您现在的位置是:首页 >技术教程 >K8s in Action 阅读笔记——【9】Deployments: updating applications declaratively网站首页技术教程
K8s in Action 阅读笔记——【9】Deployments: updating applications declaratively
K8s in Action 阅读笔记——【9】Deployments: updating applications declaratively
集群配置:

本章介绍如何更新运行在Kubernetes集群中的应用,以及Kubernetes如何帮助你实现真正的零停机更新过程。虽然这可以仅使用ReplicationControllers或ReplicaSets来完成,但Kubernetes还提供了一个Deployment资源,它位于ReplicaSets之上,并支持声明性应用程序更新。
9.1 Updating applications running in pods
让我们从一个简单的示例开始。假设有一组Pod实例为其他Pod或外部客户端提供服务。这些Pod由ReplicationController或ReplicaSet支持。还存在一个Service,通过该Service客户端可以访问这些Pod。这是Kubernetes中基本应用程序的样子(如图9.1所示)。
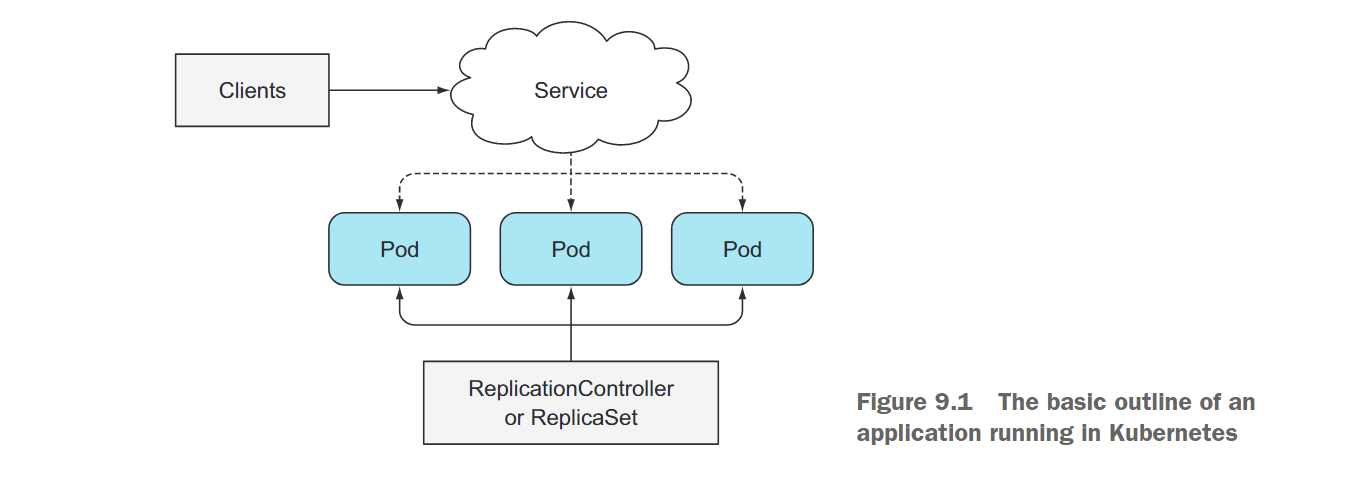
最初,Pod运行的是你的应用程序的第一个版本,假设其镜像标记为v1。然后,你开发了该应用程序的新版本,并将其作为一个新的镜像推送到镜像仓库中,标记为v2。接下来,你想要使用这个新版本替换所有的Pod。由于无法在Pod创建后更改现有Pod的镜像,你需要删除旧的Pod并替换它们以运行新镜像的新Pod。有两种更新所有这些Pod的方法。你可以选择以下其中一种方式进行操作:
- 首先删除所有现有的Pod,然后启动新的Pod。
- 启动新的Pod,一旦它们启动成功后,再删除旧的Pod。你可以一次性添加所有新的Pod,然后一次性删除所有旧的Pod;或者逐步添加新的Pod并逐步删除旧的Pod。
这两种策略都有各自的优缺点。第一种选项会导致应用程序在短时间内不可用。第二种选项要求应用程序能够同时运行两个版本的应用。如果应用程序将数据存储在数据存储中,新版本不应以破坏先前版本的方式修改数据模式或数据。
看一下如何手动执行这些操作。
9.1.1 Deleting old pods and replacing them with new ones
可以通过ReplicationController将其所有的Pod实例替换为运行新版本的Pod。而且ReplicationController的Pod模板可以随时进行更新。当ReplicationController创建新的实例时,它使用更新后的Pod模板来创建这些实例。
如果你有一个管理一组v1 Pod的ReplicationController,你可以通过修改Pod模板,使其引用镜像的v2版本,然后删除旧的Pod实例来轻松替换它们。ReplicationController会注意到没有Pod与其标签选择器匹配,然后它会启动新的实例。整个过程如图9.2所示。
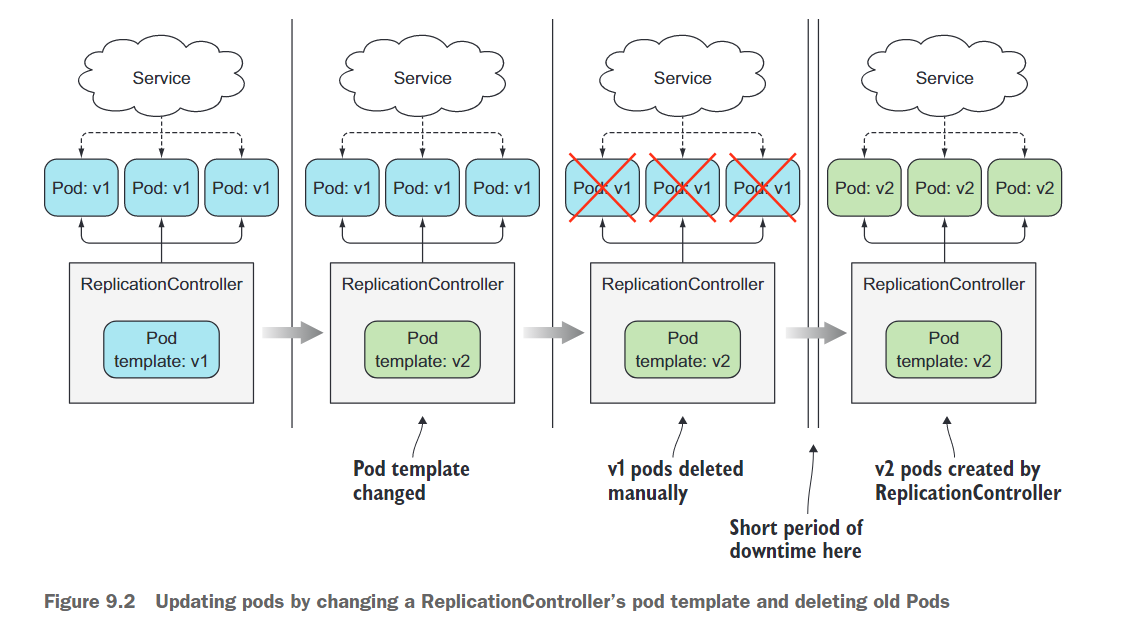
这是更新一组Pod的最简单方法,不过需要有短暂的服务停止时间。
9.1.2 Spinning up(启动) new pods and then deleting the old one
如果你不想看到任何服务停止,并且你的应用程序支持同时运行多个版本,可以反过来,首先启动所有的新Pod,然后再删除旧的Pod。这将需要更多的硬件资源,因为在短时间内你将同时运行两倍数量的Pod。
一次性切换从旧版本到新版本
Pod通常由Service作为前端。在引入运行新版本的Pod之前,可以让Service只作为初始版本的Pod的前端。然后,一旦所有新的Pod都启动起来,可以更改Service的标签选择器,让Service切换到新的Pod,如图9.3所示。这被称为蓝绿部署。切换完成后,一旦确保新版本的功能正常,可以通过删除旧的Replica
tionController来删除旧的Pod。
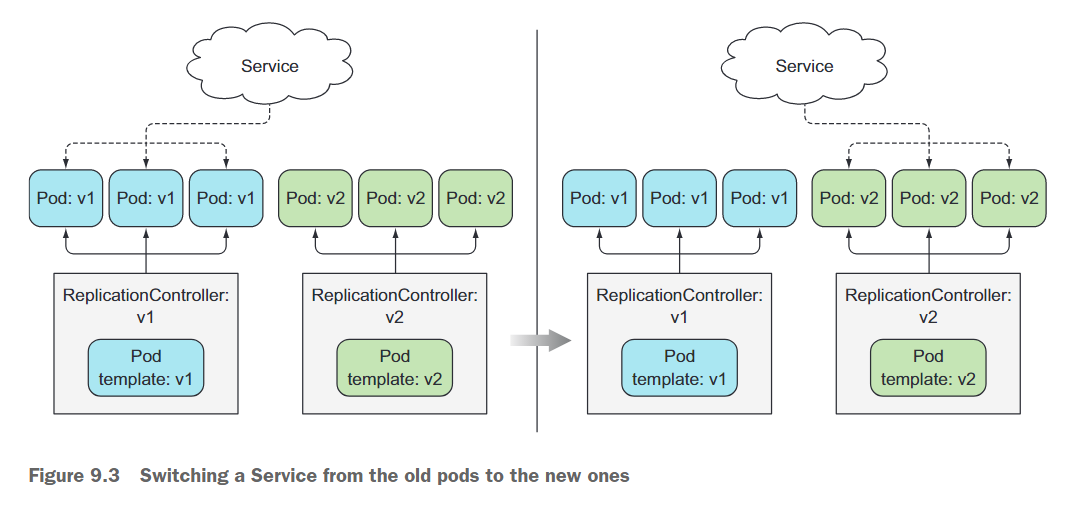
可以使用kubectl set selector命令来更改Service的Pod选择器。
执行滚动更新
与一次性启动所有新的Pod并删除旧的Pod不同,还可以执行逐步替换Pod的滚动更新。通过逐步缩减先前的ReplicationController并扩大新的ReplicationController来实现这一点。在这种情况下,Service的Pod选择器包括旧的和新的Pod,以便将请求发送到两组Pod,如图9.4所示。
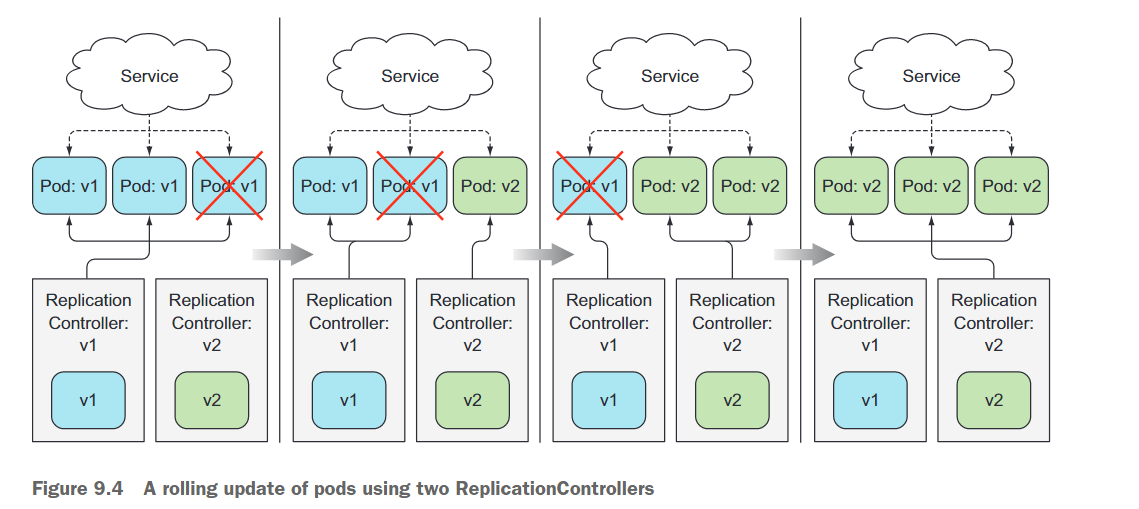
手动执行滚动更新是费时且容易出错的。根据副本数,你需要按正确的顺序运行十几个或更多个命令来执行更新过程。幸运的是,Kubernetes允许使用单个命令执行滚动更新。
