您现在的位置是:首页 >技术杂谈 >Map、Set和哈希表的应用练习(数据结构系列15)网站首页技术杂谈
Map、Set和哈希表的应用练习(数据结构系列15)
目录
前言:
在上一节博客中小编给大家介绍了Map、Set和哈希表的一些简单的知识点,同时也给大家简单的演示了一下如何使用他们里面的一些基础方法,那么接下来让小编带着你们一起来将这些知识点运用起来吧!
练习题:
1.有10个数据,并且数据有重复的,要求我们对里面的数据进行去重操作。
思路分析:
我们要想达到去重的效果的话,那么我们先来回忆一下小编上节中给大家所讲的Map和Set两种,哪一种更适合去重呢?答案是Set,在Set中我们就只存储key值,且在Set中是不可以重复存储key值的,所以使用Set就可以很好的达到我们想要的效果。接下来我们就使用代码来实现一下吧。
代码展示:
package Map_Set和Hash练习题;
//有10个数据,并且数据有重复的,要求我们对里面的数据进行去重操作
import java.util.HashSet;
import java.util.Set;
public class Test1 {
public static void main(String[] args) {
Set<Integer> set = new HashSet<>();
//对下面的一组数据进行去重
int[] array = {1,1,2,3,2,4,5,5,6,6};
for (int i = 0; i < array.length; i++) {
set.add(array[i]);
}
System.out.println(set);
}
}
结果展示: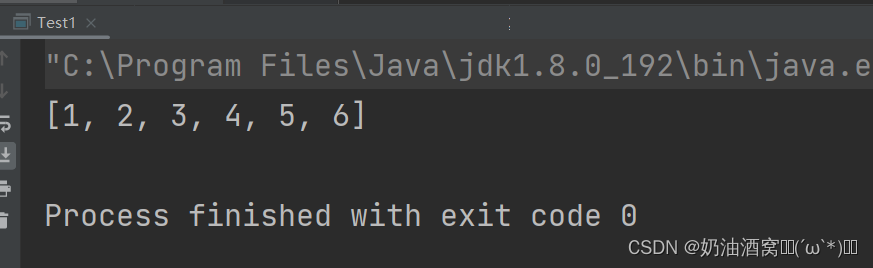
2.有10个数据,并且数据有重复的,找到第一个重复的数据。
思路分析:
与上述的情况差不多,只不过需要我们在放入set中的时候进行判断一下这个元素是不是在set里面已经存在了,如果存在那么就直接输出,结束循环,如果不存在那么就将其放入到set中。你可以将set想象成一个麻袋,你要往麻袋里面存放这些数据,当你在放的时候要查看一下麻袋中是不是存在这个值,如果存在的话就不放了,如果不存在的话就放入其中。
代码展示:
package Map_Set和Hash练习题;
import java.util.HashSet;
import java.util.Set;
//有10个数据,并且数据有重复的,找到第一个重复的数据
public class Test2 {
public static void main(String[] args) {
Set<Integer> set = new HashSet<>();
int[] array = {1,2,2,3,4,5,6,8,4};
for (int x: array) {
if (!set.contains(x)) {
set.add(x);
}else {
System.out.println(x);
break;
}
}
}
}
结果展示:
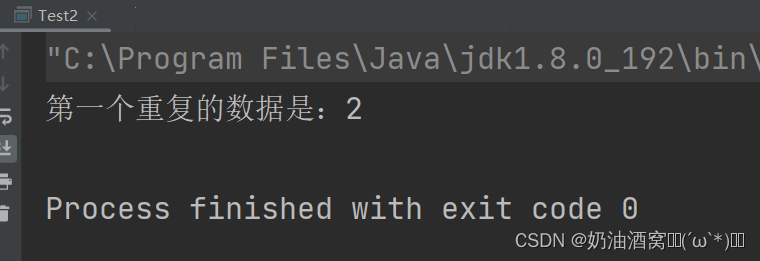
3.统计10W个数据当中重复出现数据[val >= 2]出现的次数。
思路分析:
对于上述情况我们既要存储数据,又要统计数据出现的次数,此时就是一个k-v模型,我使用Map就可以达到我们想要的效果了,我先将数据都存储到map中去,然后再对map里面的键值对进行遍历,如果发现有val>=2的就将其输出并记录次数即可。
代码展示:
package Map_Set和Hash练习题;
import java.util.HashMap;
