您现在的位置是:首页 >其他 >分布式一致性网站首页其他
分布式一致性
1 前言
1.1 目的
- 为代码实现提供理论支撑和方案参考;
- 对分布式数据一致性有一个全局的认识;
1.2 单体架构到微服务
1.2.1 单体架构
(1)优点
- 简单好维护;
- 不存在分布式系统带来的分区问题;
(2)缺点
- 单体架构不能弹性扩展;
- 随着业务发展,代码量持续增加,业务逻辑过于耦合,容错率低;
1.2.2 微服务
(1)优点
- 微服务可以弹性扩展,根据业务流量动态调整、提高系统吞吐;
- 可针对性的给微服务配置性能强弱的服务器,比如计算密集型的服务配置更好的cpu,io密集型的服务配置更好的内存、磁盘;
- 相比单体应用,将服务拆分后,可快速响应需求、系统功能清晰、系统整体可用性强;
(2)缺点
- 增加了共享数据维护难度,比如:分布式锁、分布式事务、数据一致性、分布式会话、分布式job、幂等;
- 需要相关工具保证系统可伸缩性,比如通过k8s、docker、jenkins;
- 有部署运维成本,服务依赖关系增强;
- 增加监控成本,需要性能监控,日志链路跟踪,方便问题定位;
- 会导致雪崩效应;
【雪崩效应】
说明:单个微服务不可用导致整个系统架构不可用,称为雪崩效应,又称级联故障;
原因:微服务之间相互调用,超时时间过长,导致大量请求等待,服务创建了大量线程,耗费大量cpu资源,从而导致服务不可用;
解决方案:适当设置超时时间、服务限流、服务降级、容错、线程池隔离;
2 理论
2.1 说明
2.1.1 一致性分类
(1)强一致性
任何时刻,任何用户或节点都可以读到最近一次成功更新的副本数据,强一致性是程度要求最高的一致性要求。
(2)弱一致性
一旦某个更新成功,用户无法在一个确定的时间内读到这次更新的值,且即使在某个副本上读到了新的值,也不能保证在其他副本上可以读到新的值。
(3)最终一致性
一旦数据更新成功,各个副本上的数据最终达到完全一致的状态,但达到完全一致状态所需要的时间不能保证。
2.1.2 CAP理论
(1)C一致性(Consistency)
在分布式环境下,一致性是指数据在多个副本之间能否保持一致性的特征;
在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致性的状态;
(2)A可用性(Availability)
可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果;
有限的时间:尽可能短的时间内返回处理结果;
返回结果:在有限的时间内返回正常的结果;
(3)P分区容错性(Partition)
如果是分布式系统,那么就会存在多个节点,就会存在节点故障或网络故障,所以P是不可避免的;
分布式系统中,如果要保证C一致性,那么就要执行节点数据同步,同步就存在网络请求故障、逻辑执行耗时等问题,此时就不能保证节点的可用性了。如果要保证A可用性,系统尽可能的快,此时就不能保证网络请求一定成功、逻辑是否执行完成,此时就不能保证节点的一致性了;
2.1.3 Redis如何实现AP架构
(1)redis持久化
- RDB模式
RDB模式下,通过bgsave异步子进程,指定时间策略将内存中的数据集快照写入磁盘,一旦服务器宕机,内存数据丢失,导致内存数据没有持久化到磁盘,造成数据丢失;
- AOF模式
AOF模式下,根据配置同步策略将写操作写到aof文件,配置同步策略为always时可保证数据不丢失,aof文件较大会影响redis重启速度;
- 混合模式
Redis4.0之后可开启混合模式,在aof重写时,将当前时间点之前的数据存储为rdb格式,新追加数据存为aof格式。重放时,先加载以REDIS开头的rdb格式数据,再加载aof格式的剩余部分数据;
(2)redis主从复制
- 主从复制好处
主提供读写,从提供读,提高redis的并发能力;
redis数据容灾,主节点挂了后修改slave为master,需要手动修改配置;
- 主从复制流程
全量同步:
当slave重启或有新的salve进来,salve会向master发送sync信号发起全量同步,master此时会生成全量快照并将新的写命令放入一个buffer中,当快照同步完成后,再将buffer同步到salve;
