您现在的位置是:首页 >技术杂谈 >使用Transformer模型进行计算机视觉任务的端对端对象检测网站首页技术杂谈
使用Transformer模型进行计算机视觉任务的端对端对象检测
简介使用Transformer模型进行计算机视觉任务的端对端对象检测
Transformer模型是google团队在2017在论文attention is all you need中提出的一个用于NLP领域的模型,但是随着VIT模型与Swin Transformer模型的发布,把Transformer模型成功应用到计算机视觉任务中。
上期图文,我们使用hugging face的transformers模型进行了VIT模型的对象分类任务。本期我们再次分享一个成功把Transformer模型应用到计算机对象检测任务模型。此模型是Facebook发布的基于Transformer模型的端对端对象检测任务模型-- DETR(detect Transformer模型)。
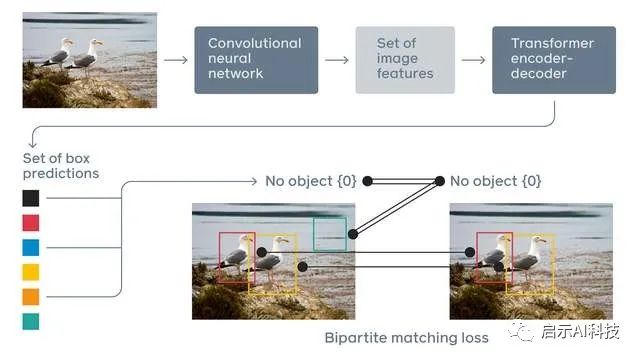
DETR模型首先使用CNN卷积神经网络搜集图片的核心特征点,然后把这些特征点整合起来,通过embedding方法,把特征图片转换到特征向量空间。然后根据标准Transformer模型的编码器与解码器进行注意力机制的计算,最后把计算后的数据进行图片对象的分类,并根据检测到的位置信息,提供对象box区域,方便我们画图。
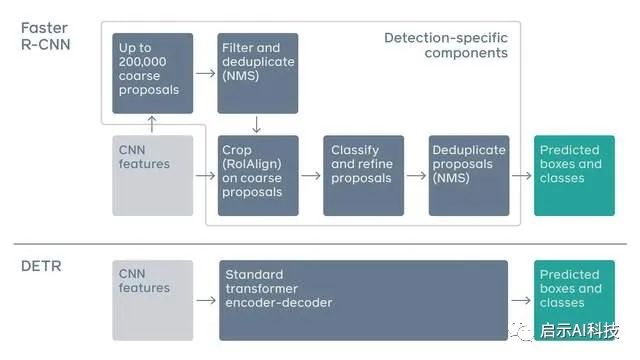
传统的对象检测算法,如 Faster R-CNN,通过过滤大量粗略对象区域来预测对象边界框,这些区域通常是 CNN 特征图片区域。每个选定的区域都用于细化操作,包括在区域定义的位置裁剪 CNN 特征,独立对每个区域进行分类,并细化其位置。最后,应用非最大抑制步
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结