您现在的位置是:首页 >技术交流 >【Linux编译器gcc/g++】带你了解代码是如何变成可执行程序的!网站首页技术交流
【Linux编译器gcc/g++】带你了解代码是如何变成可执行程序的!
Linux编辑器gcc/g++的使用
?博客主页:小智_x0___0x_
?欢迎关注:?点赞?收藏✍️留言
?系列专栏:Linux入门到精通
?代码仓库:小智的代码仓库
背景知识
我们要知道一个写一段代码到可执行程序是需要经过下面四个过程。
- 预处理(宏定义替换)
- 编译(生成汇编)
- 汇编(生成机器可识别代码)
- 链接(生成可执行文件或者库文件)
本篇将带大家深度探索以上的四个过程。因为gcc和g++的功能选项是一样的,本篇主要详解gcc的过程。
gcc的使用
我们使用vim编写一个.c文件>
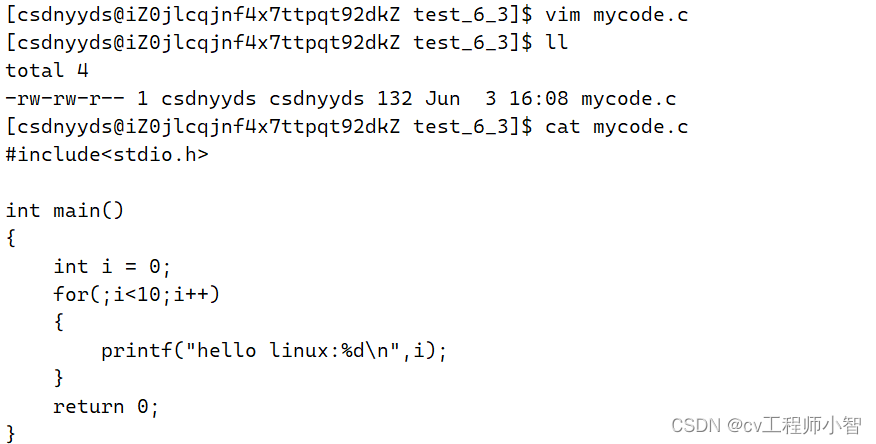
gcc的使用方法:gcc + .c文件

编译完成后会生成一个a.out文件,可以看到他的文件权限中是有x(可执行权限)权限的。
我们可以输入这行指令来执行:./a.out
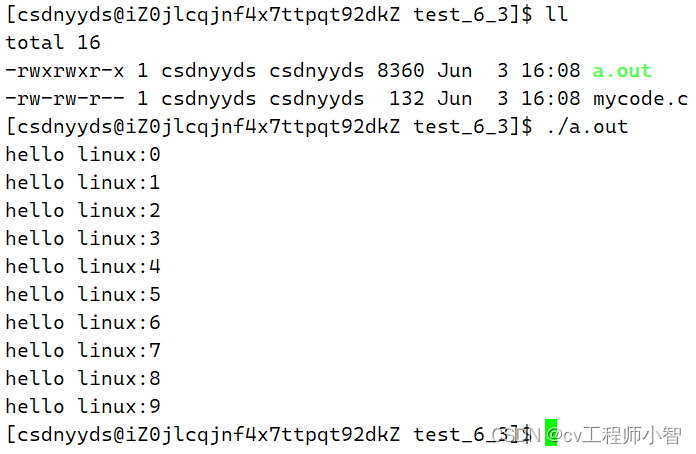
这样就可以执行我们的C语言程序了。
也可以使用gcc -o 可执行程序 .c文件或者gcc .c文件 -o 可执行程序这两个可以指定生成可执行程序的名称。
当然gcc也是可以帮我们检查语法错误的>
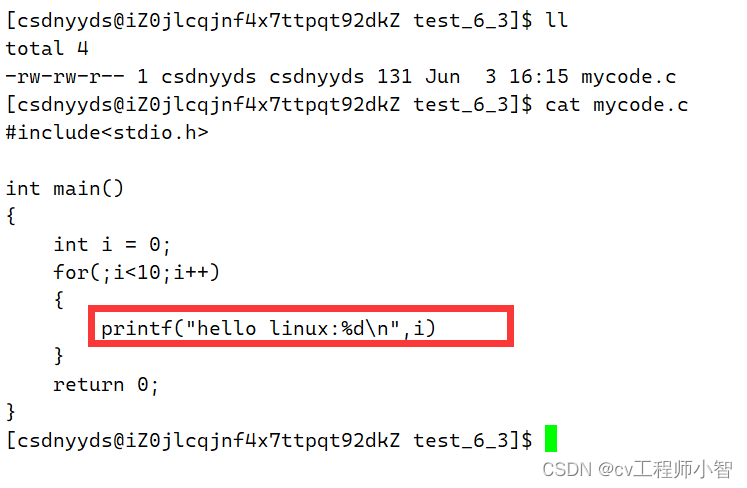
这里我我们故意不在后面不加;来使用gcc编译。
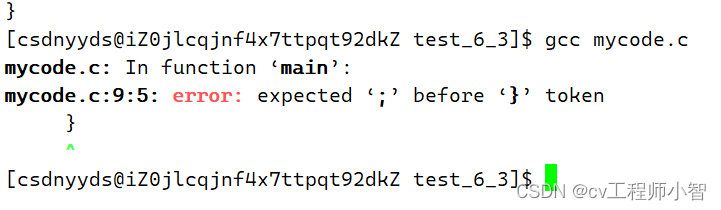
可以看到下面给我们报错显示}后面没有';'.
