您现在的位置是:首页 >技术杂谈 >【C进阶】文件操作(下)(详解--适合初学者入门)网站首页技术杂谈
【C进阶】文件操作(下)(详解--适合初学者入门)
目录
在讲这一章之前我想补充一些知识:
补充的知识点:>
标准流
标准流有三种:关于流的知识上一章有设计到,可以去看一下。
stdin - 标准输入流(standard input stream)
用于读取普通输入的流,在大多数环境中从键盘中为从键盘输入。scanf与getchar等函数会从这个流中读取字符。
stdout - 标准输出流(standard output stream)
用于写入普通输出的流,在大多数环境中为输出至显示器界面,printf、puts与putchar等函数会向这个流写入字符。
stderr - 标准错误流(standard error stream)
用于写出错误的流。在大多数环境中为输出至显示器界面。
FILE型
表示标准流的stdin、stdout、stderr都是指向FILE型的指针型。FILE型要在头文件<stdio.h>中定义,该数据类型用于记录控制流所需要的信息,其中包括以下数据
文件位置指示符(file position indicator)
记录当前访问地址。
错误指示符(error indicator)
记录是否发生了读取错误或写入错误。
文件结束指示符(EOF indicator)
记录是否已到达文件末尾。
通过流进行的输入输出都是根据上述信息执行操作的。而且这些信息也会随着操作结果更新。FILE 型的具体实现方法因编译器而异,一般多以结构体的形式实现。
fopen(打开文件)
大家在使用纸质笔记本时通常都是先打开,然后再翻页阅读或在适当的地方书写。
程序中的文件处理过程也同样如此。首先打开文件并定位到文件开头,然后找到要读取或写入的目标位置进行读写操作,最后将文件关闭。
打开文件的操作称为打开(open)。函数库中的fopen函数用于打开文件。
注意:使用文件时,需要事先用fopen函数打开文件。
该函数需要两个参数。第1个参数是要打开的文件名,第2个参数是文件类型及打开模式。以下图为例,使用"r”模式打开文件"abc.txt"。
- 文件类型有两种,即文本文件和二进制文件。接下来会讲到。
fopen函数会为要打开的文件新建一个流,然后返回一个指向FILE型对象的指针,该FILE型对象中保存了控制这个流所需要的信息。
文件一旦打开后,就可以通过FILE *型指针对流进行操作。

- 和程序启动时便准备好的标准流不同,要打开文件时必须先在程序中定义FILE * 型的指针变量。然后将fopen函数返回的指针赋于该变量,就可以通过该指针变量对文件进行操作了。
变量可以任意命名,这里我们将它命名为fp。fp不是流的实体,而是指向流的指针,严格来讲应称之为“指针fp所指向的流”。
fclose(关闭文件)
当我们读完一本书时会将它合上,文件也同样如此。在文件使用结束后,就要断开文件与流的关联将流关闭。这个操作就称为关闭(close)文件。
以下是用于关闭文件的fclose函数说明。
| 头文件 | #include<stdio.h> |
| 原型 | int fclose(FILE *stream); |
| 说明 | 刷新stream所指向的流,然后关闭与该流相关联的文件。流中留在缓冲区里面尚未写入的数据会被传递到宿主环境”,由宿主环境将这些数据写入文件。而缓冲区里面尚未读取的数据将被丢弃。然后断开流与文件的关联。如果存在系统自动分配的与该流相关联的缓冲区,则会释放该缓冲区。 |
| 返回值 | 若成功地关闭流,则返回0。检查到错误时返回EOF。 |
下图为关闭文件的示意图。只要将打开文件时fopen函数返回的指针传给fclose函数即可。

