您现在的位置是:首页 >技术交流 >基于卡尔曼滤波实现线性目标跟踪网站首页技术交流
基于卡尔曼滤波实现线性目标跟踪
前言
一个需求,在一个稳定的场景当中,实现目标检测计数算法。
任务点:
- 实现目标检测
- 完成对不同类别的物品进行计数
- 在边缘设备完成部署
难点:
- 边缘设备算力不足
- 目标识别精度问题,识别类别在28类
- 实时检测,存在相同物品重复计数的问题,需要进行区分识别,避免重复计数
易点:
- 算力不足可以使用tiny系列的yolo算法,并通过tensorRT进行加速处理
- 摄像头运动轨迹固定,为线性移动过程
方案:
- 采用yolov3-tiny 算法
- 通过卡尔曼滤波实现简单的目标跟踪,记录物品ID和类别即可完成计数
注: 本博文只提供简单思路,以及大致的实现,具体实现细节,甚至是实现语言请自行斟酌。
卡尔曼滤波
这个说来惭愧,去年好像是要写关于卡尔曼滤波的博文来着,好像还写了上篇,下篇没写。没想到,都是有铺垫的,回头还是得补上。
它的原理其实不难,先前我记得还举了什么小车运动的例子。说实话,都是徒劳的,数学语言永远都是最优雅的,当然还有个原因,举例子太麻烦了。反正最后都是对公式进行解释,还不如直面它,战胜恐惧的最好方法就算直面它!!!哪里不会,你就怼哪里,无非就是你愿不愿意花费精力的问题。扯多了哈。
基本推导
卡尔曼滤波是一种最优线性无偏估计算法,它可以对动态系统进行状态估计、控制和预测。其基本原理是通过对状态及其协方差的更新,来不断优化对系统状态的估计。
假设某时刻系统的状态为 x ( k ) x(k) x(k),观测值为 z ( k ) z(k) z(k),可以建立如下的状态方程和观测方程(其中 n ( k ) n(k) n(k)和 v ( k ) v(k) v(k)分别是系统噪声和观测噪声):
x ( k ) = A x ( k − 1 ) + B u ( k ) + n ( k ) x(k)=Ax(k-1)+Bu(k)+n(k) x(k)=Ax(k−1)+Bu(k)+n(k)
z ( k ) = H x ( k ) + v ( k ) z(k)=Hx(k)+v(k) z(k)=Hx(k)+v(k)
其中, A A A是系统状态转移矩阵, B B B是矩阵 u ( k ) u(k) u(k)的系数, H H H是观测矩阵。
首先对于一个已知的状态 x x x,我们需要根据测量值 z z z,来求出新的状态 x ′ x' x′。如果不考虑噪声,可以很容易地得到:
x ′ = H − 1 z x' = H^{-1}z x′=H−1z
但由于存在噪声,上述公式不再适用,因此需要对状态协方差进行估计,从而得到更准确的状态估计。卡尔曼滤波使用贝叶斯概率论框架来处理噪声,因此需要对先验和后验概率进行建模。假设先验概率为 P ( x ) P(x) P(x),后验概率为 P ( x ∣ z ) P(x|z) P(x∣z),则卡尔曼滤波的基本思想是通过不断更新先验概率,从而获得更准确的后验概率。
一般地,先验概率可以表示为:
P ( x ) = N ( x ( k ) ; x ^ ( k ∣ k − 1 ) , P ( k ∣ k − 1 ) ) P(x)=mathcal{N}(x(k); hat{x}(k|k-1), P(k|k-1)) P(x)=N(x(k);x^(k∣k−1),P(k∣k−1))
其中, x ^ ( k ∣ k − 1 ) hat{x}(k|k-1) x^(k∣k−1)是根据先前的状态和动态方程预测出的下一个状态的估计值, P ( k ∣ k − 1 ) P(k|k-1) P(k∣k−1)是根据协方差矩阵计算出的状态估计误差的度量。
卡尔曼滤波的核心算法是通过观测更新先验概率。观测数据可以用于修正状态估计,进而提高系统估计的精度。在更新协方差矩阵时,卡尔曼滤波使用了最小均方误差(MMSE)方法,并采用贝叶斯公式进行求解。
观测更新可以被描述为:
P ( x ∣ z ( k ) ) = P ( z ( k ) ∣ x ) P ( x ) P ( z ( k ) ) P(x|z(k)) = frac{P(z(k)|x)P(x)}{P(z(k))} P(x∣z(k))=P(z(k))P(z(k)∣x)P(x)
其中, P ( z ( k ) ∣ x ) P(z(k)|x) P(z(k)∣x)为给定状态 x x x时观测值 z ( k ) z(k) z(k)的概率密度函数, P ( z ( k ) ) P(z(k)) P(z(k))为归一化因子。
通过简单推导,可以得到状态协方差矩阵的更新方式为:
P ( k ∣ k ) = P ( k ∣ k − 1 ) ( I − K ( k ) H ) P(k|k)=P(k|k-1)(I-K(k)H) P(k∣k)=P(k∣k−1)(I−K(k)H)
其中, K ( k ) K(k) K(k)是卡尔曼增益矩阵,表示当前时刻观测信息和先验信息的权重。
K ( k ) = P ( k ∣ k − 1 ) H T H P ( k ∣ k − 1 ) H T + R K(k)=frac{P(k|k-1)H^T}{HP(k|k-1)H^T+R} K(k)=HP(k∣k−1)HT+RP(k∣k−1)HT
