您现在的位置是:首页 >技术交流 >旅游有哪些好玩的地方? 今天用python分析适合年轻人的旅游攻略网站首页技术交流
旅游有哪些好玩的地方? 今天用python分析适合年轻人的旅游攻略
前言
嗨喽,大家好呀~这里是爱看美女的茜茜呐

“旅”是旅行,外出,即为了实现某一目的而在空间上从甲地到乙地的行进过程;
“游”是外出游览、观光、娱乐,即为达到这些目的所作的旅行。
二者合起来即旅游。所以,旅游不但有“行”,且有观光、娱乐含义。
知识点:
-
requests 发送网络请求
-
parsel 解析数据
-
csv 保存数据
开发环境:
-
版 本: python 3.8
-
编辑器:pycharm 2021.2
第三方库:
-
requests >>>发送网络请求的模块
-
parsel >>> 解析数据的模块
第三方模块安装:
-
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
-
在pycharm中点击Terminal(终端) 输入安装命令
如果出现爆红, 可能是因为 网络连接超时, 可切换国内镜像源,命令如下:
pip install -i https://pypi.doubanio.com/simple/ requests
python资料、源码、教程福利皆: 点击此处跳转文末名片获取
旅游数据采集
import requests
import parsel
import csv
import time
import random
csv_qne = open('去哪儿.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.writer(csv_qne)
写入数据
csv_writer.writerow(['地点', '短评', '出发时间', '天数', '人均消费', '人物', '玩法', '浏览量'])
(1) 向目标网址发送请求 (get, post)
for page in range(1, 201):
url = f'https://*****/travelbook/list.htm?page={page}&order=hot_heat'
# <Response [200]>: 告诉我们 请求成功了
response = requests.get(url)
(2). 获取数据(网页源代码)
html_data = response.text
(3). 解析网页(re正则表达式,css选择器,xpath,bs4/六年没更新了,json)
selector = parsel.Selector(html_data)
# ::attr(href) url_list:列表
url_list = selector.css('.b_strategy_list li h2 a::attr(href)').getall()
for detail_url in url_list:
# 字符串的 替换方法
detail_id = detail_url.replace('/youji/', '')
url_1 = 'https://*****/travelbook/note/' + detail_id
print(url_1)
(4). 向详情页网站发送请求(get,post)
response_1 = requests.get(url_1).text
(5).解析网页(re正则表达式,css选择器,xpath,bs4 / 六年没更新了,json)
selector_1 = parsel.Selector(response_1)
