您现在的位置是:首页 >技术交流 >SeaTunnel StarRocks 连接器的使用及原理介绍网站首页技术交流
SeaTunnel StarRocks 连接器的使用及原理介绍
作者:毕博,马蜂窝数据平台负责人,StarRocks 活跃贡献者 & Apache SeaTunnel 贡献者
Apache SeaTunnel(以下简称 SeaTunnel)是一个分布式、高性能、易扩展、用于海量数据(离线&实时)同步和转化的数据集成平台。StarRocks 通过与 SeaTunnel 的结合可以轻松实现 StarRocks 和不同数据源之间的数据交换。
SeaTunnel StarRocks 连接器简介
首先介绍一下数据同步平台 Apache SeaTunnel 的基本架构。

上图为 SeaTunnel 架构图,它提供了一套抽象的 API,包括 Source 、Transform、Sink API 等。基于这些抽象 API 可扩展出各种各样 Connector,其中基于 Source API 实现的 Source Connector 可以从左侧众多的数据源中读取数据,Transform Connector 用于实现数据 Pineline 中的数据转换处理,而 Sink Connector 可以将数据写入到右侧多种异构的数据源中。
同时,在运行时,SeaTunnel 还提供了一个翻译层,会将 Connector 实现的 Source 和 Sink API 翻译成引擎内部可运行的 API,使连接器可以在不同引擎上运行。目前 SeaTunnel 支持三种执行引擎,Spark、Flink 以及 SeaTunnel 自研执行引擎 Zeta Engine。
以上就是 SeaTunnel 的整体架构,可以看出,SeaTunnel 通过 Souce Connector 和 Sink Connector 实现与不同数据源进行链接。

上图描述了 SeaTunnel 和 StarRocks 结合的整体情况,SeaTunnel 提供 了Source Connector 和 Sink Connector。在 Source 部分 StarRocks 的表作为数据源,通过 SeaTunnelSource Connector 分布式地去提取 StarRocks 的数据;中间通过 SeaTunnel 提供的 Transform Connector 做一些分布式的数据处理和转换;后面的 StarRocks Sink 连接器则主要是把 SeaTunnel 内存里的数据,通过 StarRocks 提供的 Stream Load API,将数据导入到 StarRocks。
StarRocks Connector 功能特性
01 Source 功能特性

上图展示了目前 SeaTunnel Source 连接器当前支持的核心功能和特性,具体包括:
字段投影: 假设待读取表有多个字段,但是整个数据处理的 Pipeline 中只用到部分字段,那么针对这些部分列做数据同步就是字段投影的使用;
谓词下推: 谓词下推可以在数据扫描的时候过滤大量用不到的数据,通过下推到引擎,可以减少数据传输的数据量;
数据类型的自动映射: 是关于从 StarRocks 读取的数据类型与 SeaTunnel 内部数据类型的映射,后面会介绍目前支持的数据类型;
用户自定义分片: 是通过将待读取数据源的整个数据集拆分多个分片,每一个分片可以单独查询,并且在分片生成的阶段用户可以通过配置参数去控制分片生成的数量;
并行读取:首先, StarRocks 是支持并行的读取数据源,同时基于上面的数据源分片的切分,在读取时多个分片同时独立进行,最终通过并行读取加快读取的速率;
状态的恢复:Source 连接器读取阶段切分多个分片之后,连接器在读取过程中会定期将未进行读取分片信息保存在 State 中;这样在故障恢复的时候,结合 State 中分片的位置信息进行重新读取;
至少一次:得益于状态恢复,所以在读取端提供至少一次的语义;
Batch 模式:目前 StarRocks 连接器 Source 部分只支持批模式。
02 Sink 功能特性

Sink 的数据导入是基于 StarRocks 的 Stream Load 实现,因为 Stream Load 支持 CSV 和 JSON 两种文件格式,所以连接器在 Sink 端可以指定 CSV 和 JSON 两种文件格式进行导入。
写入时,考虑到写入的效率,所以会涉及数攒批,进行批量数据写入,而不是单条提交。
如果写入出现了异常 ,程序会自动判断是不是可恢复的异常,再基于一定的策略进行重试。
关于 CDC,目前 SeaTunnel 支持数据库的 changelog 捕捉,再结合 StarRocks 的 Stream Load 接口,可以对 StarRocks 的主键模型表进行数据变更,包括插入、更新和删除数据,所以连接器当前支持将 SeaTunnel 获取的 CDC 数据导入到 StarRocks 中来。
上述列表展示了目前 Source 和 Sink 连接器已经支持的功能和特性,希望在实际应用中可以给大家提供一些参考。
StarRocks Connector 读取原理
接下来我会着重介绍 StarRocks Connector 的读取原理,帮助大家更好地使用连接器功能。
01 字段投影
我们在读 StarRocks 表的时候,是可以选择部分字段读取的,比如这里我们有一个 StarRocks 表,有 4 个字段。但是实际同步使用到的字段只有 lo_orderkey、lo_number 两个字段,对于指定部分列的提取数据场景,可以在配置 Source 连接器的时候,通过 fields 参数来指定要查询的字段和数据读到 SeaTunnel 上面的字段数据类型。

