您现在的位置是:首页 >技术交流 >scitb5函数1.6版本(交互效应函数P for interaction)尝鲜版发布----用于一键生成交互效应表网站首页技术交流
scitb5函数1.6版本(交互效应函数P for interaction)尝鲜版发布----用于一键生成交互效应表
在SCI文章中,交互效应表格(通常是表五)几乎是高分SCI必有。因为增加了亚组人群分析,增加了文章的可信度,能为文章锦上添花,增加文章的信服力,还能进行数据挖掘。
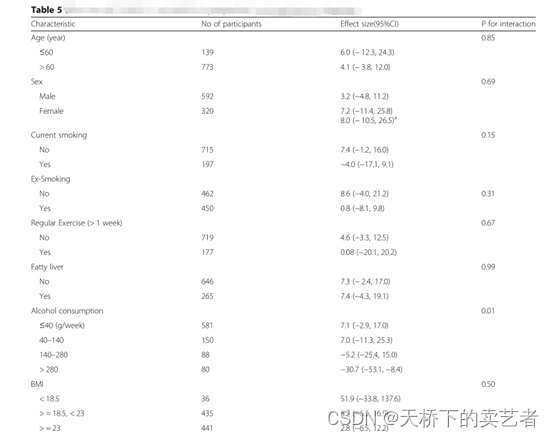
在上一个版本中,我们已经发布的1,4版本已经可以用于一键生成交互效应表,但是只能用在目标变量X是连续变量的的交互效应函数,目标变量是分类变量的的数据用不了.有些分层数据分层得不好的也用不了。我重新改进了算法,在新的版本中,已经就算亚组数据只有一个分类,也是能进行计算的,而且支持了分类变量的计算。这应该是我目前写的比较复杂的一个函数了,主要是使用别人的函数接口不好对接,所以底层函数基本全自己写了,好了,废话不多说,进行演示一下。先做逻辑回归
导入我们的早产数据
bc<-read.csv("E:/r/test/zaochan.csv",sep=',',header=TRUE)
bc <- na.omit(bc)
names(bc)
dput(names(bc))
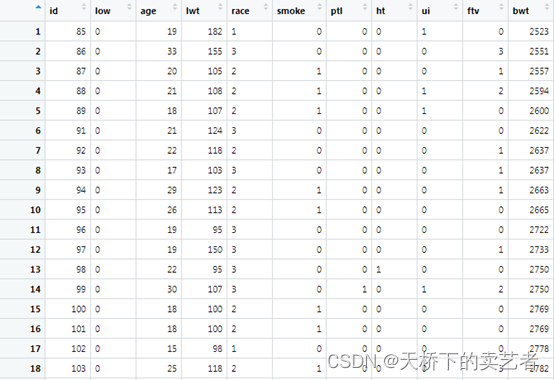
这是一个关于早产低体重儿的数据(公众号回复:早产数据,可以获得该数据),低于2500g被认为是低体重儿。数据解释如下:low 是否是小于2500g早产低体重儿,age 母亲的年龄,lwt 末次月经体重,race 种族,smoke 孕期抽烟,ptl 早产史(计数),ht 有高血压病史,ui 子宫过敏,ftv 早孕时看医生的次数,bwt 新生儿体重数值
bc$race<-ifelse(bc$race=="black",1,ifelse(bc$race=="white",2,3))
bc$smoke<-ifelse(bc$smoke=="nonsmoker",0,1)
bc$low<-factor(bc$low)
bc$race<-factor(bc$race)
bc$ht<-factor(bc$ht)
bc$ui<-factor(bc$ui)
定义协变量和分层因子
cov1<-c("lwt","smoke","ptl","ui","ftv","race")
