您现在的位置是:首页 >技术教程 >【TaskMatrix.AI - Visual ChatGPT】连接超大模型和超多API来完成任务网站首页技术教程
【TaskMatrix.AI - Visual ChatGPT】连接超大模型和超多API来完成任务
Github项目地址:https://github.com/microsoft/TaskMatrix
目前大规模预训练模型(比如ChatGPT)已经能够完成多个任务,例如
- 提供强大的对话功能,in-context learning能力和代码生成能力
- 生成高层次的解决问题框架
然而,对于特定领域的特殊问题,由于大模型没有见过类似数据的原因导致在这些任务上表现的较差。
另外,对于特定领域的问题,目前也已经有现成的模型或系统做的比较好了,但这些解决特定问题的模型并不容易和大模型适配。
所以为了解决上面两个问题,需要一种结合的机制:
- 大模型提供问题解决的整体方案
- 方案中的子任务使用特定领域的小模型解决
TaskMatrix.AI
微软提出了TaskMatrix.AI,这是一个模型的生态系统,这个系统中大模型作为大脑(brain-like central system),其它小模型作为子任务的求解器(sub-task solvers)。
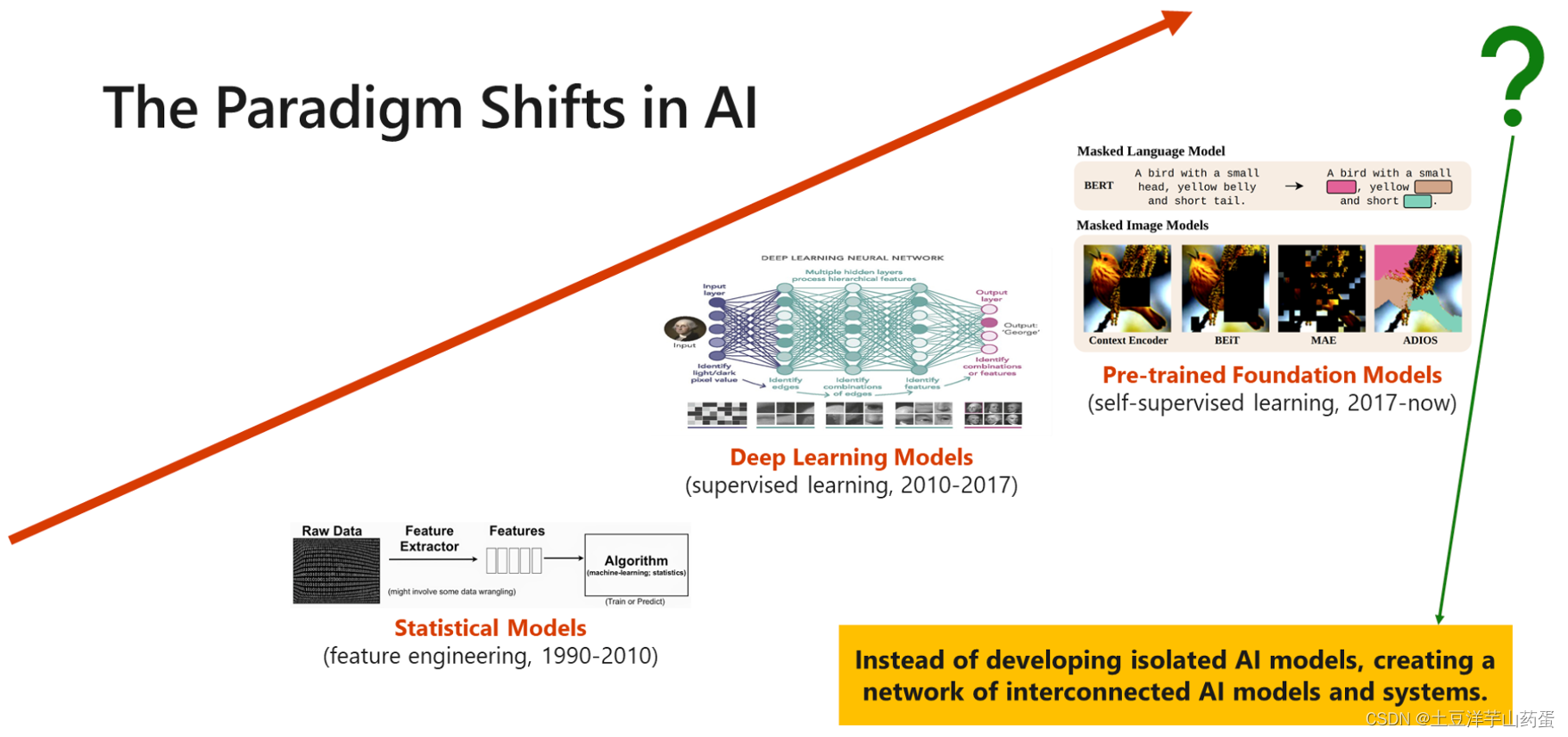
从深度学习发展的历史来看,目前貌似进入了一个新的时代
TaskMatrix.AI的整体框架如下:
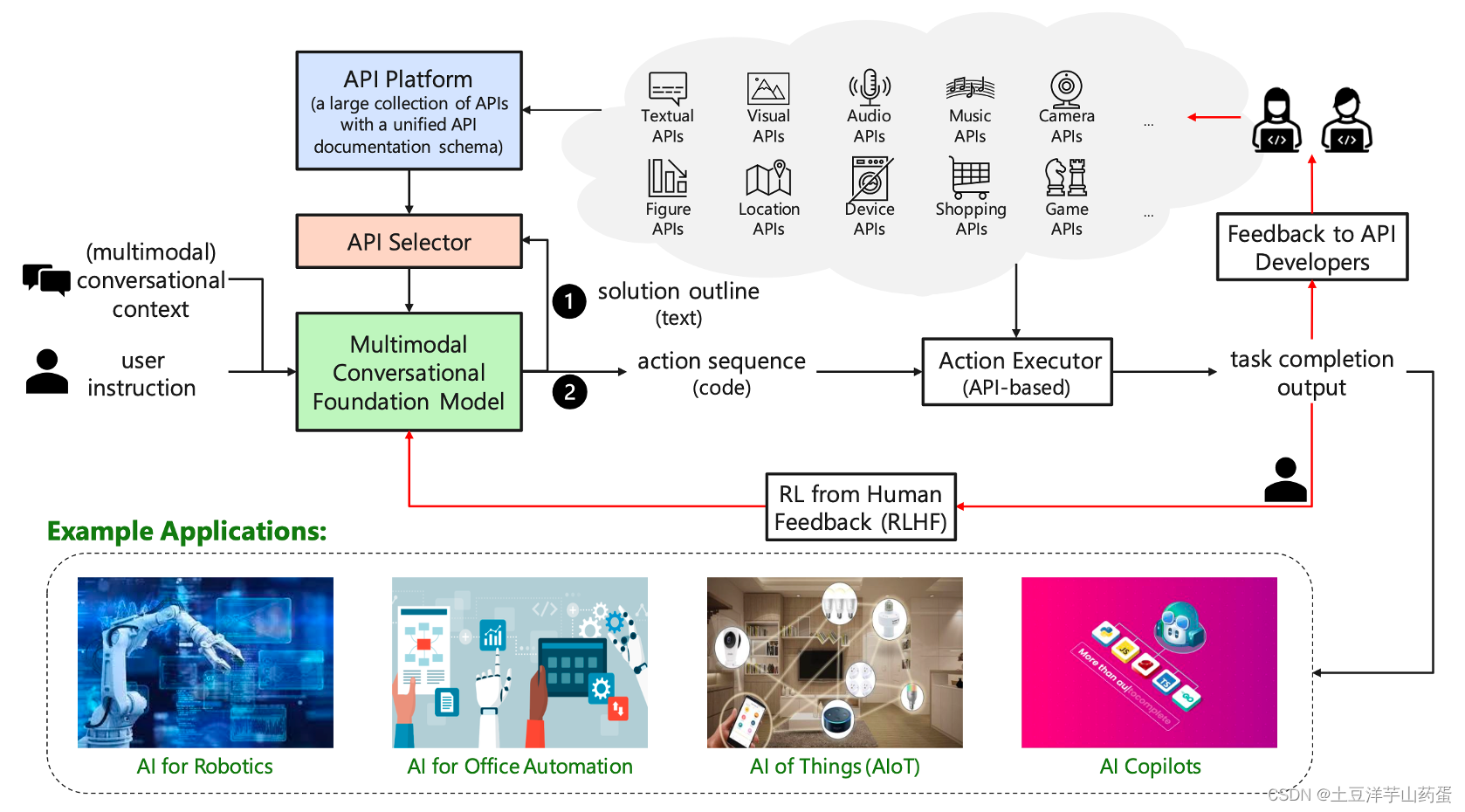
从组成成分来看,TaskMatrix.AI包括Multimodal Conversational Foundation Model (MCFM),API Platform(特定领域的模型/求解器作为API供大模型调用)和API Selector。
从工作机制来看,MCFM首先获取多模态的输入,第一步生成解决方案的概要。API Selector拿到这个概要后决定从API Platform中调用哪些工具。第二步MCFM拿到API调用结果后生成动作序列,最后执行这些动作后得到最终输出。
从后续学习的角度来看,最终产生的输出可以用与RLHF反馈给模型以调整MCFM参数,也可以反馈给API Developer以提供更好的API服务。
Visual ChatGPT