import java.util.Map;
//统计10W个数据当中重复出现数据[val >= 2]出现的次数
public class Test3 {
public static void main(String[] args) {
Map<Integer, Integer> map = new HashMap<>();
//这里我们就先用十个数据进行模拟一下10W个数据
int[] array = {1,2,2,3,4,5,6,7,8,4};
//先将数据都放入到map中
for (int x : array) {
if (map.get(x) == null) {
map.put(x,1);
}else {
map.put(x, map.get(x) + 1);
}
}
//在进行遍历里面的键值对,查看里面的value值>=2的,统计并输出
int count = 0;
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {
if (entry.getValue() >= 2) {
count++;
System.out.println("key: " + entry.getKey() + " val: " + entry.getValue());
}
}
System.out.println("val >= 2的有:" + count + "个");
}
}
结果展示:

4.只出现一次的数字
题目描述如下所示:
给你一个 非空 整数数组
nums,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
思路分析:
这里我们使用Set来进行做题,同样将set想象成一个麻袋,如果里面没有相同的则放入,如果存在的话就将里面的那个取出来,最后剩下的就是我们要找的数字。
代码展示:
package Map_Set和Hash练习题;
import java.util.HashSet;
import java.util.Set;
//只出现一次的数字
public class Test4 {
public static int singleNumber(int[] nums) {
Set<Integer> set = new HashSet<>();
for (int x : nums) {
if (!set.contains(x)) {
set.add(x);
}else {
set.remove(x);
}
}
for (int x : nums) {
if (set.contains(x)) {
return x;
}
}
return 0;
}
public static void main(String[] args) {
int[] array = {1,1,2,2,3,5,5,6,6,8,8};
int ret = singleNumber(array);
System.out.println("其中" + ret + "只出现了一次!");
}
}
结果展示:
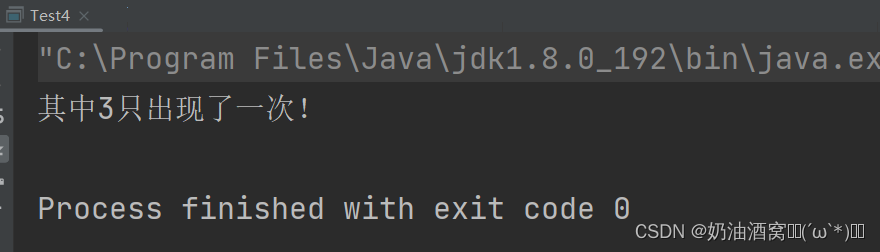
5.复制随机带指针的链表值
题目描述如下所示:
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。
random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。
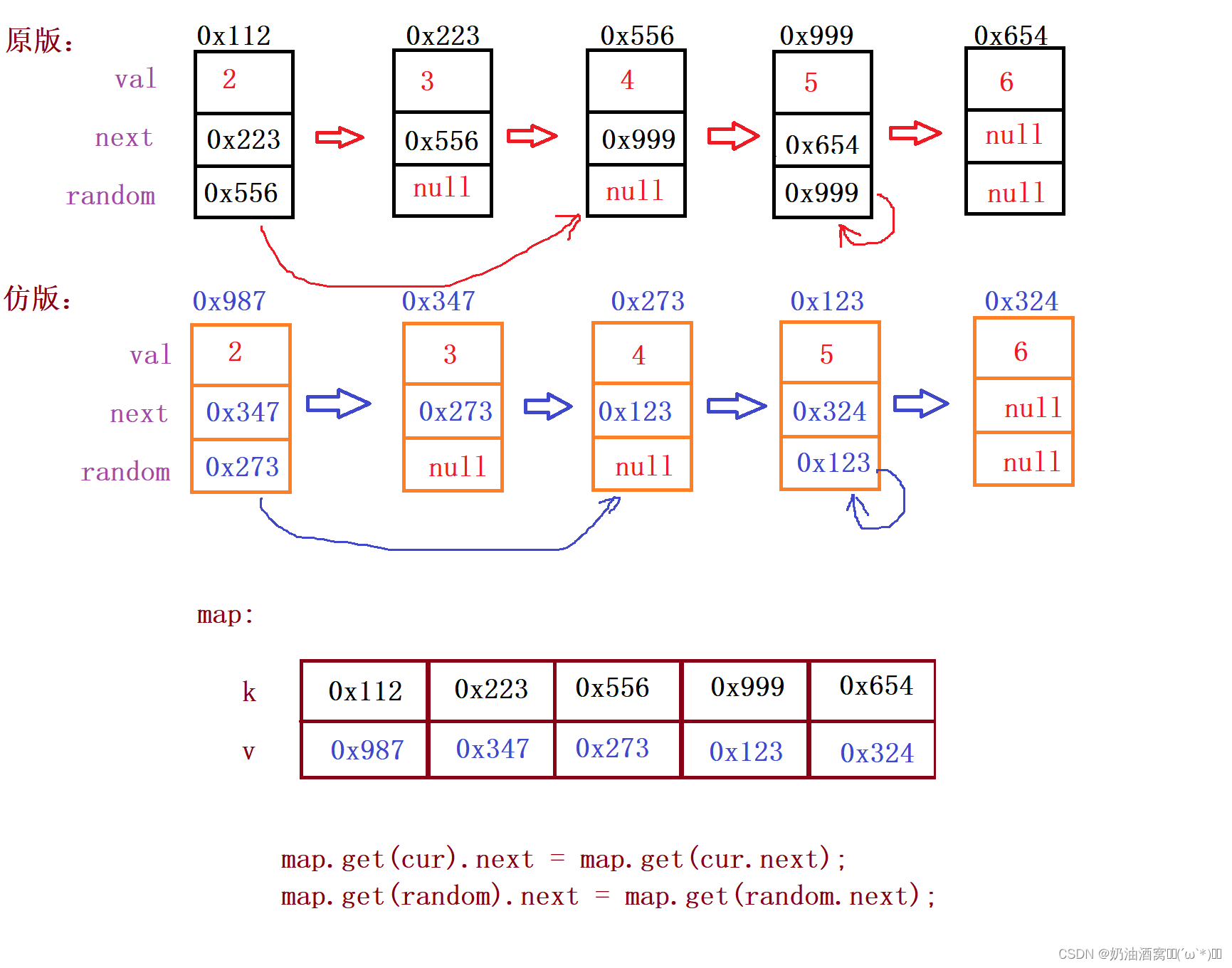
思路分析:
代码展示:
package Map_Set和Hash练习题;
import java.util.HashMap;
