您现在的位置是:首页 >学无止境 >一次etcd变更引发的惨案网站首页学无止境
一次etcd变更引发的惨案
问题描述
在做etcd的数据变更时候,etcd在组成集群的时候出现leader不断切换问题,导致集群不稳定,都面将不健康的etcd节点踢出,只剩etcd单节点,后面将踢出的etcd节点重新加入现有etcd,导致etcd集群奔溃,期间部分服务发生了重启(这个是后面用etcd快照做恢复,产生问题的起因)后面使用etcd备份的快照进行恢复,k8s集群恢复正常,但是服务部分可访问,部分无法访问。
处理过程
当时尝试对不可访问的服务进行重启,发现即使重启,仍然无法解决服务不可访问的问题,开始优先恢复ku8集群关键组件的可用性,发现有状态服务,有些在组成集群的时候,会报错,无法进行域名解析,开始着手查看coredns服务,发现coredns服务pod状态都是正常的, 但是请求coredns的svc是有三分之一成功的,发现只有一个coredns可用,重启另外两个不能正常访问的coredns,发现也不行,只能调整coredns副本数为1,暂时保持一个可用的,让整个集群可以域名解析,后面发现istiod和calico这些组件也是不正常,重启业务使pod恢复正常使用,查看这两个的服务日志都是报如下错误:
Failed to initialize Calico datastore error=Get “https://169.169.0.1:443/apis/crd.projectcalico.org/v1/clusterinformations/default”: dial tcp 169.169.0.1:443: connect: no route to host
发现应是连接不上apiserver了,但是检查master节点这些都是正常的,日志也并没有异常,开始查看无法访问服务的iptables规则,发现iptables规则转发是有问题的,

 如上图中coredns已经和iptables转发规则不一致了,这个时候去访问肯定就有问题了。
如上图中coredns已经和iptables转发规则不一致了,这个时候去访问肯定就有问题了。
还有如下图中,nginx被转发到了zookeeper上
 造成这一切问题的原因就是因为在etcd进行恢复过程中,集群中有部分服务重启,然后拿着之前备份的etcd快照进行恢复的时候,就会产生脏数据,实际数据和现有不一致了。
造成这一切问题的原因就是因为在etcd进行恢复过程中,集群中有部分服务重启,然后拿着之前备份的etcd快照进行恢复的时候,就会产生脏数据,实际数据和现有不一致了。
解决办法
systemctl stop kubelet kube-proxy
systemctl stop docker
iptables --flush
iptables -tnat --flush
systemctl start kubelet kube-proxy
systemctl start docker
然后重启下集群所有pod,让其重新更新集群数据到etcd里面,下发新的iptables转发规则。
补充说明
k8s集群中etcd的快照备份,在etcd集群发生不可逆的恢复时,用快照可以将集群恢复到某一时刻,这个肯定没法保证是最新集群数据,不仅要考虑到etcd的恢复,更要考虑到集群中iptables规则发生的变化,如下图:
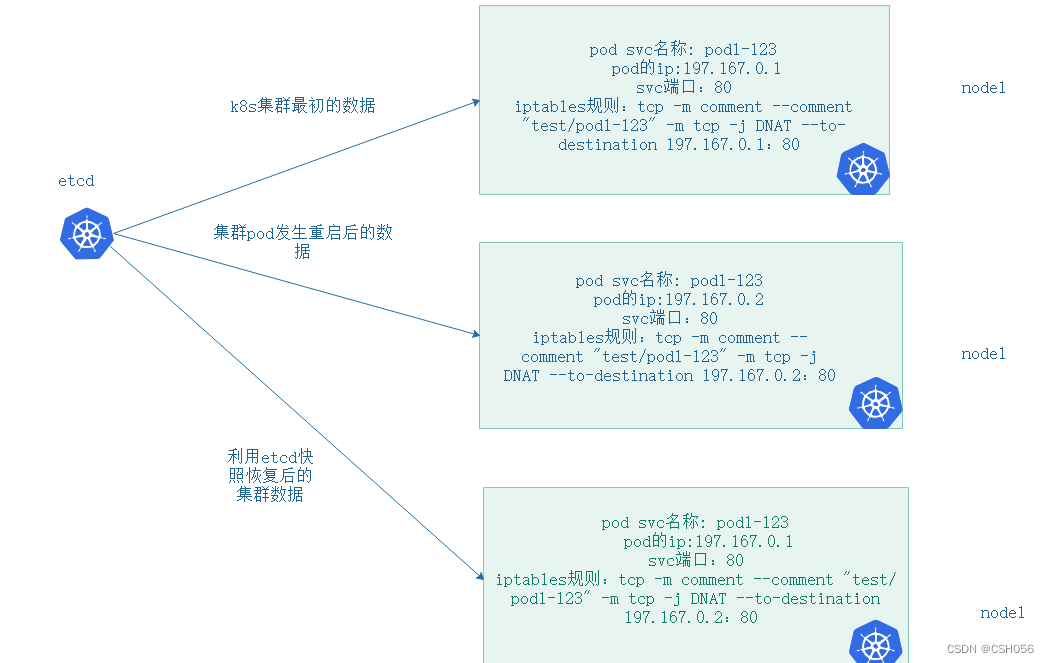 如上图可以看出,k8s集群最初的数据和集群重启后pod的数据已经发生了变化,主要体现在pod ip 和防火墙规则上,但是后续利用etcd的快照进行恢复后,pod整体状态肯定恢复到跟k8s集群最初的数据一样了,因为就是用这一时刻的快照进行恢复的,唯一区别是iptables规则仍然是集群pod发生重启后更新的规则,这就导致我们肯定无法正常访问服务了。
如上图可以看出,k8s集群最初的数据和集群重启后pod的数据已经发生了变化,主要体现在pod ip 和防火墙规则上,但是后续利用etcd的快照进行恢复后,pod整体状态肯定恢复到跟k8s集群最初的数据一样了,因为就是用这一时刻的快照进行恢复的,唯一区别是iptables规则仍然是集群pod发生重启后更新的规则,这就导致我们肯定无法正常访问服务了。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结