预处理(进行宏替换)
- 去注释
- 头文件展开
- 条件编译
- 宏替换
我们继续使用mycode.c文件>
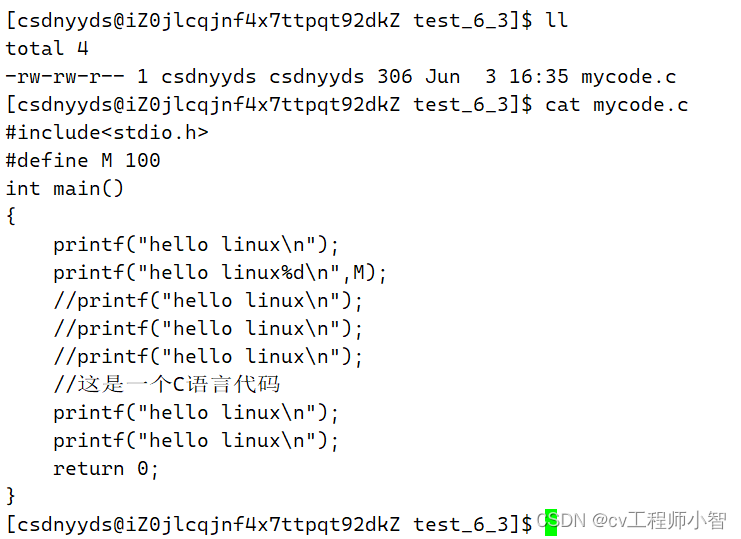
可以看到我们的代码中有注释也有#define M 100定义的宏
为了让程序执行到预处理阶段我们可以使用以下指令:
gcc -E mytest.c -o mytest.i
选项"-E",该选项的作用是让 gcc 在预处理结束后停止编译过程。
选项"-o"是指目标文件,".i"文件为已经过预处理的C原始程序。

可以看到我们生成了一个mytest.i文件:
我们来打开mytest.i文件>
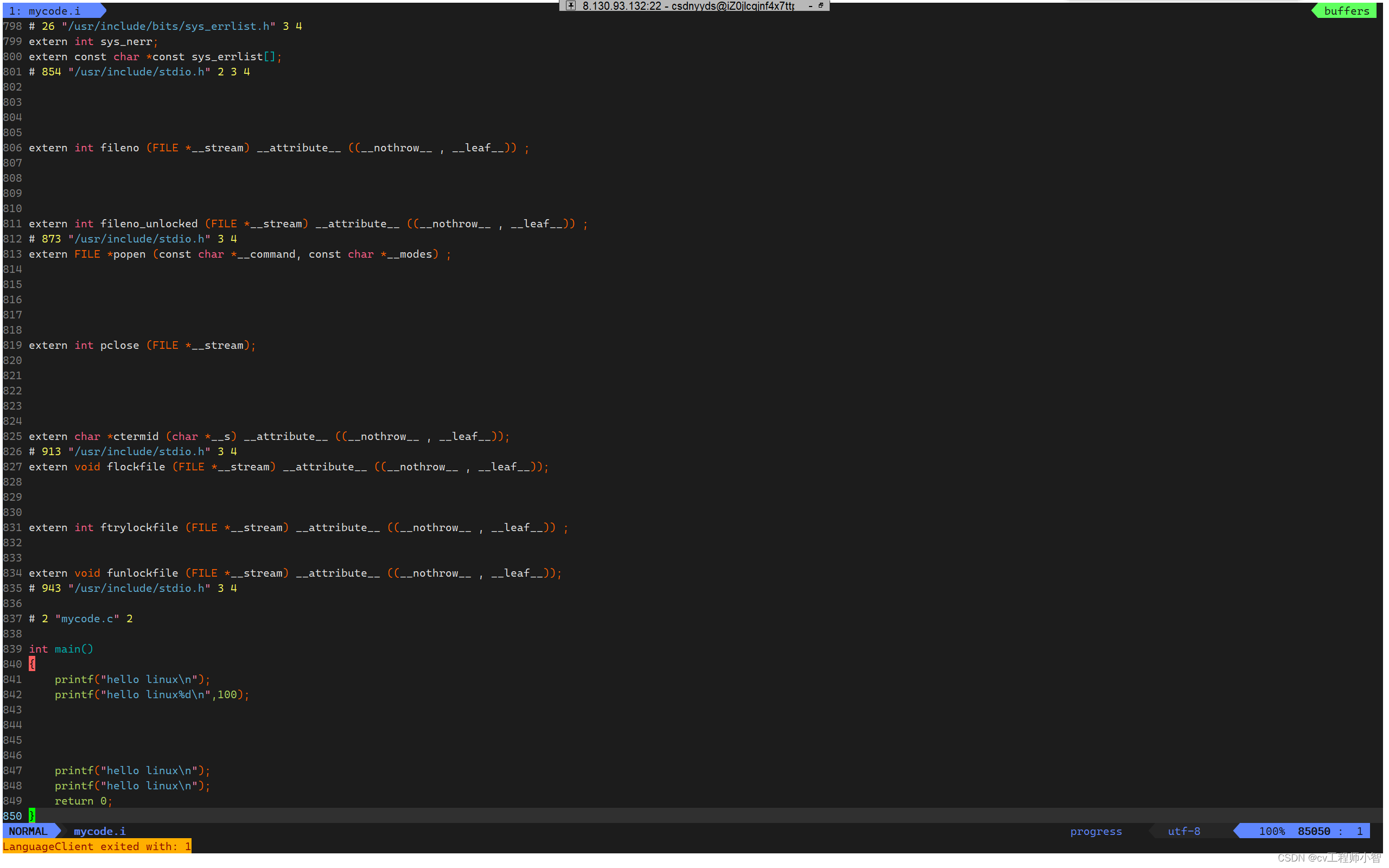
使用shift+g跳到末尾行。
我们可以看到文件变成了850行,这是因为头文件的展开预处理阶段自动把我们所包含的头文件添加进去。mytest.i文件上面的内容都是stdio.h中的内容。
我们来对比以下两个文件其他的变化。
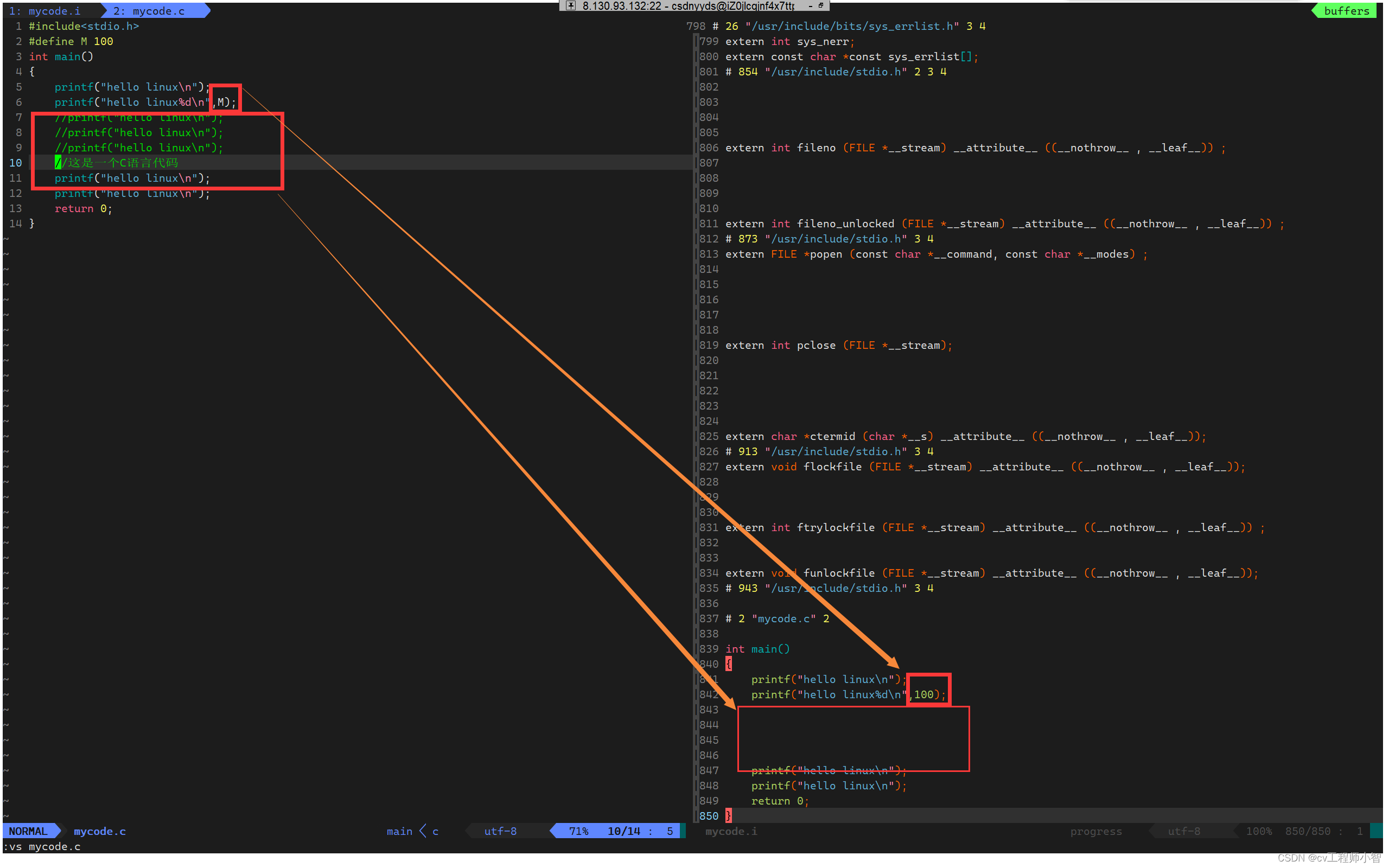
