率(DRE)是多少?( C )
A、0.33
B、0.5
C、0.67
D、0.75
根据缺陷排除效率的公式,E为发布前发现的缺陷数,D为发布以后发现的缺陷数。代入数据,我们有E = 100,D = 50。
根据公式 DRE = E / (E + D),将数据代入得到 DRE = 100 / (100 + 50) = 0.67。
61、软件测试的目的是( B )。
A、评价软件的质量
B、发现软件的错误
C、找出软件的所有错误
D、证明软件是正确的
62、软件详细设计的主要任务是确定每个模块的( A )。
A、算法和使用的数据结构
B、外部接口
C、功能
D、编程
63、
class JobQueueClass
{
public:
int queueLength;
int queue[25];
public:
void initializeJobQueue();
void addJobToQueue();
void removeJobFromQueue();
}
JobQueueClass 定义如上图,则该类的内聚情况属于( B )。
A、实用内聚
B、功能内聚
C、顺序内聚
D、通信内聚
功能内聚是指模块或类内的各个成员函数共同实现一个特定的功能。在给定的代码中,JobQueueClass 类包含了一系列与作业队列相关的操作函数,包括初始化队列、添加作业到队列、从队列中移除作业等。这些函数共同实现了作业队列的功能,因此属于功能内聚。
其他选项的解释:
- 实用内聚:模块或类内的成员函数用于实现一组相关的操作,但功能之间没有明显的关联。
- 顺序内聚:模块或类内的成员函数按照顺序执行,其中一个函数的输出作为下一个函数的输入。
- 通信内聚:模块或类内的成员函数之间通过共享数据进行通信。
64、关注点分离、模块化、抽象、信息隐蔽概念的直接产物是模块的( C )。
A、独立性
B、重构
C、封装
D、具体化
封装是指将模块内部的实现细节隐藏起来,只暴露对外部可见的接口,从而实现模块与外部的隔离和独立性。关注点分离、模块化、抽象以及信息隐蔽的概念都有助于实现封装。
其他选项解释:
独立性:模块独立于其他模块,可以单独进行开发、测试和维护。
重构:重构是对现有代码的改进和优化,旨在提高代码的质量和可维护性。
具体化:不符合给定描述,不是封装的直接产物。
65、在团队协助中,( D )行为是合理的。
A、斤斤计较
B、向组长反映对某个组员的不满
C、找到高薪就跳槽
D、能力很强,大包大揽
66、如果客户要求交付产品的时间非常迫切、团队中有几个项目同时在开发,我们最好采用( A )来开发这个项目。
A、增量模型
B、螺旋模型
C、瀑布模型
D、原型模型
增量模型是一种软件开发方法,它将项目划分为多个小的增量部分,每个增量都是一个可交付的、完整的功能子集。在每个增量中,团队可以按照优先级完成必要的功能和特性。这种方法可以让团队快速交付部分功能,并在后续增量中逐步完善和改进。对于紧迫的项目交付需求和并行开发的情况,增量模型可以帮助团队以迅速且可控的方式进行开发,并及时满足客户的要求。
67、用于衡量软件开发组织的过程能力和成熟度水平的模型是( A )。
A、CMMI
B、RAD
C、CPM
D、UP
- CMMI(Capability Maturity Model Integration,能力成熟度模型集成):
CMMI是一种广泛使用的评估模型,旨在评估和改进组织的软件工程过程。它提供了一套指南和最佳实践,帮助组织评估其软件开发和管理过程的成熟度,并提供改进路径。CMMI定义了不同成熟度级别,从初始级到优化级,组织可以根据其过程能力和成熟度水平进行评估和改进。- RAD(Rapid Application Development,快速应用程序开发)
- CPM(Critical Path Method,关键路径法)
- UP(Unified Process,统一过程)不是用于评估组织过程能力和成熟度的模型。
68、对于一个项目的工作重,给出的乐观、可能和悲观估计分别是10、25、60人月。基于三点估算,这个项目的工作量为( B )人月。
A、25
B、31.7
C、28.3
D、30
基于三点估算,可以使用PERT(Program Evaluation and Review Technique)来计算项目的工作量。PERT计算公式如下:
工作量 = (乐观估计 + 4 * 可能估计 + 悲观估计) / 6
在这个例子中,乐观估计为10人月,可能估计为25人月,悲观估计为60人月。
工作量 = (10 + 4 * 25 + 60) / 6
工作量 ≈ 31.7人月因此,这个项目的工作量约为31.7人月。所以答案是 B、31.7。
69、用于找到关键路径的方法是( C )。
A、UP
B、UML
C、CPM
D、DFD
用于找到关键路径的方法是:CPM(Critical Path Method,关键路径法)
CPM是一种项目管理技术,用于确定项目中的关键路径和关键活动。关键路径是指在项目网络图中,连接起始节点和结束节点,且具有最长时间的路径。关键路径上的活动对于项目的完成时间具有重要影响,延误任何一个关键路径上的活动都会延误整个项目的完成时间。CPM通过计算活动的最早开始时间、最晚开始时间、最早完成时间和最晚完成时间等参数,确定关键路径和项目的总工期。
UP(Unified Process,统一过程)是一种软件开发过程框架;UML(Unified Modeling Language,统一建模语言)是一种图形化建模语言;DFD(Data Flow Diagram,数据流程图)是一种描述系统功能和数据流的图形化表示方法;它们与关键路径的计算无直接关系。
70、你现在正在测试一个学籍管理系统。假设你已经完成“学生选课“功能的测试,正在对“课程设置”功能进行测试。现在你发现“课程设置"功能中有一个错误,并进行了改动。按照软件工程测试的要求,此时你应该做( B )。
A、冒烟测试
B、回归测试
C、集成测试
D、确认测试
回归测试是在对软件进行更改或修复后重新运行现有的测试用例,以确保已修复的错误没有引入新的错误或没有破坏现有的功能。在这种情况下,你已经发现并更改了“课程设置”功能中的错误,现在需要对整个系统进行回归测试,以确保修复过程中没有引入其他问题,并且之前通过的测试用例仍然能够通过。
冒烟测试主要用于在对软件进行全面测试之前,快速验证系统的基本功能和稳定性。集成测试是用于测试多个组件或模块在一起协同工作的测试。确认测试是由最终用户或客户进行的测试,旨在确认软件是否符合其需求和期望。在这种情况下,回归测试是最适合的选择。
71、假设你在开发团队有3个人,每个人的生产率是3000 LOC/月,每条通信路径上的生产率开销为300 LOC/月,但是现在表明你们已经落后于进度。如果加入2个人,每个人的生产率至少是( D )才能使得小组能够赶上进度。
A、1350
B、1050
C、2700
D、2100
首先,我们需要知道原来的开发团队有多少人月的工作量,以及他们落后于进度的程度。我们可以用以下公式来计算:
原来的工作量 = 原来的人数 * 原来的生产率 * 原来的时间
原来的人数 = 3
原来的生产率 = 3000 LOC/月
原来的时间 = 1 月(假设)
所以,原来的工作量 = 3 * 3000 * 1 = 9000 LOC
然后,我们需要知道原来的通信路径上的生产率开销,以及加入两个人后的通信路径上的生产率开销。我们可以用以下公式来计算:
通信路径上的生产率开销 = 通信路径数 * 每条通信路径上的生产率开销
通信路径数 = (人数 * (人数 - 1)) / 2
每条通信路径上的生产率开销 = 300 LOC/月
所以,原来的通信路径上的生产率开销 = (3 * (3 - 1)) / 2 * 300 = 900 LOC
加入两个人后的通信路径上的生产率开销 = (5 * (5 - 1)) / 2 * 300 = 3000 LOC
接下来,我们需要知道加入两个人后的总工作量,以及他们能够赶上进度所需的时间。我们可以用以下公式来计算:
总工作量 = 原来的工作量 + 原来的通信路径上的生产率开销 - 加入两个人后的通信路径上的生产率开销
所需时间 = 总工作量 / (加入两个人后的人数 * 加入两个人后的生产率)
所以,总工作量 = 9000 + 900 - 3000 = 6900 LOC
所需时间 = 6900 / (5 * 加入两个人后的生产率)
为了使得小组能够赶上进度,所需时间必须小于或等于1个月,即:
6900 / (5 * 加入两个人后的生产率) <= 1
解得:
加入两个人后的生产率 >= 1380 LOC/月
