您现在的位置是:首页 >技术杂谈 >Delving into Shape-aware Zero-shot Semantic Segmentation(CVPR2023)网站首页技术杂谈
Delving into Shape-aware Zero-shot Semantic Segmentation(CVPR2023)
文章目录
摘要
由于大规模视觉语言预处理取得了令人瞩目的进展,最近的识别模型可以以零样本和开放集的方式对任意对象进行分类,并且具有令人惊讶的高精度。然而,将这一成功转化为语义分割并非易事,因为这种密集的预测任务不仅需要准确的语义理解,还需要精细的形状描绘,并且现有的视觉语言模型是用图像级语言描述训练的。为了弥合这一差距,我们在本研究中追求基于形状零样本语义分割。
本文要点
- 利用自监督像素特征构建的拉普拉斯矩阵的特征向量来提高形状感知
- 使用不同主干在不同数据集上实现的性能增益
- 得出了几个有趣且结论性的观察结果:促进形状感知的好处与掩码紧凑性和语言嵌入局部性高度相关
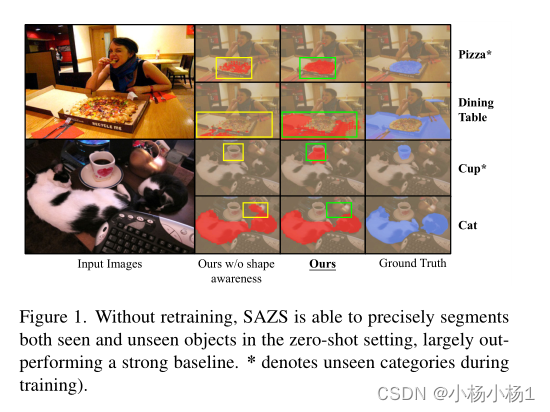
本文方法
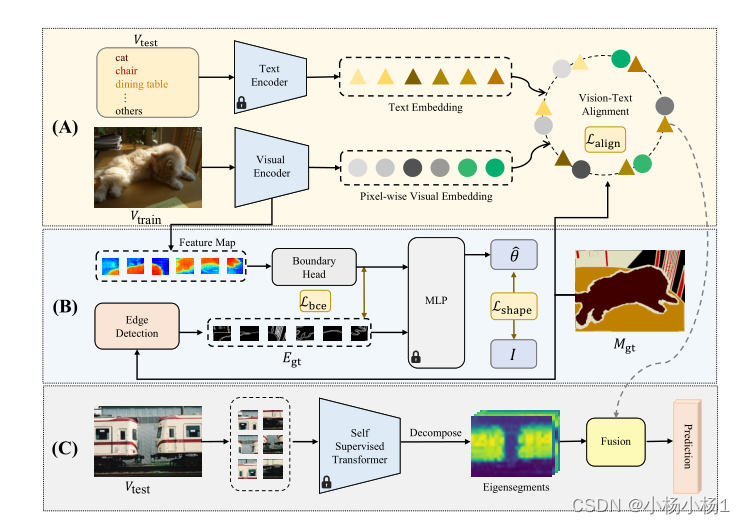
SAZS框架概述。SAZS解决了零样本语义分割的任务,其目的是通过开放集类别分割测试集图像Vtest,而无需额外的网络训练。在训练期间
(A)根据标签语义图Mgt,将输入图像Vtrain转换为与训练类别Ttrain的文本嵌入对齐的逐像素视觉嵌入。文本嵌入由CLIP的预训练文本编码器获得,并用作CLIP特征空间的优化锚
(B) 为了聚合输入图像中包含的形状先验,SAZS通过比较标签边界和视觉编码器的边界头的预测,联合训练边界检测的约束任务。
(C) 在推理过程中,为了减少可见类别和不可见类别之间的领域差距,SAZS将神经网络的像素预测与通过非学习获得的本征段相融合
Pixel-wise Vision-Language Alignment
比较共享特征空间中像素特征和不同文本锚定特征之间的距离是一种简单的零样本语义分割方法。然而,尽管先驱工作CLIP为视觉和文本输入引入了共享特征空间,但图像级CLIP视觉编码器对于密集预测任务是不可行的,因为图像中的精细细节以及像素之间的相关性都会丢失。在本节中,我们描述了我们解决这一问题的方法,方法是优化独立于CLIP的密集视觉编码器,并在训练过程中向CLIP特征空间中的文本锚点强制执行逐像素输出特征
我们使用扩展残差网络(DRN)和密集预测变换器(DPT)将图像编码为像素级嵌入。
文本编码器clip
图片文本对齐
