您现在的位置是:首页 >学无止境 >C++入门:命名空间、函数重载、缺省参数网站首页学无止境
C++入门:命名空间、函数重载、缺省参数
目录
一:命名空间
1.命名空间的意义
① 在一个大型项目中,往往会有很多函数、类、变量等,如果不加以限制,不同的函数或类很可能会使用相同的名称,这样就会产生冲突。② 为了解决这个问题,C++引入了命名空间的概念,可以把相关的函数、类、变量等放在同一个命名空间下,从而避免冲突。③ 同时,命名空间还可以提高程序的可读性和可维护性,方便例如debug的时候定位问题。
2.命名空间的定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{} 中即为命名空间的成员。代码:
//命名空间 namespace stu { //命名空间中可以定义变量/函数/类型 int Add(int x, int y) { return x + y; } int goal = 50; struct Node { int data; struct Node* next; }; //命名空间可以嵌套定义 namespace teacher { //命名空间中可以定义变量/函数/类型 int Add(int x, int y) { return x + y; } int goal = 100; struct Node { int data; struct Node* next; }; } }注意:一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中。
3.如何使用命名空间中成员?
①加命名空间名称及作用域限定符代码:
#include <stdio.h> //命名空间 namespace stu { //命名空间中可以定义变量/函数/类型 int Add(int x, int y) { return x + y; } int goal = 50; struct Node { int data; struct Node* next; }; //命名空间可以嵌套定义 namespace teacher { //命名空间中可以定义变量/函数/类型 int Add(int x, int y) { return x + y; } int goal = 100; struct Node { int data; struct Node* next; }; } } int main() { printf("%d ", stu::goal); printf("%d ",stu::teacher::goal); } ②使用using将命名空间中某个成员引入
代码:
using stu::goal; //如果想使用嵌套空间中的goal,可以用using stu::teacher::goal //但是两个不能同时存在,否则会导致多次声明 int main() { printf("%d ",goal); }③使用using namespace命名空间名称引入(相当于把命名空间全部展开)
代码:
using namespace stu; //想访问嵌套空间的goal,可以using namespace stu::teacher //但是两个不能同时存在,否则goal不明确 int main() { printf("%d ",goal); }
小结
① C++中即使是一些比较重要的声明定义(比如与输出有关的cout),也是放在一个命名空间中的,在没有展开命名空间或者引入成员的情况下,cout是可以做变量,函数名的。
②如果要写一个较大的项目,上面三种使用命名空间中成员的方法直接引入命名空间(展开)的方式是非常不好的,很容易造成命名冲突(using namespace 命名空间)如果并不需要频繁使用,我们可以用加命名空间名称及作用域限定符的方式来使用
(命名空间::成员)
如果只是需要频繁使用某一个成员,我们可以使用using将命名空间中单个成员引入
(using 命名空间::成员)
③可以存在多个同名的命名空间,编译器最后会把他们合成一个。
(比如定义两个同名命名空间,展开之后两个空间中的成员都可以使用)
二:C++的输入输出
代码:
说明:
①使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件以及按命名空间使用方法使用std。
②这里涉及到了类和对象、运算符重载、IO流、函数重载的知识,大家只需要先有个大致印象,后续的学习会一一解答这里的疑问。
●cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在< iostream >头文件中。
● <<是流插入运算符, >> 是流提取运算符。●使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动控制格式。C++的输入输出可以自动识别变量类型(本质是函数重载)③早期标准库将所有功能在全局域中实现,声明在.h后缀的头文件中,使用时只需包含对应头文件即可,后来将其实现在std命名空间下,为了和C头文件区分,也为了正确使用命名空间, 规定C++头文件不带.h;旧编译器(vc 6.0)中还支持<iostream.h>格式,后续编译器已不支持,因此推荐使用<iostream>+std的方式。

三:函数重载
1.概念
是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
2.实例
代码:
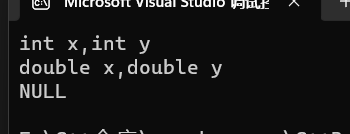
#include <iostream> using namespace std; 函数重载 void fun(int x, int y) { cout << "int x,int y" << endl; } void fun(double x, double y) { cout << "double x,double y" << endl; } void fun() { cout << "NULL" << endl; } int main() { fun(2, 0); //参数类型不同 fun(2.0, 0.0); //参数个数不同 fun(); return 0; }
注意:函数返回值不同不构成函数重载。
3.为什么C++能支持函数重载而C不行?