9.2 Performing an automatic rolling update with a ReplicationController
这一章介绍的方法和API已经过时了,不再介绍。
9.3 Using Deployments for updating apps declaratively
Deployment是一个更高级的资源,用于部署应用程序并以声明性的方式更新它们,而不是通过ReplicationController或ReplicaSet进行操作,这两个概念都被认为是较低级别的概念。
创建Deployment时,会在其下面创建一个或多个ReplicaSet资源(就像在第4章中所提到的那样)。ReplicaSet是ReplicationController的新一代,并且应该替代它们使用。ReplicaSet也负责复制和管理Pod。使用Deployment时,实际的Pod是由Deployment的ReplicaSet创建和管理的,而不是由Deployment直接创建(这种关系如图9.8所示)。

为什么要引入一个额外的对象来覆盖ReplicationController或ReplicaSet:当更新应用程序时,需要引入另一个ReplicationController并协调两个控制器,使它们在互不干扰的情况下协同工作。需要有一种协调这种过程的机制。Deployment资源负责处理这个过程(实际上不是Deployment资源本身,而是运行在Kubernetes控制平面中的控制器进程负责这个任务)。
使用Deployment而不是较低级别的构建方式可以使应用程序的更新变得更加容易,只需要通过单个Deployment资源定义所需的状态,然后让Kubernetes来处理剩下的工作。
9.3.1 Creating a Deployment
创建一个Deployment配置文件
# kubia-deployment-v1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubia
spec:
selector:
matchLabels:
app: kubia
replicas: 3
template:
metadata:
labels:
app: kubia
name: kubia
spec:
containers:
- image: luksa/kubia:v1
name: nodejs
# 可以使用---划分不同的资源
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
selector:
app: kubia
type: NodePort
ports:
- name: kubia
port: 80
targetPort: 8080
nodePort: 30021
Deployment则不涉及具体的版本信息。在某个时间点,一个Deployment可以管理多个不同版本的Pod,因此它的名称不应该包含应用程序的版本信息。
创建Deployment资源
$ kubectl create -f kubia-deployment-v1.yaml --record
deployment.apps/kubia created
确保包括–record命令行选项。这会在修订历史记录中记录该命令,将在以后有用。
显示Deployment rollout的状态
$ kubectl rollout status deployment kubia
deployment "kubia" successfully rolled out
根据这个命令的输出,Deployment已经成功部署完成,所以应该看到三个Pod副本正在运行:
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
kubia-74967b5695-f4rrg 1/1 Running 0 4m1s
kubia-74967b5695-ghq72 1/1 Running 0 4m1s
kubia-74967b5695-lxwhz 1/1 Running 0 4m1s
Deployment如何创建ReplicaSet
从上面查看Pod的信息可以看出,Pod的名称由三部分组成kubia、74967b5695和f4rrg。其中kubia-74967b5695代表了ReplicaSet的名称:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
kubia-74967b5695 3 3 3 7m40s
ReplicaSet的名称也包含了其Pod模板的哈希值。正如之后将会看到的,一个Deployment会创建多个ReplicaSet,每个ReplicaSet对应一个Pod模板的版本。使用Pod模板的哈希值可以确保Deployment始终使用相同ReplicaSet来管理特定版本的Pod模板。
访问Pod
使用创建的Service访问Pod
