您现在的位置是:首页 >技术交流 >redis总结网站首页技术交流
redis总结
一、缓存穿透
大量查询不存在的数据,从而跳过缓存直接查询数据,造成数据库崩溃
解决方案
1.对空值进行缓存
就是将不存在的数据访问结果, 也存储到缓存中并设置过期时间,避免缓存访问的穿透。最终不存在商品数据的访问结果也缓存下来。有效的避 免缓存穿透的风险。
缺点:占用内存,可能会发生不一致的问题,一般情况redis查询为空还是会重新查询数据库的,所以不推荐。
2. 布隆过滤器
将数据库中所有的查询条件,放入布隆过滤器中,当一个查询请求过来时,先经过布隆过滤器进行查,如果判断请求查询值存在,则继续查;如果判断请求查询不存在,直接丢弃。
二、缓存雪崩
redis中大量的key集体过期
解决方案
1. 在设置具体的缓存生效时间的时候, 加上一个随机的区间因子, 比如 说 5~10 分钟之间来随意选择失效时间;
2. 提前预估 DB 能力, 如果缓存挂掉,数据库仍可以在一定程度上抗住流量 的压力 这三个策略能够有效的避免短时间内,大批量的缓存失效的问题。
三、缓存击穿
redis中的某个热点key过期,但是此时有大量的用户访问该过期key
解决方案
1.使用互斥锁
就是在缓存失效的时候(判断拿出来的值为空),不是立即去查询数据库,
而是先使用缓存工具的某些带有操作成功返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
public String get(key) {
String value = redis.get(key);
if (value == null) { //代表缓存值过期
//设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可
sleep(50);
get(key); //重试
}
} else {
return value;
}
}
四、双写一致性
1、延时双删
写数据库之前删除一次,写完数据库后,隔500ms再删除一次。
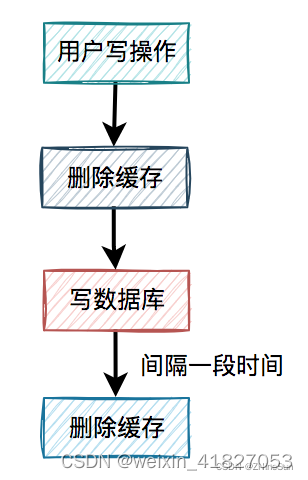
有了缓存删除方案之后,我们在回顾一下高并发下的场景问题:
1.请求d先过来,把缓存删除了。但由于网络原因,卡顿了一下,还没来得及写数据库。
2.这时请求c过来了,先查缓存发现没数据,再查数据库,有数据,但是旧值。
3.请求c将数据库中的旧值,更新到缓存中。
4.此时,请求d卡顿结束,把新值写入数据库。
5.一段时间之后,比如:500ms,请求d将缓存删除。 这样看确实解决了缓存不一致的问题,但是为什么我们非得等一会在删除缓存呢? 请求d卡顿结束,把新值写入数据库后,请求c将数据库中的旧值,更新到缓存中。
此时,如果请求d删除太快,在请求c将数据库中的旧值更新到缓存之前,就已经把缓存删除了,这次删除就没任何意义。我们必须要搞清楚,我们之所以要再删除一次缓存的原因是因为c请求导致缓存中更新了数据库中旧值,我们需要把这个旧值删除掉,所以必须要在请求c更新缓存之后,再删除缓存,才能把旧值及时删除了,删除删除太快,可能后面。现在解决了一个问题之后,又遇到一个问题:如果第二次删除缓存时,删除失败了该怎么办呢?