其中, R R R为观测噪声的协方差矩阵,用于描述观测误差。
最后,利用以上推导的公式,通过递归计算,可以得到每个时刻的状态估计和协方差矩阵,从而实现对动态系统进行状态估计。
运算
那么接下来的话,我们来看到它是如何完成整个过程的运算的。
我们遵从如下过程:
预测:利用前一时刻的状态估计和状态转移矩阵,以及控制输入的信息,预测当前时刻的状态。即:
x ^ ( k ∣ k − 1 ) = F x ^ ( k − 1 ∣ k − 1 ) + B u ( k ) hat{x}(k|k-1) = Fhat{x}(k-1|k-1) + Bu(k) x^(k∣k−1)=Fx^(k−1∣k−1)+Bu(k)
预测协方差更新:利用前一时刻的协方差矩阵,以及系统的状态转移矩阵和噪声协方差矩阵,来更新先验协方差矩阵。即:
P ( k ∣ k − 1 ) = F P ( k − 1 ∣ k − 1 ) F T + Q P(k|k-1)=FP(k-1|k-1)F^T + Q P(k∣k−1)=FP(k−1∣k−1)FT+Q
观测更新:利用观测信息来修正先验状态估计和协方差矩阵,得到后验状态估计和协方差矩阵。具体来说,我们可以通过以下步骤来进行观测更新:
计算卡尔曼增益 K ( k ) K(k) K(k):
K ( k ) = P ( k ∣ k − 1 ) H T ( H P ( k ∣ k − 1 ) H T + R ) − 1 K(k) = P(k|k-1)H^T(H P(k|k-1) H^T + R)^{-1} K(k)=P(k∣k−1)HT(HP(k∣k−1)HT+R)−1
更新后验状态估计:
x ^ ( k ∣ k ) = x ^ ( k ∣ k − 1 ) + K ( k ) ( z ( k ) − H x ^ ( k ∣ k − 1 ) ) hat{x}(k|k) = hat{x}(k|k-1) + K(k)(z(k)-Hhat{x}(k|k-1)) x^(k∣k)=x^(k∣k−1)+K(k)(z(k)−Hx^(k∣k−1))
更新后验协方差矩阵:
P ( k ∣ k ) = ( I − K ( k ) H ) P ( k ∣ k − 1 ) P(k|k) = (I-K(k)H)P(k|k-1) P(k∣k)=(I−K(k)H)P(k∣k−1)
其中, Q Q Q为系统噪声协方差矩阵, R R R为观测噪声协方差矩阵。在实际应用中,这些协方差矩阵通常需要通过经验或者试验来确定。
当然在这里,一开始的时候,这些矩阵都是需要初始化的,那么这个如何初始化就要看具体任务了,当然还有前人的经验。
怎么用呢,其实很简单,假设我们有一个物体A,我们知道了上一个时刻A的坐标,那么输入到这个函数当中。你将得到一个kf对象。这个kf对象呢可以得到下一个时刻A的预测坐标。state = kf.predict() x, y = state[0], state[1] 然后呢,你想要知道C是不是上一个时刻的A物体,那么你只要对比A的预测坐标和当前C的坐标进行对比,如果误差在合理的范围内,那么就判定为同一个。
那么在这里的话,显然你已经知道了一点,那就是,如果你需要跟踪多个目标的话,那么你需要多个kf对象,去实现跟踪。至于为什么,看上面的原理你应该明白的。
实现
很好,接下来到了万众期待的实现时刻。
目标检测
首先,我们先来实现实现目标检测部分,这一部分我们当然是通过yolov3-tiny来做。
import cv2
import numpy as np
# 读取yolo模型参数和类别列表
net = cv2.dnn.readNet("yolov3-tiny.weights", "yolov3-tiny.cfg")
classes_file = open("coco.names", "r")
classes = [line.strip() for line in classes_file.readlines()]
while True:
# 读取当前帧
ret, frame = cap.read()
# 对当前帧进行物品检测
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416), swapRB=True, crop=False)
net.setInput(blob)
outs = net.forward(net.getUnconnectedOutLayersNames())
confidences = []
boxes = []
class_ids = []
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.45:
center_x, center_y, w, h = list(map(int, detection[:4] * np.array(
[frame.shape[1], frame.shape[0], frame.shape[1], frame.shape[0]])))
x = int(center_x - w / 2)