可以看到mytest.i文件中注释被去掉了,宏定义的M被直接替换为了100。
这里就可以理解为什么宏定义不能进行调试。因为宏定义在预处理阶段就被直接替换掉了。
我们再来添加一段条件编译>
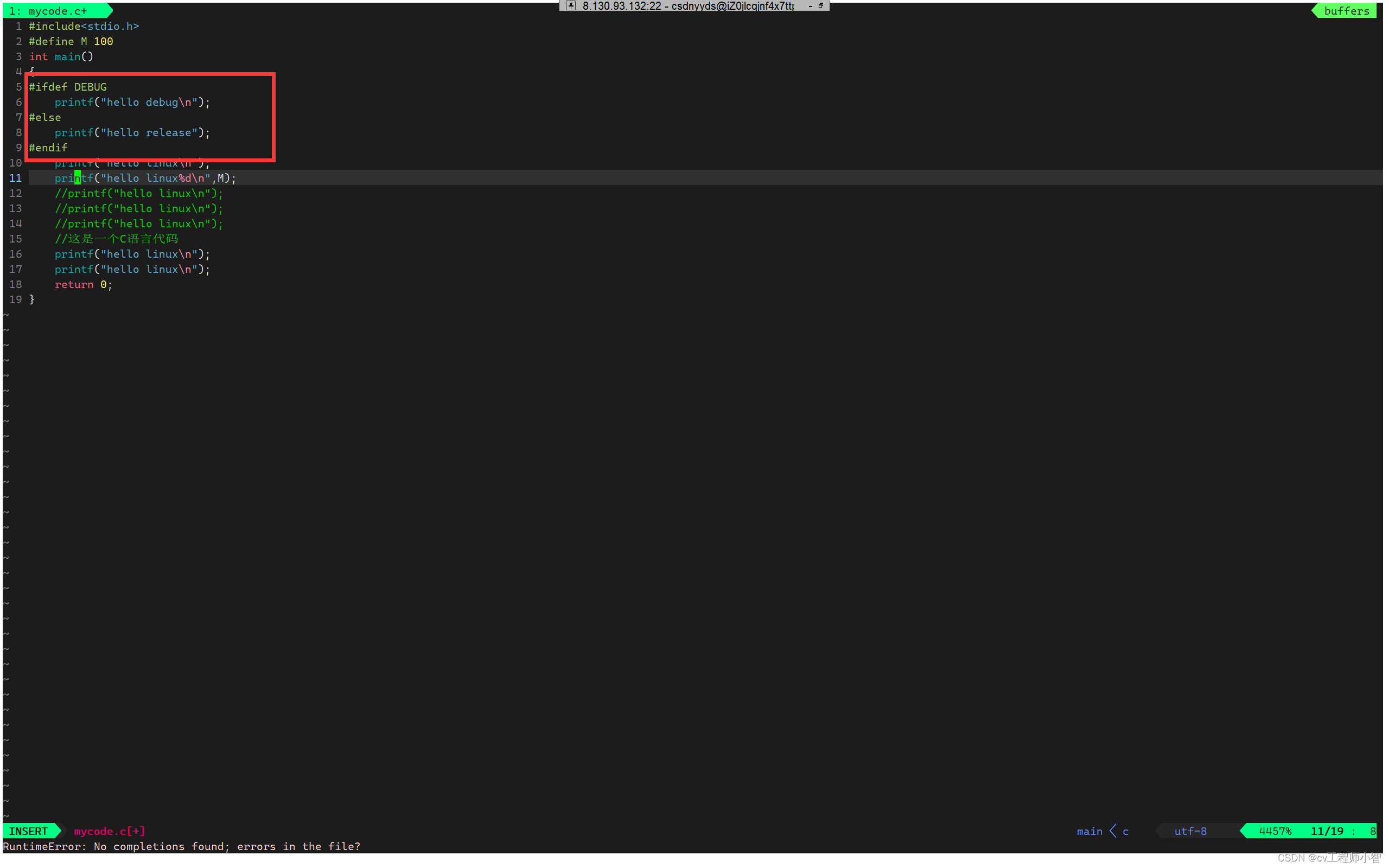
我们再次对这个文件进行预处理:

再来对比两个文件的区别>
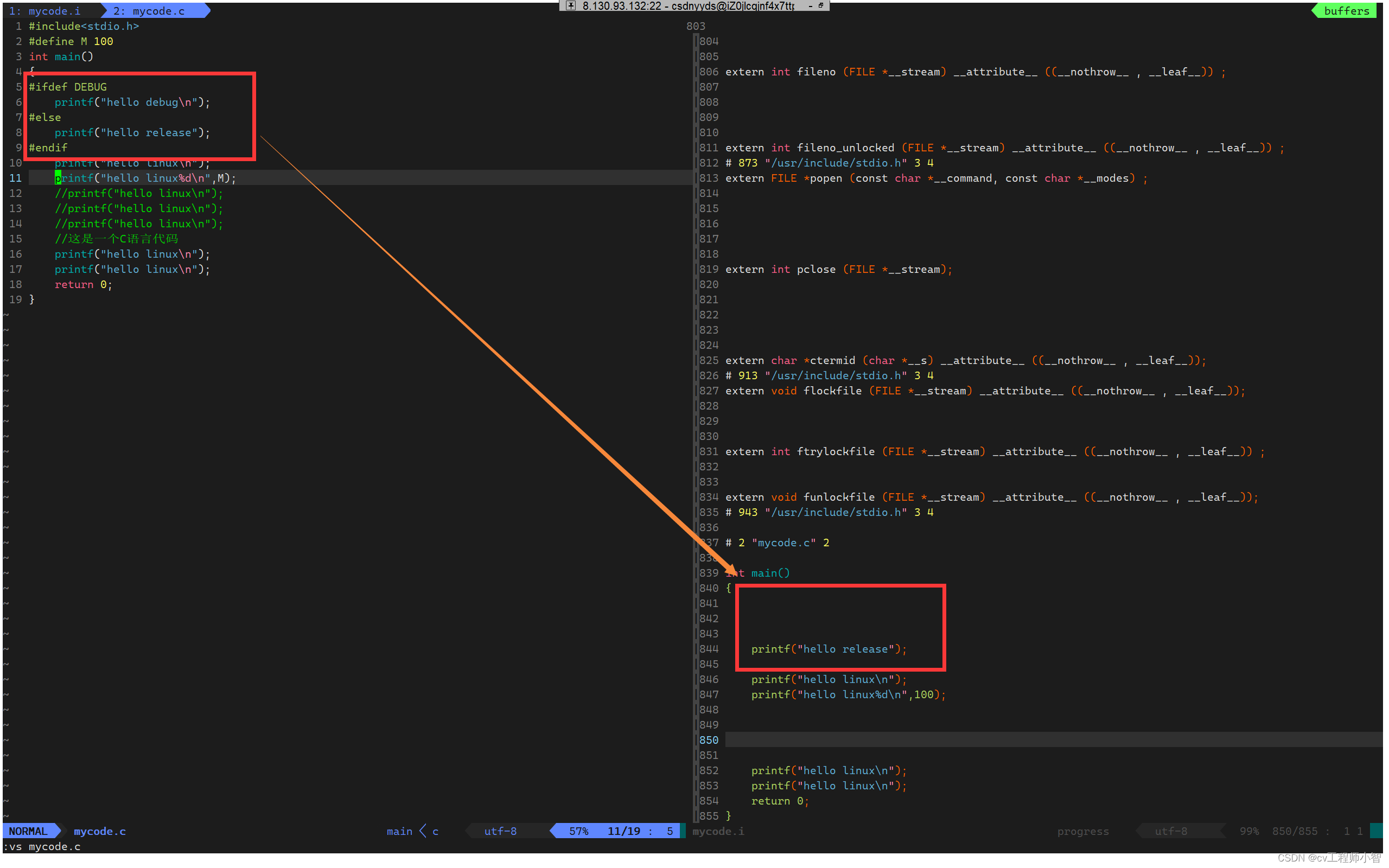
此时可以看到预处理之后是只有else中的语句。
我们可以通过文件内添加,也可以通过gcc命令行来添加使用这行指令:
gcc -E mycode.c -o mycode.i -DDEBUG

再来打开两个文件进行对比>
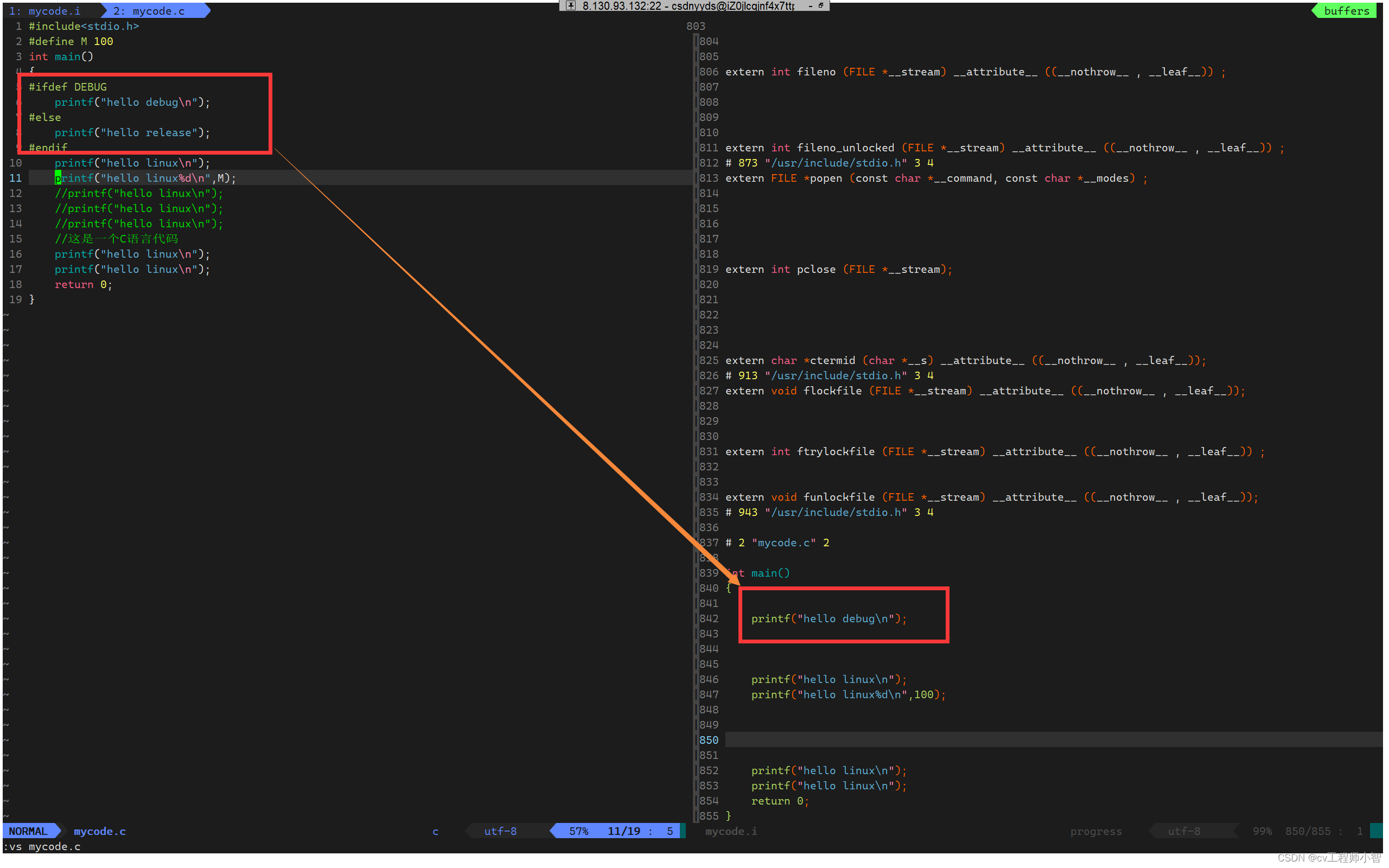
这里就可以发现预处理保留了我们if条件下的语句。
编译(生成汇编)
- 在这个阶段中,gcc 首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,gcc 把代码翻译成汇编语言。
