您现在的位置是:首页 >技术交流 >K8s in Action 阅读笔记——【11】Understanding Kubernetes internals网站首页技术交流
K8s in Action 阅读笔记——【11】Understanding Kubernetes internals
K8s in Action 阅读笔记——【11】Understanding Kubernetes internals
11.1 Understanding the architecture
Kubernetes集群分为两个部分:
- k8s控制平面
- 工作节点
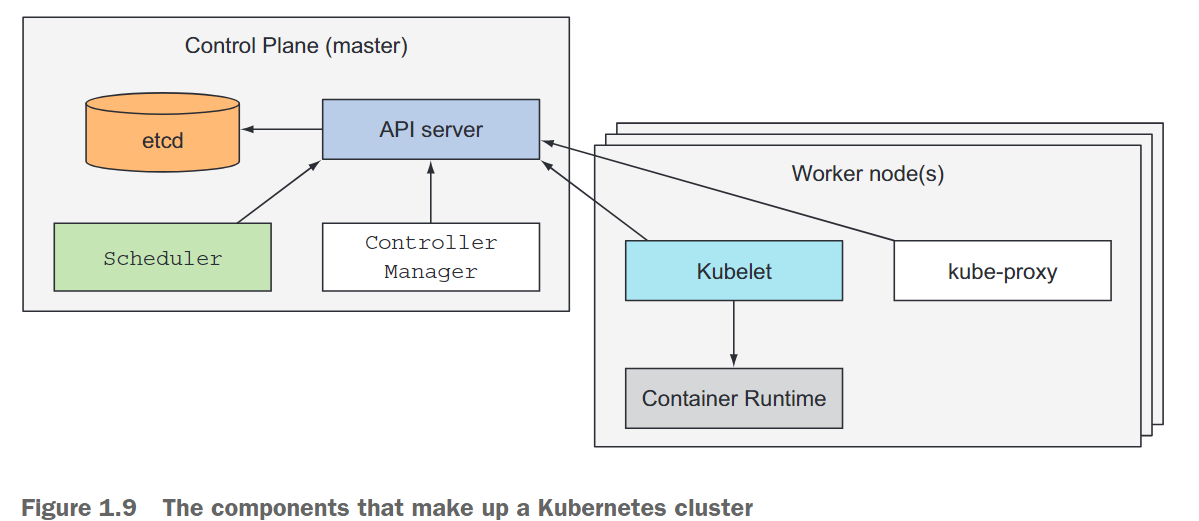
控制平面的组件
构成控制平面的组件有:
- etcd:etcd是一个分布式的持久化键值存储,用于存储集群的配置数据和状态。etcd为控制平面提供了可靠且高可用的存储解决方案。
- API服务器:API服务器是与Kubernetes集群进行交互的主要接口。它暴露了Kubernetes API,并处理与集群管理相关的所有请求和操作。它负责验证和处理API请求,并将数据持久化存储在etcd中。
- 调度器:调度器负责将工作负载(如Pod)分配和放置到集群中可用的工作节点上。它考虑资源需求、节点容量和调度策略等因素,以进行工作负载的优化分配决策。
- 控制器管理器:控制器管理器运行多个控制器,监视集群的状态,并采取必要的操作以维持所需的状态。这些控制器包括节点控制器(Node Controller),负责管理集群中的节点;副本集控制器(ReplicaSet Controller),确保所需数量的副本正在运行;以及端点控制器(Endpoint Controller),管理服务的网络端点。
工作节点的组件
每个工作节点上运行的组件负责运行容器的任务:
- Kubelet:Kubelet是在每个工作节点上运行的代理程序,负责管理节点上的容器。它与控制平面的API服务器通信,接收分配给节点的任务,并确保容器按照期望状态运行。Kubelet还负责监视容器的健康状态、资源使用情况等,并报告给控制平面。
- Kubernetes服务代理(kube-proxy):kube-proxy是运行在每个工作节点上的网络代理,负责处理网络流量路由。它维护网络规则和负载均衡规则,使服务能够通过集群中的其他容器或外部网络访问。kube-proxy通过与内核的通信来实现流量转发和网络代理功能。
- 容器运行时(Docker、rkt或其他):容器运行时负责在节点上创建和管理容器。Kubernetes支持多种容器运行时,包括Docker、rkt、Containerd等。容器运行时负责下载、启动、停止和监视容器,以及管理容器的资源和生命周期。
附加组件
- Kubernetes DNS服务器:Kubernetes DNS服务器提供了集群内部的域名解析服务。它允许通过服务名称访问其他容器和服务,而无需暴露具体的IP地址。Kubernetes DNS服务器帮助容器之间相互发现和通信。
- 仪表盘(Dashboard):Kubernetes仪表盘是一个Web界面,用于可视化和管理集群中的资源。通过仪表盘,用户可以查看和操作集群的各种对象,如容器、服务、Pod等。它提供了对集群的监控、日志查看、资源管理等功能。
- Ingress控制器:Ingress控制器允许将外部流量路由到集群中的服务。它通过定义Ingress规则来管理外部流量的访问方式,可以实现负载均衡、SSL终止、URL路径路由等功能。Ingress控制器使用不同的后端实现,如Nginx Ingress Controller、Traefik、HAProxy等。
- Heapster(将在第14章中讨论):Heapster是一个用于集群监控和性能分析的组件。它收集集群中的资源使用和度量数据,并提供实时监控、报告和分析功能。Heapster可以帮助管理员了解集群的运行状况和资源利用情况。
- 容器网络接口(CNI)网络插件:CNI网络插件是Kubernetes集群中用于管理容器网络的插件体系。它定义了一组规范和接口,使不同的容器运行时可以与网络插件进行交互,实现容器之间的网络通信和互连。CNI网络插件负责创建和配置容器的网络接口、IP地址分配和路由设置等。
11.1.1 The distributed nature of Kubernetes components
先前提到的所有组件都作为独立的进程运行。这些组件及其相互依赖关系如图11.1所示。
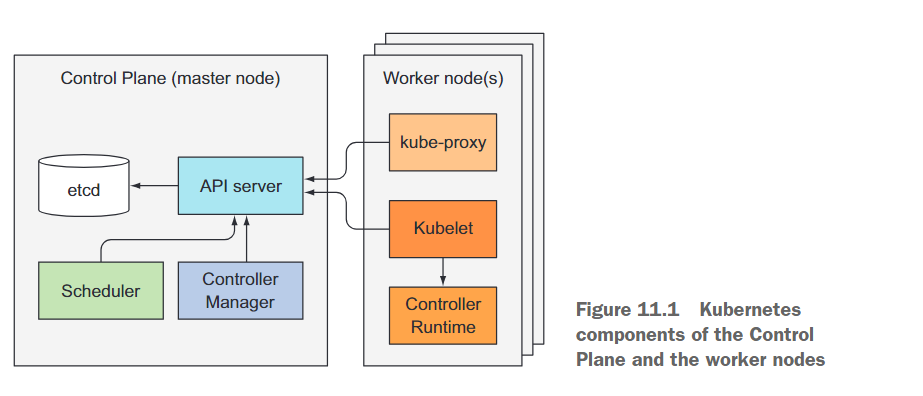
为了获得Kubernetes提供的所有功能,所有这些组件都需要运行。但是,其中几个组件也可以在没有其他组件的情况下独立执行有用的工作。
可以用如下命令查看每个控制面组件的状态:
$ kubectl get componentstatuses NAME STATUS MESSAGE ERROR scheduler Healthy ok controller-manager Healthy ok etcd-0 Healthy {"health":"true"}
组件通信
Kubernetes系统组件只与API服务器进行通信,它们不直接相互通信。API服务器是唯一与etcd通信的组件。其他组件不直接与etcd通信,而是通过与API服务器通信来修改集群状态。
API服务器与其他组件之间的连接几乎总是由组件发起的,如图11.1所示。但是当你使用kubectl获取日志、使用kubectl attach连接到正在运行的容器或使用kubectl port-forward命令时,API服务器会连接到Kubelet。
kubectl attach命令类似于kubectl exec,但它会连接到容器中正在运行的主进程,而不是运行一个额外的进程。
运行单个组件的多个实例
尽管工作节点上的组件需要在同一节点上运行,但控制平面的组件可以轻松地分布在多台服务器上。可以运行多个控制平面组件的实例以确保高可用性。虽然多个etcd和API服务器实例可以同时活动并并行执行它们的工作,但是调度器和控制器管理器只能有一个实例处于活动状态,其他实例处于待机模式。
组件运行原理
控制平面组件以及kube-proxy可以直接部署在系统上,也可以作为Pod运行(如下所示)。
$ kubectl get po -o custom-columns=POD:metadata.name,NODE:spec.nodeName --sort-by spec.nodeName -n kube-system
POD NODE
etcd-yjq-k8s1 yjq-k8s1
kube-proxy-vqx6j yjq-k8s1
chaosblade-tool-bbzw7 yjq-k8s1
kube-controller-manager-yjq-k8s1 yjq-k8s1
kube-apiserver-yjq-k8s1 yjq-k8s1
coredns-59d64cd4d4-264v5 yjq-k8s1
coredns-59d64cd4d4-q4p2m yjq-k8s1
kube-scheduler-yjq-k8s1 yjq-k8s1
chaosblade-tool-488rv yjq-k8s2
kube-proxy-2lnh2 yjq-k8s2
chaosblade-operator-64c9587579-9cj96 yjq-k8s3
chaosblade-tool-rdwx9 yjq-k8s3
kube-proxy-422l7 yjq-k8s3
coredns-59d64cd4d4-qszcl yjq-k8s3
kube-proxy-8mw2q yjq-k8s4
chaosblade-tool-wchxf yjq-k8s4
Kubelet是唯一始终作为常规系统组件运行的组件,而Kubelet会作为Pod运行所有其他组件。为了将控制平面组件作为Pod运行,Kubelet也会部署在主节点上。
正如列表中所示,所有控制平面组件都作为Pod在主节点上运行。有三个工作节点,每个节点都运行kube-proxy。
可以使用-o custom-columns选项告诉kubectl显示自定义列,并使用--sort-by对资源列表进行排序。
11.1.2 How Kubernetes uses etcd
在本书中创建的所有对象——Pod、ReplicationController、Service、Secret等等——都需要以持久方式存储,以便它们的清单在API服务器重新启动和故障时仍然存在。为此,Kubernetes使用etcd作为快速、分布式和一致性的键值存储。由于它是分布式的,你可以运行多个etcd实例,以提供高可用性和更好的性能。
唯一直接与etcd通信的组件是Kubernetes API服务器。所有其他组件通过API服务器间接地读取和写入数据到etcd。这带来了一些好处,其中包括更强大的乐观锁定系统和验证机制;并且通过将实际存储机制与所有其他组件抽象出来,将来替换存储机制变得更加简单。值得强调的是,etcd是Kubernetes存储集群状态和元数据的唯一位置。
乐观并发控制(有时称为乐观锁定)是一种方法,不是锁定数据片段并阻止在放置锁定期间对其进行读取或更新,而是数据片段包含一个版本号。每次更新数据时,版本号都会增加。在更新数据时,将检查版本号,以查看在客户端读取数据和提交更新之间是否增加。如果发生这种情况,更新将被拒绝,客户端必须重新读取新数据并尝试再次更新。
结果是当两个客户端尝试更新相同的数据条目时,只有第一个成功。
所有Kubernetes资源都包括一个
metadata.resourceVersion字段,客户端在更新对象时需要将其传递回API服务器。如果版本与存储在etcd中的版本不匹配,API服务器将拒绝更新。
资源如何在etcd中存储
etcd v2将键存储在层次化键空间中,使得键值对类似于文件系统中的文件。etcd中的每个键要么是一个目录,其中包含其他键,要么是一个具有相应值的常规键。etcd v3不支持目录,但由于键格式保持不变(键可以包含斜杠),你仍然可以将它们视为分组到目录中。Kubernetes将其所有数据存储在etcd的/registry下。下面的列表显示了存储在/registry下的键列表。
$ etcdctl get --prefix /registry --keys-only
......