增量同步:
当全量同步完成,master会异步定时将写操作同步给salve节点;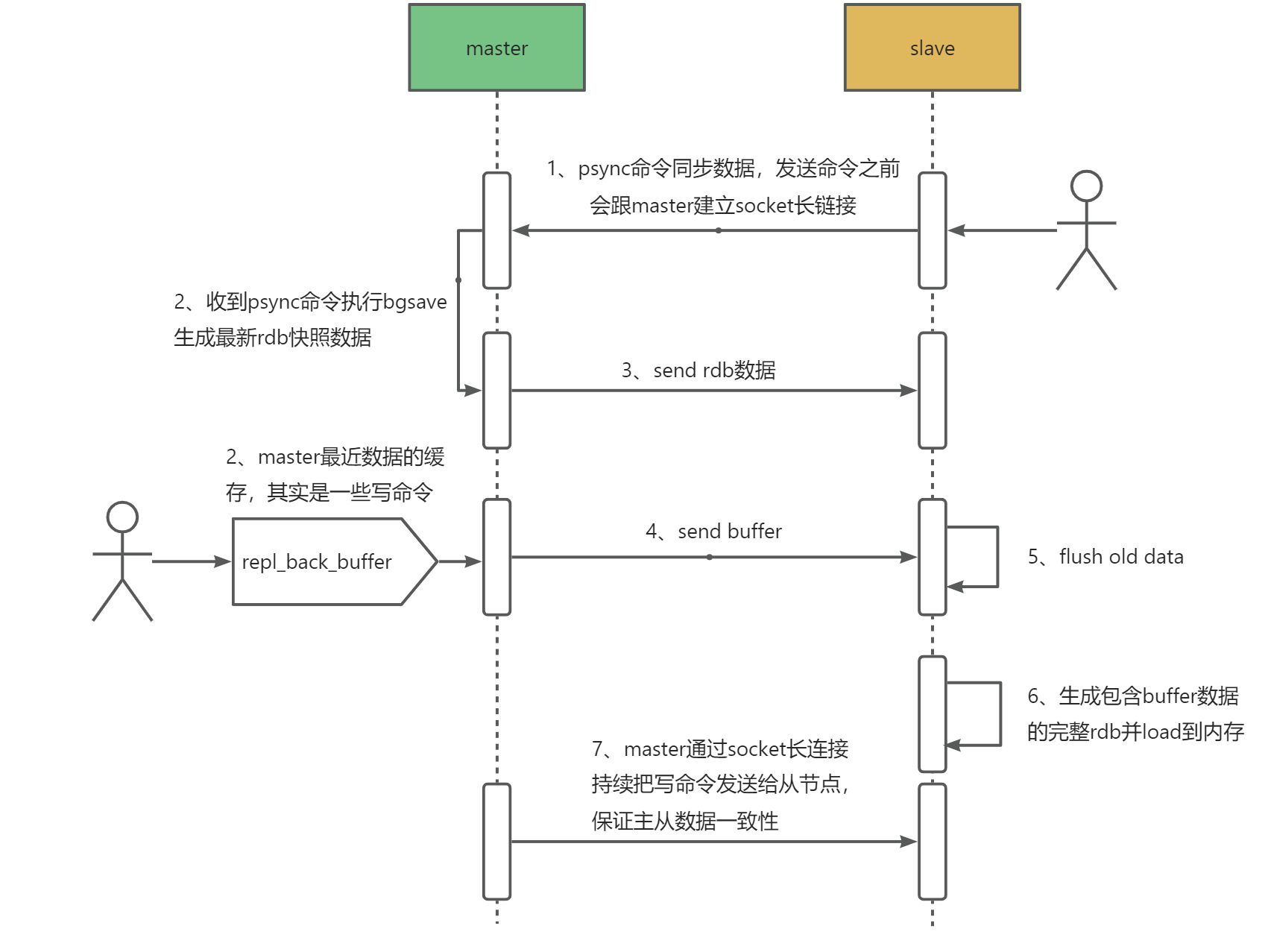
部分同步:
由于bgsave是个重量级操作,如果复制过程中发生网络问题,从节点需重新发送同步请求,此时会导致主节点再次生成快照文件。为了解决这个问题,master和所有的salve会维护复制的数据下标offset和master的进程id,再次重连时发送psync命令并带上offset和master进程id,对比offset是否在复制缓冲区中并且master的进程id未改变,成功则继续将生成的快照发送给从服务器,否则进行全量复制;
2.1.4 ZK如何实现CP架构
(1)正常的客户端提交
- client向zk的server发送写请求,如果该server不是leader,则会将写请求转发给server leader,leader将请求事务以proposal(建议)形式分发给follower;
- 当follower收到leader的proposal时,根据接收到的先后顺序处理proposal;
- 当leader收到follower针对某个proposal过半的ack后,则发起事务提交,重新发起一个commit的proposal;
- follower收到commit的proposal后,记录事务提交,并把数据更新到内存数据库;
- 当写成功后返回给client;

(2)某个节点宕机恢复
在集群运行过程当中如果有一个follower节点宕机,由于宕机节点没过半,集群仍然能正常服务。当leader 收到新的客户端请求,此时无法同步给宕机的节点,造成数据不一致。为了解决这个问题,当节点启动时,第一件事情就是找当前的Leader,比对数据是否一致。不一致则开始同步,同步完成之后再进行对外提供服务。
2.1.5 BASE理论
- BA(Basically Available)基本可用
牺牲高一致性,获得可用性和可靠性;
在分布式系统中出现不可预知故障时,允许损失部分可用性(注意,这里不等价于系统不可用)。
比如:
响应时间上的损失,系统故障时请求响应时间由原来的0.5s延长到1s,此时系统仍然可用;
系统功能上的缺失,在系统流量洪峰时为了保证核心功能稳定,将部分消费者引导到一个降级页面;
- S(Soft state)软状态
软状态指允许系统中的数据存在中间状态,并认为该中间状态不会影响系统的整体可用性,即允许系统各节点数据同步存在延时;
- E(Eventually consistent)最终一致性
系统各节点一定时间后数据最终达到一致状态;
BASE理论是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于CAP理论逐步演化而来的;
BASE理论和传统的事务ACID特性是相反的,它完全不同于ACID的强一致性模型,在实际的分布式场景中,不同业务和组件对数据一致性要求是不同的,因此在具体的分布式系统中BASE理论和ACID特性是结合一起使用的;
2.2 分布式事务
2.2.1 两阶段提交(2PC)
(1)图示
(2)原理
- 准备阶段
协调者向参与者发送询问请求,协调者操作事务并锁定资源,并记录redo和undo日志。如果事务操作成功,则返回给协调者“同意”消息,如果事务操作失败,则返回给协调者“终止”消息;
- 提交阶段
所有参与者询问阶段都返回“同意”后,协调者向参会者发送“正式提交”请求,协调者提交本地事务并释放资源。参与者节点向协调者发送“完成”消息,协调者接收到所有参与者节点返回“完成”消息后,完成分布式事务。一旦某一个参与者执行失败,协调者告知其他成功的参与者回滚事务并释放资源;
(3)缺点
- 资源被同步阻塞
在数据提交过程中,所有参与者服务器都处于阻塞状态,如果其他线程想访问临界区的资源,需要等待分布式事务执行完成后释放临界区资源;降低了程序并发执行的效率;
- 单点问题
当协调者服务器发生故障,整个分布式系统因缺少协调者而无法进行二阶段提交;
- 提交阶段数据不一致
二阶段提交时,如果由于网络故障,某些参与者没有收到协调者的提交请求,导致这些参与者无法完成最终数据变更,从而造成分布式系统数据不一致;