y = int(center_y - h / 2)
class_name = classes[class_id]
text = "{} ({})".format(class_name, len(positions))
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.putText(frame, text, (int(x), int(y) - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 显示当前帧
cv2.imshow("frame", frame)
# 等待退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
当然这只是一个示例,运行上面那段代码确保你的相互环境正常罢了。
我们实际上的代码是这样的:
class YoloDetect():
def __init__(self,model_source="yolov3-tiny.weights",mode_cfg="yolov3-tiny.cfg",
class_file="coco.names"
):
self.net = cv2.dnn.readNet(model_source,mode_cfg)
self.classes_file = open(class_file, "r")
self.classes = [line.strip() for line in self.classes_file.readlines()]
def show(self,frame,item,ID=0):
class_name = self.classes[item.get("class_id")]
text = "{}:ID({})".format(class_name,ID)
cv2.rectangle(frame, (item.get("x"), item.get("y")), (item.get("x") + item.get("w"), item.get("y") + item.get("h")), (0, 255, 0), 2)
cv2.putText(frame, text, (int(item.get("x")), int(item.get("y")) - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
return frame
def detect(self, frame, conf_thresh=0.2, nms_thresh=0.45):
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416), swapRB=True, crop=False)
self.net.setInput(blob)
outs = self.net.forward(self.net.getUnconnectedOutLayersNames())
# 对检测结果进行非极大值抑制
boxes, scores, class_ids = [], [], []
for out in outs:
for detection in out:
confidence = detection[4]
if confidence > conf_thresh:
c_x, c_y, w, h = list(map(int, detection[:4] * np.array([frame.shape[1], frame.shape[0], frame.shape[1], frame.shape[0]])))
x = int(c_x - w / 2)
y = int(c_y - h / 2)
boxes.append([x, y, w, h])
scores.append(float(confidence))
class_ids.append(np.argmax(detection[5:]))
indices = cv2.dnn.NMSBoxes(boxes, scores, conf_thresh, nms_thresh)
items = []
# 只保留NMS过后的检测结果
for index in indices:
item = {"class_id": class_ids[index], "x": boxes[index][0], "y": boxes[index][1], "w": boxes[index][2], "h": boxes[index][3],
"score": scores[index]}
items.append(item)
return items
在这里的话,咱们再加入一个NMS
卡尔曼预测器
那么接下来就是我们的卡尔曼预测器的实现了,接下来我们要实现追踪功能。那么我们的核心刚刚也说了,其实非常简单:
class ObjectTrackerKF:
def __init__(self, x_init, y_init, dt=1, sigma=10):