/registry/services/specs/monitoring/prometheus-k8s
/registry/services/specs/monitoring/prometheus-operated
/registry/services/specs/monitoring/prometheus-operator
/registry/statefulsets/default/kubia
/registry/statefulsets/monitoring/alertmanager-main
......
具体访问方式:https://www.cnblogs.com/zouzou-busy/p/16368125.html
你将会发现这些键对应于你在前几章中学到的资源类型。
下面的列表显示了/registry/pods目录的内容。
$ etcdctl get --prefix /registry/pods --keys-only
/registry/pods/default/kubia-0
/registry/pods/default/kubia-1
/registry/pods/default/kubia-2
/registry/pods/experiment/adservice-7f7875977d-wbtp4
/registry/pods/experiment/cartservice-fc4f54c96-s2xt4
/registry/pods/experiment/checkoutservice-5bc8665995-8k672
......
从名称可以推断出Pod按命名空间存储。下面的列表显示了/registry/pods/default目录中的条目。
$ etcdctl get --prefix /registry/pods/default --keys-only
/registry/pods/default/kubia-0
/registry/pods/default/kubia-1
/registry/pods/default/kubia-2
每个条目对应一个单独的Pod。这些不是目录,而是键值条目。
确保存储对象的一致性和有效性
在第1章中提到的Google的Borg和Omega系统是Kubernetes的基础,就像Kubernetes一样,Omega也使用一个集中存储来保存集群的状态,但与此相反,多个Control Plane组件直接访问该存储。所有这些组件都需要确保它们都遵循相同的乐观锁定机制以正确处理冲突。如果有一个组件没有完全遵守这个机制,可能会导致数据不一致。
Kubernetes通过要求所有其他Control Plane组件都通过API服务器来改进这一点。这样,对集群状态的更新始终是一致的,因为乐观锁定机制在一个地方实现,所以错误的可能性更小,如果有的话。API服务器还确保写入存储的数据始终有效,并且对数据的更改只能由授权的客户端执行。
确保etcd集群化时的一致性
为了确保高可用性,通常会运行多个etcd实例。多个etcd实例需要保持一致。这样的分布式系统需要就实际状态达成共识。etcd使用RAFT共识算法来实现这一点,它确保在任何给定时刻,每个节点的状态要么是大多数节点认可的当前状态,要么是之前达成一致的状态之一。
连接到etcd集群的不同节点的客户端将看到实际的当前状态或过去的某个状态(在Kubernetes中,唯一的etcd客户端是API服务器,但可能存在多个实例)。
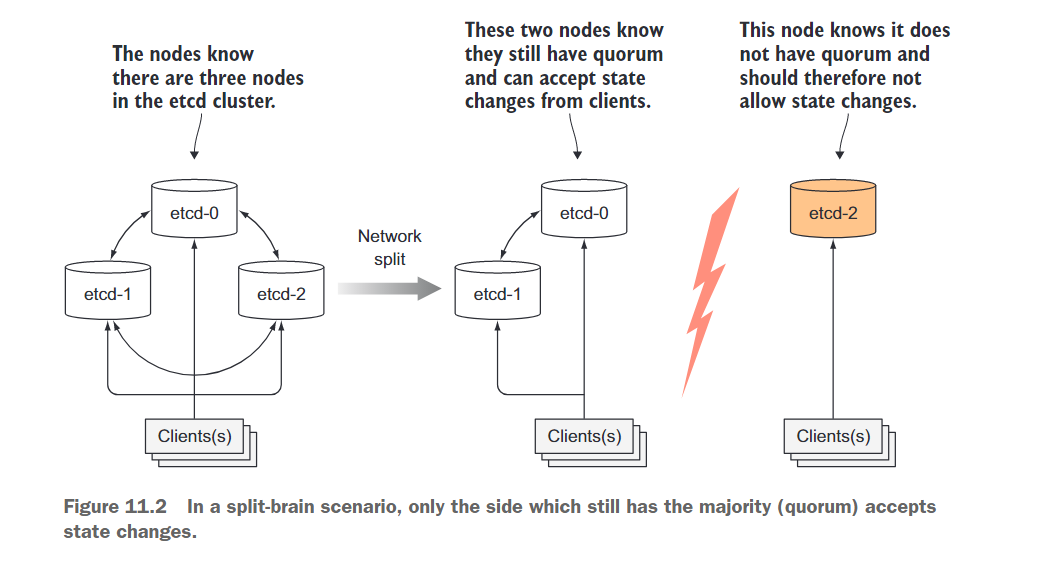
共识算法需要集群达成多数派(或法定人数)才能进入下一个状态。因此,如果集群分裂为两个不连通的节点组,两个组中的状态永远不会发散,因为要从上一个状态过渡到新状态,需要有超过一半的节点参与状态更改。如果一个组包含大多数节点,另一个组显然不包含。第一组可以修改集群状态,而另一组则不能。当两个组重新连接时,第二个组可以赶上第一个组的状态(参见图11.2)。
11.1.3 What the API server does
Kubernetes API服务器是所有其他组件和客户端(如kubectl)使用的中心组件。它通过RESTful API为查询和修改集群状态提供了CRUD(创建、读取、更新、删除)接口。它将状态存储在etcd中。
除了提供一种在etcd中存储对象的一致方式外,API服务器还执行对象的验证,因此客户端无法存储配置不正确的对象(如果直接写入存储,它们可能会这样做)。除了验证,它还处理乐观锁定,以确保在并发更新的情况下,对象的更改不会被其他客户端覆盖。
API服务器的一个客户端是你从本书开始使用的命令行工具kubectl。例如,当从JSON文件创建资源时,kubectl通过HTTP POST请求将文件的内容发布到API服务器。图11.3显示了当API服务器接收请求时内部发生的情况。接下来的几段中会详细解释这个过程。
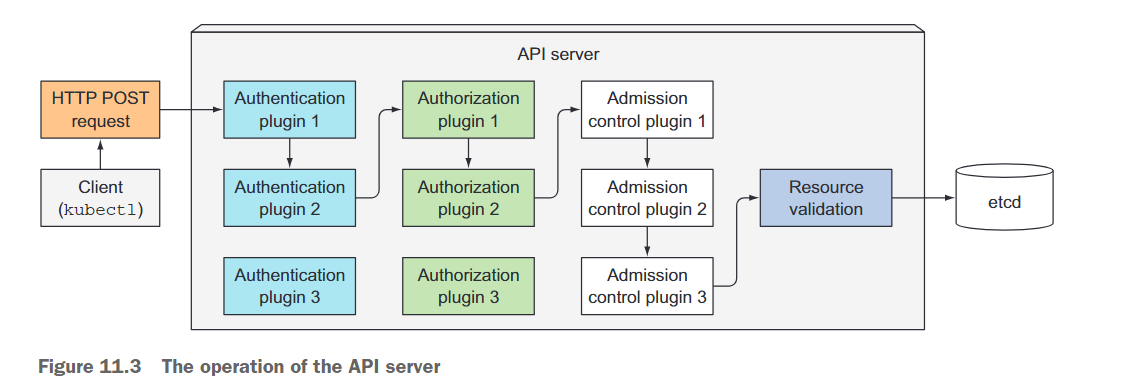
使用身份验证插件对客户端进行身份验证
首先,API服务器需要对发送请求的客户端进行身份验证。这是通过在API服务器中配置一个或多个身份验证插件来完成的。API服务器依次调用这些插件,直到其中一个确定了发送请求的用户。它通过检查HTTP请求来进行判断。
根据身份验证方法,用户可以从客户端的证书或HTTP头(如授权头,在第8章中使用过)中提取客户端的用户名、用户ID和所属的用户组。然后,这些数据将用于下一阶段,即授权。
使用授权插件对客户端进行授权
除了身份验证插件外,API服务器还配置了一个或多个授权插件。它们的工作是确定经过身份验证的用户是否可以对所请求的资源执行所请求的操作。例如,当创建Pod时,API服务器会依次查询所有授权插件,以确定用户是否可以在请求的命名空间中创建Pod。只要有一个插件表示用户可以执行该操作,API服务器就会继续进行下一阶段的处理。
使用准入控制插件验证和/或修改请求中的资源
如果请求试图创建、修改或删除资源,请求将通过准入控制(Admission Control)进行处理。同样,服务器配置了多个准入控制插件。这些插件可以出于不同的原因修改资源。它们可以将资源规范中缺失的字段初始化为配置的默认值,甚至覆盖它们。它们甚至可以修改请求中未包含的其他相关资源,并且出于任何原因都可以拒绝请求。资源会依次通过所有准入控制插件进行处理。
当请求仅尝试读取数据时,请求不会经过准入控制。
准入控制插件的示例包括:
- AlwaysPullImages:将Pod的imagePullPolicy覆盖为Always,每次部署Pod时强制拉取镜像。
- ServiceAccount:将默认服务账户应用于未显式指定的Pod。
- NamespaceLifecycle:阻止在正在删除的命名空间和不存在的命名空间中创建Pod。
- ResourceQuota:确保某个命名空间中的Pod仅使用分配给该命名空间的CPU和内存。我们将在第14章中进一步学习这个功能。
验证资源并持久存储
在让请求通过所有准入控制插件之后,API服务器随后验证对象,将其存储在etcd中,并向客户端返回响应。
11.1.4 Understanding how the API server notifies clients of resource changes
API服务器除了我们讨论过的功能之外,并不执行其他任务。例如,当创建ReplicaSet资源时,它不会创建Pod,也不会管理服务的终端点。这是Controller Manager中的控制器所做的工作。
API服务器甚至不会告诉这些控制器要做什么。它所做的只是使这些控制器和其他组件能够观察到已部署资源的变化。控制平面组件可以请求在资源创建、修改或删除时收到通知。这使得组件能够根据集群元数据的变化执行所需的任务。