$ kubectl get svc kubia
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubia NodePort 10.109.2.215 <none> 80:30021/TCP 49m
$ curl 33.33.33.108:30021
This is v1 running in pod kubia-74967b5695-f4rrg
9.3.2 Updating a Deployment
如何更新一个Deployment。唯一需要做的就是修改Deployment资源中定义的Pod模板,Kubernetes将执行所有必要的步骤,使实际系统状态与资源定义的状态相匹配。类似于缩放ReplicationController或ReplicaSet的大小,你只需要在Deployment的Pod模板中引用一个新的镜像标签,然后让Kubernetes将系统转换为新的期望状态。
了解可用的部署策略
新状态应如何实现是由配置在Deployment上的部署策略决定的。默认策略是执行滚动更新(该策略称为RollingUpdate)。另一种策略是Recreate策略,它一次性删除所有旧的Pod,然后创建新的Pod。
Recreate策略会在创建新的Pod之前删除所有旧的Pod。当你的应用程序不支持同时运行多个版本,并且需要在启动新版本之前完全停止旧版本时,可以使用此策略。这种策略会导致应用程序在短暂时间内完全不可用。
另一方面,RollingUpdate策略会逐个删除旧的Pod,并同时添加新的Pod,确保应用程序在整个过程中保持可用,并确保其处理请求的能力不会下降。这是默认的策略。可以配置上下限来限制副本数目在期望副本数目之上或之下。只有当你的应用程序可以同时运行旧版本和新版本时,才应该使用此策略。
出于演示目的,降低滚动更新的速度
在下一个练习中,你将使用RollingUpdate策略,但是需要稍微减慢更新过程,以便可以看到更新确实是以滚动方式进行的。可以通过在Deployment上设置minReadySeconds属性来实现。现在,使用kubectl patch命令将其设置为10秒。
$ kubectl patch deployment kubia -p '{"spec": {"minReadySeconds": 10}}'
deployment.apps/kubia patched
kubectl patch是一个命令行工具,用于对Kubernetes资源进行部分更新(partial update)。它允许你对资源的特定字段进行更改,而无需提供完整的资源规范。
使用patch命令来更改Deployment的spec。这不会触发对Pod的任何更新,因为你没有更改Pod模板。更改其他Deployment属性,如期望的副本数或部署策略,也不会触发滚动更新,因为它不会以任何方式影响现有的个别Pod。
触发滚动更新
使用如下命令观察Pod的变化:
$ while true; do curl http:/33.33.33.108:30021; sleep 2; done
更改Deployment的镜像版本,触发滚动更新:
$ kubectl set image deployment kubia nodejs=luksa/kubia:v2
deployment.apps/kubia image updated
当你执行此命令时,会更新kubia Deployment的Pod模板,将其nodejs容器中使用的映像更改为luksa/kubia:v2(从v1)。如图9.9所示:
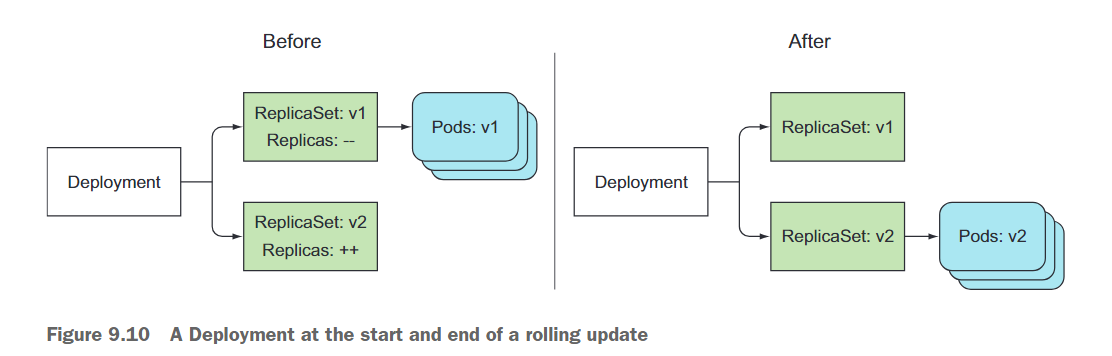
如果你运行了curl循环,你将看到请求最初只会命中v1的Pod,然后越来越多的请求会命中v2的Pod,直到最后,所有的请求只会命中剩下的v2的Pod,此时所有的v1的Pod都已被删除。
$ while true; do curl http:/33.33.33.108:30021; sleep 2; done
This is v1 running in pod kubia-74967b5695-ghq72
This is v1 running in pod kubia-74967b5695-lxwhz
This is v1 running in pod kubia-74967b5695-lxwhz
This is v1 running in pod kubia-74967b5695-ghq72
This is v1 running in pod kubia-74967b5695-ghq72
This is v1 running in pod kubia-74967b5695-f4rrg
This is v1 running in pod kubia-74967b5695-f4rrg
This is v2 running in pod kubia-bcf9bb974-rvsq6
This is v1 running in pod kubia-74967b5695-f4rrg