self.dt = dt
# 状态向量,包含位置和速度信息
self.state = np.array([[x_init], [y_init], [0], [0]], np.float32)
# 系统矩阵,将状态向量映射为下一时刻的状态向量
self.A = np.array([
[1, 0, self.dt, 0],
[0, 1, 0, self.dt],
[0, 0, 1, 0],
[0, 0, 0, 1]], np.float32)
# 测量矩阵,将状态向量映射为测量向量
self.H = np.array([
[1, 0, 0, 0],
[0, 1, 0, 0]], np.float32)
# 过程噪声,表示模型中未考虑的外部因素产生的偏差
self.Q = np.array([
[self.dt ** 4 / 4, 0, self.dt ** 3 / 2, 0],
[0, self.dt ** 4 / 4, 0, self.dt ** 3 / 2],
[self.dt ** 3 / 2, 0, self.dt ** 2, 0],
[0, 0, 0, self.dt ** 2]], np.float32) * sigma ** 2
# 测量噪声,表示测量器的误差
self.R = np.array([
[1, 0],
[0, 1]], np.float32) * sigma ** 2
# 卡尔曼滤波器初始化
self.kf = cv2.KalmanFilter(4, 2, 0)
self.kf.statePost = self.state
self.kf.transitionMatrix = self.A
self.kf.measurementMatrix = self.H
self.kf.processNoiseCov = self.Q
self.kf.measurementNoiseCov = self.R
def predict(self):
self.state = self.kf.predict()
return self.state[:2].reshape(-1)
def update(self, x, y):
self.kf.correct(np.array([[x], [y]], np.float32))
return self.state[:2].reshape(-1)
现在我们可以简单测试一下:
tr = ObjectTrackerKF(x_init=100, y_init=200)
print(tr.predict())
for i in range(10):
x = i * 10 + 100
y = i * 20 + 200
predicted_pos = tr.predict()
tr.update(x, y)
print("Predicted position:", predicted_pos)
print("Updated position:", tr.state[:2].reshape(-1))
ID分配器(跟踪器)
那么接下来就是我们的这个ID的分配器了。也就是跟踪器的实现了,其实跟踪器的实现的话,比较简单,但是在这里的话,我们还要在实现一个回收器,主要是要手动回收一下对象,避免后面炸了。
class MulObjectTracker():
def __init__(self,w=640,h=480,thorslde=0.4):
#统计当前出现的不同的类别的数量
self.counts = {}
#当前正在更正的跟踪器
self.objectPres = {}
#当前正在跟踪的item
self.track_items = {}
self.thorslde = thorslde
self.w = w
self.h = h
def __add_tracker(self,item):
class_name = item.get("class_name")
#添加一个目标跟踪,同时,对应的计数器累加
class_trackers = self.objectPres.get(class_name,[])
ID = len(class_trackers)
x,y = item.get("x"),item.get("y")
tracker_pre = ObjectTrackerKF(x,y)
tracker_pre.ID = ID
tracker_pre.hit = True
class_trackers.append(tracker_pre)
self.objectPres[class_name] = class_trackers
#同时完成计数统计
class_count = self.counts.get(class_name,0)
self.counts[class_name] = class_count+1
#对当前的item记录
class_items = self.track_items.get(class_name,[])
class_items.append(item)
self.track_items[class_name] = class_items