客户端通过打开与API服务器的HTTP连接来监听变化。通过该连接,客户端将接收到所监听对象的修改流。每当对象更新时,服务器会将对象的新版本发送给所有连接的客户端,这些客户端都在监听该对象。图11.4展示了客户端如何监听Pod的变化,以及对其中一个Pod的更改是如何存储到etcd中并转发给所有在观察Pod的客户端。
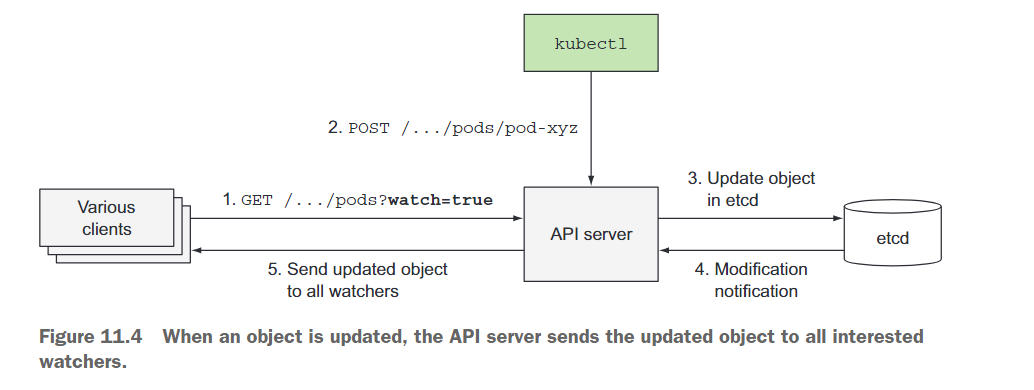
API服务器的一个客户端就是kubectl工具,它也支持监听资源的变化。例如,当部署一个Pod时,你不需要通过重复执行kubectl get pods来不断轮询Pod列表。相反,你可以使用–watch选项,这样当Pod被创建、修改或删除时,你会收到通知,如下面的示例所示:
$ kubectl get pods --watch
NAME READY STATUS RESTARTS AGE
kubia-159041347-14j3i 0/1 Pending 0 0s
kubia-159041347-14j3i 0/1 Pending 0 0s
kubia-159041347-14j3i 0/1 ContainerCreating 0 1s
kubia-159041347-14j3i 1/1 Running 0 5s
kubia-159041347-14j3i 0/1 Terminating 0 17s
你甚至可以让kubectl在每个监听事件上打印整个YAML,如下所示:
$ kubectl get pods -o yaml --watch
调度器也使用了监听机制,它是下一个要介绍的控制平面组件。
11.1.5 Understanding the Scheduler
如前所述,通常情况下,你不需要指定Pod应该运行在哪个集群节点上,这是调度器的任务。从表面上看,调度器的操作似乎很简单。它只需要通过API服务器的监听机制等待新创建的Pod,并为每个没有分配节点的新Pod分配一个节点。
调度器并不会指示所选节点(或运行在该节点上的Kubelet)来运行Pod。调度器所做的只是通过API服务器更新Pod的定义。然后API服务器通过之前描述的监听机制通知Kubelet(再次通过该机制)该Pod已被调度。一旦目标节点上的Kubelet看到Pod已被调度到该节点上,它就会创建并运行Pod的容器。
虽然对调度过程的粗略观点似乎很简单,但实际上选择最佳节点来运行Pod的任务并不那么简单。当然,最简单的调度器可能会随机选择一个节点,并不关心该节点上已运行的Pod。另一方面,调度器可以使用先进的技术,如机器学习,来预测接下来几分钟或几小时将要调度的Pod的类型,并调度Pod以最大化未来的硬件利用率,而无需重新调度现有的Pod。Kubernetes的默认调度器则介于这两者之间。
默认调度算法
节点的选择可以分为两个部分,如图11.5所示:
- 过滤节点列表,以获取可接受的节点列表,Pod可以被调度到这些节点上。
- 对可接受的节点进行优先级排序,并选择最佳节点。如果有多个节点具有最高分数,则使用轮询的方式确保Pod均匀地部署在这些节点上。
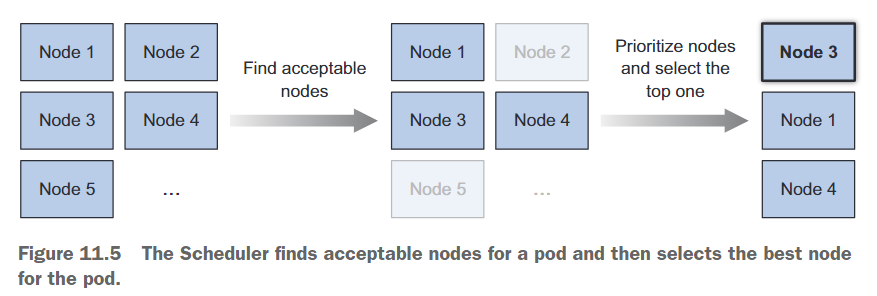
查找可接受的节点
为了确定哪些节点适合承载Pod,调度器会将每个节点通过一系列配置的谓词函数进行检查。这些函数会检查以下几个方面:
- 节点能否满足Pod对硬件资源的需求?你将在第14章中学习如何指定这些需求。
- 节点是否资源不足(是否报告内存或磁盘压力条件)?
- 如果Pod请求被调度到特定节点(按名称),是否是该节点?
- 节点是否具有与Pod规范中的节点选择器(如果定义了选择器)匹配的标签?
- 如果Pod请求绑定到特定的主机端口(在第13章中讨论),该节点上的该端口是否已被占用?
- 如果Pod请求某种类型的卷,该卷是否可以在该节点上挂载给该Pod,或者该节点上的其他Pod是否已经使用了相同的卷?
- Pod是否容忍节点的污点?污点和容忍在第16章中解释。
- Pod是否指定了节点和/或Pod的亲和性或反亲和性规则?如果是,将Pod调度到该节点是否会违反这些规则?这也在第16章中解释。
所有这些检查都必须通过,节点才有资格承载该Pod。在对每个节点执行这些检查之后,调度器会得到一个节点的子集。这些节点中的任何一个都可以运行该Pod,因为它们具有足够的可用资源,并符合在Pod定义中指定的所有要求。
为Pod选择最佳节点
尽管所有这些节点都是可接受的并且能够运行该Pod,但有些节点可能比其他节点更合适。假设你有一个由两个节点组成的集群。这两个节点都是可行的选择,但一个节点已经运行了10个Pod,而另一个节点,出于某种原因,目前没有运行任何Pod。在这种情况下,很明显调度器应该优先选择第二个节点。
如果这两个节点是由云基础设施提供的,那么为了节省成本,将Pod调度到第一个节点并释放第二个节点给云提供商可能会更好。
Pod的高级调度
考虑另一个例子。假设有多个Pod的副本。理想情况下,你希望它们尽可能分布在多个节点上,而不是都调度到一个节点上。如果该节点发生故障,那么由这些Pod支持的服务将变得不可用。如果Pod分布在不同的节点上,单个节点故障几乎不会对服务的容量造成影响。
属于同一个Service或ReplicaSet的Pod默认会分布在多个节点上。但不能保证始终如此。但是,你可以通过定义Pod的亲和性和反亲和性规则来强制Pod在集群中分散或保持在一起。
即使是这两个简单的情况,也展示了调度的复杂性,因为它取决于多种因素。因此,可以根据特定需求或基础设施要求对调度器进行配置,甚至可以完全替换为自定义实现。你也可以在没有调度器的情况下运行Kubernetes集群,但那样的话,你将不得不手动执行调度。
使用多个调度器
不仅可以在集群中运行单个调度器,还可以运行多个调度器。然后,对于每个Pod,你可以通过在Pod规范中设置schedulerName属性来指定应该调度该特定Pod的调度器。
没有设置该属性的Pod将使用默认调度器进行调度,设置schedulerName为default-scheduler的Pod也是如此。默认调度器会忽略其他所有的Pod,因此这些Pod需要手动调度或由另一个监视此类Pod的调度器进行调度。
你可以实现自己的调度器并将其部署在集群中,或者可以使用不同的配置选项部署额外的Kubernetes调度器实例。
11.1.6 Introducing the controllers running in the Controller Manager
正如之前提到的,API服务器除了将资源存储在etcd中并通知客户端有关更改之外,不会执行任何其他操作。调度程序只是为Pod分配一个节点,因此你需要其他主动组件来确保系统的实际状态向通过API服务器部署的期望状态收敛。这项工作由在控制器管理器内运行的控制器完成。
当前,单个控制器管理器进程结合了执行各种协调任务的多个控制器。最终,这些控制器将被拆分为单独的进程,使你能够根据需要替换每个控制器的自定义实现。这些控制器的列表包括:
- Replication Manager(用于ReplicationController资源的控制器)
- ReplicaSet、DaemonSet和Job控制器
- Deployment控制器
- StatefulSet控制器
- Node控制器
- Service控制器
- Endpoints控制器
- Namespace控制器
- PersistentVolume控制器
- 其他控制器
从每个控制器的名称中,你可以看出它们的功能。从列表中,你可以看出几乎为你可以创建的每个资源都有一个控制器。资源是描述应在集群中运行的内容,而控制器是作为部署资源结果而执行实际工作的主动Kubernetes组件。
控制器的工作方式
控制器执行许多不同的操作,但它们都会监视API服务器上资源(如Deployments、Services等)的更改,并对每个更改执行相应的操作,无论是创建新对象、更新现有对象还是删除对象。大部分情况下,这些操作包括创建其他资源或更新被监视资源本身(例如,更新对象的状态)。
