您现在的位置是:首页 >技术杂谈 >Linux Ubuntu配置CPU与GPU版本tensorflow库的方法网站首页技术杂谈
Linux Ubuntu配置CPU与GPU版本tensorflow库的方法
本文介绍在Linux操作系统的发行版本Ubuntu中,配置可以用CPU或GPU运行的Python新版本深度学习库tensorflow的方法。
在文章Anaconda配置Python新版本tensorflow库(CPU、GPU通用)的方法(https://blog.csdn.net/zhebushibiaoshifu/article/details/129285815)以及新版本GPU加速的tensorflow库的配置方法(https://blog.csdn.net/zhebushibiaoshifu/article/details/129291170)中,我们已经介绍了Windows平台下,配置CPU、GPU版本的tensorflow库的方法;而在本文中,我们就介绍一下在Linux Ubuntu环境中,CPU与GPU版本tensorflow库的配置方法。
本文分文两部分,第1部分为CPU版本的tensorflow库的配置方法,第2部分则为GPU版本的tensorflow库的配置方法;如果大家的电脑有GPU,那么就直接跳过第1部分,从本文的第2部分开始看起就好。需要明确的是,本文的Python版本为3.10,是一个比较新的版本;但是如果大家的Python是其他版本也没问题,整体配置的思路都是一样的。
1 CPU版本
首先,我们介绍一下CPU版本的tensorflow库的配置方法。
配置CPU版本的tensorflow库可以说是非常简单。首先,建议大家按照文章Linux Ubuntu配置Anaconda与Python的方法(https://blog.csdn.net/zhebushibiaoshifu/article/details/130807267)中提及的内容,首先配置好Anaconda环境;其次,如果大家需要在虚拟环境中配置tensorflow库,那么就可以自行创建一个虚拟环境后开始后续的操作——我这里就直接在默认的环境,也就是base环境中加以配置了。