我们可以通过这个指令对mycode.i文件进行编译:gcc -S mycode.i -o mycode.s
-S的功能是从现在进行程序的翻译,将编译工作做完就停下来。

这里就生成了mycode.s文件。我们再来打开这个文件>
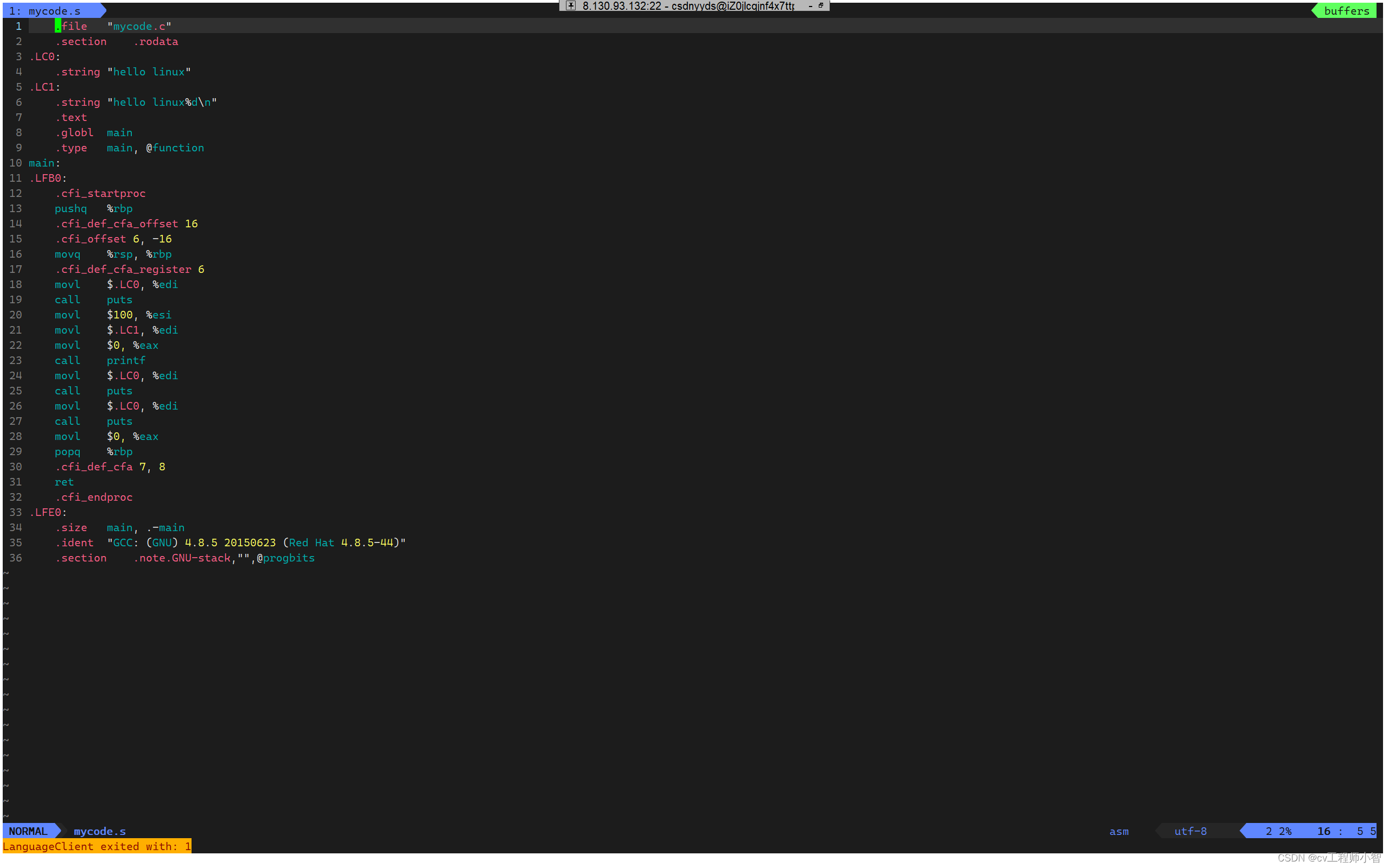
汇编(生成及其可识别代码)
- 汇编阶段是把编译阶段生成的
".s"文件转成目标文件。 - 读者在此可使用选项
"-c"就可看到汇编代码已转化为".o"的二进制目标代码了。
我们可以使用这行指令进行汇编处理:gcc -c mycode.s -o mycode.o
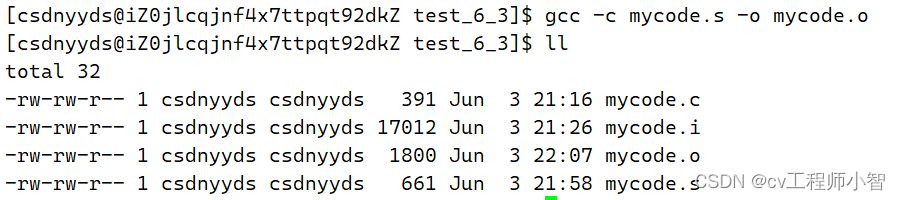
再来打开mycode.o文件(注意这里需要用od来查看文件中的内容,因为".o"文件中都是二进制机器可识别的)直接输入指令:od mycode.o

打开之后我们可以发现这里面都是二进制数,因为机器只认识二进制数(0和1)。