def lookdown(self,x,y,x_p,y_p):
# 判断是不是同一个
x,y,x_p,y_p = x/self.w,y/self.h,x_p/self.w,y_p/self.h
dist = np.linalg.norm([x-x_p,y-y_p])
if(dist<=self.thorslde):
return True
def track(self,items):
#此时我们会进行一次操作
for item in items:
class_name = item.get("class_name")
class_tracks = self.objectPres.get(class_name,None)
class_items = self.track_items.get(class_name)
if(not class_tracks):
self.__add_tracker(item)
else:
for i in range(len(class_tracks)):
track = class_tracks[i]
x_p,y_p = track.predict()
x,y = item.get("x"),item.get("y")
if(self.lookdown(x,y,x_p,y_p)):
#如果满足这个定义,那么说明是同一个目标
track.update(x,y)
c_it = class_items[i]
c_it["x"] = x
c_it["y"] = y
track.hit = True
else:
#没有满足那就创建去
self.__add_tracker(item)
self.__gc()
def __gc(self):
for class_name in self.objectPres.keys():
class_tracks = self.objectPres.get(class_name,[])
class_items = self.track_items.get(class_name,[])
dels_tr = []
dels_cl = []
indexs = []
for i in range(len(class_tracks)):
if(class_tracks[i].hit==False):
indexs.append(i)
dels_tr.append(class_tracks[i])
dels_cl.append(class_items[i])
else:
class_tracks[i].hit = False
#确保一定被回收了
class_items=self.__romve(class_items,indexs)
class_tracks=self.__romve(class_tracks,indexs)
self.objectPres[class_name] = class_tracks
self.track_items[class_name] = class_items
for dels_t in dels_tr:
del dels_t
gc.collect()
for dels_c in dels_cl:
del dels_c
gc.collect()
def __romve(self,x,idxs):
if(len(idxs)==0):
return x
j = 0
res = []
for i in range(len(x)):
if(j<len(idxs) and i!=idxs[j]):
res.append(x[i])
else:
j+=1
return res
def show(self,frame):
for class_name in self.track_items.keys():
class_items = self.track_items.get(class_name, [])
for i in range(len(class_items)):
item = class_items[i]
text = "{}:ID({})".format(class_name,i)
cv2.rectangle(frame, (item.get("x"), item.get("y")), (item.get("x") + item.get("w"), item.get("y") + item.get("h")), (0, 255, 0), 2)
cv2.putText(frame, text, (int(item.get("x")), int(item.get("y")) - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
return frame
这段代码的实现其实非常简单,当然这里适当进行了一点优化,我们按照类别构建了一颗数,然后再相同类别里面去做比对,计算。
那么在这里我要强调的点就是,我们对于,那个阈值的调整。因为流程是这样的:
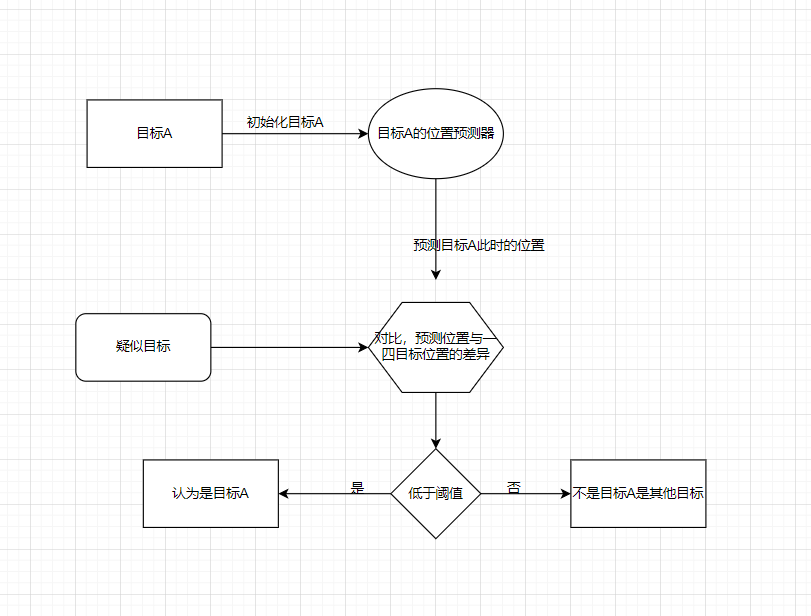