通常情况下,控制器会运行一个协调循环(reconciliation loop),用于将实际状态与期望状态(在资源的spec部分中指定)进行协调,并将新的实际状态写入资源的status部分。控制器使用watch机制来接收变更通知,但由于使用watch不能保证控制器不会错过事件,它们还会定期执行重新列举(re-list)操作,以确保没有漏掉任何内容。
控制器之间从不直接通信,它们甚至不知道其他控制器的存在。每个控制器连接到API服务器,并通过11.1.3节中描述的watch机制请求在任何类型的资源列表发生更改时得到通知,而这些资源类型是该控制器负责的。
复制管理器
Replication Manager是使ReplicationController资源变得活跃的控制器。在第4章中我们讨论过ReplicationControllers的工作原理。实际工作并非由ReplicationControllers完成,而是由Replication Manager执行。让我们快速回顾一下控制器的功能,因为这将帮助你理解其他控制器的工作原理。
在第4章中,我们说ReplicationController的操作可以被视为一个无限循环,其中在每次迭代中,控制器会找到与其pod选择器匹配的Pod数目,并将该数目与期望的副本数进行比较。
现在你已经了解了API服务器如何通过watch机制通知客户端,很明显控制器不会在每次迭代中轮询Pod,而是通过watch机制被通知可能影响期望副本数或匹配Pod数目的每个变化(参见图11.6)。任何这样的变化都会触发控制器重新检查期望与实际副本数,并采取相应的操作。
你已经知道当运行的Pod实例过少时,ReplicationController会运行额外的实例。但它并不实际运行这些实例。它会创建新的Pod清单,将其发布到API服务器,并让Scheduler和Kubelet负责调度和运行Pod的工作。
Replication Manager通过API服务器来操作Pod API对象来执行其工作。这就是所有控制器的操作方式。
Deployment控制器
Deployment控制器负责将部署的实际状态与相应的Deployment API对象中指定的期望状态保持同步。
每当修改Deployment对象(如果修改应该影响已部署的Pod)时,Deployment控制器会执行新版本的滚动更新。它通过创建一个ReplicaSet,并根据Deployment中指定的策略适当地调整新旧ReplicaSet的规模,直到所有旧的Pod都被替换为新的Pod。它不直接创建任何Pod。
StatefulSet控制器
与ReplicaSet控制器和其他相关控制器类似,StatefulSet控制器根据StatefulSet资源的规范创建、管理和删除Pod。但与其他控制器只管理Pod不同,StatefulSet控制器还为每个Pod实例实例化和管理PersistentVolumeClaims。
Node控制器
Node控制器管理Node资源,描述集群的工作节点。除其他功能外,Node控制器还将Node对象的列表与实际运行在集群中的机器列表保持同步。它还监视每个节点的健康状况,并从无法访问的节点中驱逐Pod。
Node控制器并不是唯一可以对Node对象进行更改的组件。它们也可以被Kubelet更改,并且显然也可以通过REST API调用由用户进行修改。
Service控制器
Service控制器是在创建或删除LoadBalancer类型的Service时向基础设施请求和释放负载均衡器的组件。
Endpoints控制器
正如你所记得的,Service并不直接链接到Pod,而是包含一个端点(IP和端口)列表,该列表根据Service上定义的Pod选择器手动或自动创建和更新。Endpoints控制器是将端点列表与匹配标签选择器的Pod的IP和端口保持持续更新的主动组件。
如图11.7所示,该控制器同时监视Service和Pod。当Service被添加、更新或Pod被添加、更新或删除时,它选择与Service的Pod选择器匹配的Pod,并将它们的IP和端口添加到Endpoints资源中。请记住,Endpoints对象是一个独立的对象,因此如果需要,控制器会创建它。同样,当Service被删除时,它也会删除Endpoints对象。
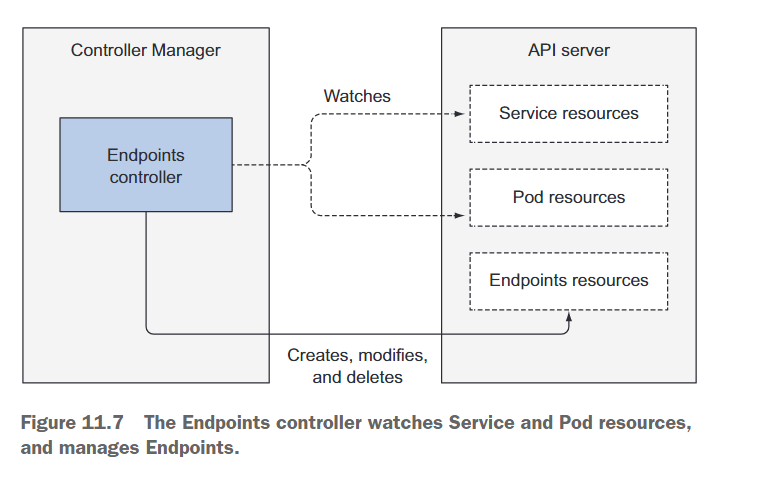
Namespace控制器
大多数资源都属于特定的命名空间。当一个Namespace资源被删除时,该命名空间中的所有资源也必须被删除。这就是Namespace控制器的工作。当它被通知删除一个Namespace对象时,它通过API服务器删除属于该命名空间的所有资源。
PersistentVolume控制器
在第6章中,你学习了关于PersistentVolumes和PersistentVolumeClaims的知识。一旦用户创建了一个PersistentVolumeClaim,Kubernetes必须找到一个合适的PersistentVolume并将其绑定到该声明。这是由PersistentVolume控制器执行的。
当出现一个PersistentVolumeClaim时,控制器通过选择最小的PersistentVolume并且其访问模式与声明中请求的访问模式匹配,并且声明的容量大于声明中请求的容量来找到最佳匹配的PersistentVolume。它通过按升序容量为每个访问模式维护一个有序的PersistentVolume列表,并从列表中返回第一个卷来实现这一点。
然后,当用户删除PersistentVolumeClaim时,该卷将解绑并根据卷的回收策略(保留不变、删除或清空)进行回收。
总结
所有这些控制器通过API服务器操作API对象。它们不直接与Kubelet进行通信,也不向其发出任何指令。实际上,它们甚至不知道Kubelet的存在。控制器在更新API服务器中的资源后,Kubelet和Kubernetes服务代理会独立地执行各自的任务,例如启动Pod的容器、附加网络存储,或者在服务的情况下,设置跨Pod的实际负载均衡。
11.1.7 What the Kubelet does
与所有的控制器不同,Kubelet和服务代理都运行在工作节点上,而不是Kubernetes控制平面的主节点上。那么Kubelet具体做什么呢?
简而言之,Kubelet是负责工作节点上所有运行任务的组件。它的首要任务是通过在API服务器中创建一个Node资源来注册所在的节点。然后,它需要不断监视API服务器,以查找已调度到该节点的Pod,并启动Pod中的容器。它通过告知配置的容器运行时(如Docker、CoreOS的rkt或其他容器运行时)根据特定的容器镜像运行容器来完成此任务。Kubelet会持续监视运行中的容器,并将它们的状态、事件和资源消耗报告给API服务器。
Kubelet还负责运行容器的活跃性探测,并在探测失败时重新启动容器。最后,当从API服务器中删除Pod时,Kubelet会终止容器,并通知服务器该Pod已终止。
尽管Kubelet与Kubernetes API服务器进行通信并从那里获取Pod的清单文件,但它也可以根据特定本地目录中的Pod清单文件运行Pod,如图11.8所示。这个功能用于将控制平面组件的容器化版本作为Pod运行,就像在本章开头所见的那样。
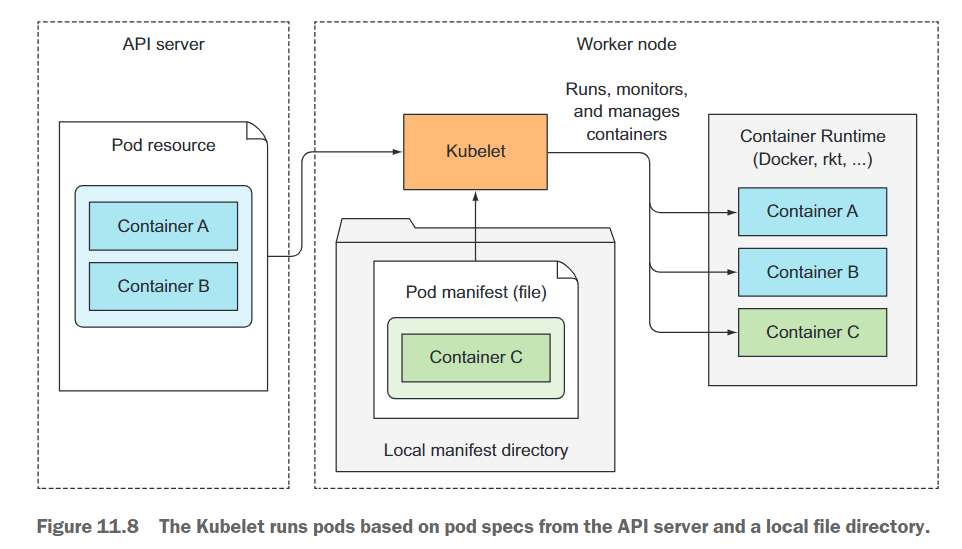
11.1.8 The role of the Kubernetes Service Proxy
除了Kubelet之外,每个工作节点还运行着kube-proxy,其作用是确保客户端能够通过Kubernetes API连接到你定义的服务。kube-proxy确保连接到服务的IP和端口最终会到达支持该服务的一个Pod(或其他非Pod服务端点)。当一个服务由多个Pod支持时,代理会在这些Pod之间执行负载均衡。