关于Anaconda创建虚拟环境,大家可以参考文章Anaconda中Python虚拟环境的创建、使用与删除(https://blog.csdn.net/zhebushibiaoshifu/article/details/128334614),这里就不再赘述了。
我们可以通过在终端中输入如下的代码,查看当前Anaconda环境中的环境。
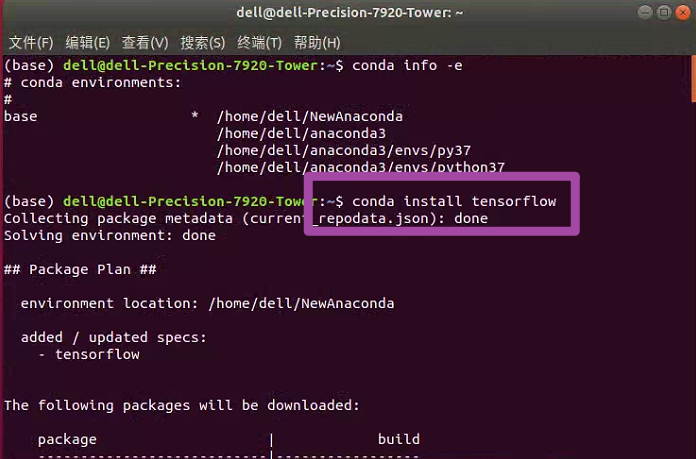
conda info -e
运行上述代码,将得到如下图所示的情况。其中,可以看到我这里因为没有创建虚拟环境,因此就是只有一个base环境。

随后,我们在终端中输入如下的代码,安装tensorflow库。
conda install tensorflow
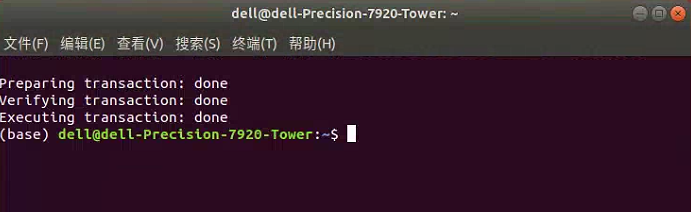
运行上述代码,我们将自动开始安装当前环境(也就是Python版本)支持的最新版本的tensorflow库;如下图所示。
安装完毕后,就将出现如下图所示的界面。
至此,我们就完成了CPU版本的tensorflow库的配置。我们按照文章新版本GPU加速的tensorflow库的配置方法(https://blog.csdn.net/zhebushibiaoshifu/article/details/129291170)中提及的方法,在Python中输入如下的代码,检验当前tensorflow库是否支持GPU运算。
import tensorflow as tf
print(tf.config.list_physical_devices("GPU"))
运行上述代码,如果得到如下图所示的一个空列表[],则表示当前tensorflow库并不支持GPU运算——当然这个是肯定的,我们这里配置的就是CPU版本的tensorflow库,自然是无法在GPU中加以运算了。