因此,这道选择题中正确答案是D。
72、团队正在开发一个智慧停车场系统,结合团队实际情况,其中一个风险为:原定复用的构件必需要自行开发,且该风险发生的概率为60%。假设该项目需要复用40个构件,每个构件预估的代码行为200 LOC,每代码行成本为15 元/LOC。则针对此风险的RE是( D )。
A、1800
B、120000
C、48000
D、72000
针对风险的RE(Risk Exposure)是根据风险概率和风险影响来计算的。在这种情况下,风险是原定复用的构件必需要自行开发,且该风险发生的概率为60%。
首先,计算风险发生的影响:
影响 = 复用构件数量 * 每个构件的代码行数 * 每代码行的成本
影响 = 40 * 200 LOC * 15 元/LOC = 120,000 元然后,计算风险的RE:
RE = 风险概率 * 影响
RE = 0.6 * 120,000 元 = 72,000 元因此,针对该风险的RE为72,000 元。
名词解释
1、RMMM
RMMM代表着风险识别、风险缓解、风险监控、风险管理。它是软件工程中风险管理的一种方法。
RMMM是一种系统化的方法,用于识别、评估和管理软件项目中的风险。以下是RMMM方法中的各个步骤的解释:
风险识别:识别可能会对项目成功产生负面影响的风险因素。这包括确定项目中的潜在风险和问题,并记录它们的性质、原因和可能性。
风险缓解:采取措施来减轻或消除已识别的风险。这包括制定风险规避策略、制定预防措施和采取纠正行动,以降低风险发生的可能性。
风险监控:持续监控和评估已经识别的风险。这包括定期检查风险的状态和进展,以及识别新的风险因素。
风险管理(Risk Management):管理风险管理计划的执行和结果。这包括跟踪风险规避和缓解措施的效果,更新风险登记册,并及时采取必要的纠正措施。
通过使用RMMM方法,软件项目团队能够更好地管理和应对项目中的风险。它有助于提早识别潜在风险,并采取适当的措施来减轻风险对项目进展和质量的影响。风险管理的有效实施可以提高项目成功的机会,并增加项目交付的可靠性和可预测性。
2、统一过程
统一过程(Unified Process)是一种软件开发过程框架,也被称为统一软件开发过程(Unified Software Development Process)。它是一种基于对象和迭代的软件开发方法论,强调逐步、逐层地构建软件系统。
统一过程是一种使用案例驱动的、以风险为导向的迭代开发方法。它提供了一套结构化的、可定制的开发过程指导,旨在帮助开发团队在软件开发的各个阶段进行有效的规划、分析、设计、实施和测试。
统一过程将软件开发过程分为一系列迭代周期,每个迭代周期都包含需求分析、设计、编码和测试等活动。每个迭代周期都会生成一个可执行的软件增量,并通过用户反馈和评审来进行验证和修正。
统一过程强调在开发过程中的模型驱动方法,包括用例模型、分析模型、设计模型和实现模型等。它还提供了一系列工件(Artifacts)和角色(Roles),用于帮助开发团队进行交流和合作。
统一过程的核心原则包括:迭代与增量、风险驱动、架构为中心、模型驱动和持续验证等。它的目标是在迭代的过程中不断提高软件系统的质量、可扩展性和可维护性。
总结来说,统一过程是一种基于对象和迭代的软件开发过程框架,它强调以案例驱动的、风险导向的迭代开发方法。它提供了一套结构化的开发过程指导,帮助开发团队在软件开发过程中进行规划、分析、设计、实施和测试。统一过程的核心原则包括迭代与增量、风险驱动、架构为中心、模型驱动和持续验证。
3、依赖倒置原则
依赖倒置(Dependency Inversion)是软件设计中的一项原则,用于解决模块或类之间的依赖关系,以提高代码的可扩展性和灵活性。
依赖倒置原则的核心思想是:高层模块不应该依赖于低层模块,而是二者都应该依赖于抽象接口。简而言之,它要求我们通过抽象来定义模块之间的依赖关系,而不是依赖具体的实现。
具体来说,依赖倒置原则主要包括以下几个关键概念:
高层模块和低层模块之间的关系反转:传统的设计中,高层模块依赖于低层模块,而依赖倒置原则要求这种关系反转,即高层模块和低层模块都依赖于抽象接口。
抽象接口的定义:通过定义抽象接口,将高层模块与低层模块解耦。高层模块只依赖于抽象接口,而不依赖于具体的实现。这样,当需要更换或扩展低层模块时,只需要保持抽象接口的一致性,而不需要修改高层模块。
依赖注入:依赖倒置原则通常与依赖注入(Dependency Injection)相结合使用。依赖注入是一种将依赖关系从高层模块传递给低层模块的机制,可以通过构造函数、参数、属性等方式来实现。
通过应用依赖倒置原则,可以实现代码的松耦合和高内聚性,提高代码的可扩展性和灵活性。它促进了代码的可测试性和可维护性,使系统更易于理解和修改。
总结来说,依赖倒置原则是一种通过反转高层模块和低层模块之间的依赖关系,以抽象接口解耦的设计原则。它通过依赖注入实现依赖关系的传递,提高代码的可扩展性和灵活性,增强了系统的可测试性和可维护性。
4、重构
重构(Refactoring)是软件开发中的一项技术和过程,旨在改进现有代码的设计、结构和可读性,而不改变其外部行为。
重构是一种有计划的代码更改过程,旨在改进代码的质量和可维护性,使其更易于理解、扩展和修改。通过重构,开发人员可以通过一系列小步骤来逐渐改进代码,而不是进行大规模的重写或修改。
重构的目标是改进代码的内部结构,减少重复代码、提高代码的可复用性、简化复杂的逻辑等。重构的过程中,不会添加新功能或修改代码的外部行为,只关注代码的内部结构和质量。
重构的常见操作包括提取方法、内联方法、重命名变量、消除重复代码、简化条件表达式等。这些操作通常是基于开发人员的经验和最佳实践,旨在改进代码的可读性、可维护性和性能。
重构是一项持续的活动,可以在软件开发的任何阶段进行。它可以由个人开发者或开发团队共同进行,并可以在版本控制系统的支持下进行追踪和管理。
总结来说,重构是一种通过有计划的代码更改过程来改善现有代码的设计、结构和可读性的技术和过程。它旨在改进代码的内部质量,使其更易于理解、扩展和修改,而不改变其外部行为。重构是持续进行的活动,可以在软件开发的任何阶段进行。
5、CRC
CRC 是软件工程中的一种需求分析技术,它是"Class, Responsibilities, and Collaborators"(类、职责和协作者)的缩写。
CRC 卡是一种用于描述类的简单工具,通过将系统中的类进行分析和组织,帮助团队理清类之间的关系和职责。每张 CRC 卡都代表一个类,上面记录了该类的名称、职责和与其他类之间的协作关系。
在使用 CRC 技术时,团队成员可以根据需求和系统设计的初步理解,编写一张张 CRC 卡,用于描述系统中的各个类。每张 CRC 卡上的内容通常包括:
- 类的名称:表示所描述的类的名称。
- 类的职责:描述该类负责的任务和功能。
- 协作者:列出与该类进行交互的其他类。
通过创建和分析 CRC 卡,团队可以更好地理解系统的组成部分,识别类的职责和关系,以及确保类之间的合作和协作。这有助于发现潜在的设计问题、确保类的功能和职责的清晰性,以及促进团队成员之间的交流和合作。
总结来说,CRC 是一种需求分析技术,通过使用 CRC 卡来描述类的职责和协作关系,帮助团队理清类之间的关系和职责,从而促进系统设计和开发过程的顺利进行。
6、接口分离
接口分离是软件工程中的一个设计原则,它强调将庞大而复杂的接口分解为更小、更具体的接口,以满足客户或模块的特定需求。接口分离原则主要是为了实现高内聚性和低耦合性。高内聚性指一个模块或类应该有且只有一个明确的职责,而低耦合性指模块或类之间的依赖关系应该尽可能地减少。
通过将庞大的接口拆分为更小的、更专注的接口,接口分离可以实现以下几个方面的好处:
减少对不需要的功能的依赖:当一个接口包含过多的方法时,客户端或使用该接口的模块可能会对不需要的功能产生依赖。通过接口分离,可以将接口细分为多个更具体的接口,使得客户端或模块只需要依赖其真正需要的接口,减少了不必要的依赖关系。
提高模块或类的可扩展性:当需要对系统进行扩展或修改时,如果接口过于庞大,可能会影响到整个系统的稳定性和维护性。通过接口分离,可以将变化的部分隔离出来,使得系统的扩展性更好,更容易进行修改和维护。
提升代码的可读性和可理解性:拆分庞大的接口为更小的接口,可以使代码更加清晰、简洁,易于理解和阅读。每个接口都具有明确的职责,使得代码结构更加清晰明了。
总而言之,接口分离原则强调将庞大的接口拆分为更小、更具体的接口,以实现高内聚性和低耦合性。这样可以减少不必要的依赖关系,提高系统的可扩展性,以及提升代码的可读性和可理解性。
