您现在的位置是:首页 >技术教程 >Maxcompute 数据上云一致性比对网站首页技术教程
Maxcompute 数据上云一致性比对
我写过很多如何去对数、如何批量对数的技术文档,最近项目遇到这个问题,我才发现在官方博客上还没有发布过这个课题的文章。这就像灯下黑,太长用到的知识点,反而没有意识到其重要性。
注:这里对数的场景就是指在阿里云平台使用dataworks等大数据开发工具集成业务系统数据库(oracle等)数据上云到maxcompute的场景,所以,示例的SQL也是针对maxcompute。
先说说一般业务上怎么对数的,我们做了一个报表,出了一个数据“某个产品卖了30个”。这个不只是在大数据平台上有这个数据,在业务系统也有这个数据,这些统计动作在业务系统通过程序和人工也会有一份,一般做好报表后会先对这个数据。
所以,第一线反馈回来的数据就是这个汇总数据不一致的问题。然而这个结果是非常概括的,因为就像我感觉这个月工资少发了5毛一样,如果我不看我的工资条我其实不知道自己是不是少发了。工资条不只是一个汇总数据,里面有我税前工资、奖金(浮动)、社保、扣税等一系列的明细数据,这些数据让我去判断我是不是少了5毛,而加工过的数据是复杂的。
说到这里,我其实就像表达一个事情,对数是要对明细数据。这是一切计算后事实的基础,可以拿出来作证的。
所以,两边都查一下这个汇总值使用的表的对应的记录,比如说查询“今天这个产品ID的售卖记录”。结果就发现业务系统有31笔,而大数据平台有30笔。
即便到了这里,其实我们仍然不知道期间发生了什么,为什么会丢失数据。另外我们还不知道其他商品ID的数据是不是也有丢失的,还有其他的表的数据是不是也会发生类似的情况。
1.明细数据比对
既然最终都是对明细数据,那么我是不是可以直接比对明细数据呢?回答是:正确。
一般发生这种情况,首先要比对业务系统和大数据平台两个表的数据。
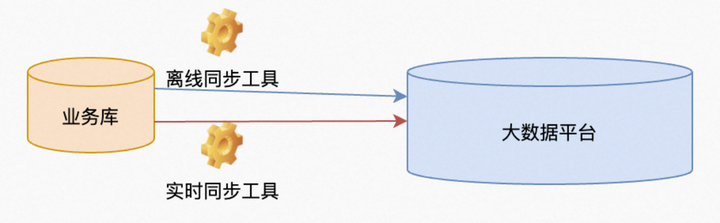
1.再利用全量集成工具,从业务系统的数据库全量抽取一遍数据到大数据平台。比对数据一定要把数据放到一起,隔空比对是不存在的。因为大数据平台的容量是数百倍于业务系统的,所以,一般都在大数据平台比对。(这里有一个悖论,如果集成工具本身就有缺陷,导致抽取过程中就丢数据,岂不是永远没办法比对了。所以,如果对这个工具也不确定就得从数据库导出数据到文件,然后再加载到某个数据库上去比对。在这里,通过我对离线集成这个产品的常年使用经验,这个工具是非常可靠的,还未遇到过这个问题。)
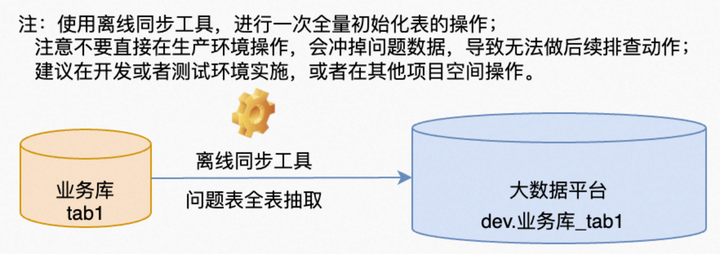
2.根据主键关联,比对2个表中的主键的差异。如果是上面提到的记录丢失的问题,这一步做完就很容易比对出来了。这里还会发现一个问题,就是业务系统的表是不断变化的,所以,这时与大数据平台的表对比会有差异。这个差异的核心原因是:大数据平台的表是业务系统表在每日的日末(00:00:00)的一个时点数据,而业务系统的数据是一直在变化的。所以,即便有差异超出预期也不要惊慌。如果是使用实时同步可以从归档日志中获取到这期间数据的每一条变化,可以追溯变化原因。如果没有实时同步,也可以通过表中与时间相关字段去判断数据是否被更新掉。要是什么都没有(这种情况也是存在的),那就去骂骂设计表的业务系统开发(没错,是他们的锅),也可以跟业务去详细了解一下,这行记录是不是今天做的,而不是昨天。
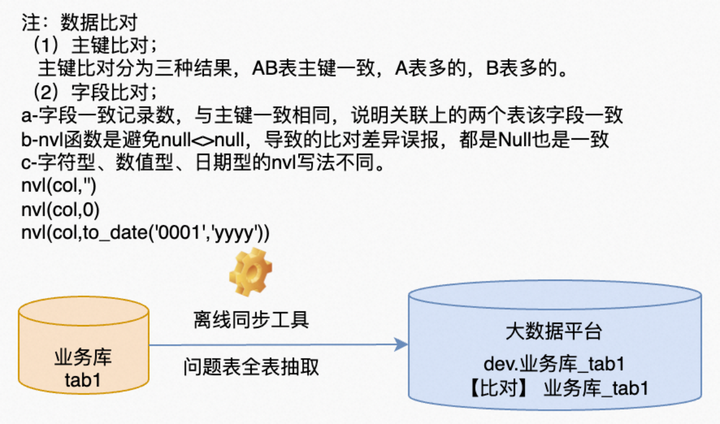
3.还有一种情况,就是主键一致,数据内容(主键之外的字段)不一致。这种情况,还是需要考虑数据变化的情况,可以从日志、时间字段、业务等几个角度去比对。如果发现数据确实不符合预期,就需要查询同步工具的问题。
2.比对SQL分析
在上面的章节,我描述了比对今天新抽取的全量表和上日在maxcompute上使用前日全量和上日增量合并的上日全量的环节。比对两张表集合是否一致的SQL方法其实比较简单,大家第一时间就会想到集合操作。在oracle里面有Minus、except,同样在maxcompute里面也有。但是为了便于分析问题,我还是自己写了一个SQL。示例SQL(maxcompute sql)如下:
--限定日期分区,比对上日
select count(t1.BATCH_NUMBER) as cnt_left
,count(t2.BATCH_NUMBER) as cnt_right
,count(concat(t1.BATCH_NUMBER,t2.BATCH_NUMBER)) as pk_inner
,count(case when t1.BATCH_NUMBER is not null and t2.BATCH_NUMBER is null then 1 end) as pk_left
,count(case when t2.BATCH_NUMBER is not null and t1.BATCH_NUMBER is null then 1 end) as pk_right
,count(case when nvl(t1.rec_id ,'') = nvl(t2.rec_id ,'') then 1 end) as col_diff_rec_id
,count(case when nvl(t2.rec_creator ,'') = nvl(t1.rec_creator ,'') then 1 end) as col_diff_rec_creator
,count(case when nvl(t2.rec_create_time,'') = nvl(t1.rec_create_time,'') then 1 end) as col_diff_rec_create_time
from ods_dev.o_rz_lms_im_timck01 t1 -- 开发环境重新初始化的今天数据
full join ods.o_rz_lms_im_timck01 t2 -- 生产环节昨日临时增量合并的数据
on t1.BATCH_NUMBER =t2.BATCH_NUMBER
and t1.IN_STOCK_TIME =t2.IN_STOCK_TIME
and t1.OP_NO =t2.OP_NO
and t1.STOCK_CODE =t2.STOCK_CODE
and t1.YP_ID =t2.YP_ID
and t2.ds='20230426'
where t1.ds='20230426'
;
--cnt_left 9205131 说明:左表有记录数 9205131
--cnt_right 9203971 说明:右表有记录数 9203971
--pk_inner 9203971 说明:主键关联一致记录数 9203971
--pk_left 1160 说明:左表比右表多记录数 1160
--pk_right 0 说明:右表比左表多有记录数 0
--col_diff_rec_id 9203971 说明:字段一致记录数与主键一致相同,说明关联上的两个表该字段一致
--col_diff_rec_creator 9203971 说明:同上
--col_diff_rec_create_time 9203971 说明:同上在上面的例子中,左表是今天重新初始化的数据,右表是在maxcompute上merge的上日全量数据。在比对之前,我们其实就应该了解这两个表的数据必然是不一致的。虽然是同一张表,但是时点是不一致的。
不一致包括几种:
1.t1表中存在的主键,在t2表中不存在;
2.t2表中存在的主键,在t1表中不存在;
3.t1和t2表中都存在的主键,但是主键之外的字段值不一致;
4.t1和t2表中都存在的主键,但是主键之外的字段值一致;
除去第4中情况,其他3种状态都是两个表的值不一致,都需要进一步核查。如果是正常情况下,第1种情况是在今天零点以后新insert到业务库中的数据,第2种情况是今天零点以后delete的业务库中的数据,第3种情况是今天零点之后update的数据,第4种情况是业务表中今天零点之后未被更新的数据。
