您现在的位置是:首页 >技术杂谈 >Hive和Hadoop关系网站首页技术杂谈
Hive和Hadoop关系
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以查询和分析存储在Hadoop中的大规模数据的机制。Hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。
关于Hive的描述可以归结为这么几点来理解:
- Hive是工具。
- Hive可以用来构建数据仓库。
- Hive具有类似SQL的操作语句HQL。
- Hive是用来开发SQL类型脚本,用于开发MapReduce操作的平台。
Hive最初由Facebook开源,用于解决海量结构化日志的数据统计分析,是建立在Hadoop集群的HDFS上的数据仓库基础框架,其本质是将类SQL语句转换为MapReduce任务运行。可以通过类SQL语句快速实现简单的MapReduce统计计算,十分适合数据仓库的统计分析。
所有Hive处理的数据都存储在HDFS中,Hive在加载数据过程中不会对数据进行任何修改,只是将数据移动或复制到HDFS中Hive设定的目录下。所以Hive不支持对数据的改写和添加,所有数据都是在加载时确定的。
因此,Hive总的说来具有以下特点:
(1)Hive是一个构建在Hadoop上的数据仓库框架。
(2)Hive设计的目的是让精通SQL技能、但Java编程技能相对较弱的数据分析师能够快速进行大数据分析项目开发与应用。
Hive的能力在于直接分析通过ETL清洗过后的半结构化数据,其步骤如图1-3所示。

图1-3 非结构化数据分析步骤
Hive 构建在 Hadoop 之上,二者关系示意图如图1-4所示。
它们关系解释如下:
- Hive对外提供CLI、Web Interface(Web接口)、JDBC、ODBC等访问接口,Hadoop提供后台存储和计算服务。
- HQL中对查询语句的解释、优化、生成查询计划是由Hive Diver完成的。
- 所有的数据都是存储在Hadoop的HDFS中。
- 查询计划被转化为 MapReduce 任务,在 Hadoop 中执行(但要注意有些查询也可能没有MapReduce 任务,如:select * from table)。
- Hadoop和Hive都是用UTF-8编码的。
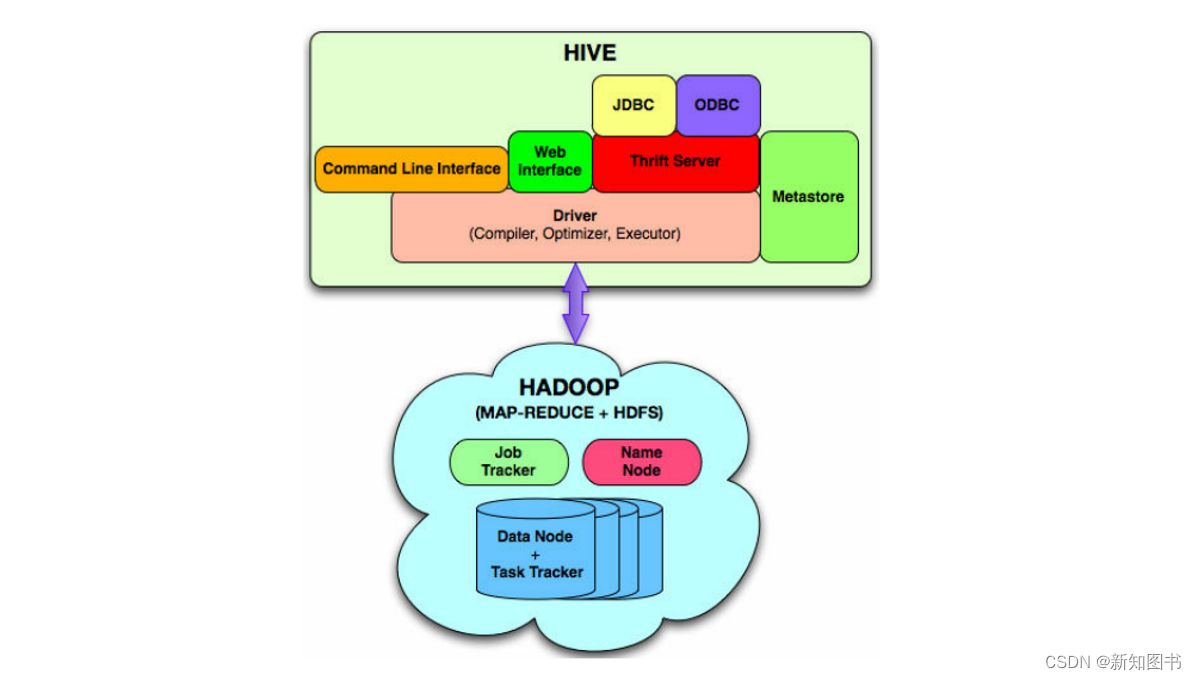
图1-4 Hive与Hadoop关系
总之,Hive是Hadoop的延申。Hive是一个提供了查询功能的数据仓库核心组件,Hadoop底层的HDFS为Hive提供了数据存储,MapReduce为Hive提供了分布式运算。HDFS上存储着海量的数据,我们要对这些数据进行计算和分析,则需要使用Java编写MapReduce(MR)程序来实现,但Java编程门槛较高,且一个MapReduce程序写起来要几十上百行。而Hive可以直接通过SQL操作Hadoop,SQL简单易写、可读性强,Hive将用户提交的SQL解析成MapReduce任务供Hadoop直接运行。Hive某种程度来说也不进行数据计算,只是个解释器,只负责将用户需要对数据处理的逻辑,通过SQL编程提交后解释成MapReduce程序,然后将这个MR程序提交给YARN进行调度执行。所以,实际进行分布式运算的是MapReduce程序。
本文节选自《Hive入门与大数据分析实战》,内容发布获得作者和出版社授权。







站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结