所以这个阈值的选定很重要,同时还有其他的参数。此外对于复杂目标来说,识别算法识别出来的目标框可能也存在波动。所以,这个就要求识别算法需要很精准。博主也做了简单测试,识别人的话效果比较差,识别其他的效果还是可以的,至少统计是ok的。
完整代码
代码
那么接下来就是万众期待的完整代码了。
首先项目结构的话比较简单:
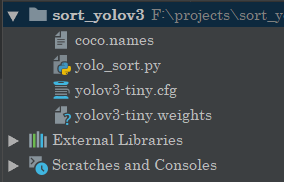
所以可以自己去下载对应的文件。
核心的是这个运行文件:
import cv2
import numpy as np
import gc
import copy
#基于卡尔曼滤波器的目标轨迹预测器
class ObjectTrackerKF:
def __init__(self, x_init, y_init, dt=1, sigma=10):
self.dt = dt
# 状态向量,包含位置和速度信息
self.state = np.array([[x_init], [y_init], [0], [0]], np.float32)
# 系统矩阵,将状态向量映射为下一时刻的状态向量
self.A = np.array([
[1, 0, self.dt, 0],
[0, 1, 0, self.dt],
[0, 0, 1, 0],
[0, 0, 0, 1]], np.float32)
# 测量矩阵,将状态向量映射为测量向量
self.H = np.array([
[1, 0, 0, 0],
[0, 1, 0, 0]], np.float32)
# 过程噪声,表示模型中未考虑的外部因素产生的偏差
self.Q = np.array([
[self.dt ** 4 / 4, 0, self.dt ** 3 / 2, 0],
[0, self.dt ** 4 / 4, 0, self.dt ** 3 / 2],
[self.dt ** 3 / 2, 0, self.dt ** 2, 0],
[0, 0, 0, self.dt ** 2]], np.float32) * sigma ** 2
# 测量噪声,表示测量器的误差
self.R = np.array([
[1, 0],
[0, 1]], np.float32) * sigma ** 2
# 卡尔曼滤波器初始化
self.kf = cv2.KalmanFilter(4, 2, 0)
self.kf.statePost = self.state
self.kf.transitionMatrix = self.A
self.kf.measurementMatrix = self.H
self.kf.processNoiseCov = self.Q
self.kf.measurementNoiseCov = self.R
def predict(self):
self.state = self.kf.predict()
return self.state[:2].reshape(-1)
def update(self, x, y):
self.kf.correct(np.array([[x], [y]], np.float32))
return self.state[:2].reshape(-1)
#基于yolo的目标检测器
class YoloDetect():
def __init__(self,model_source="yolov3-tiny.weights",mode_cfg="yolov3-tiny.cfg",
class_file="coco.names"
):
self.net = cv2.dnn.readNet(model_source,mode_cfg)
self.classes_file = open(class_file, "r")
self.classes = [line.strip() for line in self.classes_file.readlines()]
def show(self,frame,item):
class_name = self.classes[item.get("class_id")]
text = "{}".format(class_name)
cv2.rectangle(frame, (item.get("x"), item.get("y")), (item.get("x") + item.get("w"), item.get("y") + item.get("h")), (0, 255, 0), 2)
cv2.putText(frame, text, (int(item.get("x")), int(item.get("y")) - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
return frame
def detect(self, frame, conf_thresh=0.2, nms_thresh=0.45):
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416), swapRB=True, crop=False)