import java.util.Map;
//定义一个结点
class Node {
int val;
Node next;
Node random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
//复制随机带指针的链表值
public class Test5 {
public Node copyRandomList(Node head) {
Map<Node, Node> map = new HashMap<>();
Node cur = head;
//遍历原有的链表的地址,将原有地址与要拷贝的地址关联在一起。
while (cur != null) {
Node node = new Node(cur.val);
map.put(cur,node);
cur = cur.next;
}
//仿照这原有地址的关联方式对新链表进行关联
cur = head;
while (cur != null) {
map.get(cur).next = map.get(cur.next);
map.get(cur).random = map.get(cur.random);
cur = cur.next;
}
//返回新链表的头结点
return map.get(head);
}
public static void main(String[] args) {
//由于小编这里只是简单的实现了一下函数,对链表没有具体的实现,大家可以自己实现一下,进行测试
}
}
6.宝石与石头
题目描述如下所示:
给你一个字符串 jewels 代表石头中宝石的类型,另有一个字符串 stones 代表你拥有的石头。 stones 中每个字符代表了一种你拥有的石头的类型,你想知道你拥有的石头中有多少是宝石。
字母区分大小写,因此 "a" 和 "A" 是不同类型的石头。
思路分析:
首先我们先将宝石中的字母存放到set中去,然后我们在对石头进行遍历,如果发现在set中存在就将计数器加加一下,最终我们就可以统计出石头中宝石的个数了。
代码展示:
package Map_Set和Hash练习题;
import java.util.HashSet;
import java.util.Set;
//宝石与石头
public class Test6 {
public static int numJewelsInStones(String jewels, String stones) {
Set<Character> set = new HashSet<>();
//计数器
int count = 0;
//1.遍历宝石将宝石的字母都放入到set中
for (int i = 0; i < jewels.length(); i++) {
char ch = jewels.charAt(i);
set.add(ch);
}
//2.遍历石头看set中是否存在
for (int i = 0; i < stones.length(); i++) {
char ch = stones.charAt(i);
if (set.contains(ch)) {
count++;
}
}
return count;
}
public static void main(String[] args) {
String jewels = "aA";
String stones = "aAAbbbb";
int ret = numJewelsInStones(jewels, stones);
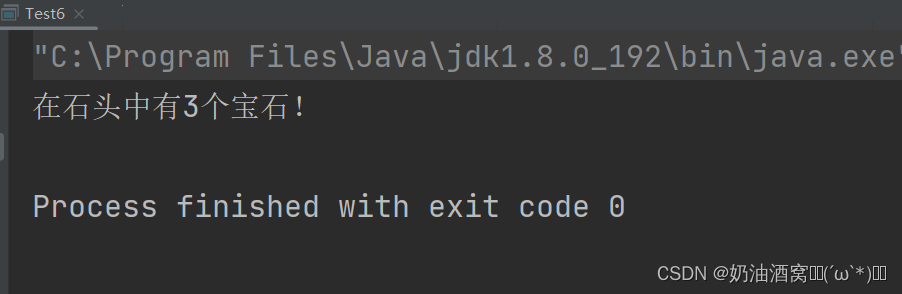