这样,在 SeaTunnel 真正执行的时候,就能只同步指定的字段,最终同步到 StarRocks 的数据如下图。

通过减少投影字段可以降低同步过程网络、内存资源消耗,提升同步性能。
02 谓词下推
在实际使用中,我们可能需要过滤掉部分行的数据,如获取表中 linenum< 3 的部分数据。这时,我们可以在配置 Source 连接器的时候,通过配置 scan-filter 参数来过滤指定的部分行。
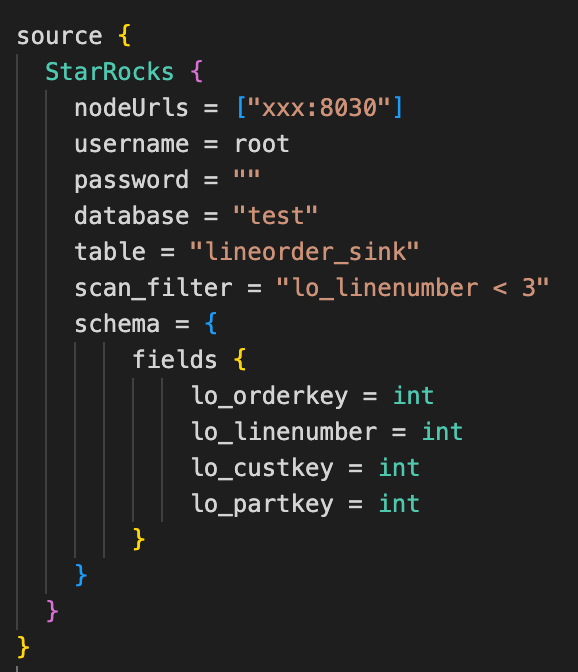
在实际执行中会将条件下推到 StarRocks,在 StarRocks 引擎内进行分区剪裁或分桶剪裁等优化处理。

这样,在读取数据阶段跳过全表扫描,可以大大减少数据处理的数据量,提升读取数据的效率。
03 字段投影&谓词下推实现
在具体实现上,通过用户在连接器中配置中指定的 fields 和 scan-filter 参数,连接器在程序中会自动生成适用于 StarRocks 的查询语句。如图,通过程序转换,最终生成 SQL。

04 并行读取:实现方案
并行读取 StarRocks 数据主要有两种方案,以 Flink 引擎读取 StarRocks 为例。方案一:直接通过 JDBC 协议读取数据,数据最终需要通过 FE 单节点将数据抽取上来,读取效率较低。

方案二:进行分布式的设计,先通过 FE 查询对应 StarRocks 表的分片的元数据信息, 获取待读取数据的数据分布情况,再用分布式并行的方式直接从多个 BE 节点读取数据。

这样做让整体的吞吐能力得到很大的提升,目前 StarRocks Connector 基于第二种方案。
05 并行读取:获取 StarRocks 的数据分布
Source 连接器实现并行读取,首先要知道 StarRocks 表的存储的数据分布情况。当前 StarRocks 的 FE 提供了获取单表查询计划接口,通过指定要查询的表及 SQL 进行 API 接口的调用。

如上图所示,右侧是 FE 接口返回的结果经过序列化后对应的数据结构,query plan 为查询计划的字符串。partitions 是一个 map,key 是 StarRocks tablet ID ,value 为 tablet 实际分布在 BE 节点的地址,因为 StarRocks 表的数据是多副本管理,所以会有多个 BE 地址。
通过以上信息信息,就可以知道表中要查询数据的数据分布情况。
06并行读取:spilt 切分(基于数据分布)
要实现并行读取,就需要要对待查询的目标表的数据范围划分,再进行分片切分,让并行的线程读取特定分片的数据。