其实主要就是一句:C++有独特的函数名修饰规则。
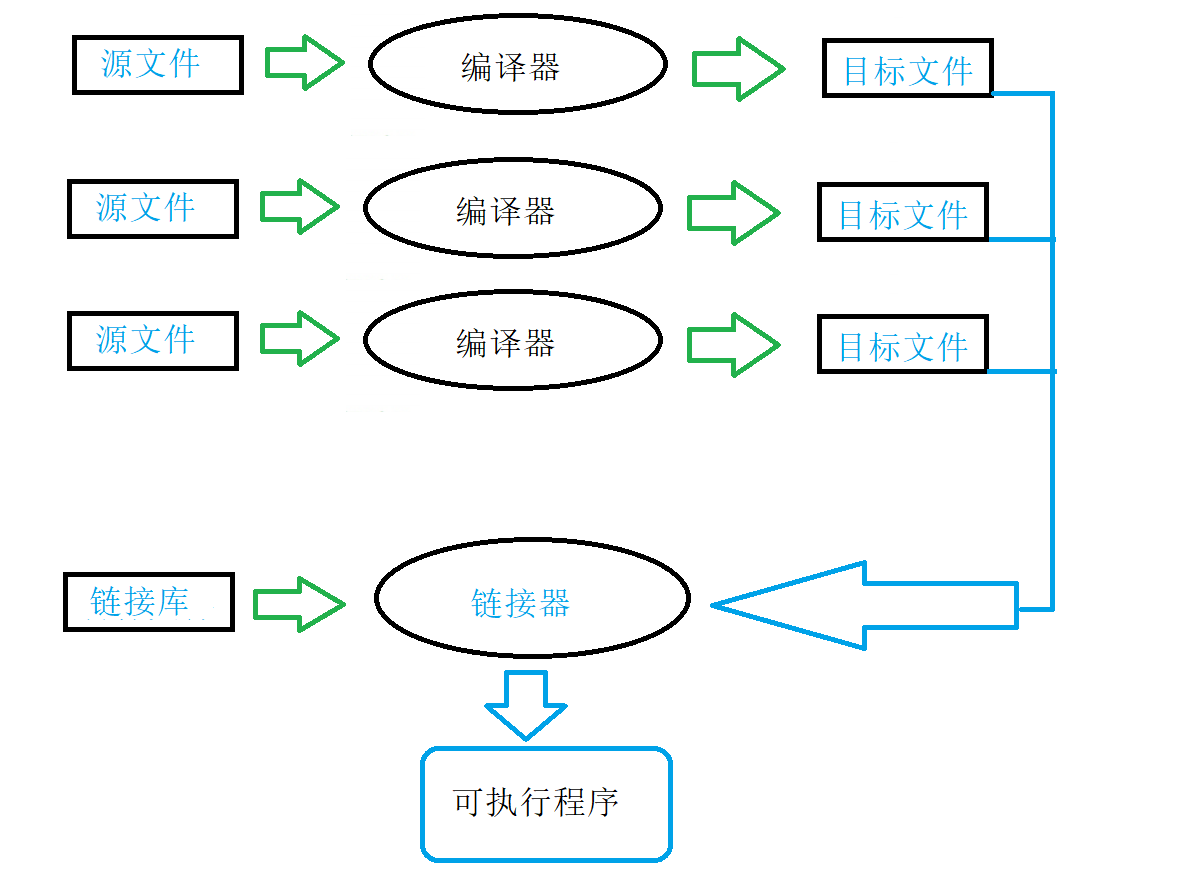
一个C/C++程序的形成需要经过预处理、编译、汇编、链接。
①预处理:进行宏的替换、头文件展开、注释的删除(空格替换)。
②编译:将代码转化为汇编代码(这个阶段主要负责语法分析、符号汇总、
词法分析、 语义分析)。
③汇编:将汇编代码转化为二进制机器指令,生成符号表。
④链接:汇编完成后会把对应源文件生成目标文件,链接阶段就是把这些目标文件
进行链接(这个过程很复杂)。
我们并不需要很在意这个过程的实现细节,要点在符号汇总和生成符号表。
【1】先看一段C语言代码
main.c文件中没有Add函数的定义,但是存在声明,没有语法错误,可以通过编译。
Add.c文件中包含了Add函数的具体实现。
汇编完成后这两个源文件会生成对应符号表。
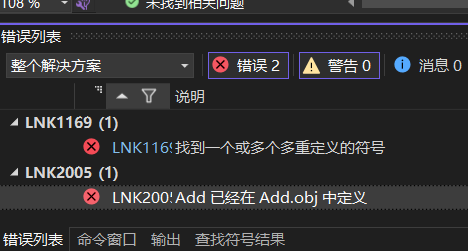
链接的过程中会进行符号表的合并,在main.obj(main.c汇编完成后生成的目标文件)中没有Add函数的定义,但是Add.obj中有,最后合并为_Add(0x200),可以找到Add函数的地址进行调用。
在上述基础上如果我们多定义一个同名函数,生成的符号表中两个函数地址都是有效的,无法区分应该调用那个,就会导致链接错误。
我们不难发现,C语言没办法处理这种情况是因为符号名相同导致的冲突,如果我们在生成符号表的时候依据函数参数的不同来生成不同符号名,不就可以解决这种情况了吗?