kube-proxy最初的实现是基于用户空间的代理。它使用一个实际的服务器进程来接受连接并将其代理到Pod上。为了拦截目标为服务IP的连接,代理配置了iptables规则(iptables是管理Linux内核的数据包过滤功能的工具),将连接重定向到代理服务器。图11.9显示了用户空间代理模式的简略图示。
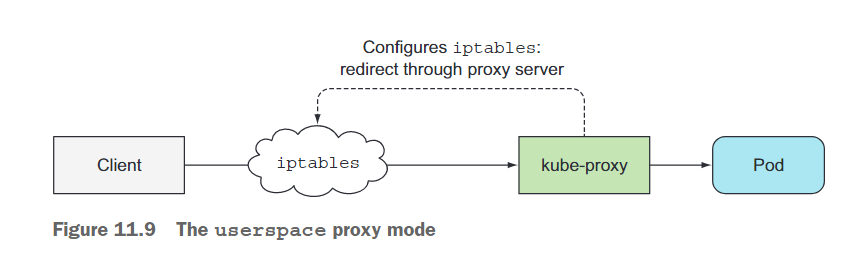
kube-proxy得名于它是一个真正的代理,但是当前性能更好的实现方式只使用iptables规则将数据包重定向到随机选择的后端Pod,而无需经过实际的代理服务器。这种模式称为iptables代理模式,如图11.10所示。
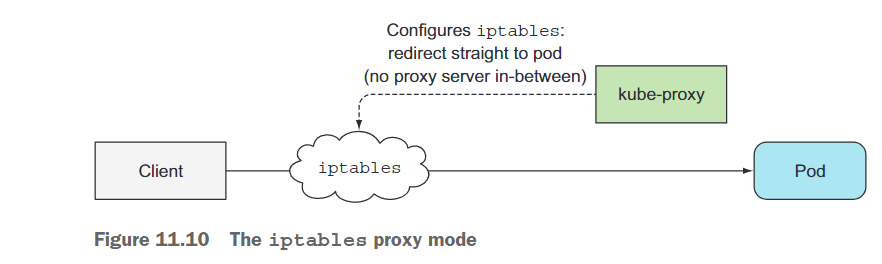
这两种模式之间的主要区别是数据包是否经过kube-proxy并在用户空间进行处理,还是仅由内核(在内核空间)处理。这对性能有很大影响。
另一个较小的区别是用户空间代理模式以真正的轮询方式平衡连接到各个Pod,而iptables代理模式不会这样做-它会随机选择Pod。当只有少数客户端使用服务时,它们可能无法均匀地分布在各个Pod上。例如,如果一个服务有两个支持的Pod,但只有五个左右的客户端,可能会看到四个客户端连接到Pod A,而只有一个客户端连接到Pod B。当客户端或Pod数量较多时,这个问题就不太明显了。
11.1.9 Introducing Kubernetes add-ons
附加组件实现诸如对Kubernetes服务进行DNS查找、通过单个外部IP地址公开多个HTTP服务、Kubernetes Web仪表板等功能。
DNS 服务器工作原理
集群中的所有Pod默认配置为使用集群的内部DNS服务器。这使得Pod可以轻松通过名称查找服务,甚至可以在无头服务的情况下查找Pod的IP地址。
DNS服务器Pod通过kube-dns服务公开,允许该Pod像其他任何Pod一样在集群中移动。该服务的IP地址被指定为部署在集群中的每个容器内的/etc/resolv.conf文件中的nameserver。kube-dns Pod使用API服务器的watch机制来观察服务和端点的变化,并在每次变化时更新其DNS记录,以便其客户端始终获取(相对)最新的DNS信息。相对是因为在Service或Endpoints资源更新和DNS Pod接收到watch通知之间的时间内,DNS记录可能无效。
Ingress控制器的工作原理
与DNS插件不同,你会发现几种不同的Ingress控制器实现,但它们大部分工作方式相同。Ingress控制器运行一个反向代理服务器(例如Nginx),并根据集群中定义的Ingress、Service和Endpoints资源进行配置。因此,控制器需要观察这些资源(再次通过watch机制)并在每次更改时修改代理服务器的配置。
尽管Ingress资源的定义指向一个Service,但Ingress控制器直接将流量转发到服务的Pod,而不经过服务IP。
11.2 How controllers cooperate
11.2.1 Understanding which components are involved
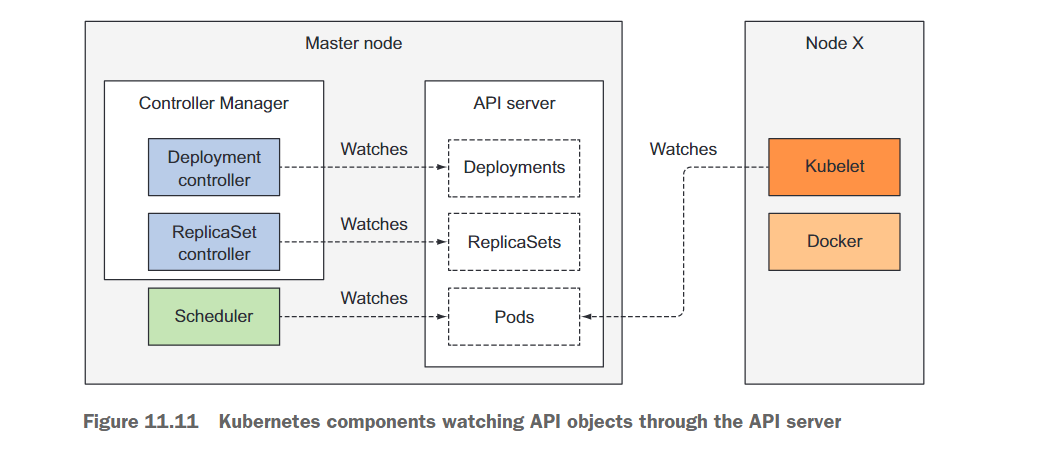
在你开始整个过程之前,控制器、调度器和Kubelet已经在API服务器上监视其各自资源类型的变化。这在图11.11中有所展示。图中描绘的各个组件将各自在即将触发的过程中扮演角色。图中没有包括etcd,因为它被隐藏在API服务器后面,你可以将API服务器视为对象存储的地方。
11.2.2 The chain of events
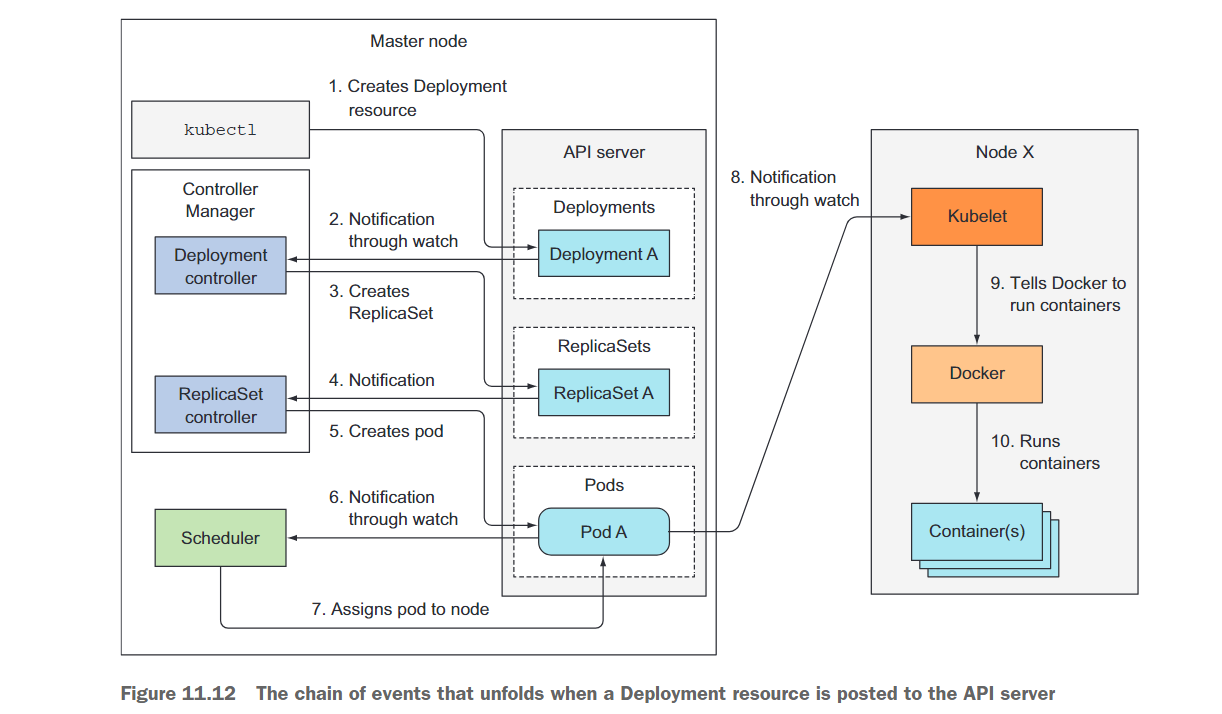
想象一下,你准备了包含Deployment清单的YAML文件,并准备通过kubectl将其提交给Kubernetes。kubectl通过HTTP POST请求将清单发送到Kubernetes API服务器。API服务器验证Deployment规范,将其存储在etcd中,并向kubectl返回响应。现在,一系列事件开始展开,如图11.12所示。
Deployment控制器创建ReplicaSet
API服务器通过其观察机制立即通知所有通过API服务器观察Deployment列表的客户端新创建的Deployment资源。其中一个客户端就是Deployment控制器,正如我们之前讨论过的,它是负责处理Deployments的主动组件。
正如你在第9章中可能记得的那样,一个Deployment由一个或多个ReplicaSet支持,而ReplicaSet则创建实际的Pod。当Deployment控制器检测到新的Deployment对象时,它会为当前Deployment的规范创建一个ReplicaSet。这涉及通过Kubernetes API创建一个新的ReplicaSet资源。Deployment控制器根本不处理单个的Pod。
ReplicaSet控制器创建Pod资源
新创建的ReplicaSet随后会被ReplicaSet控制器接管,该控制器会监视API服务器中ReplicaSet资源的创建、修改和删除。控制器会根据ReplicaSet中定义的副本数量和Pod选择器来验证是否有足够的现有Pod与选择器匹配。
然后,控制器会根据ReplicaSet中的Pod模板创建Pod资源(在Deployment控制器创建ReplicaSet时,Pod模板是从Deployment中复制过来的)。
调度器将Pod调度到一个节点
这些新创建的Pod现在存储在etcd中,但它们还缺少一个重要的信息——它们尚未与任何节点关联。它们的nodeName属性尚未设置。Scheduler会监视这样的Pod,当遇到这样的Pod时,它会选择最佳的节点,并将Pod分配给该节点。现在,Pod的定义中包含了它应该运行在的节点的名称。
到目前为止,所有的操作都发生在Kubernetes控制平面中。参与整个过程的控制器除了通过API服务器更新资源之外,没有进行任何实质性的操作。
Kubelet运行Pod的容器
将Pod调度到特定节点后,该节点上的Kubelet终于可以开始工作了。Kubelet会监视API服务器上Pod的更改,当看到一个新的Pod被调度到它的节点时,它会检查Pod的定义,并指示Docker或其他容器运行时启动Pod的容器。容器运行时会运行这些容器。
11.2.3 Observing cluster events
控制平面组件和Kubelet在执行操作时会向API服务器发出事件。它们通过创建事件资源来实现这一点,这些资源与其他Kubernetes资源类似。在使用kubectl describe查看资源时,你可能已经看到了与特定资源相关的事件,但你也可以直接使用kubectl get events命令检索事件。
使用kubectl get查看事件有些麻烦,因为它们没有按照正确的时间顺序显示。相反,如果一个事件发生多次,只会显示一次事件,并显示首次观察到事件的时间、最后观察到事件的时间以及事件发生的总次数。幸运的是,通过使用–watch选项来观察事件,可以更容易地了解集群中正在发生的情况。
下面的列表显示了之前描述的过程中发出的事件:
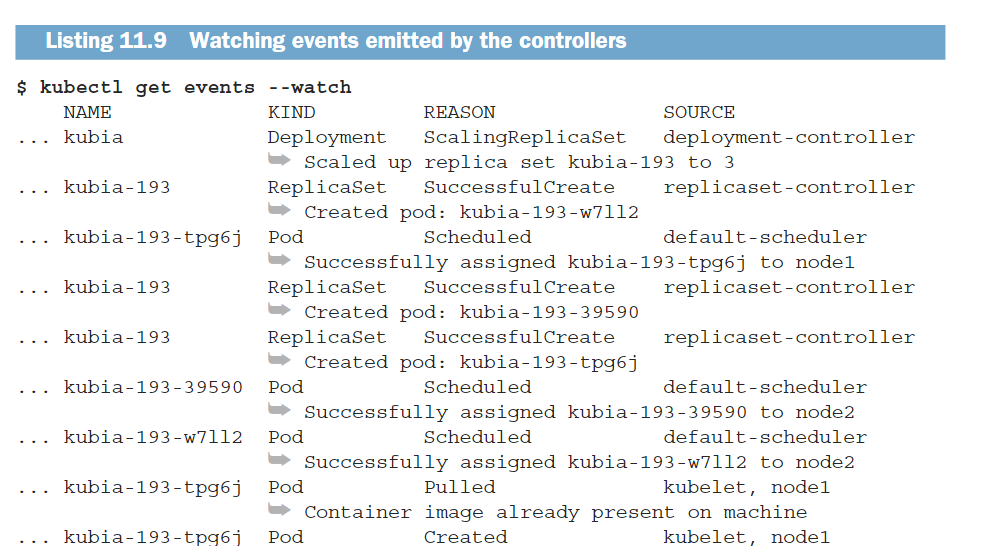
正如你所看到的,SOURCE列显示执行操作的控制器,NAME和KIND列显示控制器正在操作的资源。REASON列和MESSAGE列(显示在每一行的第二行)提供了有关控制器执行的详细信息。
11.3 Understanding what a running pod is
现在让我们更仔细地看一下正在运行的 Pod 是什么。如果一个 Pod 只包含一个容器,你认为 Kubelet 只会运行这个单独的容器吗?还是还有其他的东西?