7、α测试(Alpha Testing)
α测试是软件开发过程中的一项测试活动,它是在软件开发的早期阶段由开发者进行的测试。
α测试是在软件开发过程中的一个内部测试阶段,通常在软件的开发初期或中期进行。它的主要目标是发现和修复软件中的缺陷、错误和问题,以确保软件的功能和性能达到预期。
α测试主要由软件开发团队来执行,他们会使用各种测试方法和技术,包括功能测试、性能测试、兼容性测试等,来评估软件的可靠性、稳定性和正确性。
在α测试中,测试人员会在开发环境中模拟真实的使用场景,对软件进行全面的测试,并记录发现的问题和缺陷。开发团队会根据测试结果进行改进,以确保软件在进入下一阶段之前达到高质量的状态。
α测试主要针对软件的内部质量进行测试,着重发现和解决软件中的功能性缺陷和逻辑错误。它有助于提高软件的质量、稳定性和用户满意度,为软件的下一阶段测试和交付做好准备。
总结来说,α测试是软件开发过程中的一项内部测试活动,由开发者或内部测试团队执行,旨在发现和修复软件中的缺陷和错误,以确保软件达到预期的功能和性能要求。
8、信息屏蔽(informetion hiding)
信息屏蔽是指将模块或对象的内部细节和实现细节隐藏起来,仅向外部提供必要的接口和信息。
信息屏蔽的目的是实现模块间的独立性和封装性,以便提高软件的可维护性和可扩展性。通过隐藏内部细节,可以使模块之间的耦合度降低,使得每个模块可以独立开发、测试和修改,而不会对其他模块产生影响。
通过定义清晰的接口和隐藏内部实现细节,信息屏蔽还可以提供对外部用户的抽象,使用户只需关注模块或对象的功能和使用方法,而不需要了解其内部的复杂实现过程。
信息屏蔽常常与面向对象编程(OOP)的封装性原则相结合,通过将数据和操作封装在对象内部,并提供公共接口,来实现对信息的屏蔽和保护。
总之,信息屏蔽是软件工程中的一种设计原则,通过隐藏模块或对象的内部细节和实现细节,提高软件的模块独立性、封装性和可维护性。
9、OCP
OCP代表开闭原则(Open-Closed Principle),是面向对象设计中的一项重要原则。
开闭原则指导软件设计时,一个实体(类、模块、函数等)应该对扩展开放,对修改关闭。简单来说,它要求设计应该是可扩展的,而不是修改现有的代码。
开闭原则的核心思想是通过抽象和多态来实现可扩展性。它鼓励使用接口、抽象类和多态等技术,以确保系统的扩展性和灵活性,同时尽量避免对现有代码的修改。
遵循开闭原则的设计可以带来以下好处:
可扩展性:通过添加新的功能或模块,而不需要修改现有代码,实现系统的可扩展性。
可维护性:由于开闭原则避免了频繁的修改现有代码,系统的维护变得更加容易。
可复用性:通过提取公共接口和抽象类,使得代码更具通用性和可复用性。
可测试性:由于对现有代码的修改被限制在最小范围内,测试新功能或模块变得更加简单和可靠。
在实际设计中,遵循开闭原则需要合理地使用继承、多态、接口和抽象类等技术,通过定义适当的接口和抽象层次结构,以及使用设计模式等方法来实现系统的可扩展性和可维护性。
总结来说,开闭原则是面向对象设计的一项重要原则,要求设计应该对扩展开放,对修改关闭。它通过抽象和多态等技术来实现系统的可扩展性和灵活性,从而提高系统的可维护性、可复用性和可测试性。
10、功能独立
功能独立是指软件系统中的各个功能模块或组件能够独立地完成其所需的功能,而不依赖于其他模块的存在或状态。
在软件开发中,将系统的功能划分为独立的模块或组件具有多个好处:
模块化:将系统的功能划分为独立的模块或组件,使得系统的复杂性得到了分解和管理。每个模块只关注自身的功能,降低了模块之间的耦合性,便于单独开发和维护。
可复用性:独立的功能模块可以在不同的项目或系统中被重复利用。这种模块的独立性使得它们更容易被移植和集成到其他系统中,提高了系统的可复用性和可扩展性。
并行开发:功能独立的模块可以被不同的开发团队同时开发,提高了开发效率。每个团队可以专注于开发自己负责的模块,而不会受到其他模块的影响。
测试和调试:功能独立的模块可以被单独地测试和调试,减少了测试和调试的复杂性。每个模块的测试可以独立进行,从而更容易定位和解决问题。
功能独立的设计原则是将系统的功能划分为独立的、可测试的模块或组件,每个模块都有清晰的责任和功能边界。通过良好的功能独立设计,可以提高软件系统的可维护性、可扩展性和可复用性,同时降低开发和维护的风险和成本。
11、软件生命(生存)周期(software life cycle)
软件生命周期(software life cycle)是指从软件的概念和规划阶段开始,通过开发、测试、部署、维护和退役等一系列阶段,直到软件被完全废弃或替换的过程。软件生命周期的目的是管理和控制软件开发过程,确保软件按照预期的要求、质量标准和时间表进行开发和交付。
软件生命周期通常包括以下主要阶段:
需求分析和规划阶段:确定软件的需求、范围、目标和约束条件,进行项目规划和资源分配。
设计阶段:根据需求分析阶段的结果,设计软件的架构、模块和功能,并制定详细的设计文档。
编码和开发阶段:根据设计阶段的要求,编写软件代码,进行单元测试和集成测试。
测试阶段:对开发完成的软件进行系统测试、性能测试、安全测试和用户验收测试等,以确保软件的质量和功能符合要求。
部署和发布阶段:将测试通过的软件部署到目标环境中,进行安装、配置和用户培训等,以准备正式投入使用。
运行和维护阶段:在软件投入使用后,持续监控和维护软件,修复漏洞、改进功能,并提供技术支持和用户服务。
退役阶段:当软件不再需要或被替换时,进行软件的退役和废弃处理,包括数据迁移、文档归档和资源释放等。
软件生命周期的不同阶段通常涉及不同的活动、角色和工具,以确保软件开发和维护过程的可控性、可重复性和高质量性。
简答题
1、某公司的软件产品以开发实验型的新软件为主。用瀑布模型进行软件开发已经有近十年了,并取得了一些成功。若你作为一名管理员刚加入该公司,你认为快速原型法对公司的软件开发更加优越,你要怎么说服老板换成原型开发模型?
1、了解老板的关注点:在与老板进行沟通之前,了解他们对软件开发的关注点和期望是非常重要的。这可以帮助你根据他们的需求和优先事项来展示原型开发模型的优势。
2、准备充分的信息:收集有关原型开发模型的相关信息,并与瀑布模型进行比较。准备一些案例研究或成功故事,说明原型开发模型在其他组织中的优势,如加快开发速度、提高用户参与度、降低错误成本等。
3、强调灵活性和迭代:原型开发模型具有快速迭代的特点,可以更快地响应用户的反馈和变更请求。强调这种迭代过程可以在开发早期阶段发现和解决问题,从而减少后期修复成本。
4、强调用户参与和反馈:快速原型法鼓励用户的参与和反馈,可以帮助开发团队更好地理解用户需求,从而提供更符合用户期望的软件产品。说明通过原型开发模型可以更好地满足用户需求,增加用户满意度和产品市场竞争力。
5、提供风险管理策略:老板可能会关心风险管理方面,因此,在沟通中要强调原型开发模型对风险管理的好处。快速原型法可以在开发早期阶段识别和解决问题,减少项目失败的风险,并提供更准确的时间和成本估计。
6、提供试点项目:如果老板对切换到原型开发模型还有疑虑,你可以建议进行一个试点项目,以验证原型开发模型的有效性。选择一个小型项目,应用原型开发模型进行开发,并在项目完成后评估结果和收益。
2、某公司负责实现运行商携号转网的一部分功能,如果你是项目经理你要怎么安排?从软件规模,软件范围,质量保证,风险管理等角度进行分析。
1、软件规模:首先,需要对软件规模进行评估,确定项目的整体规模和范围。这可以通过需求分析和功能规格说明书来完成。根据业务需求和资源限制,确定项目的开发时间、团队规模、人力资源需求等。
2、软件范围:明确实现携号转网功能的软件范围,包括定义功能边界、系统接口、用户界面等。在与业务方和相关利益相关者的沟通中,明确功能需求、非功能需求和技术限制,确保软件开发的目标明确,并与利益相关者达成共识。
3、质量保证:需要制定适当的质量保证计划来确保软件的质量。这包括制定测试策略、测试计划和测试用例,以确保软件在各个阶段都能满足质量要求。同时,建立代码审查和单元测试的机制,以及进行系统集成测试和用户验收测试,以确保软件的功能完整性和稳定性。
4、风险管理:在项目中,风险管理是至关重要的。需要对潜在风险进行识别、评估和应对计划的制定。针对潜在风险,可以采取预防措施、应急计划和风险转移等策略。同时,建立有效的沟通渠道,及时识别和解决风险,确保项目进展顺利。
5、除了上述方面,还需要考虑项目资源管理、进度管理、沟通管理等方面的安排,以确保项目的顺利实施和交付。
3、请简要说明你对顺序图和状态图使用的看法?