【2】我们把上面的情况放到C++
通过这里就理解了C语言没办法支持重载,因为同名函数没办法区分。而C++是通过函数修饰规则来区分,只要参数不同,修饰出来的名字就不一样,就支持了 重载。
其中返回值并没有纳入修饰规则,因此只有返回值不同无法构成函数重载。




四:缺省参数
1.概念
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
2.实例
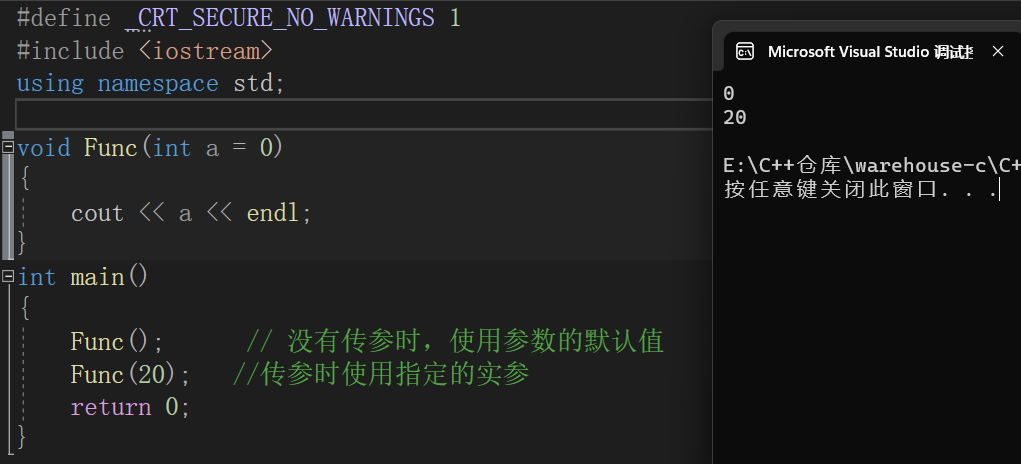
3.缺省参数分类
【1】全缺省参数
【2】半缺省参数
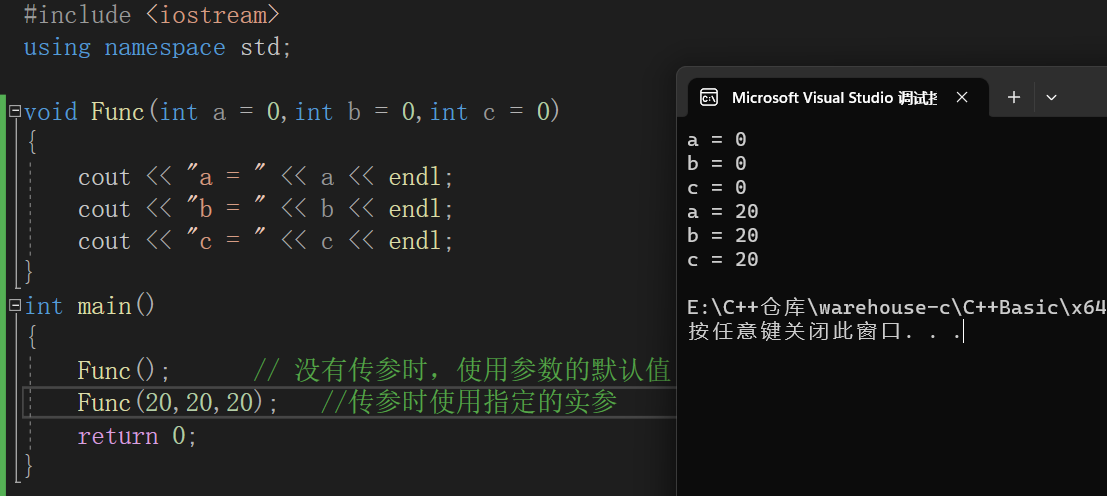
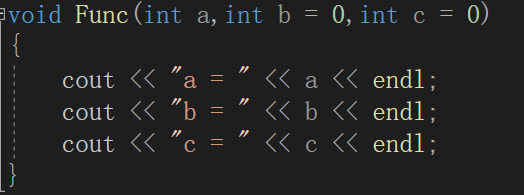
4.注意点
①半缺省参数必须从右往左依次来给出,不能间隔着给
②缺省参数不能在函数声明和定义中同时出现,建议缺省参数只在声明中设定
③缺省值必须是常量和全局变量
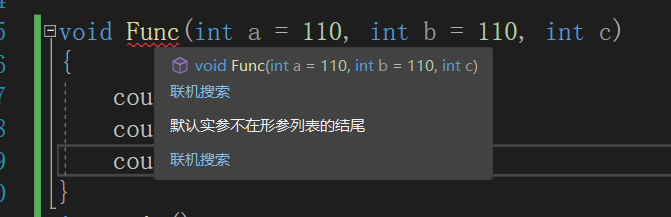
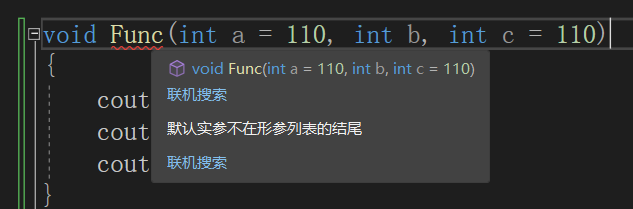








站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结