2、通过定时任务解决缓存删除失败的问题
在高并发的业务场景中,mq(消息队列)是必不可少的技术之一。它不仅可以异步解耦,还能削峰填谷。对保证系统的稳定性是非常有意义的。
mq的生产者,生产了消息之后,通过指定的topic发送到mq服务器。然后mq的消费者,订阅该topic的消息,读取消息数据之后,做业务逻辑处理。
使用mq重试的具体方案如下:
当用户操作写完数据库,但删除缓存失败了,产生一条mq消息,发送给mq服务器。
mq消费者读取mq消息,重试5次删除缓存。如果其中有任意一次成功了,则返回成功。如果重试了5次,还是失败,则写入死信队列中。
当然在该方案中,删除缓存可以完全走异步。即用户的写操作,在写完数据库之后,不用立刻删除一次缓存。而直接发送mq消息,到mq服务器,然后有mq消费者全权负责删除缓存的任务。
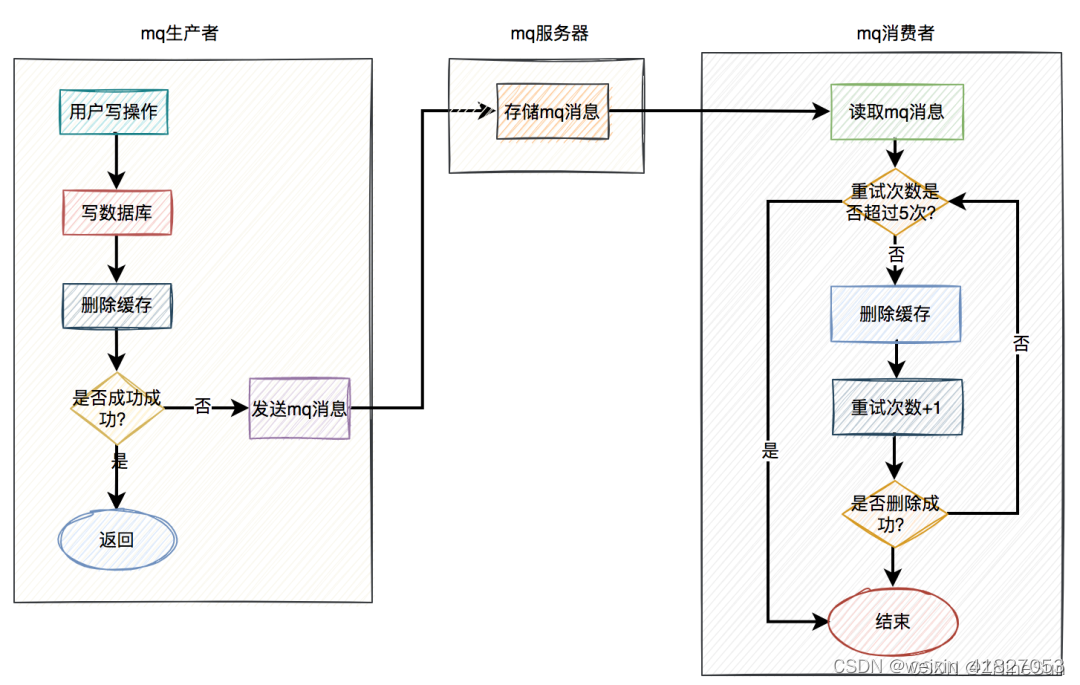
因为mq的实时性还是比较高的,因此改良后的方案也是一种不错的选择。
五、redis 持久化机制(怎么保证 redis 挂掉之后再重启数据可以进行恢复)
RDB 快照持久化 -每隔一段时间备份内存的数据到磁盘上
Redis 可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis 创建快照之后,可以对快照进行备 份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis 主从结构,主要用来提高 Redis 性 能),还可以将快照留在原地以便重启服务器的时候使用。
AOF(append-only file)持久化
与快照持久化相比,AOF 持久化 的实时性更好。默认情况下 Redis 没有开启 AOF(append only file)方式的持久化,可以通过 appendonly 参数开启:appendonly yes
开启 AOF 持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入硬盘中的 AOF 文件。AOF 文件 的保存位置和 RDB 文件的位置相同,都是通过 dir 参数设置的,默认的文件名是 appendonly.aof。
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式,它们分别是:
appendfsync #每次有数据修改发生时都会写入 AOF 文件,这样会严重降低 Redis 的速度
appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
appendfsync no #让操作系统决定何时进行同步
六、redis 基本数据结构
string incrBy生成唯一主键,用作计数器,统计在线人数等等,可以存储二进制数据如使用它来存储图片等。
hash 存放键值对,一般可以用来存某个对象的基本属性信息,例如,用户信息,商品信息等
list 链表,列表类型,可以用于实现消息队列,也可以使用它提供的range命令,做分页查询功能。
set 集合,可以用作去重功能,例如用户名不能重复等,另外,还可以对集合进行交集,并集操作,来查找某些元素的共同点
Sorted Set 有序集合 常用命令: zadd,zrange,zrem,zcard 等 和 set 相比,sorted set 增加了一个权重参数 score,
使得集合中的元素能够按 score 进行有序排列。 举例: 在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度 的消息排行榜)等信息,适合使用 Redis 中的 SortedSet 结构进行存储
遗留问题
redis的集合有没有限制,限制是多少
redis的1w条的插入和更新有什么区别
redis为什么效率高,线程,数据结构,网络模型,aio, nio, bio, 为什么这么设计?如何处理高并发






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结