运行一个只包含一个容器的 Pod,创建一个 Nginx Pod:
$ kubectl run nginx --image=nginx
pod/nginx created
现在你可以 ssh 进入运行该 Pod 的工作节点,并检查正在运行的 Docker 容器列表。:
进入节点后,你可以使用 docker ps 命令列出所有正在运行的容器,如下所示:
$ docker ps
......
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
72eda977c443 nginx ......
96582860de6b registry.aliyuncs.com/google_containers/pause:3.4.1 ......
正如预期的那样,你会看到 Nginx 容器,但还会有一个额外的容器。从 COMMAND 列来看,这个额外的容器没有做任何事情(容器的命令是 “pause”)。如果你仔细观察,你会发现这个容器是在 Nginx 容器之前几秒钟创建的。它的作用是什么呢?
这个 “pause” 容器是将 Pod 中的所有容器放在一起的容器。还记得吗?Pod 中的所有容器共享相同的网络和其他 Linux 命名空间。“pause” 容器是一个基础设施容器,其唯一目的是保存所有这些命名空间。然后,Pod 的所有其他用户定义的容器使用 Pod 基础设施容器的命名空间(参见图 11.13)。
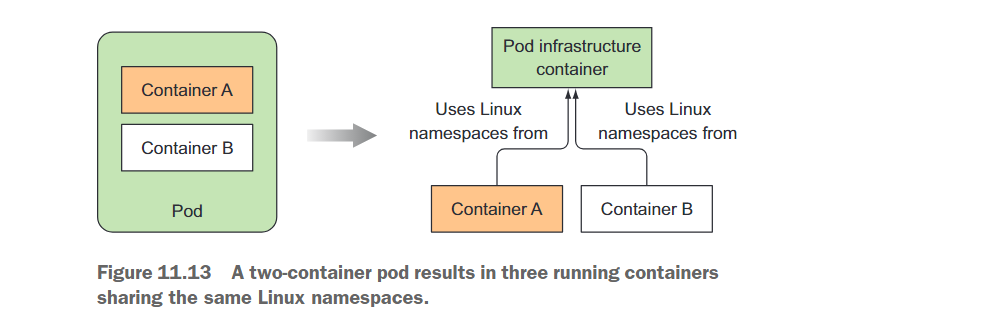
实际的应用容器可能会死亡并重新启动。当这样的容器再次启动时,它需要成为之前相同的 Linux 命名空间的一部分。基础设施容器使这成为可能,因为它的生命周期与 Pod 相关联 ——容器从 Pod 被调度开始运行,直到 Pod 被删除。如果在此期间基础设施容器被终止,Kubelet 会重新创建它以及所有 Pod 中的容器。
11.4 Inter-pod networking
到目前为止,你已经知道每个 Pod 都有自己独特的 IP 地址,并且可以通过一个扁平、无 NAT 的网络与所有其他 Pod 进行通信。Kubernetes 是如何实现这一点的呢?简而言之,它并不直接进行网络设置。网络设置是由系统管理员或者通过容器网络接口(Container Network Interface,CNI)插件进行完成,而不是由 Kubernetes 自身处理。
11.4.1 What the network must be like
看一下图11.14。当Pod A连接到(发送网络数据包给)Pod B时,Pod B所看到的源IP必须与Pod A自己的IP相同。在它们之间不应该执行任何网络地址转换(NAT)——Pod A发送的数据包必须以源地址和目标地址不变的方式到达Pod B。
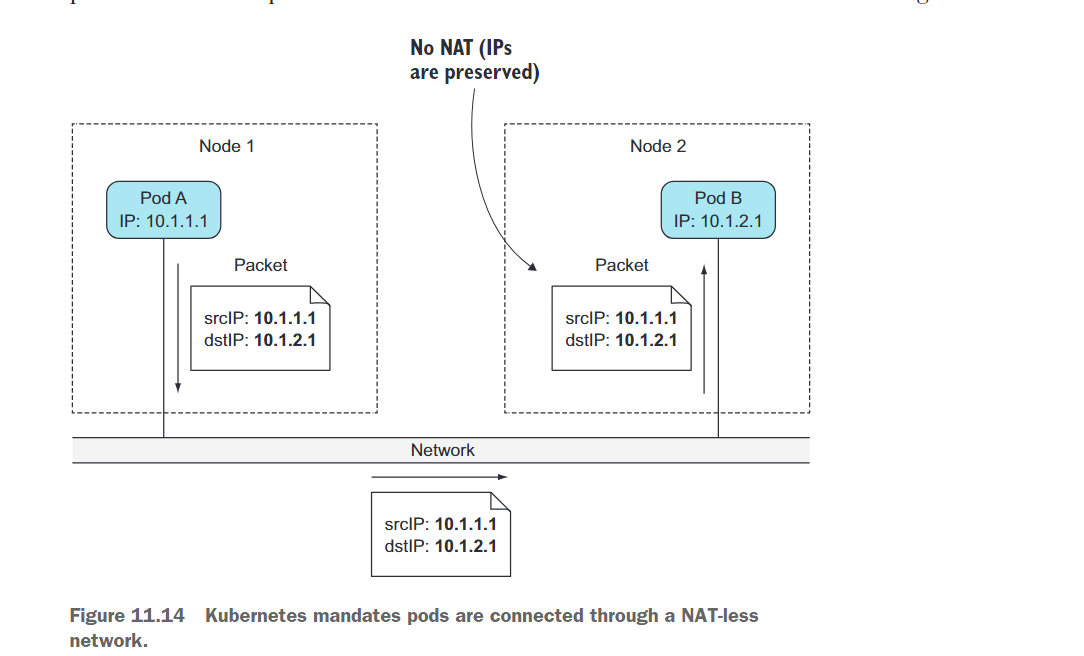
这一点非常重要,因为它使得运行在Pod内部的应用程序的网络通信变得简单,就像它们运行在连接到同一个网络交换机的机器上一样。Pod之间的无NAT使得在Pod内部运行的应用程序能够自动在其他Pod中进行注册。
例如,假设你有一个客户端Pod X和一个提供某种通知服务的Pod Y,所有注册到该服务的Pod都可以收到更新通知。Pod X连接到Pod Y并告诉它:“嘿,我是Pod X,我的IP地址是1.2.3.4;请发送更新到这个IP地址。”提供服务的Pod可以使用收到的IP地址连接到第一个Pod。
对于Pod到节点和节点到Pod的通信,无NAT通信的要求也同样适用。但是,当Pod与互联网上的服务进行通信时,Pod发送的数据包的源IP需要被更改,因为Pod的IP是私有的。出站数据包的源IP会被更改为主机工作节点的IP地址。
11.4.2 Diving deeper into how networking works
在第11.3节中,我们看到一个Pod的IP地址和网络命名空间是由基础设施容器(即暂停容器)设置和持有的。然后,Pod的容器使用该网络命名空间。因此,一个Pod的网络接口就是在基础设施容器中设置的内容。让我们看看接口是如何创建以及如何连接到所有其他Pod中的接口。请参考图11.15。我们将在接下来进行讨论。
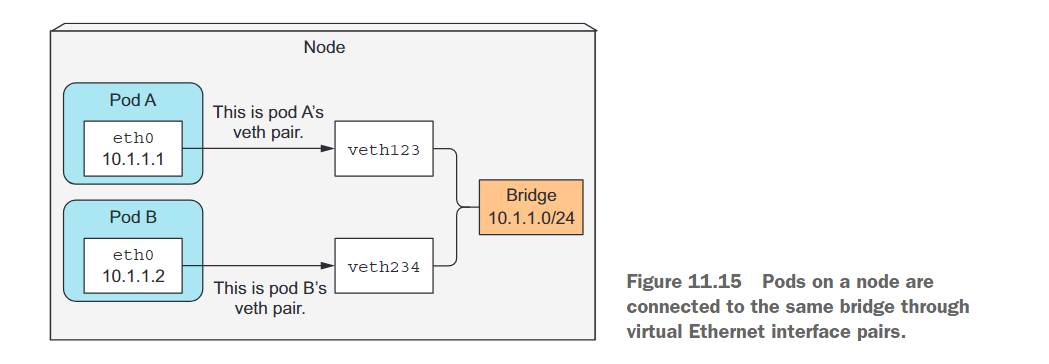
支持同一节点上的Pod之间的通信
在启动基础设施容器之前,为该容器创建一个虚拟以太网接口对(veth对)。其中一端接口保留在主机的命名空间中(当你在节点上运行ifconfig时,你将在列表中看到它的名称为vethXXX),而另一端被移动到容器的网络命名空间中,并被重命名为eth0。这两个虚拟接口就像是一根管道的两端(或者像两个通过以太网电缆连接的网络设备)——从一端进去的东西从另一端出来,反之亦然。
主机的网络命名空间中的接口连接到容器运行时配置的网络桥接。容器中的eth0接口被分配来自桥接地址范围的IP地址。容器内部运行的应用程序发送到eth0网络接口(即容器命名空间中的接口)的任何数据都会通过主机命名空间中的另一个veth接口传出,并发送到桥接设备。这意味着可以被连接到桥接设备的任何网络接口接收到该数据。
如果Pod A向Pod B发送网络数据包,数据包首先通过Pod A的veth对和桥接设备,然后通过Pod B的veth对。节点上的所有容器都连接到同一个桥接设备,这意味着它们可以彼此通信。但是,为了实现在不同节点上运行的容器之间的通信,这些节点上的桥接设备需要以某种方式连接起来。
在计算机网络中,桥接是一种网络设备或软件功能,用于连接两个或多个网络段,使它们可以透明地通信。桥接工作在OSI模型的数据链路层(第二层),根据目标MAC地址将数据帧从一个网络段转发到另一个网络段。
桥接设备(物理桥接器)是一种硬件设备,通常是一个网络交换机,它具有多个端口用于连接不同的网络段。它可以将数据帧从一个端口复制到其他端口,使得连接到不同端口的设备可以直接通信,就像它们直接连接在同一个网络上一样。