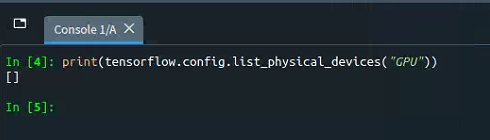
至此,tensorflow库也可以正常使用了,但是他只能支持CPU运算。这里有必要提一句,其实我们通过前述方法配置的tensorflow库,其自身原理上也是支持GPU运算的——因为在Linux操作系统中,从tensorflow库的1.15版本以后,就不再区分CPU与GPU版本了,只要下载了tensorflow库,那么他自身就是CPU与GPU都支持的;我们目前到此为止配置的tensorflow库之所以不能在GPU中加以运行,是因为我们还没有将GPU运算需要的其他依赖项配置好(或者是电脑中完全就没有GPU)。
2 GPU版本
接下来,我们介绍一下GPU版本的tensorflow库的配置方法。
2.1 NVIDIA Driver配置
首先,我们需要对NVIDIA驱动程序加以配置。NVIDIA驱动程序是用于NVIDIA显卡的软件,它可以控制NVIDIA显卡的功能和性能,并确保它们与操作系统和其他软件正常配合工作。
首先,我们可以先在终端中输入如下的代码。
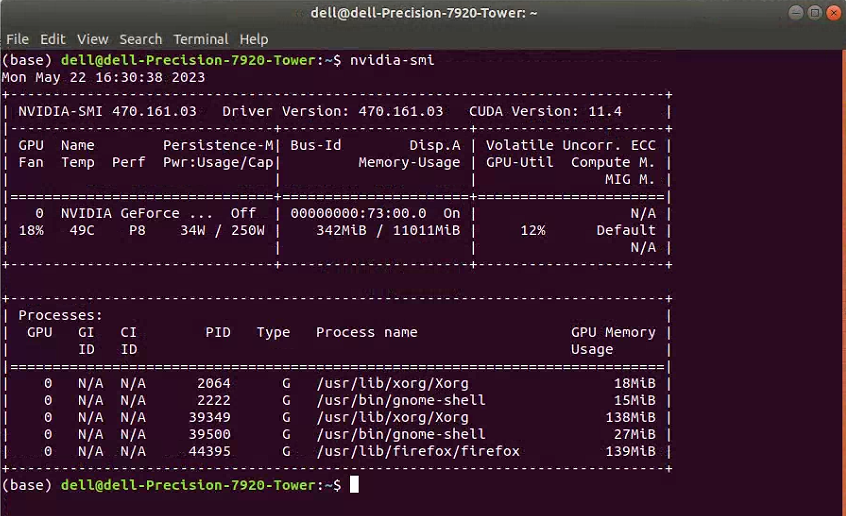
nvidia-smi
随后,正常情况下应该出现如下图所示的情况。如果大家此时出现的是其他情况,就表明要么没有安装任何NVIDIA驱动程序,要么是安装了NVIDIA驱动程序但是这一驱动的版本有问题。这里我们可以先不管,大家继续往下看即可。
接下来,我们就开始安装NVIDIA驱动程序。其中,这里提供3种不同的方法,但是建议大家用最后一种。
2.1.1 方法一(不推荐)
第1种方法,我们直接在终端中输入如下的代码即可。
sudo ubuntu-drivers autoinstall
一般情况下,这一代码将会自动下载或更新我们电脑中的驱动,其中NVIDIA驱动程序也会跟着一并下载或更新。但是这一方法我尝试之后发现,并没有效果,因此这一方法应该是和大家电脑的状态有关系,不一定百分之百成功,因此并不推荐。