在 Souce Connector 实现中,分片切分是基于 StarRocks 表的数据分布进行数据范围划分。
如上图所示,左侧描述了 StarRocks 数据分布。StarRocks 使用列式存储,采用分区分桶机制进行数据管理。对应图中表 A 按照日期“月”划分分区,进一步的 2023-01 月份的分区切分为 5 个 分桶(A、B、C、D、E)。
分桶是 StarRocks 中最小的数据管理单元,每个分桶使用多副本进行组织,对应图中分别为分桶 A,有 A-1 、A-2、A-3 个副本;分桶 B 有 B-1、B-2、B-3 等,这些分桶副本最终会存储在不同的 BE 节点中。
假如我们要同步表 A 中 2023 年 1 月份的数据,首先要知道这部分数据的数据分布情况。之前介绍了通过 FE API 可以获取 StarRocks 表的数据分布情况,对应图中,分桶 A 数据保存在 BE-1、BE-2、 BE-3 上。
下一步,通过一定策略,为每一个 tablet 选择最优的 BE 查询节点,原则是最终结果中每一个BE 节点有相对均等数量的分桶等待被查询,这样可以保证在并行查询时,每一个 BE 节查询负载相对均衡。
最后,根据前面为每一个分桶选择查询 BE 节点信息生成的 split 分片。
07 并行读取:用户自定义分片
Source Connector 支持自定义分片,也就是用户可以控制分片生成, 通过 request_tablet-size 这个配置参数制。

刚刚我们介绍了生成 split 分片切分的过程,StarRocks 表 A 的 5 个分桶 ABCDE, 最终生成了 3 个分片对图中上半部分。假加我们想让查询数据的并发度更高,就需要生成更多的分片。这时,我们可以设置 request_tablet-size,限制每个分片中 tablet 的数量。比如我们配置 request_tablet-siz=1, 表示每个分片的分桶最多为 1, 那么最终将会生成 5 个分片,效果如上图所示。
08 并行读取:分配 spilt 到 reader
Split 切分好了,需要分配给每一个并行的 Reader。Reader 数量的指定是通过在任务的 env 配置并行度(下图左侧所示),配置好就会有几个并行的 Reader 去读取数据源。

如上图所示,右侧是具体分片分配给 Reader 的过程:Split 通过 split 中的属性 ID 向 Reader 数取模,使每一个 Reader 上分配的分片数相对一致。
09 并行读取:Reader 读取数据
将 split 分片配给 Reader 之后,每一个 Reader 就开始实际的数据读取,该过程是每个 Reader 通过 BE 提供的一组 thrift 协议向 BE 节点扫描。分桶对应的数据如图中所示,每个分片包含了需要向哪个 BE 节点查询及需要扫描 BE 上的哪些分桶数据。

下图是 BE 提供 thrift 协议具体接口。

有三个重要的方法,首先创建一个scanner ,通过类似游标的方式,多次调用 getnext 获取全部数据,最终数据都完成返回后,通过 close scaner 释放资源。
10 并行读取:arrow -> seatunnel row 的数据转换
Reader 通过 thrift 协议向 BE 节点扫描数据,最终从 BE 获取到的数据是 apache arrrow 的数据格式。
因为 StarRocks 表的数据通过 SeaTunnel 读取出来之后首先要转换为 SeaTunnel 自己的数据结构 SeaTunnelRow,之后才可以在 SeaTunnel 内部进行数据转换及写出,因此需要将 apache arrow 的数据类型转换为 SeaTunnel 的数据类型。
整个转换过程如下图所示:
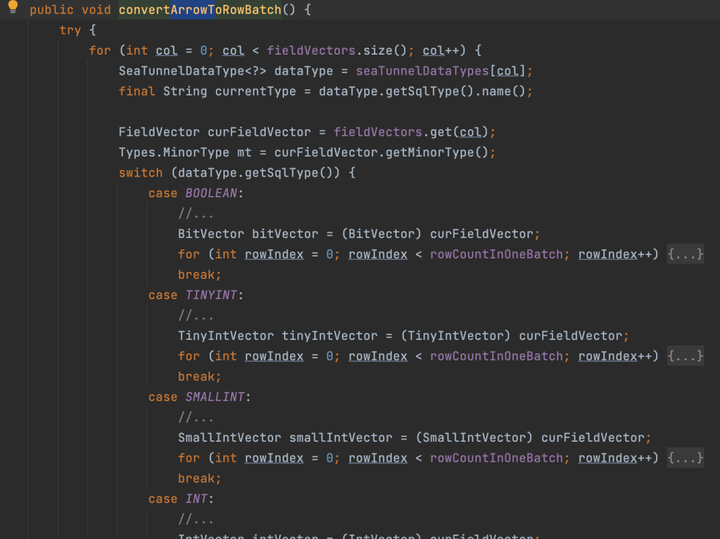

其中 Apache Arrow 的 varchar 可以根据用户在 source 连接器配置数据投影的数据类型转换为 Date、Timestamp 和 String。
11 数据类型映射
最终从 StarRocks 读取的数据类型,从 BE 节点获取的 apache-arrrow 格式的数据类型以及转换到 SeaTunnel 上的数据类型三者之间的映射关系如下图,也是目前 StarRocks 连接器支持的数据类型映射,基本上覆盖了所有的数据类型,但 ARRAY、HLL、BITMAP 等暂时还不支持。