(4)组件实现
阿里Seata分布式事务组件;
(5)场景示例
一个下单流程,用户在电商网站购买1件100元商品,使用库存系统扣减1,账户系统扣100,订单系统加1。
准备阶段:
1.下单系统插入一条订单记录,不提交;
2.库存系统减1,给记录加锁,写redo和undo日志,不提交;
3.账户系统减100元,给记录加锁,写redo和undo日志,不提交;
提交阶段:
1.下单系统提交订单记录;
2.库存系统提交,释放锁;
3.账户系统提交,释放锁;
2.2.2 三阶段提交(3PC)
(1)说明
3PC相对于2PC多了一个询问阶段,将一阶段拆分为两步:询问、再锁定资源,并引入了超时机制;
不常用,了解原理即可;
(2)图示
(3)原理
- 询问阶段
询问参与者是否可以正常执行,协调者锁定资源,成功返回PreCommit消息,失败返回Abort消息;
- 锁定资源
向参与者发送事务和预提交通知,协调者执行事务,成功返回Commit消息,失败返回Abort消息;
- 提交阶段
向参与者发送事务提交通知,协调者提交事务,成功返回成功消息,失败返回失败消息;
由于网络故障,参与者没有收到协调者发送的提交消息,参与者在等待一定时间后会自动提交事务;
(4)缺点
第三阶超时自动提交会出现数据不一致;
2.2.3 TCC(Try Confirm Cancel)
(1)说明
无论是2PC还是3PC,都存在大粒度锁定资源的问题;
在2PC应用场景示例中,在准备阶段,当数据库给库存减1后,为了维持隔离性,会给该条记录加锁,在提交事务之前,其他事务无法再访问该条记录。但实际上,我们只需要预留其中的1件,不需要锁定整个库存。这是2PC和3PC的局限,因为这两者是资源层的协议,无法提供更灵活的资源锁定操作。为了解决这个问题,TCC应运而生。TCC本质上是2PC协议,但是服务层协议,开发者可以根据业务自由控制资源锁定的粒度;
(2)原理
TCC分为三个动作:
- try,完成业务检查,预留资源;
- confirm,使用预留的资源执行业务操作(需保证幂等性);
- cancel,取消业务操作,释放预留资源(需保证幂等性);
(3)使用场景
还是上面的下单案例。
try:
1.订单系统创建订单;
2.库存系统冻结1件库存;
3.账户系统冻结该用户100元;
confirm:
1.订单系统更新为下单成功;
2.库存系统扣减1件库存;
3.账户系统扣减该用户100元;
cancel:
任何阶段订单处理异常,都会进行如下操作,
1.订单系统更新为支付失败;
2.库存系统回退1件库存;
3.账户系统回退该用户100元;
(4)表结构增加字段
(5)TCC相较于2PC和3PC区别
- 2PC位于资源层,而TCC位于服务层;
- 2PC接口由第三方厂商实现,TCC接口由开发人员实现;
- TCC可以更灵活控制资源锁定粒度;
- TCC对应用侵入性强,各个节点服务的代码都要实现对应分布式事务的三个操作:try、confirm、cancel;
2.3.4 阿里Seata
(1)说明
Seata事务模式是基于2PC来实现的。
Seata官网
Seata事务模式是基于2PC来实现的。
(2)事务角色
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
(3)事务模式
- AT
一阶段 prepare 行为:在本地事务中,一并提交业务数据更新和相应回滚日志记录。
二阶段 commit 行为:马上成功结束,自动 异步批量清理回滚日志。
二阶段 rollback 行为:通过回滚日志,自动 生成补偿操作,完成数据回滚。
依赖数据库本地事务ACID特性,记录undolog日志到undo_log表,用于回滚,回滚后删除对应的日志数据;
写隔离,需要用到本地锁和全局锁。第一阶段先获取本地锁,执行更新,获取全局锁后提交本地事务;
读隔离,默认分布式事务隔离级别为“读未提交”,即第一阶段本地事务已提交,分布式事务未完成时修改的数据能被其他程序读取到。Seata也有“读已提交”的实现;
- TCC
不依赖于底层数据资源的事务支持;
需要开发这自定义实现对应方法逻辑;