5.文件的随机读写?
5.1 fwrite?
fwrite用于函数的读取以下为说明:
| 头文件 | #include<stdio.h> |
| 原型 | size_t fwrite (const void *ptr, size_t size,size_t nmemb,FILE *stream) ; |
| 说明 | 从ptr指向的数组中将最多nmemb个长度为size的元素写入stream指向的流中。若定义了流的文件位置指示符,则以成功写入的字符数为单位向前移动。当发生错误时,该流的文件位置指示符的值不可预测。 |
| 返回值 | 返回成功写入的元素个数。仅当发生写入错误时,元素个数会少于nmemb。 |



实例代码:二进制输出(二进制的写)
#include<stdio.h>
//fwrite
struct S
{
char name[20];
int age;
float score;
};
int main()
{
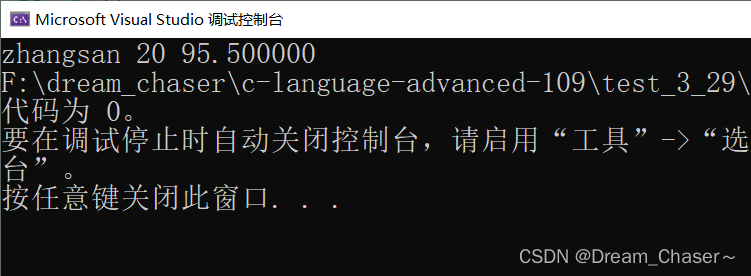
struct S s={"zhangsan",20,95.5f};
FILE* pf = fopen("test.aaa", "wb");//这个后缀.aaa可以任意命名
if (pf == NULL)
{
perror("fopen");
return 0;
}
fwrite(&s, sizeof(struct S), 1, pf);
//关闭文件
fclose(pf);
return 0;
} 执行:以二进制的信息写进文本文件,记事本打开,我们肉眼看不懂,
5.2fread?
| 头文件 | #include<stdio.h> |
| 原型 | size_t fread (const void *ptr, size_t size,size_t nmemb,FILE *stream); |
| 说明 | 从stream指向的流中最多读取nmemb个长度为size的元素到ptr指向的数组。若定义了流的文件位置指示符,则以成功读取的字符数为单位向前移动。当发生错误时,该流的文件位置指示符的值不可预测。只读取到某一元素的部分内容时,值不可预测。 |
| 返回值 | 返回成功读取的元素个数。当发生读取错误或达到文件末尾时,元素个数会少于nmemb。 若size或nmemb为0,则返回0。这时数组内容和流的状态都不发生变化。 |



实例到代码::二进制输入 (二进制的读)
struct S
{
char name[20];
int age;
float score;
};
int main()
{
struct S s = { 0 };
FILE* pf = fopen("test.aaa","rb");//二进制的读
if (pf == NULL)
{
perror("fopen");
return 0;
}
//读文件
fread(&s, sizeof(struct S), 1, pf);
printf("%s %d %f", s.name, s.age, s.score);
//关闭文件
fclose(pf);
pf = NULL;
}执行:
关于fwrite和fread:
这两个函数会接收4个参数。第一个参数是指向读写数据的首地址的指针,第二个参数是数据的长度,第三个参数是数据的个数,第四个参数是指向读写对象的流的指针。
5.3fseek?
根据文件指针的位置和偏移量来定位文件指针。
int fseek ( FILE * stream, long int offset, int origin );
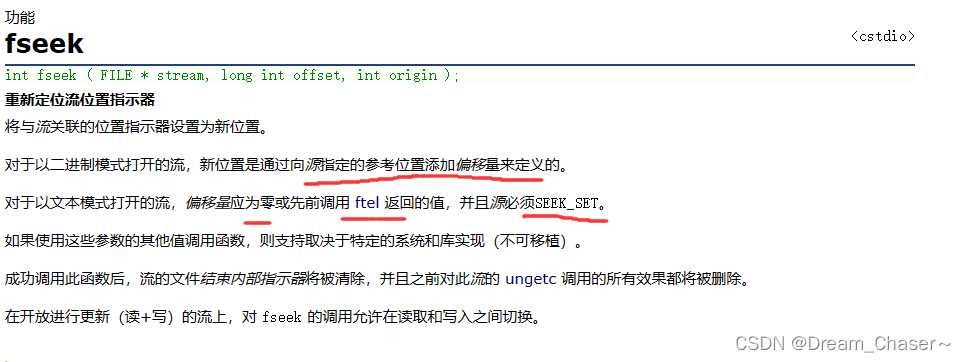