2.1.2 方法二(不推荐)
第2种方法,是直接到NVIDIA驱动程序的官方网站中下载;但是这一方法比较麻烦,因此我这里也并不推荐。
首先,我们进入NVIDIA驱动程序的官方网站(https://www.nvidia.cn/Download/index.aspx?lang=cn),并在如下图所示的界面处,依据自己电脑中显卡的型号、电脑的系统等加以选择。

随后,点击“搜索”选项,将会出现最合适大家的NVIDIA驱动程序,并点击“下载”即可。

随后,大家在终端中,安装刚刚下载好的NVIDIA驱动程序即可。
2.1.3 方法三(推荐)
第3种方法,是最为推荐的方法。
首先,大家在终端中输入如下的代码。
ubuntu-drivers devices
随后,将出现如下图所示的界面;其中,出现recommended的NVIDIA驱动程序版本,就是我们电脑中最合适的版本;大家此时需要记录一下这个版本号,后续需要用到。
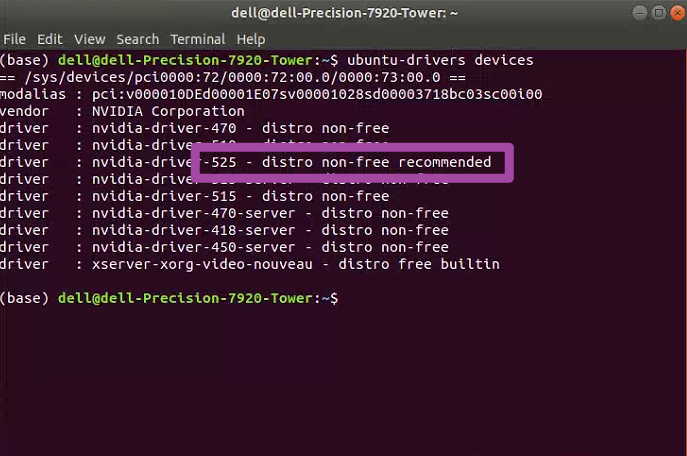
接下来,我们在终端中输入如下的代码。
sudo apt install nvidia-driver-525
其中,上述代码最后的525就是我们上图中,记录下来的版本号,大家依据自己的实际情况来修改上述代码即可。运行代码后,将出现如下图所示的情况,即这一版本的NVIDIA驱动程序将开始下载与安装。

如果大家随后的下载、安装都很顺利,那么久没事了;但是有的时候,会出现如下图所示的错误提示。
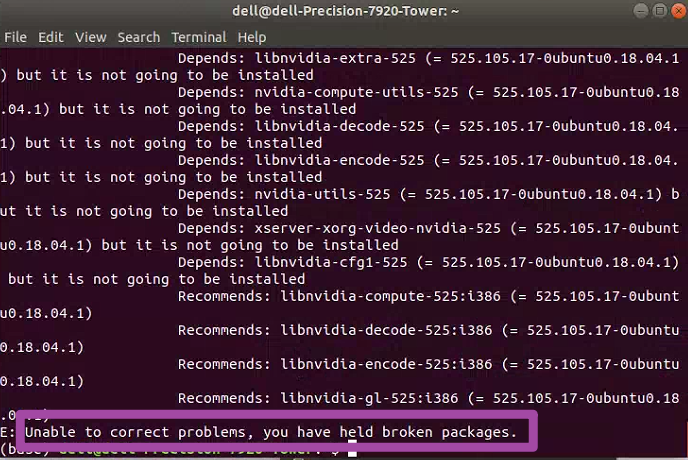
此时,表明我们电脑中原有的NVIDIA驱动程序与新下载的版本有了冲突,导致新的版本无法正常安装。此时,我们需要在终端中,依次输入如下的代码,记得每次输入一行即可。
sudo apt-get purge nvidia*
sudo apt-get purge libnvidia*
sudo apt-get --purge remove nvidia-*