This is v1 running in pod kubia-74967b5695-lxwhz
This is v2 running in pod kubia-bcf9bb974-rvsq6
This is v1 running in pod kubia-74967b5695-ghq72
This is v1 running in pod kubia-74967b5695-lxwhz
This is v2 running in pod kubia-bcf9bb974-rvsq6
This is v1 running in pod kubia-74967b5695-ghq72
This is v1 running in pod kubia-74967b5695-lxwhz
This is v2 running in pod kubia-bcf9bb974-pp2n2
This is v2 running in pod kubia-bcf9bb974-pp2n2
This is v2 running in pod kubia-bcf9bb974-tknqx
This is v1 running in pod kubia-74967b5695-ghq72
This is v2 running in pod kubia-bcf9bb974-tknqx
This is v2 running in pod kubia-bcf9bb974-rvsq6
This is v2 running in pod kubia-bcf9bb974-tknqx
This is v2 running in pod kubia-bcf9bb974-pp2n2
This is v2 running in pod kubia-bcf9bb974-rvsq6
This is v2 running in pod kubia-bcf9bb974-pp2n2
This is v2 running in pod kubia-bcf9bb974-rvsq6
This is v2 running in pod kubia-bcf9bb974-rvsq6
This is v2 running in pod kubia-bcf9bb974-tknqx
This is v2 running in pod kubia-bcf9bb974-pp2n2
This is v2 running in pod kubia-bcf9bb974-pp2n2
This is v2 running in pod kubia-bcf9bb974-tknqx
This is v2 running in pod kubia-bcf9bb974-rvsq6
This is v2 running in pod kubia-bcf9bb974-pp2n2
This is v2 running in pod kubia-bcf9bb974-pp2n2
可以看到旧的ReplicaSet还存在:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
kubia-74967b5695 0 0 0 33m
kubia-bcf9bb974 3 3 3 4m2s
9.3.3 Rolling back a deployment
创建应用的v3版本
在版本3中,你将引入一个错误,使你的应用程序只能正确处理前四个请求。从第五个请求开始的所有请求都将返回内部服务器错误(HTTP状态码500)。你将通过在处理程序函数的开头添加一个if语句来模拟这个错误。如下所示:
const http = require('http');
const os = require('os');
var requestCount = 0;
console.log("Kubia server starting...");
var handler = function(request, response) {
console.log("Received request from " + request.connection.remoteAddress);
if (++requestCount >= 5) {
response.writeHead(500);
response.end("Some internal error has occurred! This is pod " + os.hostname() + "
");
return;
}
response.writeHead(200);
response.end("This is v3 running in pod " + os.hostname() + "
");
};
var www = http.createServer(handler);
www.listen(8080);
部署v3版本的应用
通过如下命令进行部署:
$ kubectl set image deployment kubia nodejs=luksa/kubia:v3
deployment.apps/kubia image updated
