您现在的位置是:首页 >技术杂谈 >分享几个索引创建的小 Tips网站首页技术杂谈
分享几个索引创建的小 Tips
关于 MySQL 中的索引,松哥前面已经和小伙伴们聊了不少了,不过在索引使用的时候,还是有一些需要注意的细节,如果忽略了这些细节,可能会让索引的使用效果大打折扣。
1. 冗余索引
注意我这里使用了冗余索引,没有使用重复索引,因为我觉得在小伙伴们使用索引的过程中,创建重复索引的概率应该还是比较小,同一个字段上创建多个一模一样的索引,应该很少有人会犯这种错误。但是,会有一些容易被大家忽略的冗余索引,我们来捋一捋。
1.1 联合索引左边列
例如我创建了一个联合索引 (A,B,C),按照我们之前跟大家讲的最左匹配原则,当我们使用 A、(A、B)或者 (A、B、C)去查询数据的时候,都会用到这个联合索引,所以我们就没有必要再去单独针对 A 字段创建一个索引,或者针对 A、B 字段创建一个联合索引。
1.2 索引中加入主键
假设我有一张表,该表有如下字段 (ID、A、B、C),其中 ID 是主键,现在又针对 A 和 ID 两个字段创建了联合索引(A、ID)。
根据松哥前面的介绍,小伙伴们知道,在二级索引中,叶子结点上存储的数据就是 ID,所以,这个联合索引中的 ID 字段显然是多余的。
大部分情况下我们都不需要冗余索引,但是也有一些特殊情况可能让我们不得不创建一些冗余索引,这个小伙伴们还是要具体问题具体分析。
另外需要注意一点,针对相同的字段,如果索引类型不同,则不能算是重复索引,例如一个普通索引和一个全文索引,同一个字段上同时有这两个索引,不算重复索引。
2. 隐藏的索引排序
上篇文章松哥刚刚和大家聊了索引排序的问题。
结合上篇文章的内容,小伙伴们思考这样一个问题:假设我有一张表,表中包含如下字段(ID、A、B),其中 ID 是主键,现在我针对 A 字段建立一个索引,如果我有如下查询 SQL:
select ... from table where A=xxx order by ID
由于在 A 这个二级索引中就包含了 ID 字段,所以上面这个查询是可以使用到索引排序的。此时,如果由于其他需求,我们将 A 这个索引扩展成联合索引(A、B)了,那么很明显,再执行上面的查询的时候就用不了索引排序了,只能 filesort 了。这样的问题小伙伴们在创建或者修改索引的时候很容易忽略,所以一定要仔细。
3. 删除不使用的索引
有的索引可能是由于过度考虑创建了,创建成功之后就没用过,这样的索引也应该删除掉。
小伙伴们知道,索引虽然可以提高查询速度,但是却会降低插入和修改速度。
在 MySQL 的元数据库 sys 中有一个名为 schema_unused_indexes 的视图,该视图中就保存了各种创建了但是未使用的索引:
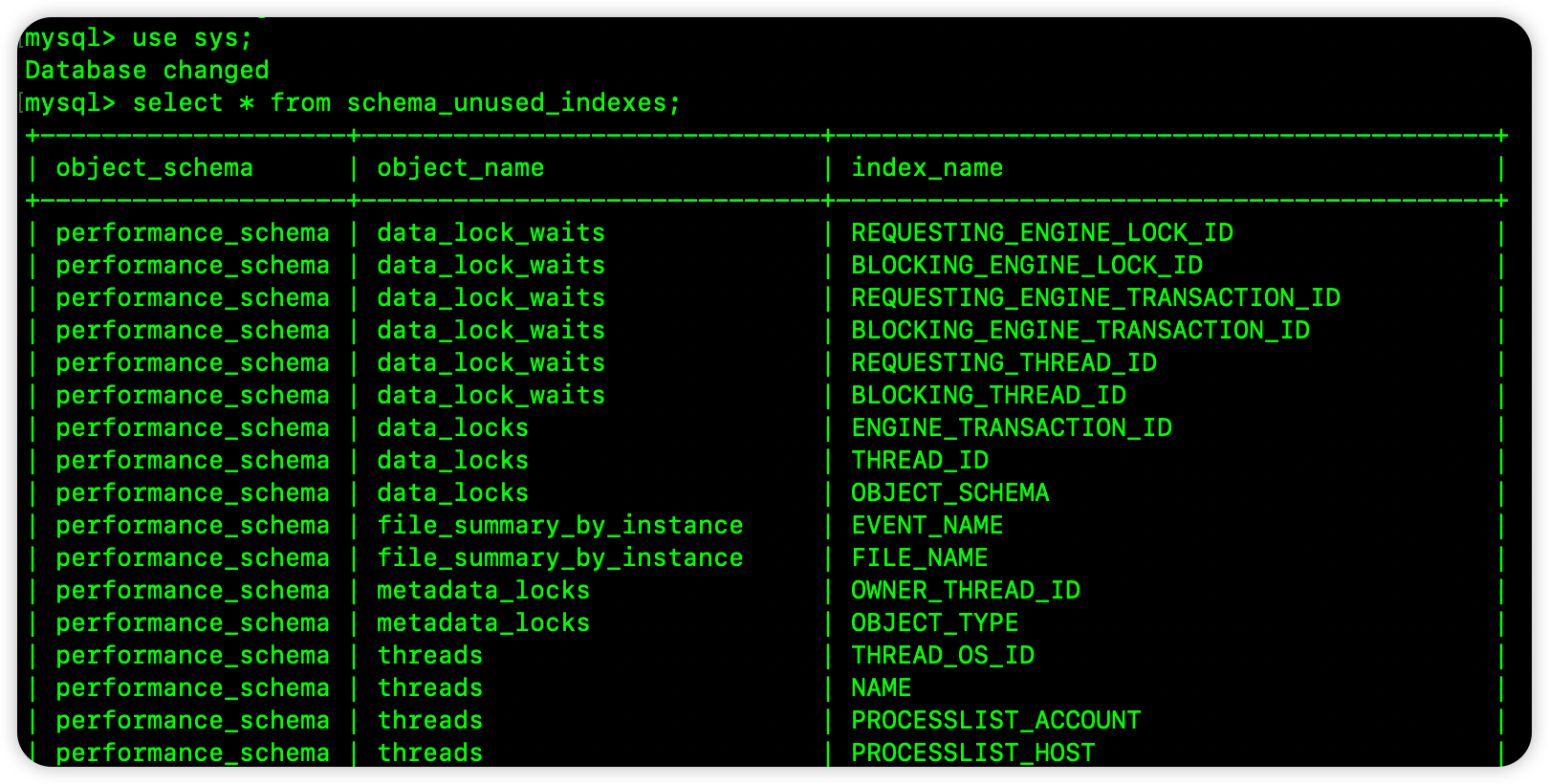
4. 手动更新索引统计信息
当我们想要查看一条 SQL 的执行计划时,这个执行计划中会展示出来这个 SQL 执行过程中大概会扫描多少行数据,如下:

这个预估的扫描行数非常重要,这是 MySQL 优化器在执行 SQL 的时候一个重要的参考指标,如果表没有这个统计信息,或者统计信息不准确,那么就有可能导致优化器做出错误的决定。
当满足如下条件的时候,这个统计信息会自动生成或者更新:
- 首次打开表。
- 表大小发生变化。
- 执行 SHOW TABLE STATUS
- 执行 SHOW INDEX
- MySQL 客户端开启自动补全功能
- 打开 infomation_schema 库中一些相关的表
这些行为都会触发统计信息的自动更新,如果表中数据量比较大,担心以上行为降低表的性能,那么也可以修改 innodb_stats_on_metadata 参数来关闭以上行为。