# :nth-child(): 伪类选择器
# ::text 提取文本内容
# * 代表所有
# 地点
title = selector_1.css('.b_crumb_cont *:nth-child(3)::text').get().replace('旅游攻略', '')
# 短评
comment = selector_1.css('.title.white::text').get()
# 出发日期
date = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.when > p > span.data::text').get()
# 天数
days = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.howlong > p > span.data::text').get()
# 人均消费
money = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.howmuch > p > span.data::text').get()
# 人物
character = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.who > p > span.data::text').get()
# 玩法
play_list = selector_1.css('#js_mainleft > div.b_foreword > ul > li.f_item.how > p > span.data span::text').getall()
play = ' '.join(play_list)
# 浏览量
count = selector_1.css('.view_count::text').get()
# None: 空值 当前没有提取到内容 就会为空
print(title, comment, date, days, money, character, play, count)
(6). 保存数据 (保存为文本,保存到数据库,保存特定格式的文件)
# 保存成csv
csv_writer.writerow([title, comment, date, days, money, character, play, count])
# 设置了延迟 为的就是避免 爬虫程序被抓到
time.sleep(random.randint(3, 5))
csv_qne.close()
"""
报错, 请求次数过于频繁 导致ip被限制, 此时我们有两种方法
1. 搭建自己的ip代理池
在系统课程当中会教大家怎么搭建自己的代理池
怎么加快爬虫的效率问题
2. 通过延迟操作 去模拟正常用户发送请求
延迟时间尽量不去固定
"""
攻略分析
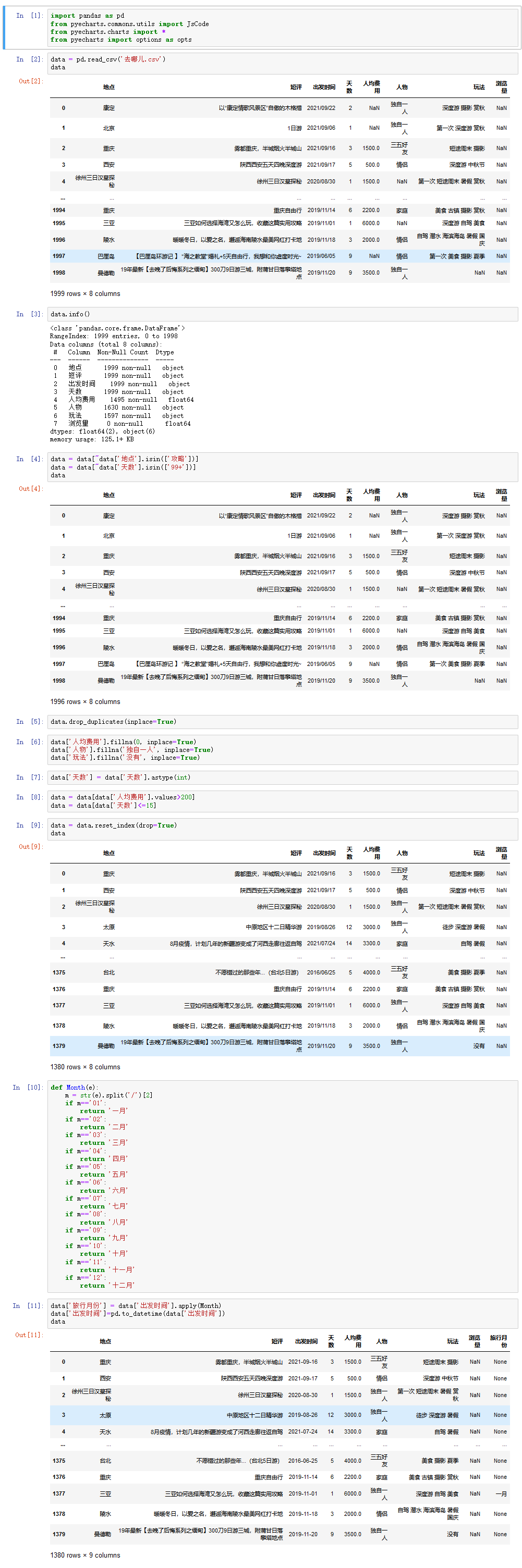
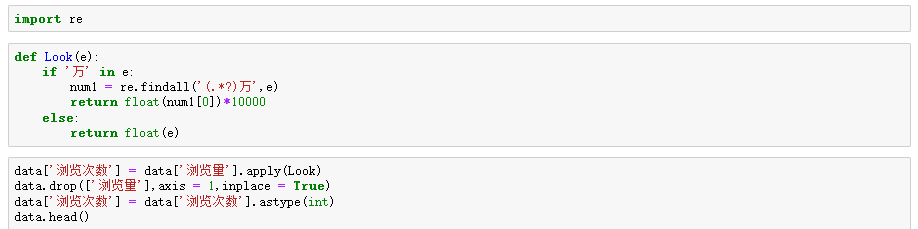

综上述分析可得到一些结论:
个人认为性价比较高的旅游城市:杭州、成都。
旅游天数大多控制在2-5天内,不宜过多。
三五好友一起旅游是最令人们喜欢的出游方式。
“摄影”与“美食”已成为旅游的代名词。
避开旅游高峰期,三月和六月的周末短途旅行也是不错的选择。
尾语
感谢你观看我的文章呐~本次航班到这里就结束啦 ?
希望本篇文章有对你带来帮助 ?,有学习到一点知识~
躲起来的星星?也在努力发光,你也要努力加油(让我们一起努力叭)。







站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结