使用kubectl rollout status来跟踪部署过程:
$ kubectl rollout status deployment kubia
Waiting for deployment "kubia" rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for deployment "kubia" rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for deployment "kubia" rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for deployment "kubia" rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for deployment "kubia" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "kubia" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "kubia" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "kubia" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "kubia" rollout to finish: 1 old replicas are pending termination...
Waiting for deployment "kubia" rollout to finish: 1 old replicas are pending termination...
Waiting for deployment "kubia" rollout to finish: 1 old replicas are pending termination...
deployment "kubia" successfully rolled ou
新版本现在已经生效。正所示,在进行了几次请求之后,Web客户端开始收到错误。
$ while true; do curl http:/33.33.33.108:30021; sleep 2; done
This is v3 running in pod kubia-7bddb8bfc7-htng9
This is v3 running in pod kubia-7bddb8bfc7-djvkm
This is v3 running in pod kubia-7bddb8bfc7-htng9
This is v3 running in pod kubia-7bddb8bfc7-djvkm
This is v3 running in pod kubia-7bddb8bfc7-djvkm
This is v3 running in pod kubia-7bddb8bfc7-htng9
This is v3 running in pod kubia-7bddb8bfc7-htng9
This is v3 running in pod kubia-7bddb8bfc7-djvkm
This is v3 running in pod kubia-7bddb8bfc7-4x9zn
This is v3 running in pod kubia-7bddb8bfc7-4x9zn
This is v3 running in pod kubia-7bddb8bfc7-4x9zn
Some internal error has occurred! This is pod kubia-7bddb8bfc7-htng9
Some internal error has occurred! This is pod kubia-7bddb8bfc7-djvkm
Some internal error has occurred! This is pod kubia-7bddb8bfc7-djvkm
撤销一个部署
当应用程序出现了问题,我们可以撤销该错误版本的部署:
$ kubectl rollout undo deployment kubia
deployment.apps/kubia rolled back
这会将Deployment回滚到上一个版本。
展示一个部署的发布历史
可以使用 kubectl rollout history 命令来显示发布历史记录。
$ kubectl rollout history deployment kubia
deployment.apps/kubia
REVISION CHANGE-CAUSE
1 kubectl create --filename=kubia-deployment-v1.yaml --record=true
3 kubectl create --filename=kubia-deployment-v1.yaml --record=true