System.out.println("在石头中有" + ret + "个宝石!");
}
}
结果展示:
7.坏键盘打字
题目描述如下所示:
旧键盘上坏了几个键,于是在敲一段文字的时候,对应的字符就不会出现。现在给出应该输入的一段文字、以及实际被输入的文字,请你列出肯定坏掉的那些键。
思路分析:
我们先将输入的字符串都以大写的方式放入到set中去,然后在将输出的字符串以大写的方式放入的新建的setBroken中去,然后在看两个中是否都包含了输入的字符,如果没有则输出。
代码展示:
package Map_Set和Hash练习题;
import java.util.HashSet;
import java.util.Scanner;
import java.util.Set;
//坏键盘打字
public class Test7 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
while (scanner.hasNextLine()) {
String str1 = scanner.nextLine();
String str2 = scanner.nextLine();
error_BordKey(str1, str2);
}
}
private static void error_BordKey(String str1, String str2) {
Set<Character> set = new HashSet<>();
//将输入的都放入到set中
for (char ch : str2.toUpperCase().toCharArray()) {
set.add(ch);
}
//将输出的在存放到另一个set中,然后判断两个中是否都包含ch如果都不包含那就说明是坏键。
Set<Character> setBroken = new HashSet<>();
for (char ch : str1.toUpperCase().toCharArray()) {
if (!set.contains(ch) && !setBroken.contains(ch)) {
setBroken.add(ch);
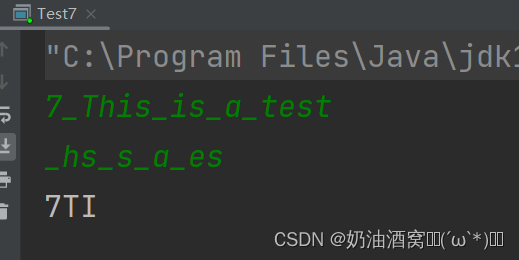
System.out.print(ch);
}
}
}
}
结果展示:
8.前K个高频单词
题目描述:
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
思路分析:
既然这里涉及到了统计单词的频率,那么我们就使用Map来将其统计出来和我们上面用到的方法一样,第二步我们在创建出一个小根堆,第三步我们将Map中的数据依次存放到小根堆中,注意当小于K的时候我们就直接存放进去即可,当大于K的时候我们就要与堆顶元素进行比较了,首先我们先来比较频率,如果频率不同则将大频率的放入小根堆中即可,但是如果频率相同则我们就需要进行比较单词首字母了,这里我们是按照字典序进行排序的,操作完成之后,此时小根堆里存放的就是我们需要的数据了,但是按照题目的要求是要按单词出现频率由高到低排序,所以我们要将数据先存放到一个线性表中,然后再进行反转输出即可。
代码展示:
package Map_Set和Hash练习题;
import java.util.*;
//前K个高频单词
public class Test8 {
public static List<String> topKFrequent(String[] words, int k) {
//1.遍历数组 统计每个单词出现的频率
Map<String, Integer> hashMap = new HashMap<>();