图解:
主动把文件的内容改成:要找的字符是b
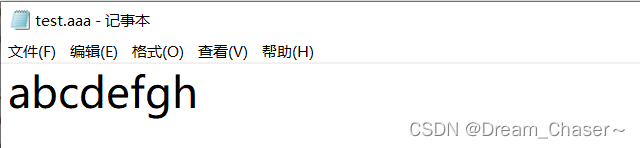
图解:

实例代码:
#include<stdio.h>
int main()
{
FILE* pf = fopen("test.aaa","r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
int ch = fgetc(pf);
printf("%c
", ch);
ch = fgetc(pf);
printf("%c
", ch);
ch = fgetc(pf);
printf("%c
", ch);
ch = fgetc(pf);
printf("%c
", ch);
ch = fgetc(pf);
printf("%c
", ch);
//希望读到的是b--想读那个位置就读哪个位置
//fseek(pf, -4, SEEK_CUR);
//fseek(pf, 1, SEEK_SET);
fseek(pf, -7, SEEK_END);
ch = fgetc(pf);
printf("%c
", ch);
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}执行:

关于rewind函数:

5.4 ftell?
long int ftell ( FILE * stream );

#include<stdio.h>
int main()
{
FILE* pf = fopen("test.aaa","r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
int ch = fgetc(pf);//a
printf("%c ", ch);
ch = fgetc(pf);//b
printf("%c ", ch);
ch = fgetc(pf);//c
printf("%c ", ch);
ch = fgetc(pf);//d
printf("%c ", ch);
ch = fgetc(pf);//e
printf("%c ", ch);
//希望读到的是b--想读那个位置就读哪个位置
printf("%d ", ftell(pf));//此时pf指向的是f,与a字符相差5个char
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}
执行:

5.5 rewind?

#include<stdio.h>
int main()
{
FILE* pf = fopen("test.aaa", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//读文件
int ch = fgetc(pf);//a
printf("%c ", ch);
ch = fgetc(pf);//b
printf("%c ", ch);
ch = fgetc(pf);//c
printf("%c ", ch);
ch = fgetc(pf);//d
printf("%c ", ch);
rewind(pf);//重新回到起始位置
printf("%d ", ftell(pf));//与起始位置的偏移量
ch = fgetc(pf);//从a开始
printf("%c ", ch);
}
执行:

6.文本文件和二进制文件?
我们打开之后通过文本文件的类型是能看得懂的,知道里面放的是什么内容,一眼就可以看得懂
二进制的信息,用文本文件打开是看不懂的。(这里不算是压缩文件,因为压缩是在已有的数据格式再进行压缩的,这里是原模原样把数据按不同的组织形式存起来)
也就是说内存里的数据不做任何转换直接存到文件里面去,这就是 二进制文件
如果要求在外存上以ASCII码的形式存储,则需要在存储前转换。以ASCII字符的形式存储的文件就是文本文件。
一个数据在内存中是怎么存储的呢?
字符一律以ASCII形式存储,数值型数据既可以用ASCII形式存储,也可以使用二进制形式存储。
图解:

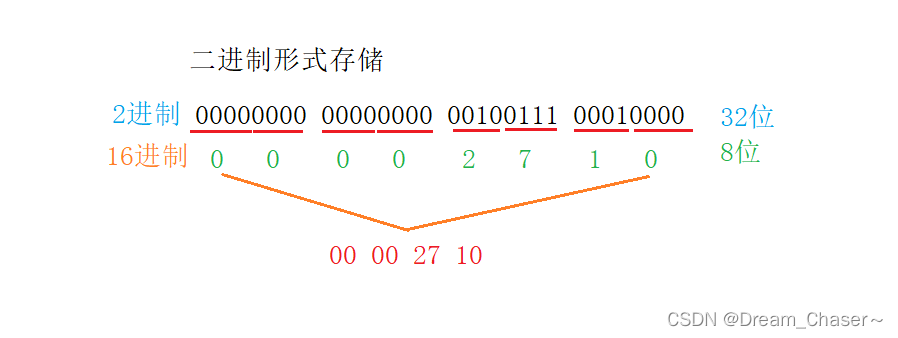
二进制形式输出为什么占用4字节?❓因为10000是一个整数(int),一个int占用4个字节的空间创建一个int a变量,那么a=10000,10000(10进制),它的二进制表示形式为:
可以看到二进制的表达形式为00 00 27 10 -->小端存储形式:10 27 00 00(下面有演示图)
解释一下 以 ASCII码的形式 输出到磁盘,为什么占用5个字节:因为 10000 5位如果以ascll码值的形式存到硬盘里面去的时候 '1''0''0''0''0' 5个字符存到硬盘里面去,那就是5个字节
测试代码:
#include<stdio.h>
int main()
{
int a = 10000;
FILE* pf = fopen("test.txt", "wb");
fwrite(&a, 4, 1, pf);//二进制的形式写进文件中
fclose(pf);
pf = NULL;
return 0;}
二进制文件展现:?
把test.txt文本文件添加进编译器之后,右键可以按照以下的流程可以看到10000在内存中的存储情况:10000它的二进制序列以小端的方式存储到内存里面,内存里面的数据不加任何转换直接以小端的形式的顺序写到文件里面去,这种文件就被称为2进制文件

7.文件读取结束的判定✅
牢记:在文件读取过程中,不能用 feof 函数的返回值直接用来判断文件的是否结束就是说feof是等到文件读取结束之后去判断,而不是一边读取一边判断。这个写法是错的:while(!feof(pf)){}
例如:1. 文本文件读取是否结束,判断返回值是否为 EOF ( fgetc ),或者 NULL ( fgets )
- fgetc 判断是否为 EOF .
- fgets 判断返回值是否为 NULL
2. 二进制文件的读取结束判断,判断返回值是否小于实际要读的个数。例如:
- fread判断返回值是否小于实际要读的个数。


总结fgetc:
1.遇到文件末尾,返回EOF,同时设置一个状态,遇到文件末尾了,使用feof来检测这个状态
⒉.遇到错误,返回EOF,同时设置一个状态,遇到了错误,使用ferror来检测这个状态
| 头文件 | #include<stdio.h> |
| 原型 | int fgetc(FILE *stream); |
| 说明 | 从stream指向的输入流(若存在)中读取unsigned char型的下一个字符的值,并将它转换为int型。然后,若定义了流的文件位置指示符,则将其向前移动。 |
| 返回值 | 返回stream所指输入流中的下一个字符。若在流中检查到文件末尾,则设置该流的文件结束指示符并返回EOF。如果发生读取错误,就设置该流的错误指示符并返回EOF。 |


实例代码:
#include<stdio.h>
int main()
{
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
return 1;
}
//读文件
int ch = 0;
while ((ch = fgetc(pf)) != EOF)
{
printf("%c ", ch);
}
fclose(pf);
pf = NULL;
return 0;
}执行:(前提已经往里面写好了数据)


如何让fgetc在读取中途失败呢?
写法1:
首先把文件删掉
 其次把代码改成:
其次把代码改成:
#include<stdio.h>
int main()
{
FILE* pf = fopen("test.txt", "r");//这个位置写成"r"
if (pf == NULL)
{
return 1;
}
//读文件
int ch = 0;
while ((ch = fgetc(pf)) != EOF)
{
printf("%c ", ch);
}
fclose(pf);
pf = NULL;
return 0;
}执行:


写法2:如果文件中字符不等于10个,就会读取失败(举例)
#include<stdio.h>
#include <stdlib.h>
int main() {
FILE* fp;
char str[20];
fp = fopen("test.txt", "r");
if (fp == NULL) {
printf("打开文件失败
");
exit(EXIT_FAILURE);
}
if (fread(str, sizeof(char), 9, fp) != 10) {
printf("读取文件失败
");
exit(EXIT_FAILURE);
}
fclose(fp);
return 0;
}执行:
前提是我的文件写入26个字母
这里要读取的就是9个字符


8. 文件缓冲区?
当我们想把我们程序的数据写到硬盘上(也就是文件里面去的时候),不是直接就写到硬盘里面去,而是先写到输出缓冲区里面去,当缓冲区放满了或者说主动把数据放到硬盘里面,它自动再把输出缓冲区的数据放到硬盘里面去。而输入的时候,从硬盘里读数据放到输入缓冲区,然后再把输入缓冲区的数据放到程序数据区里面去。

其实这就是一个提高效率的问题:就以fwrite为例吧,操作系统可以从电脑里面写数据与读数据,提供了一堆的API(接口),c语言凭什么可以操作文件呢?其实因为操作系统有一些接口可以操作文件。而fwrite是c语言的一个函数,通过利用fwrite函数写的一个代码称为用户程序,用户程序调用操作系统提供的一些接口然后去操作文件的。

所以说调用这些函数写文件或者读文件的时候严格来说会频繁打断操作系统,所以说能不能写上一堆然后一次搞定呢?所以就提供了输入和输出缓冲区。一个同学一次问10个问题和频繁地分时间问问题的效果是一样的,只是效率问题,这个资源就可以腾出来给其他同学服务。
//VS2013 WIN10环境测试
//#include<stdio.h>
//#include<stdlib.h>
//#include<Windows.h>
int main()
{
FILE* pf = fopen("test.txt", "w");
fputs("abcdef", pf);//先将代码放在输出缓冲区
printf("睡眠10秒-已经写数据了,打开test.txt文件,发现文件没有内容
");
Sleep(10000);
printf("刷新缓冲区
");
fflush(pf);//刷新缓冲区时,才将输出缓冲区的数据写到文件(磁盘)
//注:fflush 在高版本的VS上不能使用了
printf("再睡眠10秒-此时,再次打开test.txt文件,文件有内容了
");
Sleep(10000);
fclose(pf);
//注:fclose在关闭文件的时候,也会刷新缓冲区
pf = NULL;
return 0;
}睡眠sleep就是,程序在这停止了,不继续往下执行,停了10秒后,再继续执行,这样有助于我们
观察数据从缓冲区到文件的过程。
不写fflush刷新会写入到文件里面吗?
可以理解为提前写入了。因为本来他计划的是程序执行结束之后再将缓冲区中的数据写入,现在是程序结束之前将数据写入文件。
9.实现一个代码,拷贝一个文件打开文件,打开被读的文件
int main()
{
//实现一个代码,拷贝一个文件
//打开文件
//打开被读的文件
FILE* pfRead = fopen("test1.txt", "r");
if (pfRead == NULL)
{
perror("open file for read");
return 1;
}
//打开要写的文件
FILE* pfWrite = fopen("test2.txt", "w");
if (pfWrite == NULL)
{
fclose(pfRead);
pfRead = NULL;
pfRead = NULL;
perror("open file for write");
return 1;
}
//拷贝
int ch = 0;
while ((ch=fgetc(pfRead)) != EOF)
{
fputc(ch,pfWrite);
}
//关闭文件
fclose(pfRead);
pfRead = NULL;
fclose(pfWrite);
pfWrite = NULL;
return 0;
}执行:
test1:起始文件
test2:目标文件



c语言的文件操作到这里就写完了,如有不对的地方,欢迎大佬的指导,感谢您的来访!






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结