顺序图(Sequence Diagram):
顺序图主要用于描述系统中对象之间的交互和消息传递顺序。它展示了对象之间的时序关系,有助于理解系统的行为和交互流程。
顺序图适用于以下情况:
- 显示对象之间的消息传递和交互顺序,可以帮助捕捉系统的时序逻辑。
- 描述用例场景或特定操作的流程,以便识别参与者和对象之间的交互。
- 强调时间和顺序对系统行为的影响。
状态图(State Diagram):
状态图主要用于描述系统或对象的状态和状态之间的转换。它展示了对象在不同状态下的行为和响应,以及导致状态转换的事件和条件。
状态图适用于以下情况:
- 描述对象的生命周期和状态转换,特别适用于具有复杂状态和状态变化的系统。
- 显示系统的不同状态和状态之间的转换条件,有助于识别系统的行为和响应。
- 捕捉对象或系统的状态行为和约束,以便更好地设计和实现系统。
综上所述,顺序图和状态图在软件系统建模中起着不同的作用。顺序图主要关注对象之间的交互和消息传递顺序,而状态图主要关注对象的状态和状态之间的转换。选择使用哪种图取决于想要描述的系统行为和需求,以及希望强调的方面。通常,在系统设计和开发过程中,这两种图经常结合使用,以提供更全面和准确的系统模型。
4、请简要描述三个适于采用瀑布模型的软件项目。
传统的桌面应用程序:对于传统的桌面应用程序,通常具有明确的功能需求和固定的技术环境。这种项目通常遵循传统的软件开发生命周期,并且在项目开始之前能够明确定义所有的功能和规范。瀑布模型可以帮助团队在每个阶段有序地进行设计、开发和测试。
嵌入式系统开发:嵌入式系统往往需要与硬件进行密切集成,其开发过程需要严格的计划和预测。在这种情况下,瀑布模型可以帮助团队在每个阶段有序地完成需求分析、设计、编码和测试,并最终交付一个完整且稳定的嵌入式系统。
传统的企业级软件开发:某些企业级软件项目对于稳定性和可靠性的要求较高,而且对于变更的容忍度相对较低。这些项目通常有明确的业务需求和规范,并需要按计划进行开发和交付。在这种情况下,瀑布模型可以帮助团队按照预定的计划进行逐个阶段的开发和测试,确保项目按时交付。
5、请简要描述三个适于采用原型模型的软件项目。
用户界面设计:原型模型在用户界面设计方面非常有用。当需要开发一个用户友好、易用的界面时,原型模型可以帮助设计团队更好地理解用户需求并快速验证不同设计概念。通过创建和迭代原型,设计团队可以与用户进行频繁的交互和反馈,以确保最终的用户界面符合用户期望和需求。
前沿技术和创新项目:原型模型适用于前沿技术和创新项目的开发。这些项目通常具有高度的不确定性和变动性,难以明确定义和预测最终产品的形态和功能。通过使用原型模型,团队可以快速建立原型来验证新技术的可行性、用户反馈和市场需求,以便在后续开发阶段进行相应调整和优化。
需求不明确或频繁变化的项目:当项目需求不够明确或经常发生变化时,原型模型是一种有效的开发方法。原型模型允许团队快速构建和演示原型,以便客户或利益相关者提供及时反馈。通过不断迭代和增量开发原型,团队能够更好地理解需求并及时适应变化,从而减少后续开发阶段的风险和错误。
6、用自己的话描述(用于软件项目的)敏捷性。
敏捷性是一种软件开发方法论,旨在通过迭代和增量的方式开发软件项目。它强调灵活性、快速响应变化和高度合作的团队工作。
敏捷性的特点包括以下几个方面:
- 迭代开发:敏捷方法采用迭代开发的方式,将项目分解为多个短期的开发周期,每个周期称为一个迭代。每个迭代都会产生可用的软件部分,可以进行测试和验证。这种迭代的开发方式可以更好地应对需求变化和项目风险。
- 增量交付:敏捷方法强调每个迭代都要交付可用的软件增量,而不是等待整个项目完成后才交付。这使得客户能够尽早地获得软件的价值,并提供快速反馈,从而指导后续的开发工作。
- 灵活性和适应性:敏捷方法鼓励团队在开发过程中灵活应对变化。当需求或市场情况发生变化时,团队可以及时作出调整,重新规划迭代和优先级,以确保软件始终符合最新的需求。
- 高度合作的团队:敏捷方法注重团队合作和沟通。开发团队与业务代表、用户和利益相关者密切合作,以确保开发出满足需求的软件。团队成员之间的密切协作和信息共享是敏捷方法成功的关键。
- 持续改进:敏捷方法鼓励团队在开发过程中进行持续改进。通过定期回顾和反思,团队可以识别问题和改进机会,并采取相应的行动来提高开发效率和质量。
总体而言,敏捷性在软件项目中提供了一种迭代、灵活和协作的开发方法,旨在满足客户需求、快速响应变化,并持续改进软件开发过程。
7、请你谈谈你对敏捷开发的认识。
敏捷开发是一种迭代、增量的软件开发方法,强调通过快速响应变化、灵活应对需求,实现高质量的软件交付。以下是我对敏捷开发的认识:
迭代和增量开发:敏捷开发采用迭代和增量的方式进行开发,将整个开发过程分成多个短期的迭代周期。每个迭代周期内,团队集中精力完成一部分功能,并进行测试和验证。每个迭代周期的结果是一个可交付的、经过测试的软件增量,使得客户可以及时地审查和反馈。
快速响应变化:敏捷开发鼓励面对变化,迎接客户需求的变化。它通过频繁的迭代和交互,及时获取用户反馈,以便及时调整项目方向和优先级。敏捷开发注重灵活性和适应性,可以更好地应对需求的变化和市场的变化。
自组织和跨功能团队:敏捷开发倡导自组织的团队和跨功能的团队合作。团队成员具备多种技能,可以跨越职能边界,共同完成项目的各项任务。团队成员之间密切合作,通过面对面的沟通和协作,实现高效的软件开发。
高度用户参与:敏捷开发强调用户的参与和反馈。用户作为项目的利益相关者,与开发团队紧密合作,提供清晰的需求和反馈。用户参与可以帮助团队更好地理解用户需求,减少沟通误差,并及时调整开发方向。
持续交付和持续集成:敏捷开发强调持续交付和持续集成的原则。团队通过频繁的集成和测试,确保软件质量,减少集成和发布的风险。持续交付使得软件可以更快地交付给用户,实现快速价值的实现。
总的来说,敏捷开发是一种注重灵活性、迭代和增量的软件开发方法。它强调快速响应变化、高度用户参与和持续交付,通过团队的自组织和跨功能合作,以及频繁的迭代和交互,实现高质量的软件交付。敏捷开发适用于需求变化频繁、市场竞争激烈的项目,可以帮助团队更好地应对变化和快速交付有价值的软件产品。
8、简述瀑布模型的定义,特点和适用场合
瀑布模型是一种经典的软件开发过程模型,它以线性顺序的方式进行软件开发,包括一系列连续且有序的阶段,每个阶段的输出作为下一个阶段的输入。下面是对瀑布模型的定义、特点和适用场合的简述:
定义:
- 瀑布模型是一种顺序进行的软件开发过程模型,按照预定的顺序依次执行需求分析、系统设计、编码、测试和维护等阶段,每个阶段的输出作为下一个阶段的输入。这意味着在开始下一个阶段之前,必须完成上一个阶段的工作。
特点:
- 阶段性:瀑布模型将软件开发过程划分为明确定义的阶段,每个阶段都有特定的目标和交付物。
- 顺序性:瀑布模型要求各个阶段按照固定的顺序依次执行,前一阶段完成后才能进入下一阶段。
- 文档驱动:瀑布模型注重详细的文档编写,每个阶段都有相应的文档作为输出和记录。
- 刚性和预测性:瀑布模型在项目开始时就需要明确的计划和需求,较为刚性,难以适应需求变化。
适用场合:
瀑布模型适用于以下场合:
- 需求相对稳定:适用于需求相对稳定、明确且变动不大的项目,不太适应频繁的需求变更。
- 小规模项目:适用于相对较小且简单的项目,开发过程相对简单和直观。
- 需要详尽文档记录:适用于对文档编写和记录要求较高的项目,对软件需求、设计和测试等有严格的文档要求。
需要注意的是,瀑布模型在应对需求变化、灵活性和快速交付等方面存在一些局限性,因此在实际应用时需要综合考虑项目的特点和需求来选择合适的软件开发过程模型。
9、你被要求负责一个开发软件产品的商业项目,该项目有明确的需求和完成时限,各种人力资源、软硬件资源都已经确定。但你和项目组的成员经过详细的估算后发现在项目中现有的约束条件(需求、人员、进度)下根本无法按时、保证完成项目。请问你现在有哪几种选择。请分析你做这些选择的理由和优缺点。
在面对这种情况时,可能有以下几种选择:
重新评估和调整项目计划:你可以重新评估项目计划,并尝试调整需求、资源分配或进度安排,以减少项目的范围或延长时间表。这样做的理由是通过重新规划项目,有可能在现有的约束条件下更好地满足项目要求。优点是可以提供更现实的项目计划,并减轻团队压力;缺点是可能会导致项目范围缩减或时间延长,可能不符合初期的预期。
增加资源或外包:你可以寻求增加人力资源或外包一部分工作,以增强团队的能力和效率。这样做的理由是通过增加资源,可以更好地满足项目的要求并加快开发速度。优点是可以提供更多的人力资源,加快项目进展;缺点是可能需要额外的成本投入,并且需要管理外包团队的协调与沟通。
与利益相关者沟通并重新协商项目要求:你可以与项目的利益相关者进行沟通,并重新协商项目的要求和交付期限。这样做的理由是通过重新协商,可以调整项目的目标和约束条件,以达到更合理的目标。优点是可以为项目提供更合理的期望,并减轻团队的压力;缺点是可能需要妥协一些项目要求,并与利益相关者进行复杂的谈判和沟通。
延期或取消项目:如果在评估后发现无法在现有的约束条件下完成项目,并且其他选择都不可行,你可能需要考虑延期项目或取消项目。这样做的理由是项目目前的约束条件无法满足要求,延期或取消可能是避免更大风险和损失的最佳选择。优点是可以避免项目失败或质量问题;缺点是可能会损失已经投入的资源和努力,并对利益相关者产生不良影响。
选择哪种方案取决于项目的具体情况和你对风险的评估。在做出选择时,应该综合考虑项目的目标、质量、利益相关者的期望以及团队的能力和资源情况。还应该与项目组成员、利益相关者进行充分的沟通和讨论,以便做出明智的决策,并采取适当的行动来解决项目的困境。
10、什么是黑盒测试法?