self.net.setInput(blob)
outs = self.net.forward(self.net.getUnconnectedOutLayersNames())
# 对检测结果进行非极大值抑制
boxes, scores, class_ids = [], [], []
for out in outs:
for detection in out:
confidence = detection[4]
if confidence > conf_thresh:
c_x, c_y, w, h = list(map(int, detection[:4] * np.array([frame.shape[1], frame.shape[0], frame.shape[1], frame.shape[0]])))
x = int(c_x - w / 2)
y = int(c_y - h / 2)
boxes.append([x, y, w, h])
scores.append(float(confidence))
class_ids.append(np.argmax(detection[5:]))
indices = cv2.dnn.NMSBoxes(boxes, scores, conf_thresh, nms_thresh)
items = []
# 只保留NMS过后的检测结果
for index in indices:
item = {"class_id": class_ids[index], "x": boxes[index][0], "y": boxes[index][1], "w": boxes[index][2], "h": boxes[index][3],
"class_name": self.classes[int(class_ids[index])]}
items.append(item)
return items
class MulObjectTracker():
def __init__(self,w=640,h=480,thorslde=0.4):
#统计当前出现的不同的类别的数量
self.counts = {}
#当前正在更正的跟踪器
self.objectPres = {}
#当前正在跟踪的item
self.track_items = {}
self.thorslde = thorslde
self.w = w
self.h = h
def __add_tracker(self,item):
class_name = item.get("class_name")
#添加一个目标跟踪,同时,对应的计数器累加
class_trackers = self.objectPres.get(class_name,[])
ID = len(class_trackers)
x,y = item.get("x"),item.get("y")
tracker_pre = ObjectTrackerKF(x,y)
tracker_pre.ID = ID
tracker_pre.hit = True
class_trackers.append(tracker_pre)
self.objectPres[class_name] = class_trackers
#同时完成计数统计
class_count = self.counts.get(class_name,0)
self.counts[class_name] = class_count+1
#对当前的item记录
class_items = self.track_items.get(class_name,[])
class_items.append(item)
self.track_items[class_name] = class_items
def lookdown(self,x,y,x_p,y_p):
# 判断是不是同一个
x,y,x_p,y_p = x/self.w,y/self.h,x_p/self.w,y_p/self.h
dist = np.linalg.norm([x-x_p,y-y_p])
if(dist<=self.thorslde):
return True
def track(self,items):
#此时我们会进行一次操作
for item in items:
class_name = item.get("class_name")
class_tracks = self.objectPres.get(class_name,None)
class_items = self.track_items.get(class_name)
if(not class_tracks):
self.__add_tracker(item)
else:
for i in range(len(class_tracks)):
track = class_tracks[i]
x_p,y_p = track.predict()