软件桥接(虚拟桥接器)是一种在操作系统内部实现的桥接功能。它可以创建虚拟的网络接口,将不同的网络接口连接起来,并通过转发数据帧来实现不同网络段之间的通信。软件桥接常用于虚拟化环境中,例如在虚拟机之间或容器之间创建一个共享的网络。
无论是物理桥接还是软件桥接,它们的目标都是实现不同网络段之间的透明通信,使得网络中的设备可以像连接在同一个网络上一样进行通信。
支持不同节点上的Pod之间的通信
在连接不同节点的桥接之间,你有许多方法可以选择。这可以通过覆盖网络(overlay)或底层网络(underlay),或者通过常规的第3层路由(layer 3 routing)来实现,接下来我们将详细讨论。
Pod的IP地址必须在整个集群中是唯一的,因此节点之间的桥接必须使用不重叠的地址范围,以防止不同节点上的Pod获得相同的IP地址。在图11.16中所示的示例中,节点A上的桥接使用10.1.1.0/24 IP范围,节点B上的桥接使用10.1.2.0/24,这确保了不存在IP地址冲突。
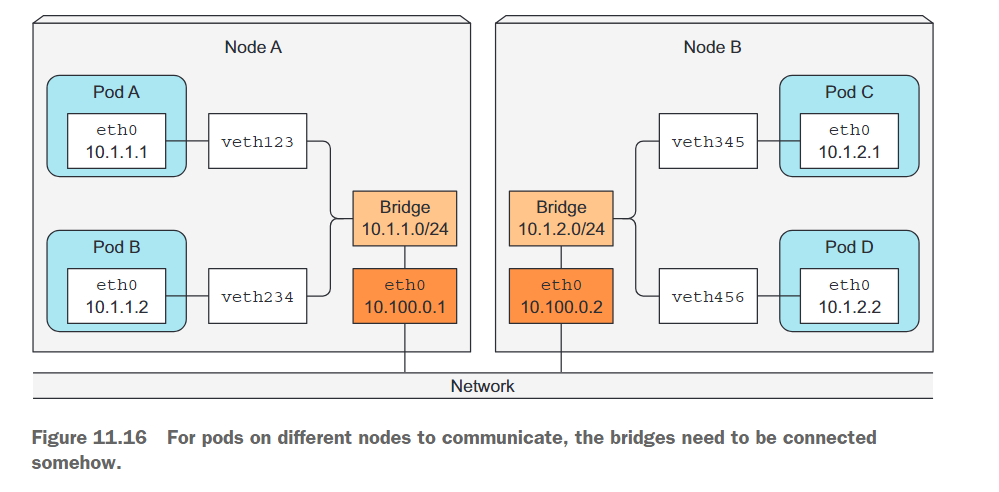
图11.16显示,为了在使用普通的第3层网络连接时实现节点间的Pod通信,节点的物理网络接口也需要连接到桥接上。节点A的路由表需要配置,以便将所有发送到10.1.2.0/24的数据包路由到节点B,而节点B的路由表需要配置,以便将发送到10.1.1.0/24的数据包路由到节点A。
通过这种设置,当一个节点上的容器向另一个节点上的容器发送数据包时,数据包首先通过veth对,然后通过桥接到达节点的物理适配器,然后通过电缆传输到另一个节点的物理适配器,通过另一个节点的桥接,并最终通过目标容器的veth对。
这种设置仅适用于节点直接连接到相同的网络交换机,并且之间没有任何路由器;否则,那些路由器会丢弃与Pod的私有IP相关的数据包。当然,可以配置中间的路由器以在节点之间路由数据包,但随着路由器数量的增加,这变得越来越困难和容易出错。因此,**使用软件定义网络(Software Defined Network,SDN)**更加简单。SDN使得节点看起来好像它们连接到同一个网络交换机上,而不管实际的底层网络拓扑结构是什么样的,无论其复杂程度如何。从Pod发送的数据包会被封装并通过网络发送到运行另一个Pod的节点,然后在目标节点上解封装并以原始形式传递给目标Pod。
11.4.3 Introducing the Container Network Interface
为了更容易将容器连接到网络中,启动了一个名为容器网络接口(Container Network Interface,CNI)的项目。CNI允许配置Kubernetes以使用任何现有的CNI插件。这些插件包括:Calico、Flannel、Romana、Weave Net等等。
安装网络插件并不困难。只需要部署一个包含DaemonSet和其他一些支持资源的YAML文件。每个插件的项目页面都提供了这个YAML文件。
11.5 How services are implemented
11.5.1 Introducing the kube-proxy
所有与服务(Services)相关的内容都由运行在每个节点上的kube-proxy进程处理。最初,kube-proxy是一个真正的代理程序,等待连接,并对每个传入连接,打开一个到其中一个Pod的新连接。这被称为用户空间代理模式(userspace proxy mode)。后来,一个性能更好的iptables代理模式取代了它,现在是默认设置,但如果需要的话,你仍然可以配置Kubernetes使用旧的模式。
我们已经了解到,每个服务都有自己稳定的IP地址和端口。客户端(通常是Pod)通过连接到这个IP地址和端口来使用服务。这个IP地址是虚拟的,它不会分配给任何网络接口,并且在网络数据包离开节点时,它永远不会被列为源IP地址或目标IP地址。服务的一个关键细节是它由一个IP和端口对组成(在多端口服务的情况下是多个IP和端口对),因此单独的服务IP并不代表任何东西。这就是为什么你不能对它们进行ping操作。
11.5.2 How kube-proxy uses iptables
当在API服务器中创建服务时,虚拟IP地址会立即分配给它。随后,API服务器通知所有运行在工作节点上的kube-proxy代理,一个新的服务已经被创建。然后,每个kube-proxy在其所在的节点上使该服务可寻址。它通过设置一些iptables规则来实现,这些规则确保每个发往服务IP/端口对的数据包都被拦截,并修改其目标地址,以便将数据包重定向到支持服务的其中一个Pod。
除了监视API服务器中服务的更改,kube-proxy还监视Endpoints对象的更改。一个Endpoints对象保存了支持服务的所有Pod的IP/端口对。这就是为什么kube-proxy必须监视所有的Endpoints对象。毕竟,每当创建或删除一个新的支持Pod,或者当Pod的就绪状态发生变化,或者当Pod的标签发生变化并且进入或离开服务范围时,Endpoints对象都会发生变化。
现在让我们看看kube-proxy如何使客户端通过服务连接到这些Pod。这在图11.17中显示出来。
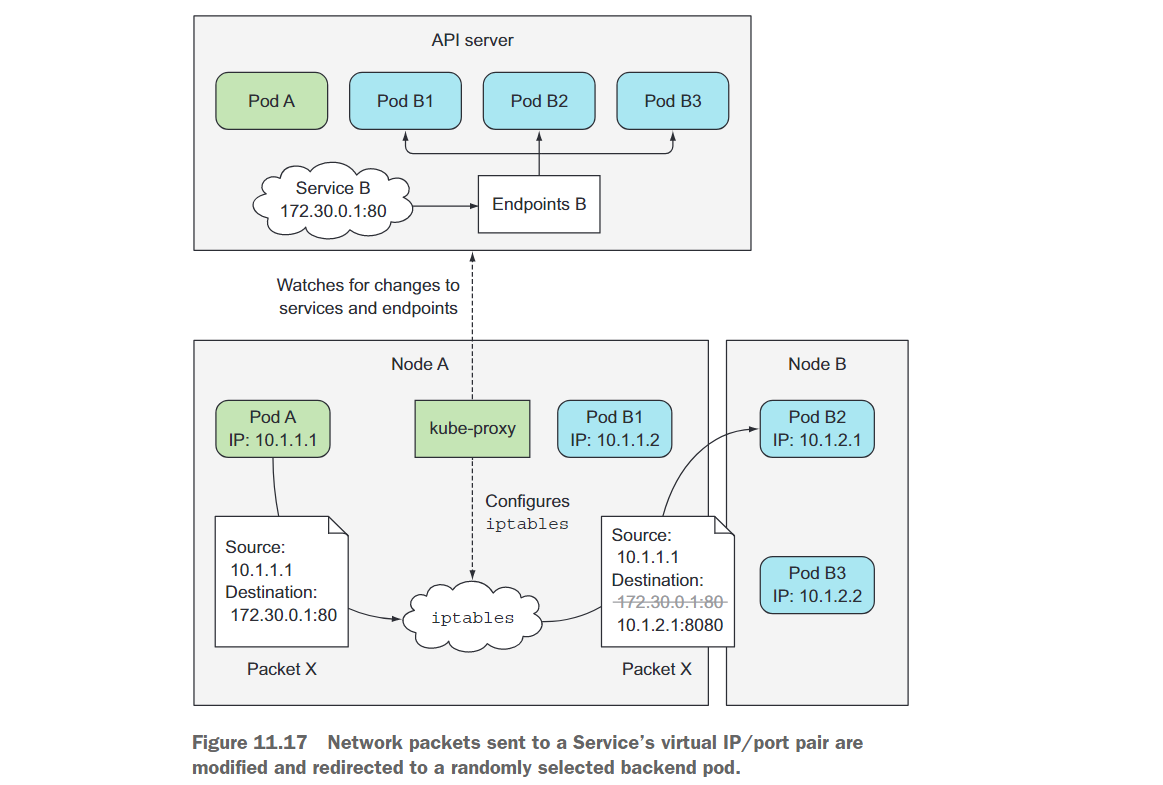
该图显示了kube-proxy的操作以及客户端Pod发送的数据包如何到达支持服务的其中一个Pod。让我们来看看当客户端Pod(图中的Pod A)发送数据包时,数据包经历了哪些处理过程。
数据包的目的地最初设置为服务的IP和端口(在示例中,服务的地址是172.30.0.1:80)。在发送到网络之前,数据包首先由节点A的内核处理,根据节点上设置的iptables规则进行处理。
内核会检查数据包是否匹配任何iptables规则。其中一个规则指定,如果任何数据包的目标IP等于172.30.0.1且目标端口等于80,则该数据包的目标IP和端口应被替换为随机选择的一个Pod的IP和端口。