mycode.o可重定位目标二进制文件,简称目标文件,(vs环境下是.obj)
不可以独立执行,虽然已经是二进制了需要经过 链接(库) 才能执行。
链接(生成可执行文件或者库文件)
- 在成功编译之后,就进入了链接阶段。
这里我们在使用 :gcc -o mytest mycode.o
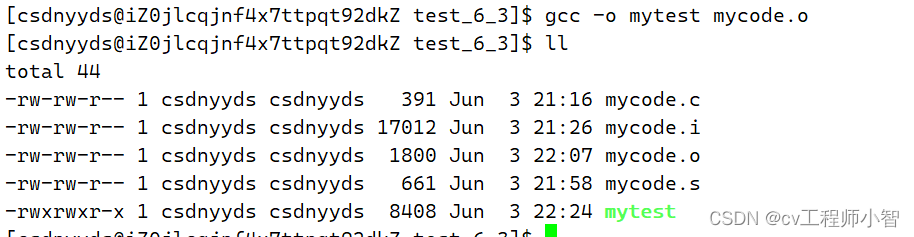
这里就生成了我们自定义的名称的可执行程序mytest。
再来执行这个可执行程序:./mytest
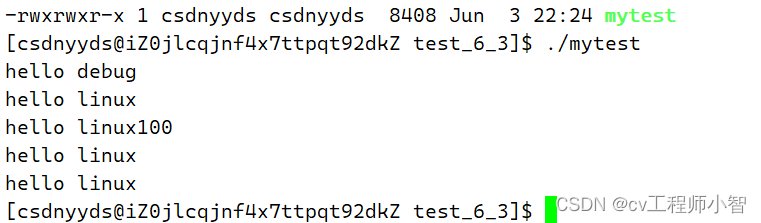
gcc -o mytest mycode.o是将可重定位目标二进制文件,和库进行链接形成可执行程序
库
在 Linux 中,库(Library)是一组可重用的代码和数据,它们提供了一些常用的函数和方法,可以被其他程序调用。库通常被编写成共享对象文件(Shared Object File),也称为动态链接库(Dynamic Linking Library),这种文件可以在运行时被加载到内存中,并被多个程序共享。
