您现在的位置是:首页 >技术交流 >机器学习:基于XGBoost对信用卡欺诈行为的识别网站首页技术交流
机器学习:基于XGBoost对信用卡欺诈行为的识别

机器学习:基于XGBoost对信用卡欺诈行为的识别
作者:i阿极
作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页
???如果觉得文章不错或能帮助到你学习,可以点赞?收藏?评论?+关注哦!???
???如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!?
大家好,我i阿极。喜欢本专栏的小伙伴,请多多支持
文章目录
1、XGBoost算法的介绍
XGBoost(eXtreme Gradient Boosting)是一种梯度提升树算法,它是基于决策树的集成学习方法。相对于传统的梯度提升树算法,XGBoost引入了一些创新的技术,如正则化、并行计算和缺失值处理,以提高模型的准确性和效率。下面详细讲解XGBoost算法的原理和关键步骤:
-
梯度提升树:
XGBoost算法基于梯度提升树,梯度提升树是一种集成学习算法,通过迭代地训练多个决策树,并将它们组合起来构建一个强大的模型。每个决策树都通过拟合残差来逐步改进模型的预测能力。 -
损失函数:
XGBoost使用一种灵活的损失函数来衡量模型预测结果的准确性。常用的损失函数有平方损失函数(用于回归问题)和对数损失函数(用于二分类问题)。XGBoost还支持自定义的损失函数。 -
树的结构:
XGBoost使用CART(Classification and Regression Trees)决策树作为基础模型。决策树通过将输入空间划分为多个区域,并在每个区域内预测目标变量的值。 -
正则化:
XGBoost引入了正则化项来控制模型的复杂度,防止过拟合。正则化项包括L1正则化和L2正则化,它们分别对应于权重的绝对值和平方和。正则化可以促使模型更加稀疏,削弱不重要的特征的影响。 -
样本权重和学习率:
XGBoost通过样本权重和学习率来控制每个样本对模型的贡献。样本权重可以根据样本的重要性进行调整,学习率则控制每次迭代的步长,避免过拟合并提高模型的稳定性。 -
并行计算:
XGBoost通过利用并行计算的能力,提高了训练和预测的速度。它支持在特征和样本级别上进行并行计算,以加快模型训练的速度。 -
缺失值处理:
XGBoost能够自动处理缺失值,无需对缺失值进行处理或填充。在决策树的划分过程中,XGBoost可以将缺失值放入左子树或右子树中,以最大程度地提高模型的准确性。 -
特征重要性评估:
XGBoost提供了一种方法来评估特征的重要性,这对于特征选择和模型解释非常有用。通过计算每个特征在模型中的分裂次数或分裂增益,可以得到特征的重要性排序。
2、SMOTE算法思想
SMOTE(Synthetic Minority Over-sampling Technique)是一种用于解决类别不平衡问题的算法,特别适用于处理少数类样本较少的情况。其主要思想是通过合成新的少数类样本来增加训练数据,从而达到平衡类别分布的目的。
SMOTE算法的基本思想如下:
-
针对少数类样本,选择一个样本作为基准样本。
-
随机选择该基准样本的若干个最近邻样本(通常是k个),这些最近邻样本必须属于同一类别。
-
对于每个最近邻样本,计算基准样本与其之间的差值,得到一个差值向量。
-
根据差值向量和一个介于0和1之间的随机数,合成新的样本。
-
重复上述步骤,直到生成足够数量的新样本。
通过SMOTE算法生成的合成样本具有两个特点:
-
新样本位于原有样本之间的线段上,因此可以认为新样本是原有样本的线性插值。
-
生成的新样本在特征空间中均匀分布,有助于丰富少数类样本的特征表达。
SMOTE算法的目标是通过增加合成样本来改善模型在少数类样本上的学习效果。通过引入合成样本,可以使得模型更好地捕捉少数类样本的特征和边界,提高分类器的性能。
需要注意的是,SMOTE算法应该在训练集上应用,而不是在整个数据集上。这是因为合成的样本是基于少数类样本生成的,为了保持测试集的独立性,应该在测试集上不使用SMOTE。
2、XGBoost函数介绍
XGBClassifier(max_depth=3, learning_rate=0.1, n_estimators=100, silent=True,
objective='binary:logistic', booster='gbtree', n_jobs=1, nthread=None,
gamma=0, min_child_weight=1, max_delta_step=0, subsample=1,
colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1,
scale_pos_weight=1, base_score=0.5, random_state=0, seed=None, missing=None)
- max_depth:用于指定每个基础模型所包含的最大深度,默认为3层。