4 kubectl create --filename=kubia-deployment-v1.yaml --record=true
还记得在创建部署时使用的 --record 命令行选项吗?如果没有它,历史记录中的 CHANGE-CAUSE 列将为空,这会使得更难确定每个版本的背后是什么。
回滚到特定版本的Deployment
可以通过在撤销命令中指定修订版本来回滚到特定的修订版本。例如,如果你想回滚到第一个版本,可以执行以下命令:
$ kubectl rollout undo deployment kubia --to-revision=1
由部署创建的所有 ReplicaSet 都代表了完整的修订历史记录,如图 9.11 所示。每个 ReplicaSet 存储了该特定修订版本的部署的完整信息,因此不应手动删除它。如果你这样做,将会从部署的历史记录中丢失该特定修订版本,无法回滚到该版本。
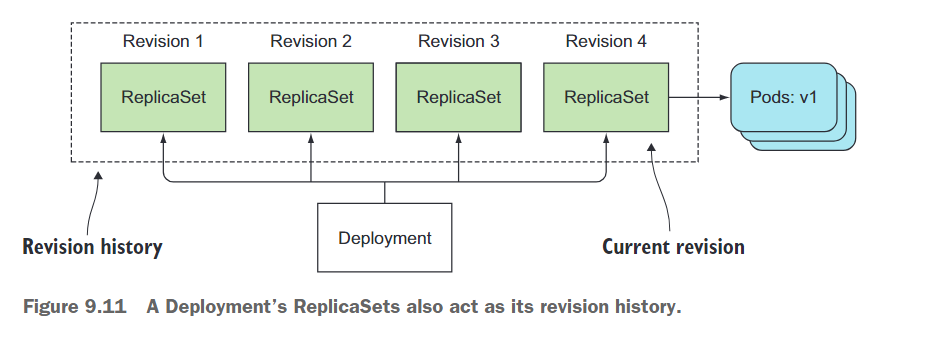
但是,保留过多的旧 ReplicaSet 在 ReplicaSet 列表中并不理想,因此修订历史记录的长度受部署资源上的 revisionHistoryLimit 属性限制。默认情况下,它为 10。
9.3.4 Controlling the rate of the rollout
引入滚动更新策略的 maxSurge 和 maxUnavailable 属性
有两个属性可以影响在部署的滚动更新过程中一次替换多少个 pod。它们是 maxSurge 和 maxUnavailable,可以作为部署策略属性的 rollingUpdate 子属性的一部分进行设置,如下所示的示例中所示。
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
- maxSurge: maxSurge属性确定你允许的超过部署中配置的期望副本数的 pod 实例数量。它的默认值为25%,因此最多可以有比期望数量多25%的pod实例。如果期望的副本数设置为4,那么在更新期间同时运行的pod实例数量将不会超过5个。将百分比转换为绝对数字时,数字向上取整。除了百分比,该值还可以是绝对值(例如,允许一个或两个额外的pod实例)。
- maxUnavailable: maxUnavailable属性确定在更新期间允许不可用的pod实例数量相对于期望的副本数。它的默认值也是25%,因此可用的pod实例数量不得低于期望副本数的75%。在这里,将百分比转换为绝对数字时,数字向下取整。如果期望的副本数设置为4,百分比为25%,则只能有一个pod不可用。在整个滚动更新过程中,始终至少有3个可用的pod实例来处理请求。与maxSurge一样,你还可以指定绝对值而不是百分比。
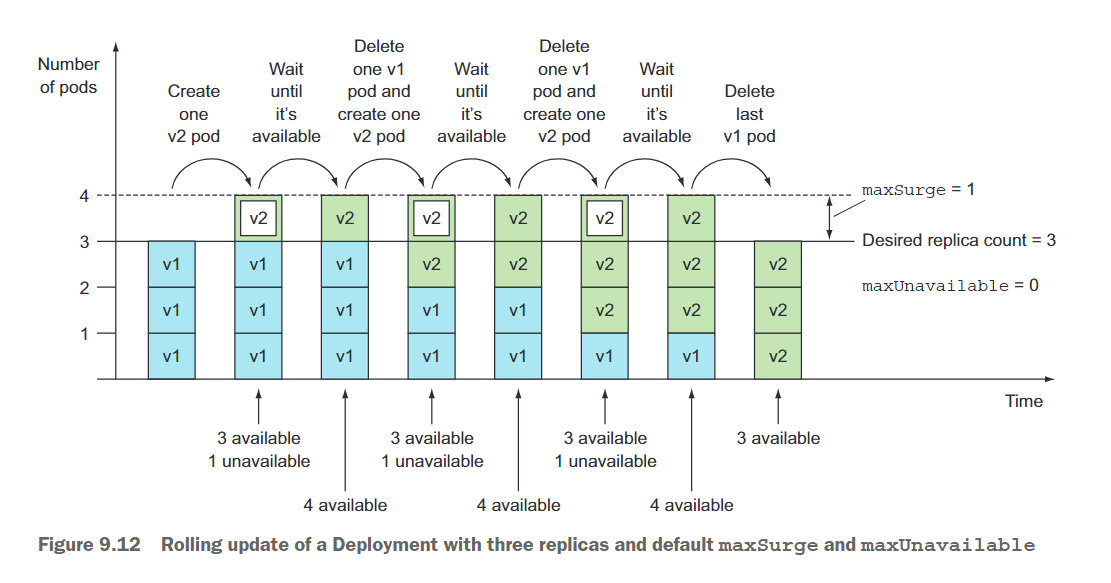
由于期望副本数是三,并且这两个属性的默认值都为25%,maxSurge允许所有pod的数量达到四个,而maxUnavailable禁止出现任何不可用的pod(换句话说,始终必须有三个可用的pod)。如上图所示。
9.3.5 Pausing the rollout process
暂停部署
在你修复了应用程序版本3的问题后,想象一下你现在已经修复了bug并推送了应用程序版本4的镜像。你对像之前一样将其在所有pod上部署有些担心。你希望在现有的v2 pod旁边运行一个单独的v4 pod,并观察它在只有一小部分用户使用时的表现。然后,一旦你确定一切正常,你可以将所有旧的pod替换为新的pod。
你可以通过直接运行一个额外的pod,或者通过额外的Deployment、ReplicationController或ReplicaSet来实现这一点,但你在Deployment本身上还有另一个可用的选项。在部署过程中,Deployment也可以暂停。这允许你在继续进行剩余的部署之前验证新版本是否正常。
$ kubectl set image deployment kubia nodejs=luksa/kubia:v4
deployment.apps/kubia image updated
$ kubectl rollout pause deployment kubia
deployment.apps/kubia paused
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
kubia-555774bf68-2w9lr 1/1 Running 0 21s
kubia-bcf9bb974-44slv 1/1 Running 0 26m
kubia-bcf9bb974-4blzq 1/1 Running 0 26m
kubia-bcf9bb974-dgvxv 1/1 Running 0 26m