Linux 中的库可以分为两类:
-
静态库(Static Library):静态库是一组预编译的对象代码,它们被链接到目标程序中,使得目标程序包含了所有所需的代码和数据。静态库的文件扩展名通常是
.a或.lib。静态库的优点是使用简单,因为它们被编译到目标程序中,所以不需要在运行时加载库文件。但缺点是占用更多的磁盘空间。 -
动态库(Shared Library):动态库是一种动态链接库,它们被多个程序共享。共享库的文件扩展名通常是
.so或.dll。共享库的优点是占用更少的磁盘空间,并且可以在多个程序之间共享代码和数据。但缺点是需要在运行时加载库文件,因此会稍微降低程序的执行速度。
Linux 中有许多常用的库,例如 C 语言标准库 libc、数学库 libm、图形库 libX11 等等。这些库通常都已经安装在系统中,可以直接使用。同时,开发者也可以编写自己的库,并将其发布供其他程序使用。

我们可以使用:ldd+可执行程序来查看可执行程序所依赖的库:
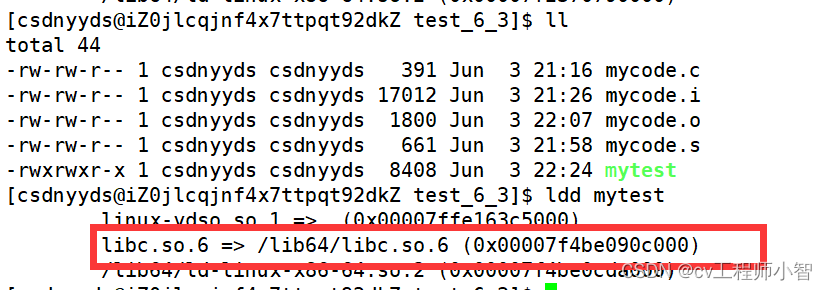