Interaction<-c("race","smoke","ui")
导入函数,我这里直接写成函数文件1.6final.R,直接导入就可以了
source("E:/r/test/1.6final.R")
导入成功后应该生成7个函数
生成表,和1.4版本一样data是你的数据,必须是数据框形式,x是你研究的目标变量,y是你的结局变量,Interaction是你的分层变量,这个必须是分类变量并转成因子,cov是你的协变量,在我的设定中cov是要包含Interaction的,这也符合我们的习惯。family这里和原来有点不同,统一使用family=“glm”,支持逻辑回归和线性回归,cox回归目前还没支持,需要的可以使用1.4版本
out<-scitb5(data=bc,x="age",y="low",Interaction=Interaction,cov = cov1,family="glm")
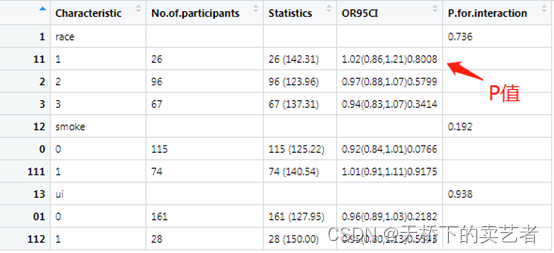
新版本多加了一个P值,在可信区间的后面。换一个分类数据试一下,这里ht是个分类数据,表示是否有高血压。
cov1<-c("lwt","smoke","ptl","ui","ftv","race")
Interaction<-c("race","smoke","ui")
out<-scitb5(data=bc,x="ht",y="low",Interaction=Interaction,cov = cov1,family="glm")
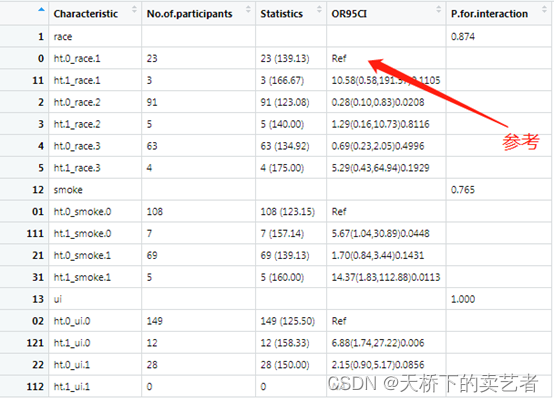
上图我要解释一下,做分类变量的时候需要设定一个参考,在race这个分层比较的时候,ht.0_race.1是被认定做参考的,什么意思呢?就是当ht等于0和race等于1这个亚组的人群是被默认为做参考比较的,其他组都是和它进行比较最后一组有个数据缺失,是因为这个分层一个数据都没有,所以就是NA。
所以说,分类变量进行亚组交互的时候,分类最好不要太多,要不数据会很大,而且有些层分不到数据。下面来演示一下粉丝的数据,我们先导入数据
bc<-read.csv("E:/r/fensi/final1.csv",sep=',',header=TRUE)
dput(names(bc))
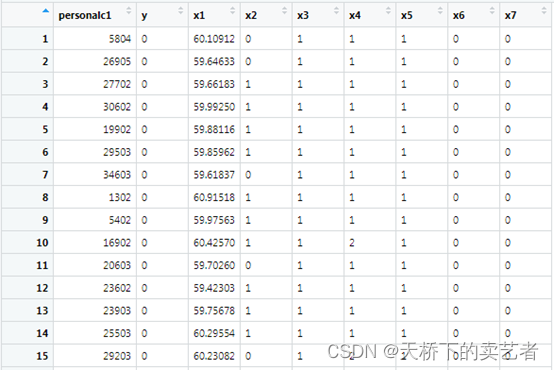
分类变量转成因子