sudo dpkg --list | grep nvidia-*
上述代码中,前3行表示删除原有的NVIDIA驱动程序及其相关内容,最后一句用来检测,原有的NVIDIA驱动程序是不是被删除干净了。如果大家出现如下图所示的情况,即输入上述最后一句代码后什么提示信息都没有出现,那么就说明原有的NVIDIA驱动程序已经删除干净了。
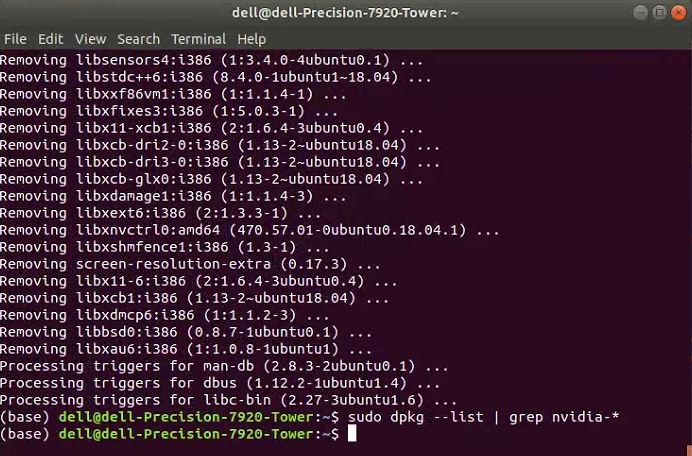
此时,我们可以再执行一次如下的代码。
ubuntu-drivers devices
但此时,和前文中不一样的是,或许可以看到出现recommended的NVIDIA驱动程序版本发生了变化,例如我这里不再是前面的525了,而是另一个版本;但是这里我们不用管这个变化,之后还是下载525版本即可。

接下来,我们还是运行以下代码。
sudo apt install nvidia-driver-525
其中,上述代码最后的525就是我这里的版本号,大家还是要记得修改一下。此时,我们就可以正常下载、安装指定版本的NVIDIA驱动程序了。
此时,我们再一次在终端中输入如下的代码。
nvidia-smi
随后,正常情况下应该出现如下图所示的情况。其中,可以留意一下下图的右上角,表示CUDA版本最高支持12.0,再新的版本就不支持了——当然,这个CUDA具体是什么,以及怎么配置,我们接下来会提到,这里就是先留意一下即可。

还有一点需要注意,如果输入前述代码后,出现的是如下图所示的情况,那么还是说明我们此时电脑中原有的NVIDIA驱动程序与新下载的版本有了冲突,大家重新执行一下前文中删除电脑中原有的NVIDIA驱动程序的3句代码即可。
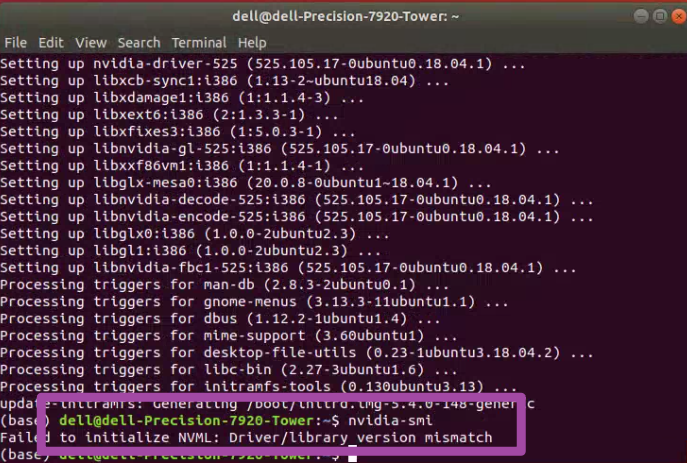
随后,我们还可以输入如下的代码。
nvidia-settings
如果出现如下图所示的情况,即一个新的名为“NVIDIA X Server Settings”的窗口被打开,即说明我们前述的配置没有问题。