- learning_rate:用于指定模型迭代的学习率或步长,默认为0.1,即对应的梯度提升模型F_T(x)可以表示为F_T(x)=F_T−1(x)+υf_t(x):,其中的υ就是该参数的指定值,默认值为1;对于较小的学习率υ而言,则需要迭代更多次的基础分类器,通常情况下需要利用交叉验证法确定合理的基础模型的个数和学习率。
- n_estimators:用于指定基础模型的数量,默认为100个。
- silent:bool类型参数,是否输出算法运行过程中的日志信息,默认为True。
- booster:用于指定基础模型的类型,默认为’gbtree’,即CART模型,也可以是’gblinear’,表示基础模型为线性模型。
- objective:用于指定目标函数中的损失函数类型,对于分类型的XGBoost算法,默认的损失函数为二分类的Logistic损失(模型返回概率值),也可以是’multi:softmax’,表示用于处理多分类的损失函数(模型返回类别值),还可以是’multi:softprob’,与’multi:softmax’相同,所不同的是模型返回各类别对应的概率值;对于预测型的XGBoost算法,默认的损失函数为线性回归损失。
- n_jobs:用于指定XGBoost算法在并行计算时所需的CPU数量,默认为1表示仅使用1个CPU运行算法,即不使用并行运算功能。
- nthread:用于指定XGBoost算法在运行时所使用的线程数,默认为None,表示使用计算机最大可能的线程数。
- gamma:用于指定节点分割所需的最小损失函数下降值,即增益值Gain的阈值,默认为0。
- min_child_weight:用于指定叶子节点中各样本点二阶导之和的最小值,即H_j的最小值,默认为1,该参数的值越小,模型越容易过拟合。
- max_delta_step:用于指定模型在更新过程中的步长,如果为0,表示没有约束;如果取值为某个较小的正数,就会导致模型更加保守。
- subsample:用于指定构建基础模型所使用的抽样比例,默认为1,表示使用原始数据构建每一个基础模型;当抽样比例小于1时,表示构建随机梯度提升树模型,通常会导致模型的方差降低,偏差提高。
- colsample_bytree:用于指定每个基础模型所需的采样字段比例,默认为1,表示使用原始数据的所有字段。
- colsample_bylevel:用于指定每个基础模型在节点分割时所需的采样字段比例,默认为1,表示使用原始数据的所有字段。
- reg_alpha:用于指定L1正则项的系数,默认为0。
- reg_lambda:用于指定L2正则项的系数,默认为1。
- scale_pos_weight:当各类别样本的比例十分不平衡时,通过设定该参数设定为一个正值,可以使算法更快收敛。
- base_score:用于指定所有样本的初始化预测得分,默认为0.5。
- random_state:用于指定随机数生成器的种子,默认为0,表示使用默认的随机数生成器。
- seed:同random_state参数。
- missing:用于指定缺失值的表示方法,默认为None,表示NaN即为默认值。
3、SMOTE函数介绍
SMOTE(ratio='auto', random_state=None, k_neighbors=5, m_neighbors=10,
out_step=0.5, kind='regular', svm_estimator=None, n_jobs=1)
- ratio:用于指定重抽样的比例,如果指定字符型的值,可以是’minority’(表示对少数类别的样本进行抽样)、‘majority’(表示对多数类别的样本进行抽样)、‘not minority’(表示采用欠采样方法)、‘all’(表示采用过采样方法),默认为’auto’,等同于’all’和’not minority’。如果指定字典型的值,其中键为各个类别标签,值为类别下的样本量。
- random_state:用于指定随机数生成器的种子,默认为None,表示使用默认的随机数生成器。
- k_neighbors:指定近邻个数,默认为5个。
- m_neighbors:指定从近邻样本中随机挑选的样本个数,默认为10个。
- kind:用于指定SMOTE算法在生成新样本时所使用的选项,默认为’regular’,表示对少数类别的样本进行随机采样,也可以是’borderline1’ ‘borderline2’和’svm’。
- svm_estimator:用于指定SVM分类器,默认为sklearn.svm.SVC,该参数的目的是利用支持向量机分类器生成支持向量,然后生成新的少数类别的样本。
- n_jobs:用于指定SMOTE算法在过采样时所需的CPU数量,默认为1表示仅使用1个CPU运行算法,即不使用并行运算功能。
4、实验环境
Python 3.9
Anaconda
Jupyter Notebook
5、案例实战——信用卡欺诈行为的识别
5.1读取数据