黑盒测试法(Black-box testing)是一种软件测试方法,其中测试人员不考虑内部实现细节和代码逻辑,而是基于软件的输入和输出来评估软件的功能和性能。在黑盒测试中,测试人员将软件视为一个黑盒子,只关注输入和输出之间的关系,而不需要了解内部的工作原理。
黑盒测试方法主要关注以下方面:
功能测试:验证软件是否按照需求规格说明书中规定的功能工作,检查输入数据是否能产生正确的输出结果。
边界值测试:测试软件在边界条件处的行为,包括最小值、最大值、临界值和非法值等。
错误处理测试:测试软件对于错误和异常情况的处理能力,包括错误提示、恢复机制和日志记录等。
性能测试:评估软件在不同负载和压力条件下的性能和响应时间。
用户界面测试:验证软件的用户界面是否符合设计要求,是否易于使用和导航。
通过黑盒测试,可以发现软件中的功能缺陷、逻辑错误、接口问题和性能瓶颈等。这种测试方法不需要了解软件的内部实现细节,更侧重于对软件功能和外部行为的评估。因此,黑盒测试可以由测试人员独立进行,不依赖于开发人员的知识或代码的访问权限。
11、什么是白盒测试法?
白盒测试法(White-box testing)是一种软件测试方法,其中测试人员具有对软件内部结构和代码的详细了解,并使用这些知识来设计测试用例和评估软件的功能和质量。
在白盒测试中,测试人员可以查看软件的内部逻辑、数据结构和算法,以了解程序是如何处理输入并生成输出的。测试人员可以直接访问源代码、控制流程图和数据流图等开发文档,以及使用调试工具和技术来检查软件的执行过程。
白盒测试方法主要关注以下方面:
语句覆盖:确保测试用例能够覆盖软件中的每个语句。
判定覆盖:测试用例能够覆盖每个判断条件的所有可能结果。
路径覆盖:测试用例能够覆盖软件中的每条可能路径。
条件覆盖:测试用例能够覆盖每个条件的所有可能取值。
通过白盒测试,可以检测软件中的逻辑错误、数据错误、控制流错误和性能问题等。白盒测试依赖于对软件内部实现的详细了解,因此通常由开发人员或具有开发背景的测试人员执行。白盒测试可以在软件开发的早期阶段进行,帮助开发人员及时发现和修复问题,提高软件的质量和可靠性。
12、以下是三个类的代码片段,请根据代码信息,说说在 RootedTreeClass 类已经通过测试的情况下,BinaryTreeClass 和 BalanceBinaryTreeClass 该如何测试。
class RootedTreeClass
{ ...
void displayNodeContents(Node a);
void printRoutine(Node b);
//...
}
class BinaryTreeClass extends RootedTreeClass
{ ...
void displayNodeContents(Node a);
//...
}
class BalanceBinaryTreeClass extends BinaryTreeClass
{ ...
void printRoutine(Node b);
//...
}
根据代码片段提供的信息,可以进行以下测试:
BinaryTreeClass 的测试:
由于 BinaryTreeClass 是 RootedTreeClass 的子类,并继承了 displayNodeContents(Node a) 方法,可以针对该方法进行测试,以确保在 BinaryTreeClass 中的实现是否正确。测试时可以创建一个 BinaryTreeClass 的实例,调用 displayNodeContents(Node a) 方法,并验证输出结果是否符合预期。BalanceBinaryTreeClass 的测试:
BalanceBinaryTreeClass 是 BinaryTreeClass 的子类,并继承了 printRoutine(Node b) 方法。在测试 BalanceBinaryTreeClass 时,需要对 printRoutine(Node b) 方法进行测试,以验证其在 BalanceBinaryTreeClass 中的实现是否正确。测试时可以创建一个 BalanceBinaryTreeClass 的实例,调用 printRoutine(Node b) 方法,并检查输出结果是否符合预期。需要注意的是,由于 BalanceBinaryTreeClass 是 BinaryTreeClass 的子类,而 BinaryTreeClass 又是 RootedTreeClass 的子类,所以在测试 BalanceBinaryTreeClass 时,也应该考虑继承自父类的方法和功能是否正常工作。可以选择一些典型的测试用例,对继承自父类的方法进行测试,以确保继承关系的正确性。
总结:在已经通过测试的情况下,针对 BinaryTreeClass 和 BalanceBinaryTreeClass,主要测试继承自父类的方法的正确性。对于 BinaryTreeClass,测试 displayNodeContents(Node a) 方法;对于 BalanceBinaryTreeClass,测试 printRoutine(Node b) 方法,并确保继承关系的正确性。
13、公司了解到客户需求不明确,在签订合同时故意提出一个低报价,待客户将来提出需求变更时再索要高价。你认为这样做道德吗?
需求管理:软件工程的一个重要方面是需求管理,确保准确理解和明确客户的需求。在这种情况下,公司故意提出低报价,暗示满足客户需求,但实际上意图在未来变更需求时索要高价。这种欺骗行为会导致需求不明确,增加开发团队的工作量和风险,可能会导致项目延迟或失败。
伦理和职业道德:软件工程师应该遵守伦理和职业道德准则。这包括诚实、透明和公正地与客户和利益相关者合作。提出低报价然后在未来变更需求时索要高价是不诚实和不公正的行为,违背了软件工程师的职业道德准则。
项目管理:在软件项目中,良好的项目管理是确保项目成功的关键。提供准确的成本估计和合理的定价对于项目的成功非常重要。故意提出低报价可能导致项目的预算不足,无法满足客户的期望,并可能导致项目失败。
风险管理:软件工程包括对项目风险的管理和评估。故意提出低报价然后索要高价会增加项目的风险,可能导致不满意的结果和客户不满。
14、“2022年全国多地出现的本土新冠肺炎确诊病例,依旧时刻年动着大众的心,疫情这三年,在缺乏新冠特效药,仅以疫苗和核酸撑起全民防疫的时间里,“隔离”,“保持距离”、“外出戴口罩”等,都在强调一种防范措施:减少与病毒的正面对抗。5月25日,人工智能制药公司英矽智能(Insilico Medicine)宣布,凭借其AI平台,发现了一款就向主蛋白酶(3CL)的全新临床前候选药物,用于治疗新型冠状病毒引起的肺炎。作为人工智能制药领域的明星企业,英矽智能自2021年以来已经发现了8款临床前候选药物。成为国内为数不多的将研发项目推进到临床阶段的AI制药公司。目前,英矽智能上海JLABs的生物学实验室,主攻靶点验证。苏州也正在建设英砂智能的智能机器人实验室,将最大限度实现湿实验自动化,为靶点发现以及化合物筛选提供高效的实验验证。而实验中收集到的数据,也将被处理分析,促进Al平台的迭代。
正如英砂智能创始人兼首席执行官 Alex Zhavoronkov 博士表示,“疫情大流行的背景下,全球都在关注快速开发新冠药物的迫切医疗需求。我们在疫情早期就下定决心要推进新冠药物的研发,期待与学术界和产业界联动,展示AI工具在人类与疾病斗争中的强大力量。”
阅读上述材料:
(1)社会、健康、安全、环境、法律、文化等现实元素将对软件项目产生深远影响,谈谈你对这个项目可行性的理解。
(2)若你是这个利用AI平台研制靶向药物分子式项目的负责人,团队积累了大量的案研数据集用于AI算法的训练学习,项目是研究和探索性质的,预计在一年后能够形成优化后的产品。请问你会以何种方式组织你的团队成员?为什么?