x,y = item.get("x"),item.get("y")
if(self.lookdown(x,y,x_p,y_p)):
#如果满足这个定义,那么说明是同一个目标
track.update(x,y)
c_it = class_items[i]
c_it["x"] = x
c_it["y"] = y
track.hit = True
else:
#没有满足那就创建去
self.__add_tracker(item)
self.__gc()
def __gc(self):
for class_name in self.objectPres.keys():
class_tracks = self.objectPres.get(class_name,[])
class_items = self.track_items.get(class_name,[])
dels_tr = []
dels_cl = []
indexs = []
for i in range(len(class_tracks)):
if(class_tracks[i].hit==False):
indexs.append(i)
dels_tr.append(class_tracks[i])
dels_cl.append(class_items[i])
else:
class_tracks[i].hit = False
#确保一定被回收了
class_items=self.__romve(class_items,indexs)
class_tracks=self.__romve(class_tracks,indexs)
self.objectPres[class_name] = class_tracks
self.track_items[class_name] = class_items
for dels_t in dels_tr:
del dels_t
gc.collect()
for dels_c in dels_cl:
del dels_c
gc.collect()
def __romve(self,x,idxs):
if(len(idxs)==0):
return x
j = 0
res = []
for i in range(len(x)):
if(j<len(idxs) and i!=idxs[j]):
res.append(x[i])
else:
j+=1
return res
def show(self,frame):
for class_name in self.track_items.keys():
class_items = self.track_items.get(class_name, [])
for i in range(len(class_items)):
item = class_items[i]
text = "{}:ID({})".format(class_name,i)
cv2.rectangle(frame, (item.get("x"), item.get("y")), (item.get("x") + item.get("w"), item.get("y") + item.get("h")), (0, 255, 0), 2)
cv2.putText(frame, text, (int(item.get("x")), int(item.get("y")) - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
return frame
if __name__ == '__main__':
cap = cv2.VideoCapture(0)
yolo_d = YoloDetect()
mtracker = MulObjectTracker()
while True:
ret, frame = cap.read()
results = yolo_d.detect(frame,conf_thresh=0.4)
mtracker.track(results)
frame = mtracker.show(frame)
cv2.imshow("frame", frame)
print(mtracker.counts)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
那么之后的话,你可以进行其他的操作了。
运行结果如下:(视频就不展示了,可以自己去测试)
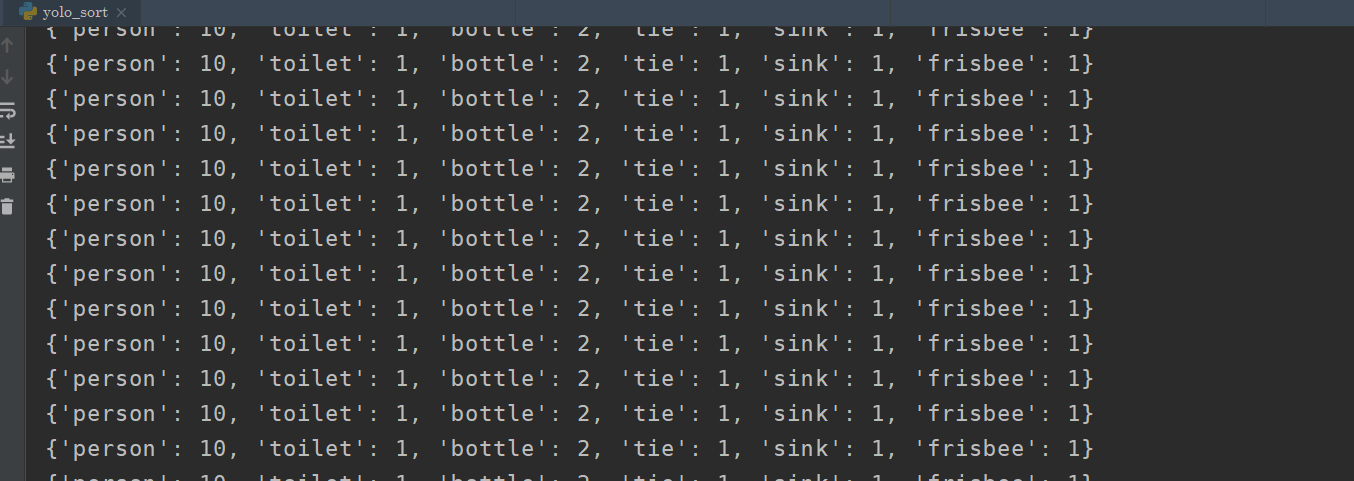
总结
ok,以上就是全部内容。
此外关于操作系统的那部分更新的话,本来是打算按照书上的来,一天一天更新的。但是发现,太麻烦了,而且实话实话,每一天的内容不多。而且最近还在复习数据结构和期末作业,所以嘛,就不一天一天来,而是一个阶段一个阶段来。虽然初期阅读汇编很枯燥,不过还好,那么本书《30天自制操作系统》作为引导确实不错。加上书上的代码和GPT,学习起来还不错感觉。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结