创建了一个新的Pod,但原始的Pod也应该仍在运行。一旦新的Pod启动起来,部分请求将被重定向到新的Pod。这样,你实际上进行了金丝雀发布(canary release)。金丝雀发布是一种减少部署错误版本对所有用户影响风险的技术。与将新版本应用于所有用户不同,你只替换了一到少数几个旧的Pod,用新的Pod来代替。这样只有少数用户会最初使用新版本。然后你可以验证新版本是否正常工作,然后继续在所有剩余的Pod上部署新版本,或者回滚到先前的版本。
恢复部署进程
通过暂停部署过程,只有一小部分客户请求将命中v4 Pod,而大多数请求仍将命中v3 Pod。一旦确信新版本的工作正常,可以恢复部署,用新的Pod替换所有旧的Pod:
$ kubectl rollout resume deployment kubia
deployment "kubia" resumed
显然,必须在部署过程的确切点上暂停部署并不是你想做的事情。将来,可能会有一种新的升级策略可以自动执行这个操作,但目前,执行金丝雀发布的正确方式是使用两个不同的部署,并适当进行扩缩容。
9.3.6 Blocking rollouts of bad versions
在本章结束之前,我们还需要讨论 Deployment 资源的另一个属性。还记得你在9.3.2节开始时设置的 minReadySeconds 属性吗?你使用它来减慢部署过程,以便你能够看到它确实执行了滚动更新,而不是立即替换所有的Pod。minReadySeconds 的主要功能是防止部署出现故障的版本,而不是为了减慢部署过程而设置。
理解 minReadySeconds 的适用性
minReadySeconds 属性指定了一个新创建的Pod在被视为可用之前应该准备就绪的时间。在Pod可用之前,部署过程将不会继续进行。当一个Pod的所有容器的就绪探针返回成功时,该Pod被视为准备就绪。如果一个新的Pod在 minReadySeconds 过去之前出现功能问题,并且它的就绪探针开始失败,那么新版本的部署将被有效地阻塞。
你使用了这个属性来减慢部署过程,让 Kubernetes 在一个Pod准备就绪后等待10秒,然后才继续部署。通常情况下,你会将 minReadySeconds 设置得更高,以确保Pod在开始接收实际流量后仍然报告其准备就绪状态。
虽然在将Pod部署到生产环境之前,显然应该在测试和预发布环境中对其进行测试,但使用 minReadySeconds 就像是一个安全气囊,可以挽救应用程序遭受重大破坏。
定义一个就绪探针
将再次部署v3版本,但这次你将在Pod上定义适当的就绪探针。
与之前不同,你现在不仅在Pod模板中更新镜像,还将同时引入容器的就绪探针。为了一次性更改镜像并引入就绪探针,你将使用kubectl apply命令。你将使用以下YAML文件来更新Deployment(将其存储为kubia-deployment-v3-with-readinesscheck.yaml),如下所示:
# kubia-deployment-v3-withreadinesscheck.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
minReadySeconds: 10
strategy:
rollingUpdate:
maxSurge: 1
# 使pod一个个地替换
maxUnavailable: 0
type: RollingUpdate
template:
metadata:
name: kubia
labels:
app: kubia
spec:
containers:
- image: luksa/kubia:v3
name: nodejs
readinessProbe:
periodSeconds: 1
httpGet:
path: /
port: 8080
kubectl apply和kubectl create是 Kubernetes 命令行工具中用于创建和修改资源的两个命令。
kubectl create用于创建新的 Kubernetes 资源。它需要指定资源类型和名称,并提供资源的配置信息。如果资源已经存在,则kubectl create命令将失败。kubectl apply用于创建或更新 Kubernetes 资源。它可以接受完整的资源配置文件,并根据文件中的定义来创建或更新资源。如果资源不存在,则会创建新资源。如果资源已经存在,则kubectl apply命令会根据配置文件中的定义更新资源的属性。它会比较现有资源和配置文件中的定义,并只应用有变化的部分。因此,
kubectl apply比kubectl create更适用于资源的创建和更新操作,因为它具有更灵活的行为,可以部分更新资源,并保留已存在的资源的其他属性和配置。
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
kubia-555774bf68-2w9lr 1/1 Running 0 19m
kubia-555774bf68-n4vwn 1/1 Running 0 16m
kubia-555774bf68-wfpsj 1/1 Running 0 16m
kubia-67d49c55dd-wn4fc 0/1 Running 0 69s
可以发现Pod并没有准备好,这是为什么呢?