在使用中我们只需要关心 StarRocks 的 Datatype 和 SeaTunnel Datatype 的映射就可以,apache-arrrow 部分的转换是程序自动完成的。
12 并行读取:状态恢复
在读取的时候还会涉及到状态恢复,因为如果任务读取的数据量比较大,读取的时间会较长,中间一旦出现错误或者异常,需要从出错的位置重新读取,类似于断点续传。
这里面有两个比较重要的过程: 状态保存: 通过 Reader 把未读取的 split 信息存到 state 里,引擎在读取过程会定期对 state 做快照,如 snapshotState 方法的逻辑;
状态恢复:Reader 的状态恢复主要是通过最后一次快照,进行恢复后继续读取。在开始读取数据的时候,从未读取的分片集合中里面去消费,之后开始实际读取,对应 pollNext 方法逻辑。
StarRocks Connector 写入原理
介绍完 Source Connector 的写入原理,我们再来看 Sink 连接器的写入原理。
StarRocks Sink 写入是基于 Stream Load 接口,在写入时需要做处理批量和重试。对于批量,数据是在写入之后,先缓存在内存中,达到一定阈值之后再进行批量数据的提交。
阈值目前包括批数据的大小、数据条数限制,同时连接器也支持定时提交,一定时间间隔下提交一次。
?注意,在 sink 的时候,需要留意"too many tablet versions" 报错,出现问题是由于导入频率太快,数据没能及时合并(Compaction),从而导致版本数超过支持的最大未合并版本数。
除了优化 BE 的配置,调整合并策略,如 cumulative_compaction_num_threads_per_disk、base_compaction_num_threads_per_disk 等来加快合并,也可以在 sink 端控制批量的提交的阈值,增大单次导入的数据量,降低导入频率。
对于重试,SeaTunnel 支持配置重试策略,如重试次数,等待间隔与最大重试次数等。
01 CDC 数据写入支持
目前,SeaTunnel 已支持数据库变更数据捕获(CDC https://github.com/apache/incubator-seatunnel/issues/3175),以将数据更改实时传送到下游系统。SeaTunnel 将捕获到的数据更改分为以下 4 种类型:
-
INSERT(数据插入)
-
UPDATE_BEFORE(数据更改前的旧值)
-
UPDATE_AFTER(数据更改后的新值)
-
DELETE(数据删除)

在写入的目标数据上面,StarRocks 数据源的主键模型支持通过 Stream Load 导入作业,同时对 StarRocks 表进行数据变更,包括插入、更新和删除数据。
因此,将 SeaTunnel changelog 数据的变更类型转换成 StarRocks 支持的变更类型,使 SeaTunnel Connector 可以支持 CDC 写入 StarRocks。
在 SeaTunnel 中假如 CDC 数据如上图图所示,分别插入主键为 123 的数据,对主键 1 进行 UPDATE,会生成 update_before、update_after 、dedete 的 cdc changelog event,通过 sink 连接器配置中 enable_upsert_delete = true,开启将 CDC 数据写入 StarRocks 的支持。
StarRocks Connector 使用示例
这里以 StarRocks 之间同步数据这个使用场景为例,介绍如何配置使用连接器。假设在 StarRocks 有一张数据表 customer_1,有四个数据列,我们目标将数据同步到一个张表 customer_2,首先在 SeaTunnel 任务配置文件中配置 Source Connector,数据表有 4 个字段列,我们只需要 2 个字段,所以配置数据投影。
在 Transform Connector 配置中我们进一步进行数据处理,希望将 c_name 字段中 customer前缀去除,保留数字部分同时导入数据字段名称跟目标表名称表不一致,需要通过 SQL 重命名。
最后配置 Sink Connector,配置目标数据源的链接信息,指定 Stream Load 数据导入的文件格式为 JSON。
在 env 里面对任务参数进行指定,如任务的整体并行度,当然也可以在 connector 的配置里面单独指定并行度。
最终导入到目标表的 customer_2,如下图:

连接器后续规划
至此,我们可以看到,SeaTunnel 的基本数据同步功能已经非常完善了,但一些数据同步场景对数据可靠性有着更高的要求,在 Sink 侧需要有仅一次和至少一次的语义支持,这两点已经在社区的支持计划中了。
其中对于 Exactly-Once 语义,StarRocks 2.4 版本提供了 Stream Load 事务接口,为实现高效导入同时兼顾 Exactly-Once 提供了实现的基础。
另外,SeaTunnel 社区还计划在 Source 和 Sink 连接器中支持更多的数据类型映射,如 BITMAP、HLL、Array 等,丰富连接器的功能。
最后,也欢迎 StarRocks 的朋友们一起来为 StarRocks 添砖加瓦,促进生态的融合,让大数据处理回归简单!






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结