一阶段 prepare 行为:调用 自定义 的 prepare 逻辑。
二阶段 commit 行为:调用 自定义 的 commit 逻辑。
二阶段 rollback 行为:调用 自定义 的 rollback 逻辑。
- Saga
适用于业务流程长、业务流程多的长事务场景;
(4)缺点
需要另建一张undo_log表,需要建表权限;
各种模式都有相应的场景限制;
分区故障时,只能通过最终一致性来处理;
(5)代码演示
- 代码结构

DubboAccountServiceStarter,账户服务
DubboOrderServiceStarter,订单服务
DubboStockServiceStarter,库存服务
DubboBusinessTester,测试用户下单
- 表结构
-- seata回滚日志
CREATE TABLE `undo_log` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT comment '主键id',
`branch_id` bigint(20) NOT NULL default 0 comment 'branch_id',
`xid` varchar(100) NOT NULL default '' comment 'xid',
`context` varchar(128) NOT NULL default '' comment 'context',
`rollback_info` longblob comment 'rollback_info',
`log_status` int(11) NOT NULL default 0 comment 'log_status',
`log_created` datetime NOT NULL default now() comment 'log_created',
`log_modified` datetime NOT NULL default now() comment 'log_modified',
`ext` varchar(100) DEFAULT NULL default '' comment 'ext',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 comment 'seata回滚日志';
-- 仓储表
CREATE TABLE `storage_tbl` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT comment '主键id',
`commodity_code` varchar(255) DEFAULT NULL comment 'commodity_code',
`count` int(11) DEFAULT 0 comment 'count',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_storage_tbl_commodity_code` (`commodity_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 comment '仓储表';
-- 订单表
CREATE TABLE `order_tbl` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT comment '主键id',
`user_id` varchar(255) DEFAULT NULL comment 'user_id',
`commodity_code` varchar(255) DEFAULT NULL comment 'commodity_code',
`count` int(11) DEFAULT 0 comment 'count',
`money` int(11) DEFAULT 0 comment 'money',
PRIMARY KEY `uniq_order_tbl_id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 comment '订单表';
-- 账户表
