您现在的位置是:首页 >技术杂谈 >Flink SQL之Regular Joins网站首页技术杂谈
Flink SQL之Regular Joins
简介Flink SQL之Regular Joins
1.Regular Joins(双流join)
双流join是最通用的联接类型(支持 BatchStreaming),其中任何新记录或联接两侧的更改都是可见的,并影响整体的Join结果。
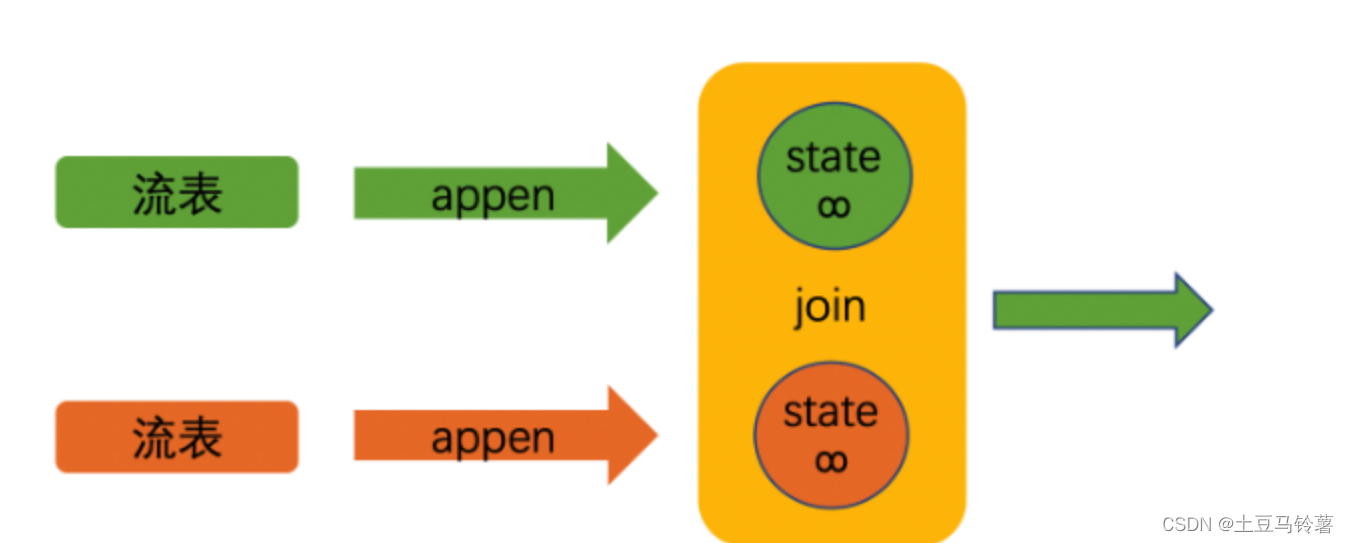
特点:
- 对于流式查询,双流join的语法是最灵活的,允许任何类型的更新(插入、更新、删除)输入表。
- 它需要将连接输入的两侧永远保持在Flink状态。因此,根据所有输入表和中间联接结果的不同输入行的数量,计算查询结果所需的状态可能会无限增长。可以为查询配置提供适当的状态生存时间(TTL),以防止状态大小过大。同时,这可能会影响查询结果的正确性。
- 数据一直根据输入流一直更新,“逐步逼近”最终的精确值,下游可能看到不断变化的结果,为了执行结果更新,下游需要定义主键。同时,状态可能会无限增长,需注意状态需要内存空间是否足够。
适用场景:因为资源问题 Regular Join 通常是不可持续的,一般只用做有界数据流的 Join。
总结以上特点,双流join支持基本特性如下:
- 支持INNER、LEFT、RIGHT、FULL OUT JOIN
- 语义语法和传统sql join一致
- 左右流都会触发更新
- 状态持续增长、一般结合 state TTl配合使用
2.语法
SELECT * FROM Orders
[INNER|RIGHT|LEFT|FULL OUTER] JOIN Product
ON Orders.productId = Product.id3.流表join流表
如果其中一个流表触发更新操作,同样触发join生成最新的结果。
CREATE TABLE users (
user_id STRING,
name STRING,
age INT,
gmt_time TIMESTAMP(3)
) WITH (
'connector' = 'kafka',
'topic' = 'users',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'orders2ConsumerGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
CREATE TABLE address (
user_id STRING,
address STRING,
update_time TIMESTAMP(3)
) WITH (
'connector' = 'kafka',
'topic' = 'address',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'orders2ConsumerGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
select u.user_id,u.name,u.age,a.address
FROM users u
LEFT JOIN address a
ON u.user_id = a.user_id;4.流表join维表
CREATE TABLE users (
`user_id` STRING,
`name` STRING,
`age` INT,
`gmt_time` TIMESTAMP(3)
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/flink',
'table-name' = 'user',
'username' = 'root',
'password' = '123456'
)
CREATE TABLE address (
`user_id` STRING,
`address` STRING,
`gmt_time` TIMESTAMP(3)
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/flink',
'table-name' = 'user_address',
'username' = 'root',
'password' = '123456'
)
select users.name, users.user_id, users.age, address.address
from users,address
where users.user_id = address.user_id;实际项目流处理中,维表通常存储在外部设备中(MySQL,OceanBase、HBase等),对于每条流式数据,可以关联一个外部维表数据源,为实时计算提供数据关联查询。所以流表关联维表通常采用Temporal Joins(时态join)方式进行关联,后续会继续介绍。
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结