(1) 这个项目可行性的理解:
该项目是利用人工智能平台进行新冠肺炎药物研发的探索性项目。考虑到社会、健康、安全、环境、法律、文化等现实元素对软件项目的影响,以下是对项目可行性的理解:
- 社会影响:疫情对全球社会造成了巨大的影响,对新冠药物的需求迫切。该项目可以为社会提供一种新的药物研发方法,可能对抗疫情产生积极的社会影响。
- 健康影响:新冠肺炎对全球人类健康构成了严重威胁。该项目旨在研发治疗新冠肺炎的药物,如果成功,将对健康产生积极影响,降低患者病情严重程度和死亡率。
- 安全影响:在药物研发过程中,确保药物的安全性是至关重要的。项目需要遵守相关法律法规和伦理准则,确保药物的安全性和有效性。
- 环境影响:项目本身在软件开发和数据处理过程中不会对环境产生直接影响。然而,在实验室阶段可能需要使用化学试剂和生物材料,需要遵守环境保护的相关规定和标准。
- 法律影响:药物研发涉及众多法律方面的规定,包括知识产权、临床试验、药物注册等。项目需要遵守国家和地区的相关法律法规,确保合规性和合法性。
- 文化影响:不同地区对药物研发和使用有不同的文化和习俗。项目需要充分尊重和考虑当地文化的特点,与相关利益相关者进行合作,确保项目在文化层面上的可行性。
综上所述,项目的可行性取决于多个方面的影响因素,包括社会、健康、安全、环境、法律和文化等现实元素。团队需要全面评估这些因素,确保项目在各方面具备可行性。
(2) 若我是这个利用AI平台研制靶向药物分子式项目的负责人,我会采取以下方式组织团队成员:
跨学科团队:由具有不同专业背景和技能的成员组成,包括药学、生物学、计算机科学等领域的专家和研究人员。这样的团队可以充分发挥各自的专业优势,在不同领域之间进行合作和知识交流。
AI算法专家:团队需要拥有具备深度学习和人工智能算法方面的专家,能够熟练应用AI算法进行数据分析和模型训练。他们可以负责开发和优化AI算法,以支持药物分子式的预测和筛选工作。
实验室研究人员:在药物研发过程中,需要进行实验室实验验证。团队应该有一支实验室研究人员团队,负责样本采集、生物实验和数据收集。他们将协助AI算法的训练和验证,并确保实验过程的合规性和准确性。
临床专家:在项目进展到临床阶段时,需要有临床专家加入团队。他们可以提供临床实践的经验和指导,确保药物研发符合临床要求和标准。
项目管理人员:负责整个项目的规划、组织、协调和监控。项目管理人员应具备项目管理知识和经验,能够确保项目按时、按质完成,并协调各个团队成员之间的合作。
通过以上方式组织团队成员,可以充分发挥每个成员的专业优势,并促进团队之间的协作与合作。同时,团队成员之间的多样性和跨学科性也有助于提供全面的解决方案和创新思维,推动项目的顺利进行和取得预期成果。
综合题
1、某公司正在进行一个软件开发项目,项目计划总工作量为800人小时,预算为10000美元。已经进行了200人小时的工作,实际花费为3000美元。请使用挣值分析计算以下指标,并分析项目的绩效:
- 计划值(Planned Value,PV)
- 实际值(Actual Cost,AC)
- 挣值(Earned Value,EV)
- 成本偏差(Cost Variance,CV)
- 成本偏差率(Cost Variance Percentage,CV%)
- 进度偏差(Schedule Variance,SV)
- 进度偏差率(Schedule Variance Percentage,SV%)
请根据给定的数据计算上述指标,并对项目的绩效进行分析。
- 计划值:项目计划总工作量为800人小时,已经进行了200人小时的工作,所以计划值为200。
- 实际值:实际花费为3000美元。
- 挣值:已经完成的工作量为200人小时,根据挣值分析,挣值等于已完成工作量乘以预算比率,即200 * (10000 / 800) = 2500。
- 成本偏差(Cost Variance,CV):成本偏差等于挣值减去实际成本,即2500 - 3000 = -500(负值表示超出预算)。
- 成本偏差率(Cost Variance Percentage,CV%):成本偏差率等于成本偏差除以实际成本的百分比,即(-500 / 3000)* 100% = -16.67%。
- 进度偏差(Schedule Variance,SV):进度偏差等于挣值减去计划值,即2500 - 200 = 2300。
- 进度偏差率(Schedule Variance Percentage,SV%):进度偏差率等于进度偏差除以计划值的百分比,即(2300 / 200)* 100% = 1150%。
分析:
- 成本偏差为负值,表示项目的实际成本超出了预算,需要采取措施控制成本。
- 进度偏差为正值,表示项目的进度超过了计划值,说明项目进展较快。
综合来看,尽管项目的成本超出了预算,但项目的进度超出了计划值,表示在这个时间点上项目的绩效整体上是较好的。然而,仍然需要关注成本超支的情况,并采取适当的措施来控制项目的成本。
2、假设你正在设计一个自动售货机的软件系统。该售货机根据货物的种类和支付方式来确定出货和找零的逻辑。根据以下规则,请填写完整的判定表:
规则:
- 如果货物种类是饮料且支付方式是现金,则出货并找零。
- 如果货物种类是零食且支付方式是现金,则出货并找零。
- 如果货物种类是饮料且支付方式是刷卡,则出货但不找零。
- 如果货物种类是零食且支付方式是刷卡,则出货但不找零。
- 如果货物种类是其他且支付方式是现金,则不出货。
- 如果货物种类是其他且支付方式是刷卡,则不出货。
请根据以上规则填写完整的判定表。
判定表如下:
| 货物种类 | 支付方式 | 出货 | 找零 |
|---|---|---|---|
| 饮料 | 现金 | 是 | 是 |
| 饮料 | 刷卡 | 是 | 否 |
| 零食 | 现金 | 是 | 是 |
| 零食 | 刷卡 | 是 | 否 |
| 其他 | 现金 | 否 | - |
| 其他 | 刷卡 | 否 | - |
3、某单位招收暑假实习生,方案为:
①如果该学生的校内成绩为优秀,则直接录用。
②如果该学生的校内成绩为良好,同时导师推荐成绩为良及以上,则直接录用。
③如果该学生的校内成绩为中等,同时导师推荐成绩为良及以上,则直核录用。
④如果该学生的校内成绩为中等,同时导师推荐成绩为中,则需要考试。
⑤如果该学生的校内成绩为及格,同时导师推荐成绩为良及以上,则需要考试。
⑥如果该学生的校内成绩为及格,同时导师推荐成绩为中及以下,则拒绝录用。
⑦如果该学生的校内成绩为中等,同时导师推荐成绩为中以下。 则拒绝录用。
用判定表表述上述方案。
根据给定方案,可以使用判定表来表述。判定表由条件和动作组成,根据不同的条件组合确定相应的动作。以下是根据方案描述的判定表:
| 校内成绩 | 导师推荐成绩 | 录用/考试/拒绝录用 |
|---|---|---|
| 优秀 | - | 录用 |
| 良好 | 良及以上 | 录用 |
| 中等 | 良及以上 | 直核录用 |
| 中等 | 中 | 考试 |
| 及格 | 良及以上 | 考试 |
| 及格 | 中及以下 | 拒绝录用 |
| 中等 | 中以下 | 拒绝录用 |
根据上述判定表,可以根据学生的校内成绩和导师推荐成绩确定相应的录用动作,或者需要进行考试,或者拒绝录用。
4、已知被测试模块的C语言源程序如下:
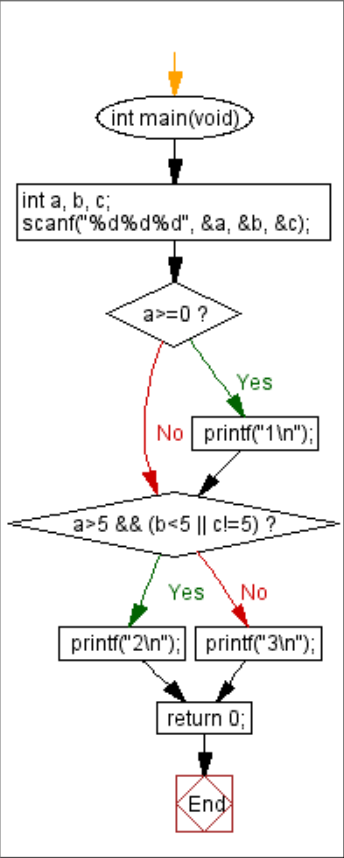
#include<stdio.h>
int main(void) {
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
if(a>=0)
printf("1
");
if(a>5 && (b<5 || c!=5))
printf("2
");
else
printf("3
");
return 0;
}
(1)画出该程序对应的流图。
(2)上述程序有几条独立路径,即求环路复杂性:V(G)的值。
(3)设计一组测试用例以强制执行每条独立路径:必须列出测试用例的输入数据和所经
过的路径。
(4)设计满足“判定、条件”覆盖的一组最少的测试用例并说明符合的理由。
(1)该程序对应的流图如下:
(2)程序中存在4条独立路径。
(3)设计测试用例以强制执行每条独立路径:
- 路径1: a = 1, b = 1, c = 1
- 路径2: a = 6, b = 4, c = 5
- 路径3: a = 6, b = 4, c = 6
- 路径4: a = -1, b = 1, c = 1
(4)
测试用例:
- 路径1: a = 1, b = 1, c = 1
- 路径2: a = 6, b = 4, c = 5
使用路径1和路径2的测试用例即可实现"判定、条件"覆盖。因为路径1和路径2涵盖了所有的判定和条件语句。
5、某经营文具用品企业需要构建一个在线购物系统,下图是某个用户通过系统下订单的
效果图。
我的全部订单
订单编号:2016010008625
订单生成时间:2022-05-22 18:20:15
送货地址:福州市大学城区学院路2号
付款方式:货到付款
| 商品编号 | 商品名称 | 购买数量 | 单价(元) |
|---|---|---|---|
| A0023 | 涂改带 | 20 | 5.00 |
| B0421 | 0.7mm签字笔 | 10 | 3.00 |
| B0422 | 0.5mm签字笔 | 10 | 2.50 |
总价:155.00
(1)要达到这样的效果,该如何设计相关类?给出主要类图
(2)为了促销,该企业决定推出618活动:满100元减5元、满200元减15元、满300元减30元。考虑到将来还会有双十一、双十二等不同促销手段的活动,你将如何修改设计方案,以适应上述要求?给出设计方案并说明运用了哪些设计原则。
(1) 主要类图设计如下:
- 订单系统类是整个系统的入口,负责处理订单生成、支付、查询等功能。
- 订单类包含订单编号、生成时间、送货地址、付款方式等属性,以及商品项的集合。
- 商品类包含商品编号、商品名称、单价等属性。
- 购物车类负责管理用户的购物车,包含商品项的集合和相关操作。
- 促销活动类包含满减活动的规则,如满100元减5元、满200元减15元等。
- 促销策略类负责根据当前促销活动规则计算订单的折扣金额。
(2)修改设计方案以适应不同促销手段的活动:
可以引入策略模式来灵活处理不同的促销活动。具体设计方案如下:
- 新增一个抽象策略类PromotionStrategy,其中定义了一个calculateDiscount方法用于计算订单的折扣金额。
- 每种具体的促销活动(如满减、打折、赠品等)都实现PromotionStrategy接口,并实现自己的calculateDiscount方法来计算折扣金额。
- 在订单系统中引入一个促销策略类PromotionContext,该类具有一个promotionStrategy属性,用于存储当前所应用的促销策略。
- 订单在生成时,通过PromotionContext设置当前的促销策略。
- 在计算订单总价时,调用当前促销策略的calculateDiscount方法来计算折扣金额,并在原总价上减去折扣金额。
通过上述设计方案,可以根据不同的促销活动灵活地选择不同的促销策略,并实现可扩展性,以适应不同的促销需求。这样的设计方案运用了策略模式和开闭原则。策略模式通过将算法封装在独立的策略类中,使其可以独立变化,而不影响其他部分的代码。开闭原则则保证了系统的扩展性,通过新增具体的促销策略类来添加新的促销活动,而无需修改订单系统的代码。

6、假定你是一个项目管理者,受命为一个小型软件项目进行挣值统计。这个项目共计划需要 200 人日才能完成,下面给出相关进度安排数据(单位:人日)。
目前有5个工作任务已经完成,但是按照项目进度,现在应该完成7个工作任务。
请计算:该项目的计划完成任务 BCWS、实际完成任务 BCWP、进度表执行指标 SPI、进度偏差 SV、预定完成百分比、完成百分比、已经完成任务 ACWP、成本执行指标 CPI和成本偏差 CV,并说说你认为该团队的现状如何。
| 任务 | 计划工作量 | 实际工作量 |
|---|---|---|
| 1 | 6 | 8 |
| 2 | 16 | 18 |
| 3 | 4 | 5 |
| 4 | 12 | 9 |
| 5 | 5 | 3 |
| 6 | 16 | —— |
| 7 | 13 | —— |
根据给出的进度安排数据,我们可以计算以下指标:
- 计划完成任务(BCWS):按照项目进度,目前应该完成的任务数。
BCWS = 计划工作量之和 = 6 + 16 + 4 + 12 + 5 + 16 + 13 = 72 人日- 实际完成任务(BCWP):目前已经完成的任务数。
BCWP = 实际工作量之和 = 8 + 18 + 5 + 9 + 3 = 43 人日- 进度表执行指标(SPI):衡量实际完成任务与计划完成任务的比例。
SPI = BCWP / BCWS = 43 / 72 ≈ 0.597- 进度偏差(SV):实际完成任务与计划完成任务之间的差异。
SV = BCWP - BCWS = 43 - 72 = -29 人日- 预定完成百分比:已经完成的任务百分比。
预定完成百分比 = BCWP / BCWS * 100% = 43 / 72 * 100% ≈ 59.72%- 完成百分比:已经完成的任务百分比。
完成百分比 = (已经完成的任务数 / 总任务数) * 100% = (5 / 7) * 100% ≈ 71.43%- 已经完成任务(ACWP):已经完成的工作量之和。
ACWP = 实际工作量之和 = 8 + 18 + 5 + 9 + 3 = 43 人日- 成本执行指标(CPI):实际完成工作量与预算之间的比例。
CPI = BCWP / ACWP = 43 / 43 = 1
成本偏差(CV):实际完成工作量与预算之间的差异。
CV = BCWP - ACWP = 43 - 43 = 0根据计算的指标:
- 进度表执行指标 (SPI) 小于 1,表示项目进度滞后于计划。
- 进度偏差 (SV) 为负值,表示项目进度落后于计划。
- 预定完成百分比小于完成百分比,也说明项目进度滞后于计划。
- 成本执行指标 (CPI) 等于 1,表示实际完成工作量与预算相符。
- 成本偏差 (CV) 为零,表示实际成本与预算相符。
综上所述,该团队目前的现状是项目进度滞后于计划,但成本控制良好,实际完成工作量与预算一致。需要采取措施加快进度,以保证项目按时完成。
7、现有一段程序如下图,要求:
(1)给出以上程序对应程序控制流图(自行在代码上标出测试节点编号)。
(2)本段程序存在多少个独立路径?