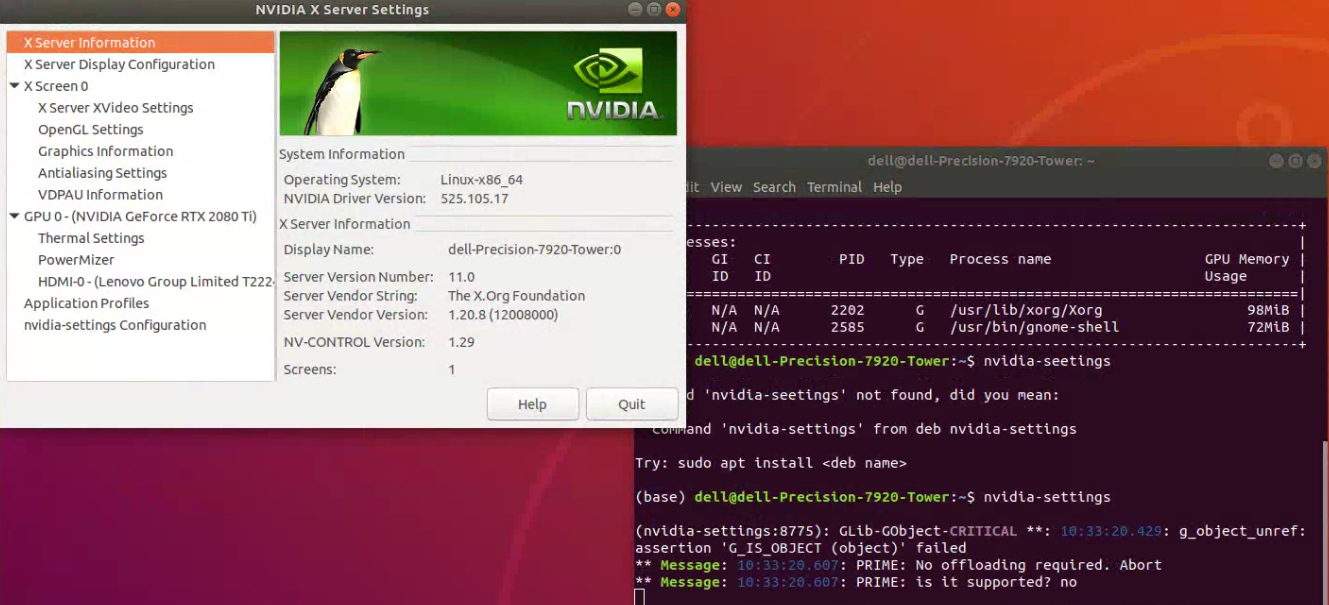
至此,我们完成了NVIDIA驱动程序的配置工作。
2.2 CUDA配置
接下来,我们进行CUDA的配置;CUDA是NVIDIA发明的一种并行计算平台和编程模型。
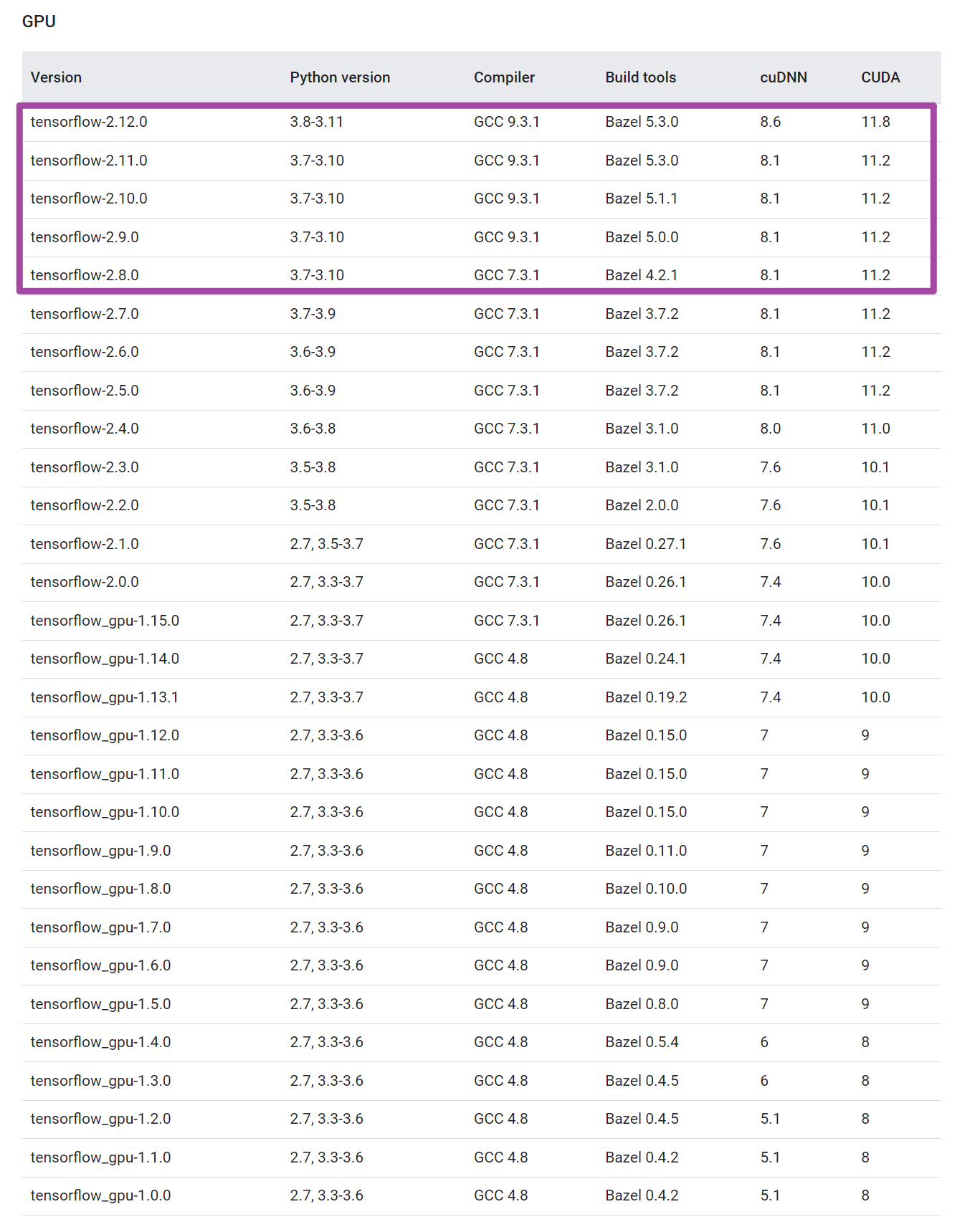
首先,我们需要到tensorflow库的官方网站(https://www.tensorflow.org/install/source)中,下拉找到如下图所示的tensorflow库版本与对应的CUDA、cuDNN版本匹配表格,并结合自己的Python版本,选择确定自己需要哪一个版本的tensorflow库,并进一步确定自己CUDA、cuDNN的版本。其中,如下图紫色框所示,由于我这里Python版本是3.10的,因此只能选择紫色框内的版本;随后,想着用新版本的tensorflow库,因此我就选择用第一行对应的CUDA、cuDNN版本了。
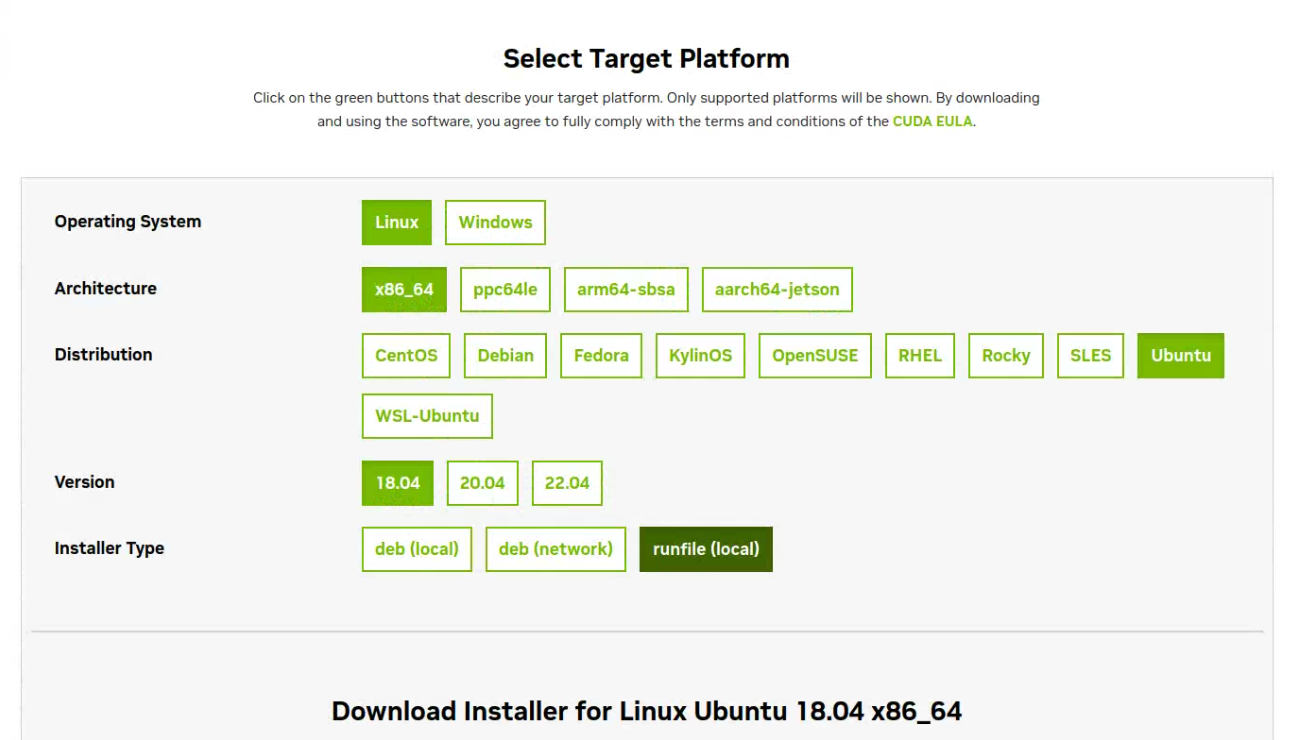
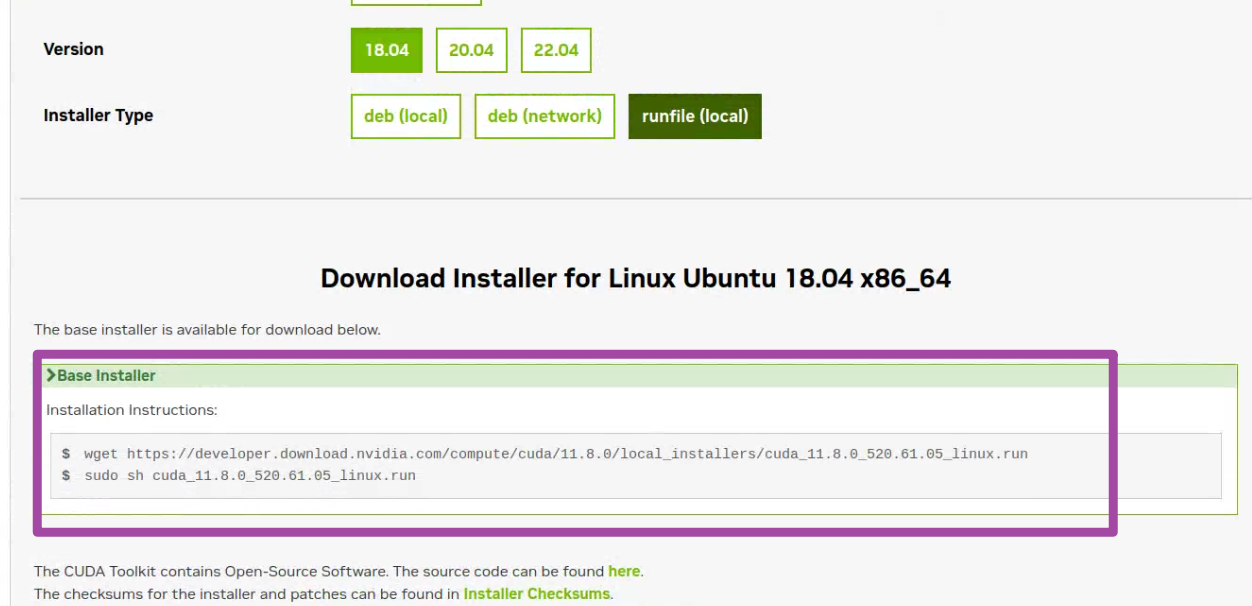
随后,我们到CUDA的官方网站(https://developer.nvidia.com/cuda-downloads)中,首先按照如下图所示的方法,基于自己电脑的型号选择对应的内容;其中,注意最后一个选项要选择runfile (local)。
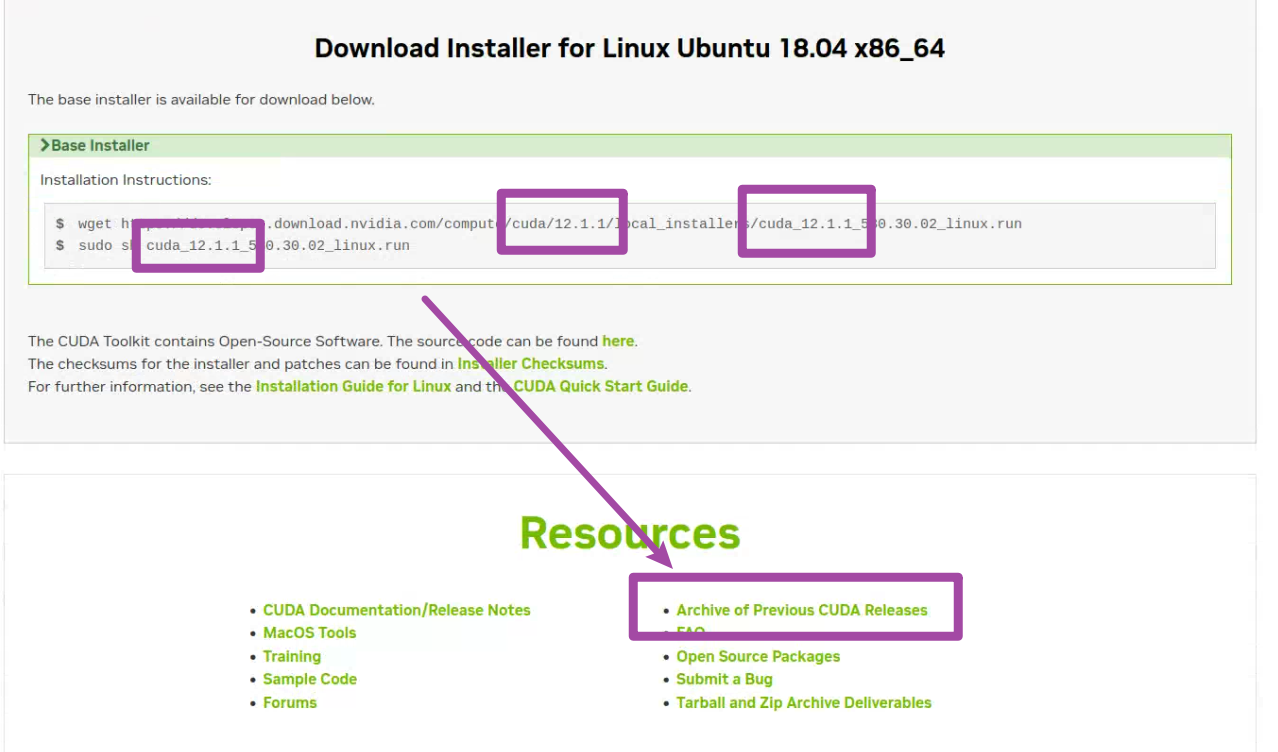
随后,网站将根据我们的选择,自动展示最新版本的CUDA。但是要注意,网站中给我们的选择,默认是最新的版本,而我们需要根据前文提到的tensorflow库版本与对应的CUDA、cuDNN版本匹配表格,确定我们需要的版本。例如,如下图前3个紫色框所示,网站中给出的CUDA版本是12.1.1的,而我需要的版本是11.8的,因此就需要通过下图中“Archive of Previous CUDA Releases”选项,找到老版本的CUDA。