为了实现视觉语言对齐,像素和相应语义类别之间的距离应最小化,而像素和其他类别之间的间距应最大化。在像素视觉和语言特征嵌入同一特征空间的假设下,我们利用余弦相似性作为特征之间的定量距离度量,并提出对齐损失作为所有像素的可见类上的交叉熵损失之和
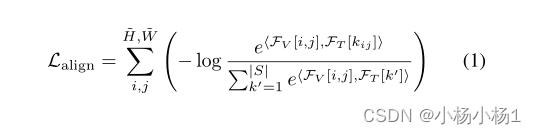
Shape Constraint
由于CLIP是在图像级任务上训练的,因此简单地利用CLIP特征空间中的先验可能不足以用于密集的预测任务。为了解决这个问题,我们引入了边界检测作为一项约束任务,以便视觉编码器能够聚合图像中包含的更精细的信息。受InverseForm的启发,我们通过优化标签边缘和特征图中的边缘之间的仿射变换来解决这一约束任务。
提取视觉编码器的中间层特征,并将它们分割成patch。一方面,通过在标签语义掩码上应用Sobel算子来获得patch内的标签边缘。另一方面,特征块由边界头处理。然后,我们使用预训练的MLP计算地面实况边缘和处理后的特征块之间的第i个块的仿射变换矩阵576θi。请注意,该MLP是使用边缘掩码预先训练的,并且在我们的方法的训练过程中没有进行优化。我们通过以下方式将该仿射变换矩阵优化为单位矩阵
Self-supervised Spectral Decomposition
以无监督的方式将输入图像分解为具有清晰边界的本征段,然后将这些本征段与融合模块中神经网络的预测融合。亲和矩阵的推导是谱分解的关键。首先利用来自预训练的自监督变换器(即DINO)的最后一层的注意力块的特征f,像素i和j之间的亲和力定义为:
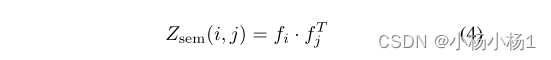
推理
给定一个用于推理的图像,我们首先使用预先训练的文本编码器CLIP对类别的短语进行编码,并获得C个类别的文本特征,每个类别由D维嵌入表示。然后,我们利用训练的视觉编码器来获得视觉特征图。最后的logits被计算为视觉特征图和文本特征之间的余弦相似性。同时,我们使用预先训练的DINO以无监督的方式提取语义特征,并计算顶部K个谱本征段Ek(在我们的实现中K=5)。最终的预测结果由融合模块生成,融合模块根据Ek和argmax的最大IoU(表示为ΦFUSE)从预测集合中进行选择。
实验结果
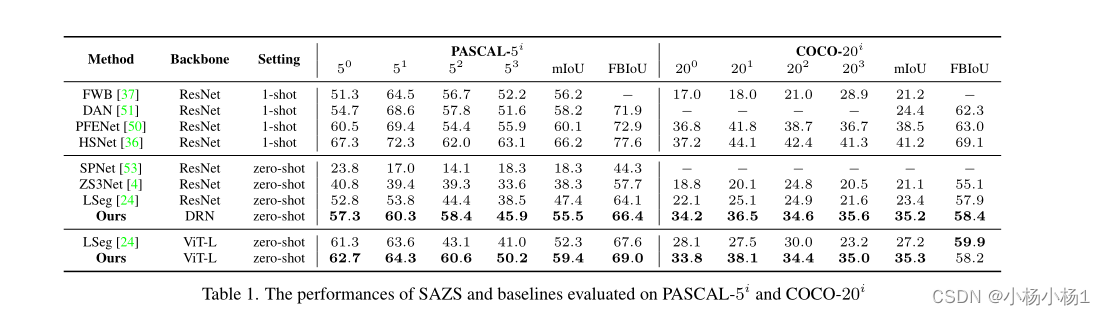
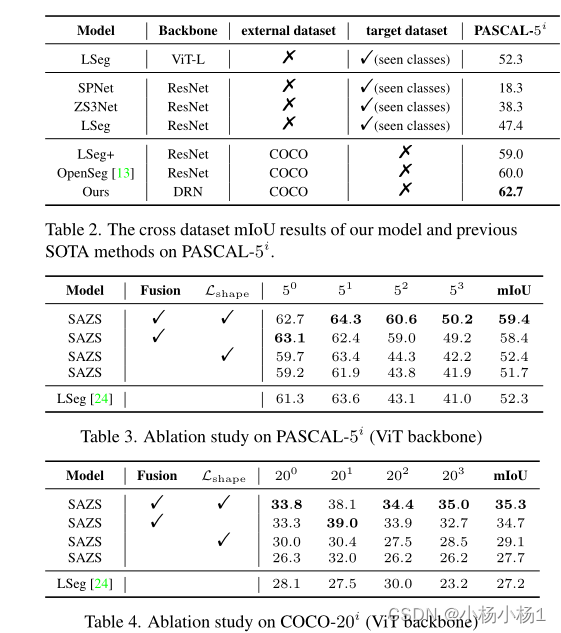
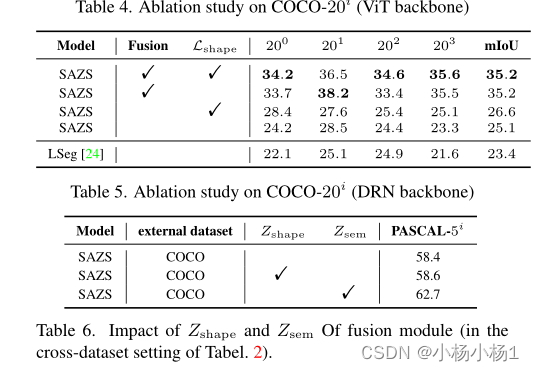






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结