creditcard = pd.read_csv(r'D:creditcard.csv')
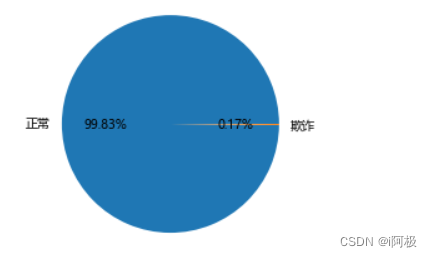
5.2统计交易是否为欺诈的频数
import matplotlib.pyplot as plt
plt.axes(aspect = 'equal')
# 统计交易是否为欺诈的频数
counts = creditcard.Class.value_counts()
# 绘制饼图
plt.pie(x = counts, # 绘图数据
labels=pd.Series(counts.index).map({0:'正常',1:'欺诈'}), # 添加文字标签
autopct='%.2f%%' # 设置百分比的格式,这里保留一位小数
)
# 显示图形
plt.show()
5.3数据拆分为训练集和测试集
# 删除自变量中的Time变量
from sklearn import model_selection
X = creditcard.drop(['Time','Class'], axis = 1)
y = creditcard.Class
# 数据拆分
X_train,X_test,y_train,y_test = model_selection.train_test_split(X,y,test_size = 0.3, random_state = 1234)
5.4运用SMOTE算法实现训练数据集的平衡
# 导入第三方包
from imblearn.over_sampling import SMOTE
import imblearn
# 运用SMOTE算法实现训练数据集的平衡
over_samples = SMOTE(random_state=1234)
over_samples_X,over_samples_y = over_samples.fit_resample(X_train, y_train)
# 重抽样前的类别比例
print(y_train.value_counts()/len(y_train))
# 重抽样后的类别比例
print(pd.Series(over_samples_y).value_counts()/len(over_samples_y))

5.5构建XGBoost分类器
# 导入第三方包
import xgboost
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
import numpy as np
# 构建XGBoost分类器
xgboost = xgboost.XGBClassifier()
# 使用重抽样后的数据,对其建模
xgboost.fit(over_samples_X,over_samples_y)
# 将模型运用到测试数据集中
resample_pred = xgboost.predict(np.array(X_test))
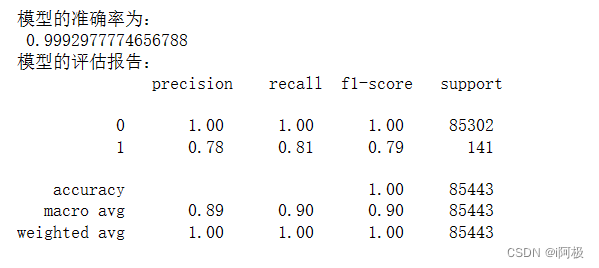
# 返回模型的预测效果
print('模型的准确率为:
',metrics.accuracy_score(y_test, resample_pred))
print('模型的评估报告:
',metrics.classification_report(y_test, resample_pred))
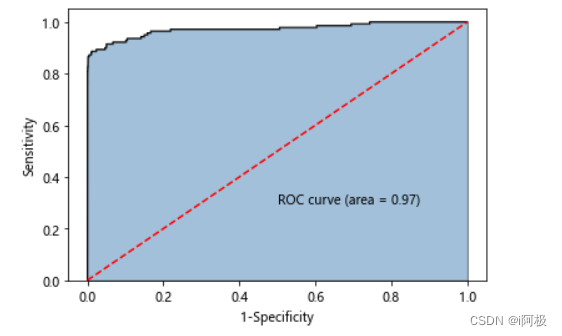
5.6计算欺诈交易的概率值,用于生成ROC曲线的数据
from sklearn import metrics
y_score = xgboost.predict_proba(np.array(X_test))[:,1]
fpr,tpr,threshold = metrics.roc_curve(y_test, y_score)
# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)
# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black')
# 添加边际线
plt.plot(fpr, tpr, color='black', lw = 1)
# 添加对角线
plt.plot([0,1],[0,1], color = 'red', linestyle = '--')
# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc)
# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
# 显示图形
plt.show()
?文章下方有交流学习区!一起学习进步!???
?首发CSDN博客,创作不易,如果觉得文章不错,可以点赞?收藏?评论?
?你的支持和鼓励是我创作的动力❗❗❗






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结