如下图所示,我们这里找到11.8版本的CUDA,点击即可。

随后,将出现11.8版本的CUDA的安装方法,我们就在终端中,先后输入网站中此时展示出来的两句代码即可。
随后,即可开始安装CUDA。其中,如果大家在安装时,出现如下图所示的提示,一般情况下是由于电脑中安装有老版本CUDA导致的;但是也不用专门去管他,选择“Continue”选项即可。

随后,大家要注意,在如下图所示的界面中,取消选中Driver前面的叉号,从而取消NVIDIA驱动程序的安装,因为我们已经在前面安装过这个驱动了。随后,即可选择“Install”。

接下来,我们即可开始安装CUDA,安装完毕后将会出现如下图所示的界面。

至此,我们完成了CUDA的安装操作,但是需要进一步配置对应的环境变量。首先,在终端中输入如下的代码。
vim ~/.bashrc
这句代码表示,我们将打开bashrc这一文件,并对其加以编辑,从而实现对环境变量的配置。运行上述代码后,我们将看到类似如下图所示的界面。

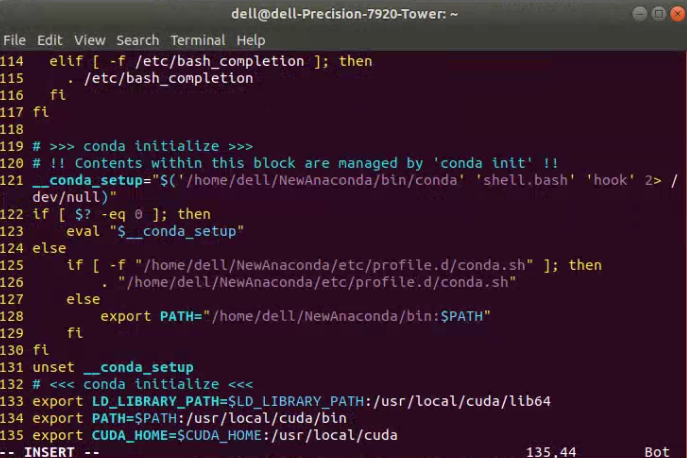
随后,我们按下i键,开始对bashrc这一文件加以编辑。通过调整鼠标的位置,从而在bashrc文件的末尾增添如下的内容。
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export PATH=$PATH:/usr/local/cuda/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda
此时,我们将得到如下图所示的情况。
接下来,我们首先按下Esc键退出编辑模式;接下来,输入:wq,表示保存并退出bashrc这一文件。此时,应该会出现如下图所示的界面。

接下来,我们分别在终端中输入如下所示的两句代码。
source ~/.bashrc
nvcc --version