CREATE TABLE `account_tbl` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT comment '主键id',
`user_id` varchar(255) DEFAULT NULL comment 'user_id',
`money` int(11) DEFAULT 0 comment 'money',
PRIMARY KEY `uniq_account_tbl_id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 comment '账户表';
- 执行测试类》下单购买
public static void main(String[] args) {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext(
new String[] {"spring/dubbo-business.xml"});
final BusinessService business = (BusinessService)context.getBean("business");
// 购买
business.purchase("U100001", "C00321", 2);
}
- 分布式事务中间态示例

{
"@class":"io.seata.rm.datasource.undo.BranchUndoLog",
"xid":"172.19.72.30:8091:8467152861968244754",
"branchId":8467152861968244755,
"sqlUndoLogs":[
"java.util.ArrayList",
[
{
"@class":"io.seata.rm.datasource.undo.SQLUndoLog",
"sqlType":"UPDATE",
"tableName":"storage_tbl",
"beforeImage":{
"@class":"io.seata.rm.datasource.sql.struct.TableRecords",
"tableName":"storage_tbl",
"rows":[
"java.util.ArrayList",
[
{
"@class":"io.seata.rm.datasource.sql.struct.Row",
"fields":[
"java.util.ArrayList",
[
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"id",
"keyType":"PRIMARY_KEY",
"type":4,
"value":[
"java.lang.Long",
2
]
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"count",
"keyType":"NULL",
"type":4,
"value":100
}
]
]
}
]
]
},
"afterImage":{
"@class":"io.seata.rm.datasource.sql.struct.TableRecords",
"tableName":"storage_tbl",
"rows":[
"java.util.ArrayList",
[
{
"@class":"io.seata.rm.datasource.sql.struct.Row",
"fields":[
"java.util.ArrayList",
[
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"id",
"keyType":"PRIMARY_KEY",
"type":4,
"value":[
"java.lang.Long",
2
]
},
{
"@class":"io.seata.rm.datasource.sql.struct.Field",
"name":"count",
"keyType":"NULL",
"type":4,
"value":98