(3)给出一组包含全部独立路径的测试集。
void task(int x, int y)
{
int a;
while(x<y)
{
if( (x<1)&&(y<10) )
{
y = x + y;
}
if( (x == 5)||(y>8) )
{
a = x*y;
}
x++;
}
printf("%d, %d, %d", x, y, a);
}
(1)以下是给定程序的控制流图(包括标注的测试节点编号):
Start
|
v
+-----+
| 1 | (x < y)
+-----+
|
v
+-----+
No | 2 | (x < 1) && (y < 10)
+-----+
|
v
+-----+
Yes | 3 | (x = x + y)
+-----+
|
v
+-----+
| 4 | (x == 5) || (y > 8)
+-----+
|
v
+-----+
Yes | 5 | (a = x * y)
+-----+
|
v
+-----+
| 6 | (x++)
+-----+
|
v
+-----+
| 7 | (x < y)
+-----+
|
v
+-----+
No | 8 | Print(x, y, a)
+-----+
|
v
End
(2)该程序存在 4 个独立路径。
(3)给出一组包含全部独立路径的测试集:
| 输入数据 | 预期输出结果 | 覆盖的独立路径 |
|---|---|---|
| x = 5, y = 4 | x = 5, y = 4, a = 20 | 路径1 |
| x = -1, y = 9 | x = 9, y = 8, a = -9 | 路径2 |
| x = 5, y = 9 | x = 6, y = 9, a = 45 | 路径3 |
| x = -1, y = 11 | x = -1, y = 11, a = -11 | 路径4 |
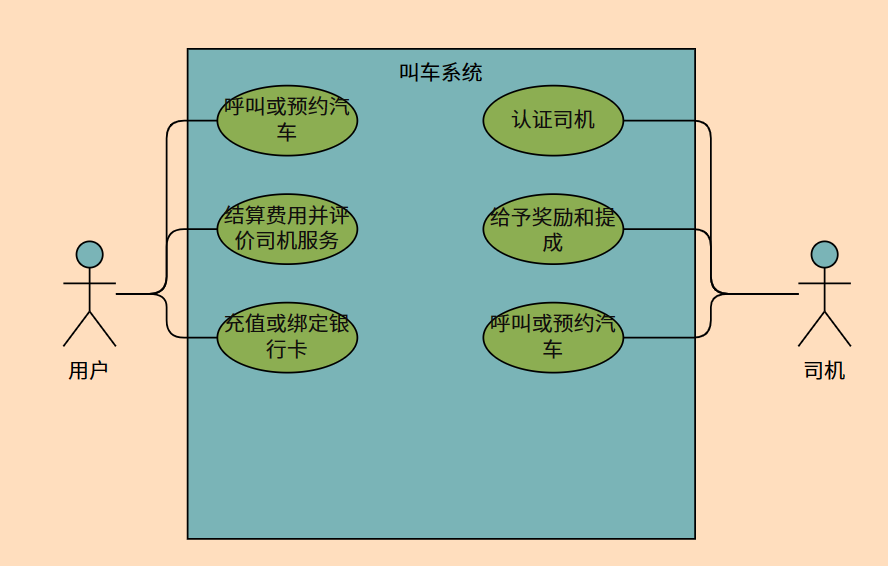
8、互联网技术和智能手机的普及,使得人们出行方式发生了改变,人们可以通过叫车系统呼叫或预约汽车,送顾客到目的地,系统根据行程的距离、用车时段、车型以及是否拼车等方式计算出行费用,用户到达目的地后再结算费用并评价司机服务。其中叫车系统提供三种出行方案:快车、出租车和顺风车。其中快车方式,用户可以选择车型,不同车型价格不同;出租车方式,用户可以添加调度费来召唤出租车;顺风车方式,用户可以选择是否拼车。如果用户的用车时间恰恰是在高峰时段,那么总费用将上浮40%。用户可以通过充值的方式给自己账户充钱,也可以通过绑定银行卡的方式,结算费用时直接扣去银行卡余额。叫车系统对于司机需要认证,主要通过身份证和机动车驾驶证,同时,根据用户用车后的评价,给予司机奖励和提成,差评率高的司机将进入黑名单,好评率高的司机将优先推荐。
(1)使用用例图表述系统的功能。
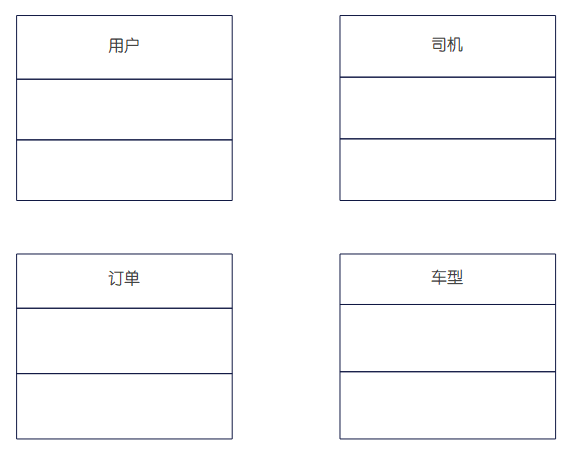
(2)使用类图表述支撑系统功能的主要分析类和类间关系,每个类要给出必要的属性与操作。
(3)分析系统第0层和第1层的数据流图。
(1)用例图
(2)类图
(3)数据流图
第0层数据流图:
第1层数据流图:
9、
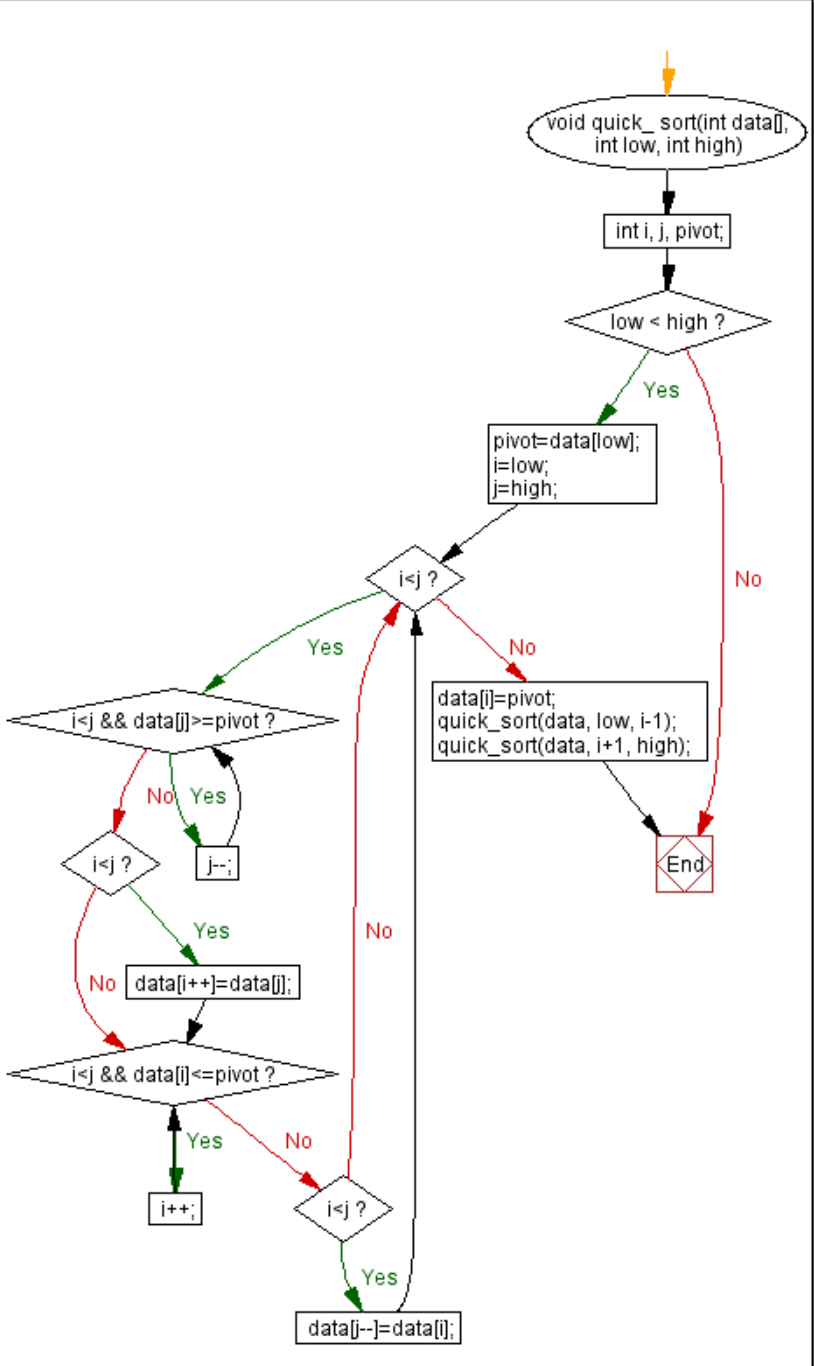
void quick_ sort(int data[], int low, int high)
{
int i, j, pivot;
if (low < high)
{
pivot=data[low];
i=low;
j=high;
while(i<j)
{
while(i<j && data[j]>=pivot)
j--;
if(i<j)
data[i++]=data[j]; //将比枢轴记录小的记录移到低端
while (i<j && data[i]<=pivot)
i++;
if(i<j)
data[j--]=data[i]; //将比枢轴记录大的记录移到高端
}
data[i]=pivot; //枢轴记录移到最终位置
quick_sort(data, low, i-1);
quick_sort(data, i+1, high);
}
}
以上为一个快速排序算法的代码段,请你采用基本路径测试方法进行测试。
要求:
①画出相应的程序控制流图;
②分析该段程序的环路复杂性;
③什么是独立路径?给出该程序的一组独立路径。
(1)
(2)程序的环路复杂性为4,表示需要至少执行4条独立路径才能覆盖所有的语句和分支。
(3)以下是一组独立路径:
- Start -> if (low < high) -> while (i < j) -> while (i < j && data[j] >= pivot) -> if (i < j) -> data[i++] = data[j] -> while (i < j && data[i] <= pivot) -> if (i < j) -> data[j–] = data[i] -> data[i] = pivot -> quick_sort(data, low, i-1) -> Return
- Start -> if (low < high) -> while (i < j) -> while (i < j && data[j] >= pivot) -> if (i < j) -> data[i++] = data[j] -> quick_sort(data, low, i-1) -> quick_sort(data, i+1, high) -> Return
这是两个独立路径的示例,覆盖了程序中的所有语句和分支。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结