了解这些状况后,我们就可以依据可循去识别
3.Dataworks实时同步日志表
如果同步才有的是DataWorks的离线同步,其实观测以上数据变化是有些困难的。如果我们采用实时同步,数据库数据的变化是都会保留下来的。上一章节中提到的变化,都可以从日志中观测到。下面SQL,就是我查询这个变化使用的SQL,查询(dataworks实时数据同步日志表)示例SQL如下:
select from_unixtime(cast(substr(to_char(_execute_time_),1,10) as bigint)) as yy
,get_json_object(cast(_data_columns_ as string),"$.rec_id") item0
,x.*
from ods.o_rz_lms_odps_first_log x -- 实时同步数据源 o_rz_lms 的日志表
where year='2023' and month='04' and day>='10' --数据区间限制
--and hour ='18'
and _dest_table_name_='o_rz_lms_im_timck01' --数据表限制
-- 以下为主键字段
and get_json_object(cast(_data_columns_ as string),"$.yp_id") ='L1'
and get_json_object(cast(_data_columns_ as string),"$.batch_number") ='Y1'
and get_json_object(cast(_data_columns_ as string),"$.in_stock_time") ='2'
and get_json_object(cast(_data_columns_ as string),"$.op_no") ='9'
and get_json_object(cast(_data_columns_ as string),"$.stock_code") ='R'
--and _operation_type_='D'
order by _execute_time_ desc
limit 1000
;
-- _execute_time_ 数据操作时间
-- _operation_type_ 操作类型 增删改UDI
-- _sequence_id_ 序列号,不会重复
-- _before_image_ 修改前数据
-- _after_image_ 修改后数据
-- _dest_table_name_ 操作的表名
-- _data_columns_ 操作的数据内容JSONDataWorks的实时同步的数据源每隔一段时间就会实时写入到一张以“数据源名+_odps_first_log”命名的表中,表有年、月、日、时四级分区。该表的主键并不是数据操作时间,而是序列号“_execute_time_”,所以,一行数据主键的更新顺序是按照“_execute_time_”更新。
一行数据更新是有前后两个状态的,所以有“_before_image_ 修改前数据、_after_image_ 修改后数据”这两个字段来标识前后状态。
数据是在字段“_data_columns_”中,以JSON格式存储。为了识别其中的某一行数据,我使用函数解析了对应的字段,以此来确定自己要的数据。
4.持续的质量保障
到这里,我并未讲如何去处理数据不一致的情况。如果确实发现数据不一致,可用的处理方式就是重新初始化全量数据。在这里要强调一点,如果离线全量集成工具是可信的,全量初始化的数据就不会丢。但是如果这种方式不可信,则就要更换方法。
在很多情况下,源端做一些业务变更也会偶发数据异常。在数据丢失原因未查明的情况下,需要经常的去做数据一致性的比对,做到防患于未然。所以,日常监控数据数据一致性也是非常重要的。
本文为阿里云原创内容,未经允许不得转载。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结