了解就读取探针如何防止错误版本的部署
一旦新的 Pod 启动,就会开始每秒发送一次就读取探针(在 Pod 规范中将探针的间隔设置为一秒)。在第五个请求时,就读取探针开始失败,因为你的应用从第五个请求开始返回 HTTP 状态码 500。
结果,该 Pod 从服务中被移除(参见图 9.14)。当你在 curl 循环中开始访问服务时,该 Pod 已被标记为不可用。这解释了为什么你从未访问到新的 Pod。这正是你所期望的,因为你不希望客户端访问一个无法正常运行的 Pod。
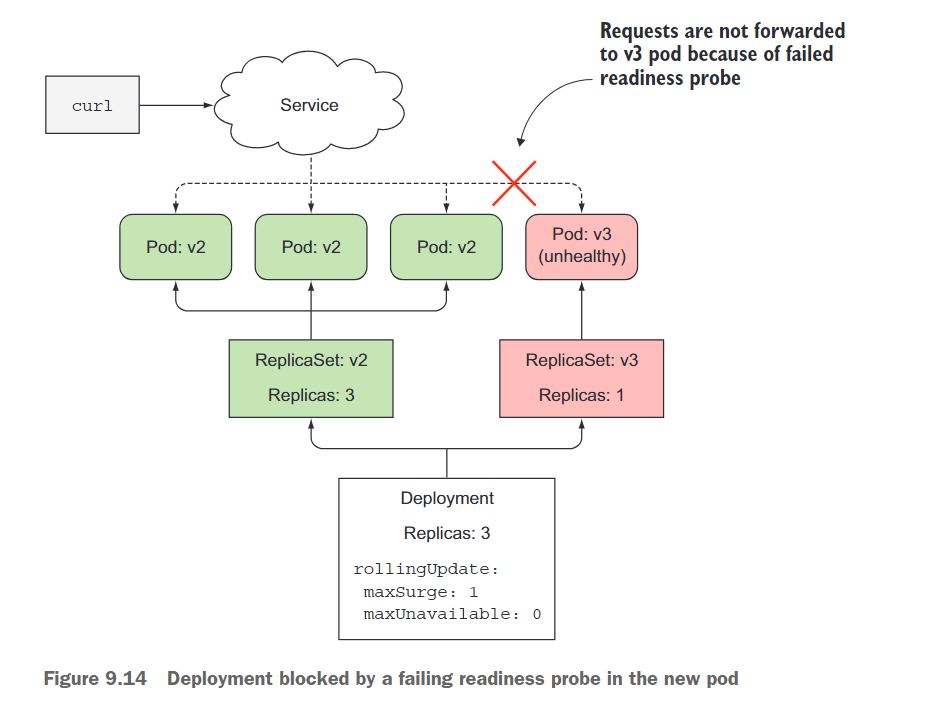
那么部署过程又如何呢?部署状态命令只显示一个新的副本已经启动。值得庆幸的是,部署过程不会继续,因为新的 Pod 永远不会变为可用状态。要被视为可用,它需要至少准备好 10 秒钟。在它变为可用之前,部署过程不会创建任何新的 Pod,也不会删除任何原始 Pod,因为你将 maxUnavailable 属性设置为 0。
部署过程被阻塞的事实是一个好事,因为如果它继续用新的 Pod 替换旧的 Pod,你最终会得到一个完全无法工作的服务,就像你第一次部署版本 3 时那样,当时你没有使用就读取探针。但是现在,有了就读取探针,对用户几乎没有负面影响。一些用户可能会遇到内部服务器错误,但这不像将所有 Pod 替换为有问题的版本 3 那样严重的问题。
如果只定义了就读取探针而没有正确设置 minReadySeconds,当第一次就读取探针成功后,新的 Pod 就会立即被视为可用。如果就读取探针在之后不久开始失败,有问题的版本将在所有 Pod 上进行部署。因此,你应该适当设置 minReadySeconds。
配置部署的最后期限
默认情况下,如果在10分钟内部署无法取得任何进展,它将被视为失败。如果使用kubectl describe deployment命令,你会看到它显示一个ProgressDeadlineExceeded条件,如下面的列表所示。
$ kubectl describe deployment kubia
Name: kubia
...
Conditions:
Type Status Reason
---- ------ ------
Progressing False ProgressDeadlineExceeded
Available True MinimumReplicasAvailable
...
部署被视为失败的时间可以通过部署规范中的progressDeadlineSeconds属性进行配置。
由于部署失败了,最后需要进行回滚:
$ kubectl rollout undo deployment kubia





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结