在示例中,数据包匹配了该规则,因此它的目标IP/端口被修改。在示例中,随机选择了Pod B2,因此数据包的目标IP被修改为10.1.2.1(Pod B2的IP),端口被修改为8080(Service规范中指定的目标端口)。从这一点开始,就好像客户端Pod直接将数据包发送给Pod B,而不是通过Service路由。
11.6 Running highly available clusters
在Kubernetes中运行应用程序的原因之一是在基础设施发生故障时保持应用程序的连续运行,尽量减少或避免手动干预。为了实现服务的不间断运行,不仅应用程序需要始终处于运行状态,而且Kubernetes的控制平面组件也需要保持可用性。接下来,我们将了解实现高可用性所涉及的内容。
11.6.1 Making your apps highly available
当在Kubernetes中运行应用程序时,各种控制器确保你的应用程序即使在节点故障时也能平稳运行,并保持指定的规模。为了确保应用程序具有高可用性,你只需要通过Deployment资源运行它们,并配置适当数量的副本;其余的工作将由Kubernetes来处理。
运行多个实例以降低停机时间的可能性
这需要你的应用程序具有水平扩展性,但即使在应用程序不具备水平扩展性的情况下,你仍应使用具有副本数为1的Deployment。如果副本不可用,它将迅速被替换为新的副本,尽管这并不会立即发生。各个控制器需要时间来察觉到节点故障,创建新的Pod副本,并启动Pod的容器。这之间不可避免地会有一段短暂的停机时间。
对于不具备水平扩展性的应用程序,使用领导选举来避免停机时间
为了避免停机时间,你需要同时运行额外的非活动副本和活动副本,并使用快速生效的租约或领导选举机制,确保只有一个副本处于活动状态。如果你对领导选举不熟悉,它是在分布式环境中运行的多个应用程序实例达成一致的一种方式,确定哪个实例是领导者。该领导者可以是唯一执行任务的实例,而其他所有实例则等待领导者失败后成为领导者,或者它们都可以处于活动状态,其中领导者是唯一执行写操作的实例,而其他实例提供只读访问其数据的功能,例如。这确保了不会有两个实例执行相同的工作,如果这样做会因竞争条件导致不可预测的系统行为。
该机制不需要集成到应用程序本身中。你可以使用一个旁路容器来执行所有领导选举操作,并在应该激活主容器时通知主容器。
11.6.2 Making Kubernetes Control Plane components highly available
在本章的开头,你了解了构成Kubernetes控制平面的几个组件。为了使Kubernetes具备高可用性,你需要运行多个主节点,并在每个主节点上运行以下组件的多个实例:
- API server
- Controller Manager
- etcd
- Scheduler
在不详细介绍如何安装和运行这些组件的情况下,让我们看看如何实现每个组件的高可用性。图11.18展示了高可用性集群的概览。
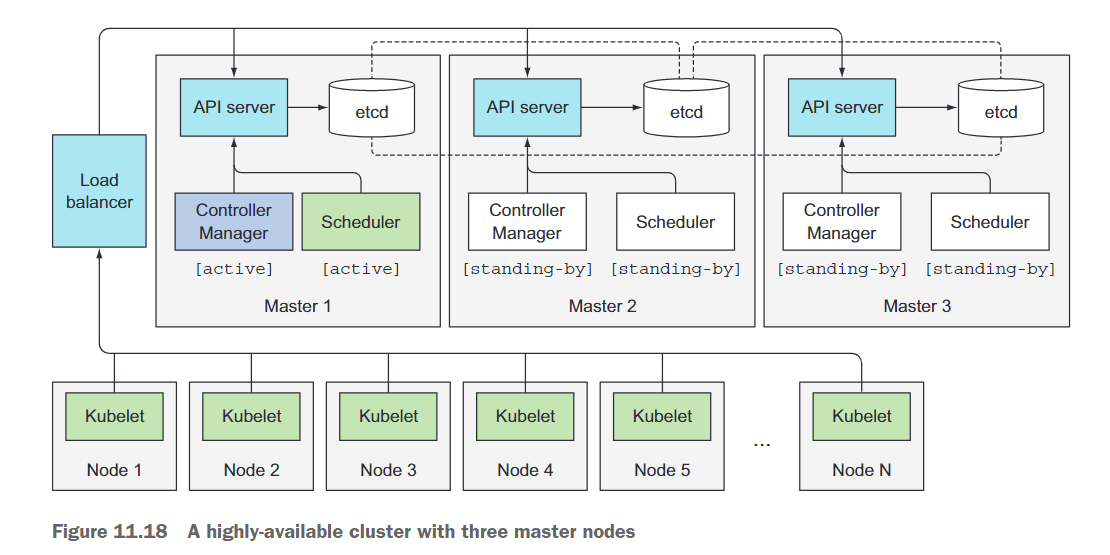
运行etcd集群
由于etcd被设计为分布式系统,其关键特性之一是能够运行多个etcd实例,因此实现高可用性并不困难。你只需要在适当数量的机器上运行etcd(如本章前面解释的三个、五个或七个节点),并让它们相互感知。你可以通过在每个实例的配置中包含所有其他实例的列表来实现这一点。例如,当启动一个实例时,你会指定其他etcd实例的IP和端口。
etcd将在所有实例之间复制数据,因此在运行三个节点集群时,如果一个节点发生故障,集群仍然可以接受读写操作。要增加故障容忍度,超过一个节点的故障,你需要运行五个或七个etcd节点,分别允许集群处理两个或三个节点的故障。超过七个etcd实例几乎从不是必要的,而且会影响性能。
运行多个API Server实例
使API服务器具备高可用性甚至更简单。因为API服务器几乎是无状态的(所有数据存储在etcd中,但API服务器会进行缓存),所以你可以根据需要运行任意数量的API服务器,它们不需要相互感知。通常,每个etcd实例旁边都有一个API服务器。通过这样做,etcd实例不需要任何类型的负载均衡器,因为每个API服务器实例只与本地的etcd实例通信。
另一方面,API服务器确实需要由负载均衡器进行前置,以便客户端(例如kubectl,以及Controller Manager、Scheduler和所有的Kubelet)始终只连接到可用的API服务器实例。
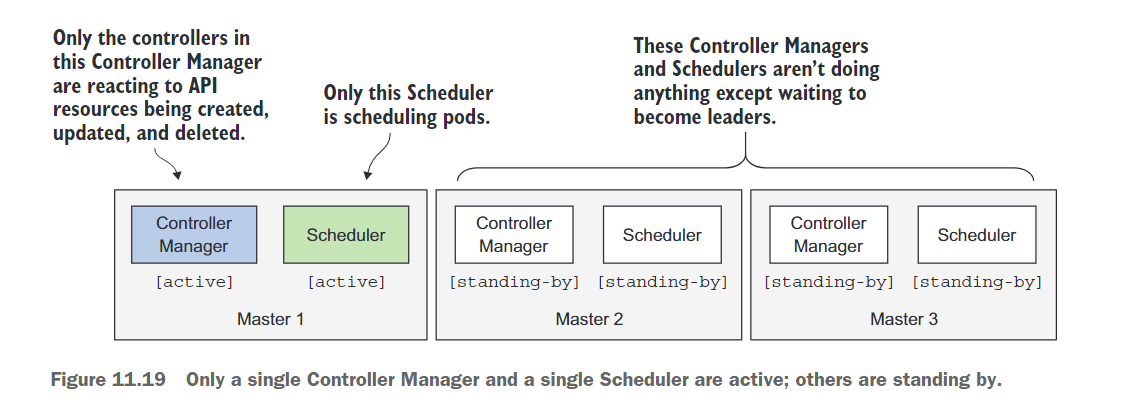
确保控制器和调度器的高可用性
与API服务器可以同时运行多个副本相比,同时运行多个Controller Manager或Scheduler实例并不那么简单。因为控制器和调度器都会主动监视集群状态,并在状态发生变化时采取行动,可能会进一步修改集群状态(例如,当ReplicaSet上的期望副本数增加一个时,ReplicaSet控制器会创建一个额外的Pod),同时运行多个每个组件的实例将导致所有实例执行相同的操作。它们将彼此竞争,这可能会产生不希望的效果(如前面的例子中创建两个新的Pod而不是一个)。
因此,当运行这些组件的多个实例时,任何给定时间只能有一个实例处于活动状态。幸运的是,组件本身已经处理了所有这些(这通过–leader-elect选项进行控制,默认为true)。每个单独的组件只在被选举为领导者时才处于活动状态。只有领导者执行实际工作,而所有其他实例都处于待命状态,等待当前领导者失败。一旦失败,剩余的实例将选举出新的领导者,然后接管工作。这种机制确保两个组件永远不会同时运行并执行相同的工作(参见图11.19)。
Controller Manager和Scheduler可以与API服务器和etcd共同运行,也可以在单独的机器上运行。当与API服务器和etcd共同运行时,它们可以直接与本地的API服务器进行通信;否则,它们通过负载均衡器连接到API服务器。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结