}
]
]
}
]
]
}
}
]
]
}
2.3 分布式锁
2.3.1 Redis实现分布式锁
redis为AP架构,redisson客户端自带分布式锁实现;
代码格式:
public void test(){
String key = "xxx";
RLock rLock = null;
try {
rLock = redissonClient.getLock(key);
if(rLock.isLocked()){
throw new BusinessRuntimeException("请不要频繁操作");
}
rLock.lock(5L, TimeUnit.SECONDS);
doBusiness(); // 执行业务逻辑
} finally {
if(rLock!=null && rLock.isHeldByCurrentThread()){
rLock.unlock();
}
}
}
两种获取锁说明:
/**
* 如果没有获取到锁,则继续等待waitTime时间,超过waitTime时间没有获取到锁则返回false,获取到锁后,最大等待leaseTime或执行了unlock方法,无论哪个条件先到都释放锁
*/
boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException;
/**
* 获取到锁后最大等待leaseTime或执行了unlock方法,无论哪个条件先到都释放锁
*/
void lock(long leaseTime, TimeUnit unit);
(2)ZK实现分布式锁;
zk为CP架构,通过zk的临时顺序节点实现分布式锁;
(3)MySql实现分布式锁
性能较低,且对mysql造成压力,一般不推荐;
2.4 最终一致性
2.4.1 多级缓存一致性
(1)关系型数据库存在性能瓶颈
访问量很高的读请求,显然不能直接访问关系型数据库,而是在访问关系型数据库之前加上缓存;
(2)缓存选择
常用的缓存方式分为本地缓存和分布式缓存两种。如果对性能要求不是非常高,优先使用分布式缓存;对于数据实时性和分布式一致性要求不高的可以用本地缓存,比如某些配置,即使不同机器短时间内数据不一致也不影响正常业务流转;
(3)多级缓存
为了提高获取数据的速度,可设置多级缓存,java项目中常用的多级缓存:jvm(guava cache)》redis》mysql;
本地jvm缓存,通过ConcurrentHashMap实现;
应用服务器缓存,其他缓存:浏览器缓存、CDN缓存、Nginx缓存;
(4)多级缓存数据同步
可以基于redis的发布/订阅机制实现分布式系统的本地缓存更新,比MQ更轻量,重新订阅channel不会收到订阅之前的消息,适用于可靠消息不强的场景,本地缓存也要设置过期时间,最坏的结果是达到过期时间后重新拉取数据达到一致性;
(5)缓存双删
当缓存方案为redis+mysql时,如果修改数据,需要对redis和mysql都进行更新
有以下几种方式:
- 更新redis》更新mysql
如果更新redis成功,更新mysql失败,会导致数据不一致;
如果更新redis成功,更新mysql成功,但两个步骤不是原子操作,并发查询时会导致数据不一致。比如redis更新成功,更新mysql正在处理中,此时另一个查询会查询到redis已更新的数据;
- 更新mysql》更新redis
如果更新mysql成功,更新redis失败,会导致数据不一致。可以通过将两个操作放在事务里解决该问题;
如果更新mysql成功,更新redis成功,但两个步骤不是原子操作,并发查询时会导致数据不一致。比如mysql更新成功,更新redis正在处理中,此时另一个查询会查询到redis未更新的数据;
- 删除redis》更新mysql》增加redis
如果删除redis成功,此时有一个查询操作将mysql更新前数据写到redis,mysql更新成功后,redis仍是老数据;
- 删除redis》更新mysql》删除redis
数据一致性效果最好,但是仍会出现操作间隔时间内的数据不一致;
如果redis删除成功,此时有个查询操作将mysql更新前数据写到redis,mysql更新成功后,redis仍是老数据。删除redis后,下一个查询才会将mysql最新数据写到redis;