libc.so.6 => /lib64/libc.so.6是C语言的动态库。
我们也可以使用ldd来查询Linux中的指令。
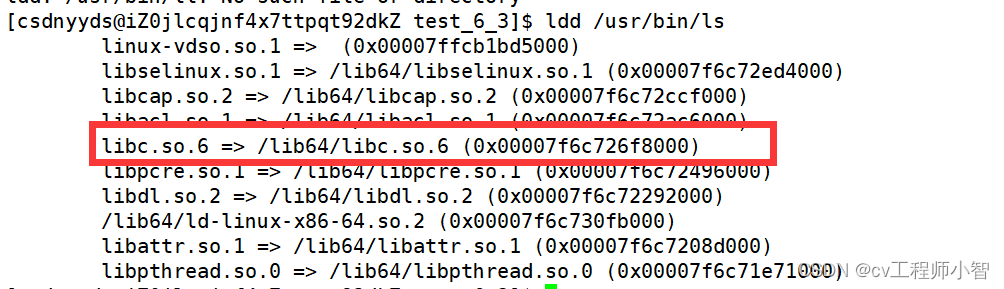
可以看到ls指令也是依赖C语言动态库的,这是因为Linux中大部分指令都是使用C语言编写的。
我们再来使用静态库来链接一下:gcc -o mytet_static mycode.s

可以看到动态库和静态库链接形成的两个可执行程序的大小差距还是很大的,因为静态库是将其所有内容全部拷贝过去,所以所占的字节数要大一点。(平时我们很少会使用静态库链接。)
Linux操作系统中默认是没有静态库的,我们可以使用这行指令进行安装:
sudo yum -y install glibc-static C语言静态库安装
sudo yum install -y libstdc++-static c++静态库安装
【注意】:
- 在编译器使用 静态库进行静态链接的时候,会将自己的方法拷贝到目标程序中,该程序以后不用再依赖静态库!