for (String str: words) {
if (hashMap.get(str) == null) {
hashMap.put(str, 1);
}else {
hashMap.put(str, hashMap.get(str) + 1);
}
}
//2.建立小根堆
PriorityQueue<Map.Entry<String, Integer>> minHeap = new PriorityQueue<>(
k, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
if (o1.getValue().compareTo(o2.getValue()) == 0) {
return o2.getKey().compareTo(o1.getKey());
}
return o1.getValue().compareTo(o2.getValue());
}
}
);
//3.遍历hashMap把里面的数据放到小根堆里面
for (Map.Entry<String, Integer> entry : hashMap.entrySet()) {
if (minHeap.size() < k) {
minHeap.offer(entry);
}else {
//小根堆放满了k个,下一个entry和堆顶元素比较
Map.Entry<String, Integer> top = minHeap.peek();
//堆顶的频率小于当前entry的频率就出队,然后入队entry
if (top.getValue().compareTo(entry.getValue()) < 0) {
minHeap.poll();
minHeap.add(entry);
}else {
//频率相同的情况
if (top.getValue().compareTo(entry.getValue()) == 0) {
if (top.getKey().compareTo(entry.getKey()) > 0) {
minHeap.poll();
minHeap.add(entry);
}
}
}
}
}
//4.此时小根堆当中已经有了结果
List<String> ret = new ArrayList<>();
for (int i = 0; i < k; i++) {
String key = minHeap.poll().getKey();
ret.add(key);
}
Collections.reverse(ret);
return ret;
}
public static void main(String[] args) {
String[] words = {"i", "love", "leetcode", "i", "love", "coding"};
int k = 2;
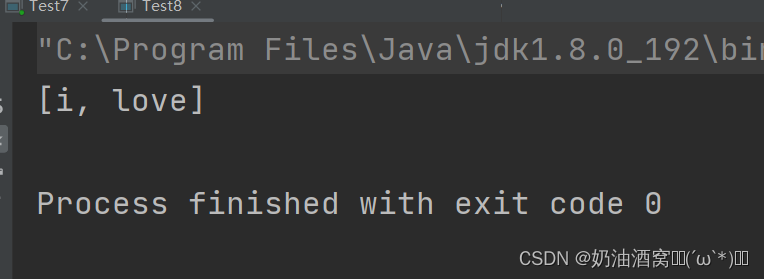
System.out.println(topKFrequent(words, k));
}
}
结果展示:
结束语:
好啦这节博客的内容小编就分享到这里啦!这节中小编主要是针对上一节博客的知识点和大家一起来练习了几道习题与大家一起实战演习一下,希望这节中大家能对上一节小编所讲的Map、Set和哈希表有更深刻的了解,大家继续跟紧小编的步伐,一起往前冲!!!想要学习的同学记得关注小编和小编一起学习吧!如果文章中有任何错误也欢迎各位大佬及时为小编指点迷津(在此小编先谢过各位大佬啦!)






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结