bc[,c("x2", "x3", "x4", "x5", "x6", "x7","y")] <- lapply(bc[,c("x2", "x3", "x4", "x5", "x6", "x7","y")], factor)
定义协变量和分层变量
Interaction<-c("x2", "x3", "x4","x5")
cov<-c("x2", "x3", "x4", "x5", "x6", "x7")
在上一个版本中X5是不能分层的,如下图
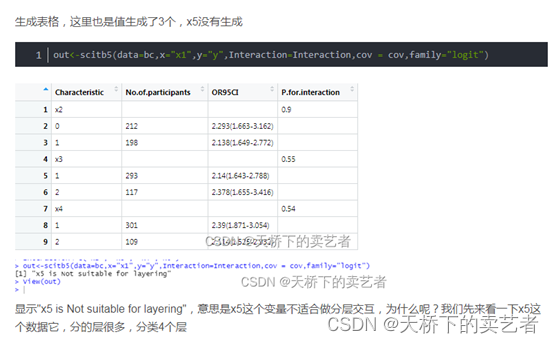
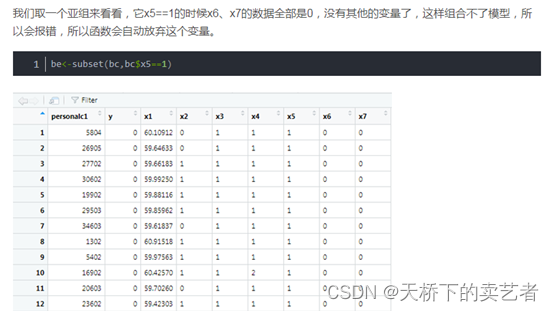
在改变了新的算法后,这个问题就不存在了。我们来试一下
out<-scitb5(data=bc,x="x1",y="y",Interaction=Interaction,cov = cov,family="glm")
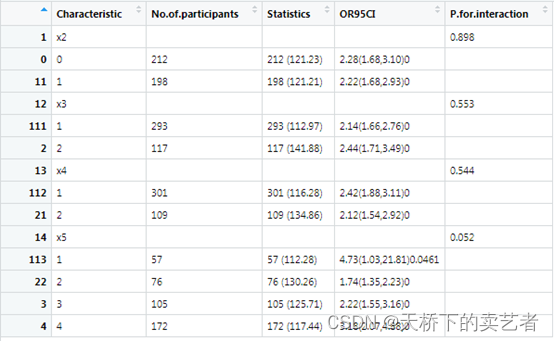
我们可以看到,虽然使用了完全不一样的算法,但是X2、X3、X4的值和原来一样,而且使用常规方法不能计算的和X5Y也计算出来了。我们可以看到在X5分组的3个亚组人群中,目标变量和结局是线性关系,理论上可以写3篇文章进行分析了。
我们在再看一个粉丝的数据,目标变量是分类变量的
bc<-read.csv("E:/r/fensi/DII_GROUP.csv",sep=',',header=TRUE)
dput(names(bc))

这个数据很大,上图只是一部分,把分类变量转成因子
bc[,c("sex_02", "nianling_02", "marriage_02", "GROUP",
"smoke_02")] <- lapply(bc[,c("sex_02", "nianling_02", "marriage_02","GROUP", "smoke_02")], factor)
str(bc)
定义协变量和分层变量
Interaction<-c("sex_02", "nianling_02", "marriage_02", "smoke_02")
cov<-c("sex_02", "nianling_02", "marriage_02", "smoke_02","wc_02")
生成表格
out<-scitb5(data=bc,x="GROUP",y="dm_19",Interaction=Interaction,cov = cov,family="glm")