- 动态库不能缺失,一旦对应的动态库缺失,影响的不止一个程序可能导致很多程序都无法进行正常运行!
- 在Linux中,编译形成可执行程序,默认采用的就是动态链接–提供动态库
- 在Linux中,如果要按照静态链接的方式,进行形成可执行程序,需要添加-static选项–提供静态库
如果我们没有静态库,但是我们就要-static,行不行呢? 答案是肯定不行
如果我们没有动态库,只有静态库,而且gcc能找到 - 能的,gcc默认优先动态链接-static的本质: 改变优先级
不一定是纯的全部动态链接或者静态链接,混合的!
加了-static所有的连接要求全部变成静态链接(只适配一次)
我们也可以通过file指令来查询可执行程序到底依赖的是哪一个库:

动态库vs静态库
动态库和静态库都有各自的优缺点,下面是它们的主要特点:
动态库的优点:
- 节省内存:多个程序可以共享同一个动态库,避免了重复加载代码和数据的浪费。
- 灵活性:动态库可以在运行时动态加载和卸载,使得程序更加灵活,可以根据需要加载不同的库版本。
- 兼容性:动态库可以在不同的平台上运行,因为库文件和程序是分离的,不需要重新编译程序。
动态库的缺点:
- 性能:由于需要在运行时加载库文件,所以动态库会稍微降低程序的执行速度。
- 稳定性:如果动态库的版本不兼容,或者动态库本身存在漏洞,可能会导致程序崩溃或者安全问题。
静态库的优点:
- 稳定性:静态库可以使得程序更加独立和稳定,因为程序不依赖于外部的库文件。
- 性能:由于每个程序都包含完整的代码和数据,所以静态库可以提高程序的执行速度。
- 安全性:静态库不会受到动态库版本兼容性问题的影响,因此更加安全。
静态库的缺点:
- 浪费内存:每个程序都需要包含完整的代码和数据,因此静态库会占用更多的磁盘空间和内存。
- 不灵活:如果需要更新静态库的版本,那么需要重新编译程序,并重新分发给用户。
小结:
- 动态库因为是共享库,有效的节省资源(磁盘空间,内存空间,网络空间等)[优]动态库一旦缺失,导致各个程序都无法运行[缺点]
- 静态库,不依赖库,程序可以独立运行[优点],体积大,比较消耗资源[缺]
debug和release
在Linux中,Debug和Release是两种不同的编译模式,其主要区别在于编译器优化和符号表信息。
Debug模式:
- 编译器不会对代码进行优化,生成的可执行文件包含完整的符号表信息,以便调试程序时能够进行源代码级别的调试。
- 可执行文件的体积通常比较大,因为包含了完整的符号表信息和调试相关的代码。
- Debug模式通常用于开发阶段,方便开发人员进行调试和定位问题。
Release模式:
- 编译器会对代码进行优化,以提高程序的执行效率和减小可执行文件的体积。
- 可执行文件不包含完整的符号表信息,因此不能进行源代码级别的调试。
- Release模式通常用于发布阶段,生成最终的产品版本。
我们默认编译生成的是release版本,如果我们想要生成debug版本可以添加一个-g选项: gcc -o mytest_debug mycode.s。
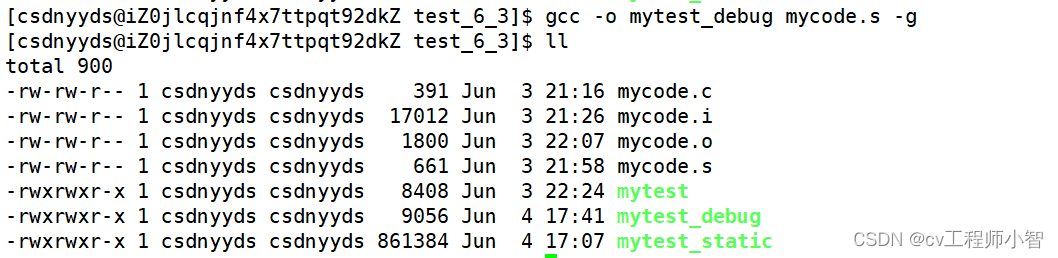
我们可以看到debug版本比release版本所占的字节数是要大一点点的。
?小结?
今天我们学习了Linux编译器gcc/g++的使用相信大家看完有一定的收获。
种一棵树的最好时间是十年前,其次是现在! 把握好当下,合理利用时间努力奋斗,相信大家一定会实现自己的目标!加油!创作不易,辛苦各位小伙伴们动动小手,三连一波??~~~,本文中也有不足之处,欢迎各位随时私信点评指正!






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结