解决方案:
- 通过canel将mysql数据实时同步到redis,最终一致性
- 更新mysql后将更新消息写入到MQ,消费MQ将数据更新到redis,最终一致性
2.4.2 定时任务查询
通过定时任务查询某类型数据流转状态,如果判断该状态有问题,通过告警信息通知相关人员进行修复处理;
2.4.3 补偿操作
重新执行未完成的子操作,通过修复整个分布式系统达到数据最终一致性;
(1)自动恢复
程序根据不一致的情况,自动完成未完成的操作,比如请求失败后自动重试;
实现案例:
差旅系统下单调用外部接口失败,记录失败日志,包括请求参数和失败次数,通过xxljob定时任务重试,最大重试3次,超过三次仍然失败告警通知手动处理;
(2)通知运营
如果程序无法自动恢复,并且设计时考虑到了不一致的场景,可以提供运营功能,通过运营手动进行补偿;
实现案例:
主播退转会时,异步生成退转会合同,当条件校验失败时会邮件通知产品人员,产品人员根据邮件信息提示处理后,再次触发退转会逻辑;
(3)通知技术
如果程序无法自动恢复,又没有运营功能,必须通过技术手段来解决了。比如执行预提供的补偿入口进行恢复(比如xxljob),或者走代码变更或者数据变更;
实现案例:
差旅同步人员信息到大唐时重试3次后仍失败,会通过xxljob接口手动执行同步;
2.4.4 异步通知
异步通知是设计三方接口时常用的方案,为了提高接口服务的性能,将后续的耗时操作异步处理,及时返回调用方处理成功状态,最终的操作结果通过异步接口再通知调用方,或者提供查询接口给调用方自行查询;
实现案例:
oa系统流程提报成功后,流程为审核中状态,后续如果有状态变动,比如审核通过/审核驳回,都为以异步的方式通知到子系统;
2.4.5 定期校对
定时任务或手动执行校对逻辑,使得上下游数据一致,不一致时根据原因进行补偿操作或者告知相关人员;
比如财务对账系统,定期校对计算数据和业务单据数据的一致性;
2.4.6 可靠消息模式
(1)方案
对于异步操作可以使用MQ消息队列,通过消息队列将调用方和被调用方进行解耦,提高系统响应速度和消峰;
消费方需要保证消息处理幂等;
(2)RocketMQ如何保证消息可靠
- 发送消息和消费消息通过ack机制确认是否发送和消费成功
- 生产端消息发送重试,重试失败需要业务代码兜底
比如业务合同同步广告到下游,发送mq失败会将失败消息存入mq_message表
- 生产端重试导致消息多发,消费端需要做幂等处理
比如根据流程oa号查询业务数据库该消息是否已处理
- 消费端消息确认机制以及消费重试策略
- 消费端消费重试设定次数后仍没消费成功的消息进入死信队列,通过消费死信队列的消息进行业务恢复
- 发布订阅模式,同一个topic能被多个消费者组重复消费,可以指定消息位点再次消费
- RocketMQ支持异步刷盘和同步刷盘两种刷盘方式
异步刷盘(默认):
消息写入到PAGECACHE中立刻返回写成功,当PAGECACHE中的消息积累到一定的量时,触发一次写操作,将 PAGECACHE 中的消息写入到磁盘中。吞吐量大、性能高,数据不可靠;
同步刷盘:
消息写入内存的PAGECACHE后,立刻通知刷盘线程刷盘,然后等待刷盘完成,刷盘线程执行完成后唤醒等待的线程,返回消息写成功的状态。吞吐量不大,数据可靠;
- 运维监控MQ服务端系统资源,比如剩余磁盘空间
2.4.7 本地事务优先
先执行本地事务或耗时操作,再调用远程接口,尽可能保证不会因为本地异常导致数据不一致情况
- 错误示例
begin transaction;
发送消息;
操作数据库;
commit transaction;
- 正确示例
begin transaction;
操作数据库;
发送消息;
commit transaction;
3 总结
- 大多数情况下保证最终一致性即可
- 没有完美的分布式缓存一致性解决方案,当你使用缓存时,就要容忍缓存不一致的存在
- 根据业务场景来决定使用那种一致性方案,不要脱离业务谈架构






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结