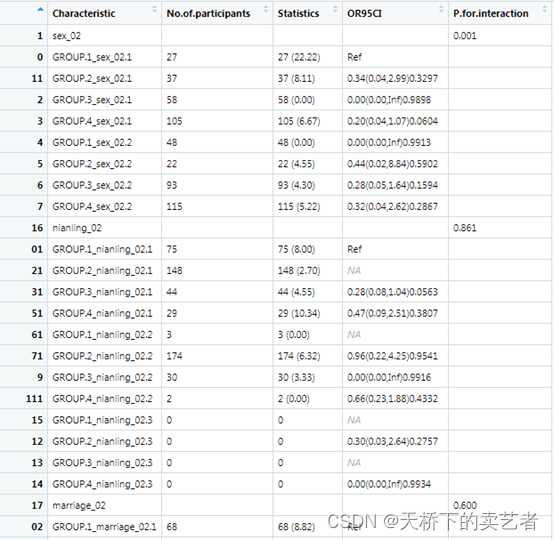
我们可以看到,某些分层变量过少,是出不了结果的,所以显示NA。所以目标变量是分类变量时,最好分类不要太多。
再来演示一个粉丝的数据,这回就不解释了,直接上代码
bc<-read.csv("E:/r/fensi/yang.csv",sep=',',header=TRUE)
dput(names(bc))
bc[,c("Gender", "CVDs.death", "PIR.group", "smoker","X","State")] <- lapply(bc[,c("Gender", "CVDs.death", "PIR.group", "smoker","X","State")], factor)
str(bc)
Interaction<-c("smoker","PIR.group")
cov<-c("PIR.group","smoker","Age")
out<-scitb5(data=bc,x="X",y="CVDs.death",Interaction=Interaction,cov = cov,family="glm")
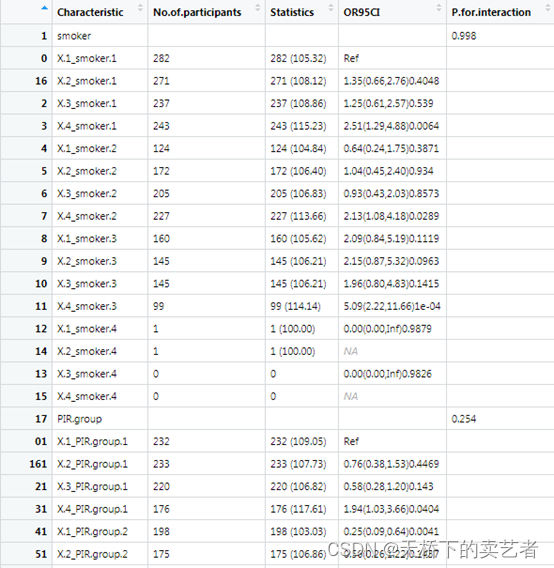
我想说的是这个数据中X有4个分类,smoker 有4个分类,所以单单smoker 这个组就有16个分类了。
最后说说怎么导出数据做表,拿第一个数据来说
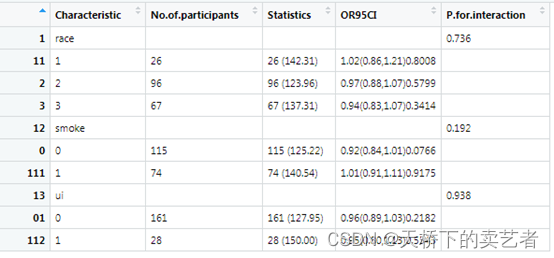
我们把它先保存成CSV格式
write.csv(out,file = "1.csv",row.names = F)
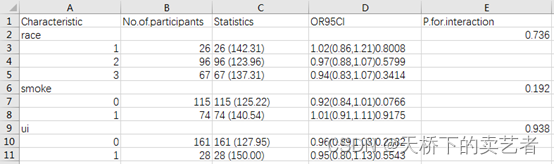
然后再把它复制到WORD上,
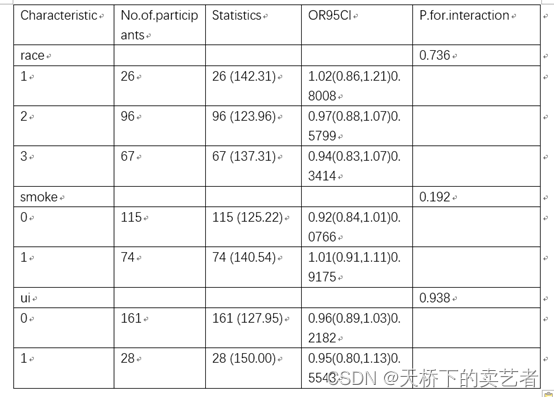
稍稍整理一下
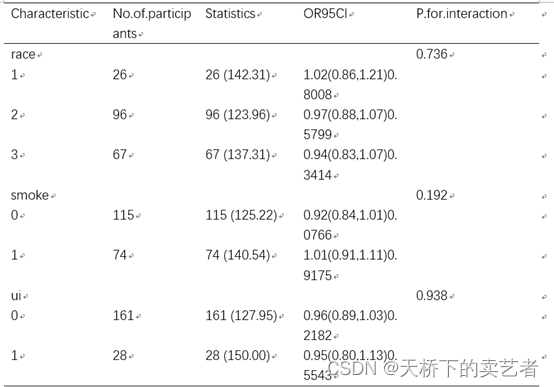
一个可以用于发表的的交互效应表就做好啦。
原来已经购买1.4版本的不需要重新购买,使用原来的方法下载就可以了,已经进行内容跟新。
新版本要是有什么问题,非常乐意你私信告诉我
获取scitb5函数代码请参看这篇文章:






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结