Visual ChatGPT是上面TaskMatrix.AI 框架的一个应用案例,即给ChatGPT加入图像处理的功能。
基本的想法是:
- 视觉基础模型(VFM)在计算机视觉中显示出巨大的潜力,已经可以处理很多图像任务
- Visual ChatGPT直接基于ChatGPT并结合了各种VFM,以给ChatGPT加入视觉智能。
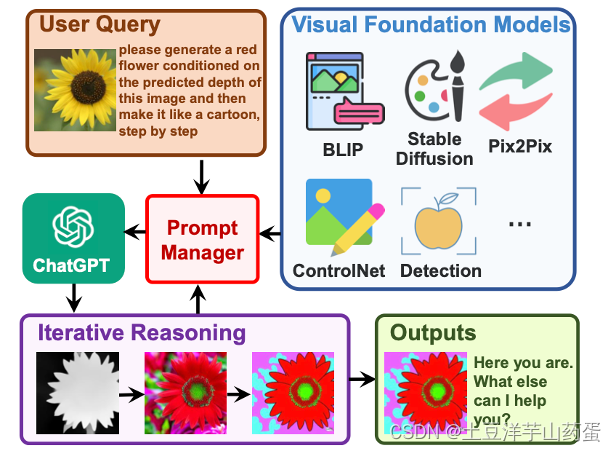
文中提出了一种Prompt Manager的模块管理ChatGPT的输入,这种输入中可以引入多个视觉基础模块的生成或处理结果,从而使得在ChatGPT中可以处理图片。
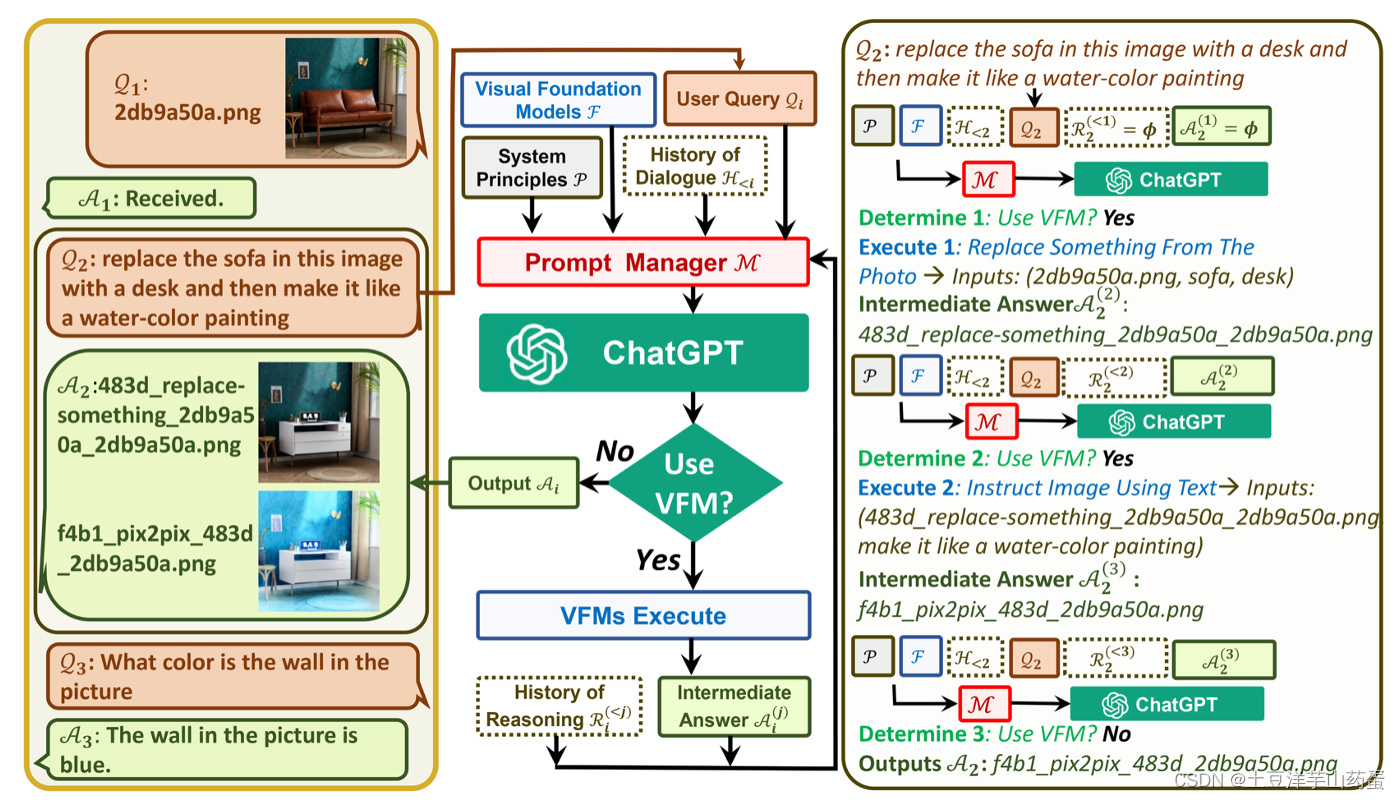
上图展示了一个案例,左边是对话过程,中间是处理流程,右边是处理细节。可以看出流程中的主要部分是要决定是否要使用VFM模块,如果使用则需要引入具体的视觉模型进行处理,并将进行迭代决定是否继续使用VFM。右边是对Q2的回答细节,其中前两步都是要使用VFM处理图片,最后讲处理后的图片输出。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结