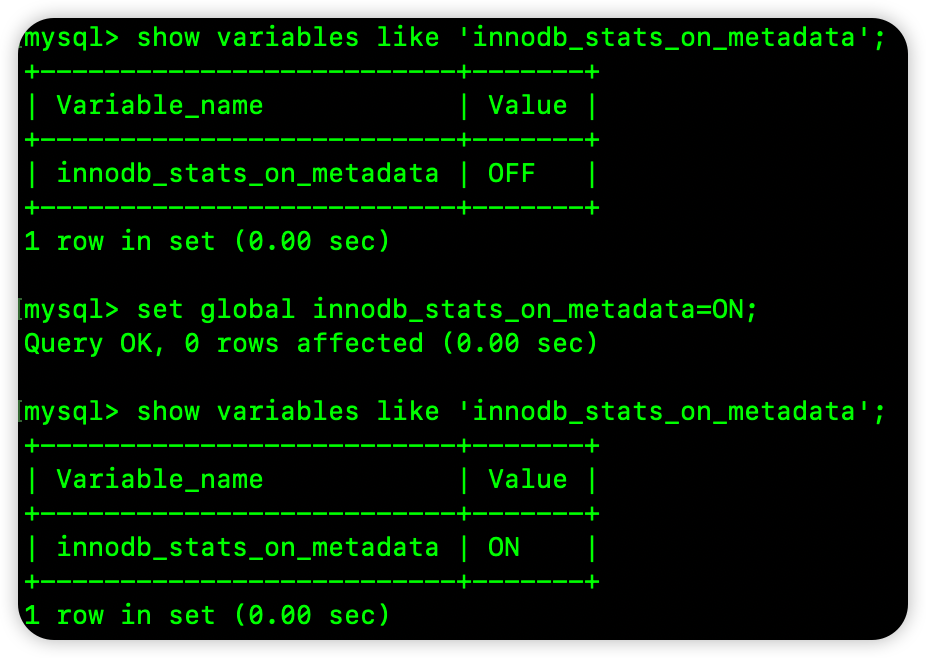
当然,我们也可以手动执行 analyze table 命令来更新索引的统计信息。
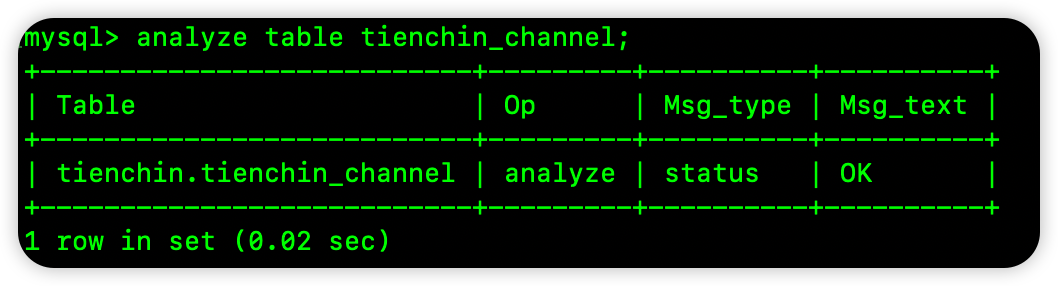
5. 适时优化表
InnoDB 中的索引是一个 B+Tree,这个我们在之前的文章中就和小伙伴们聊过了。B+Tree 通过一个多路平衡查找树将数据组织在一起,然而这个树中的各个结点在存储的时候在物理分布上却并不一定连续,如果是连续的,则在数据操作的时候就会快很多,如果不需连续,数据操作性能必然会有下降,一般来说,存在这样几种不同的碎片形式:
- 行碎片:数据行分布在不同的地方,读取数据行的时候涉及到多次随机 IO。
- 行间碎片:逻辑上应该是连续的行或者数据页,在磁盘上存储时并不连续。原本全表扫描的时候是顺序 IO,现在变成了随机 IO。
- 剩余空间碎片:小伙伴们知道,InnoDB 操作数据表最基本单位是页,一页是 16KB,也就是 InnoDB 从磁盘上读、往磁盘上写,最低单位都是 16KB,有时候这 16KB 中,有效数据很少,其他地方都是剩余空间,就会让 InnoDB 在读写数据的时候造成很大浪费。
对于以上情况,我们可以通过执行 optimize table 来重新整理数据,如果存储引擎不支持 optimize table 命令,那么我们也可以通过执行 alter table <table> engine=xxx 命令来实现数据的重整(命令中的 xxx 就是表原本的引擎)。

当然,optimize table 命令在执行的过程中还有一些细节问题,这个松哥后面再整文章和小伙伴们分享。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结