其中,第一句表示更新bashrc文件,使得我们刚刚修改的环境变量立即生效;第二句则是验证CUDA安装情况的代码。如果运行以上两句代码后,出现如下图所示的界面,则表明我们的CUDA配置与环境变量配置都已经完成。

至此,我们就完成了这一部分的配置工作。
2.3 cuDNN配置
接下来,我们开始配置cuDNN。cuDNN是一个GPU加速的深度神经网络基元库,能够以高度优化的方式实现标准例程(如前向和反向卷积、池化层、归一化和激活层)。这里还是要看一下前文提及的那个tensorflow库版本与对应的CUDA、cuDNN版本匹配表格,明确我们需要下载哪一个版本的cuDNN。
首先,我们进入cuDNN的官方网站(https://developer.nvidia.com/rdp/cudnn-download);要下载cuDNN之前,我们需要先注册一下,不过注册流程也比较快,几分钟就可以完成。
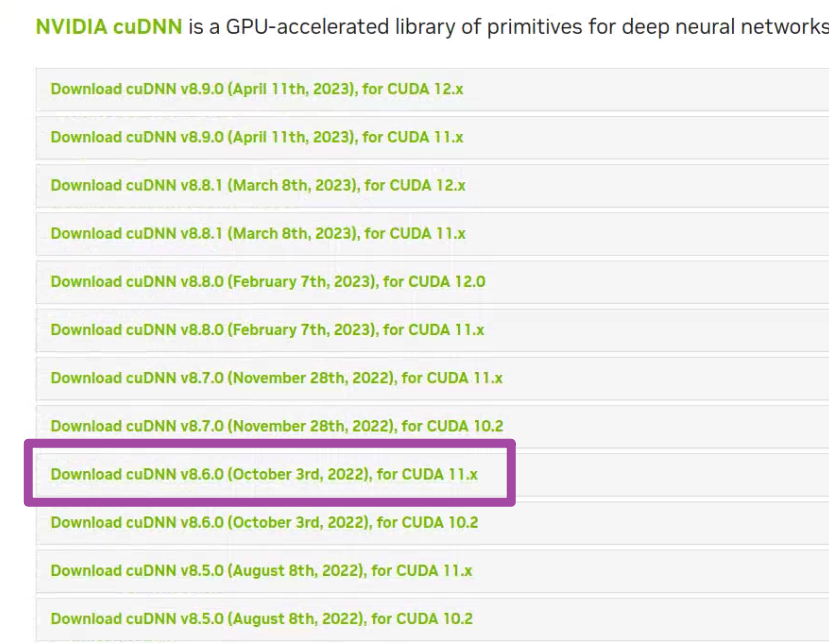
随后,我们在网站中找到对应版本的cuDNN。这里需要注意,如果我们需要的cuDNN版本并不是最新的,那么就需要在下图中“Archived cuDNN Releases”选项中找到老版本。
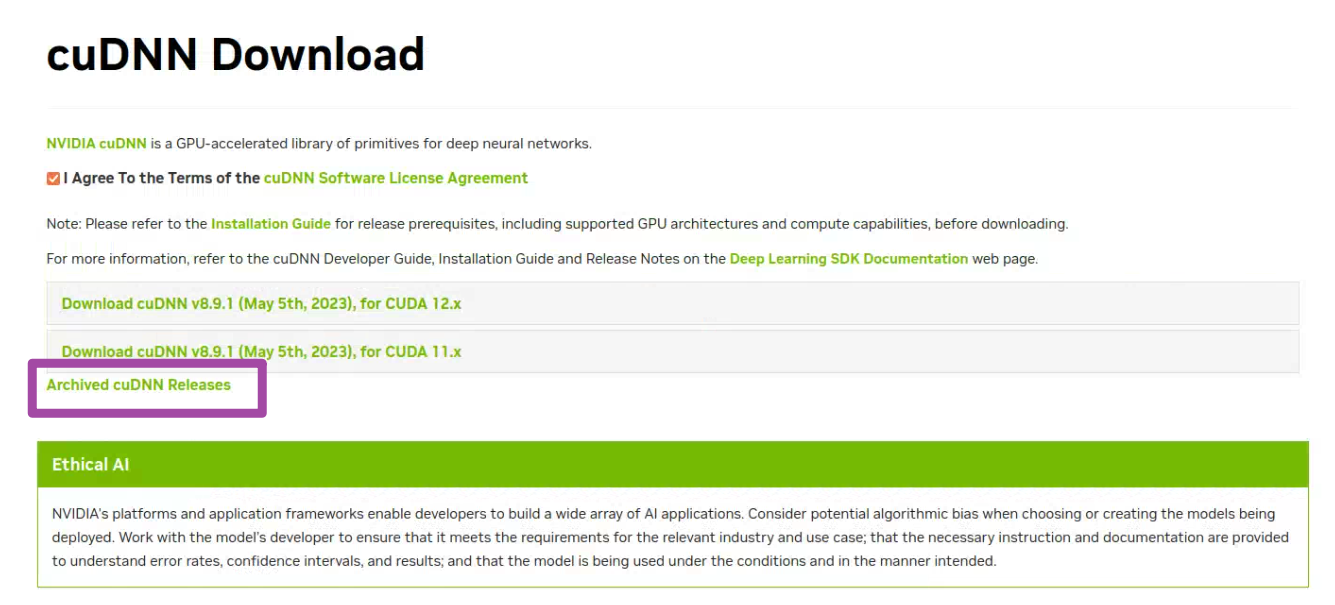
我这里需要8.6版本的cuDNN,因此就需要从上图所示的位置中找到这一个版本的下载链接,并开始下载。
下载完毕后,我们首先在终端中通过如下的命令进入下载路径;当然如果大家的下载路径不一样的话,就自行对下面这句代码加以修改即可。
cd ~/Downloads
随后,输入如下的代码;这里需要注意,下面代码中的8.x.x.x这一部分,大家需要结合自己下载后获得安装包中具体的版本数字来修改。这一句代码的作用是启动我们本地的存储库。
sudo dpkg -i cudnn-local-repo-${OS}-8.x.x.x_1.0-1_amd64.deb
运行上述代码,如下图所示。

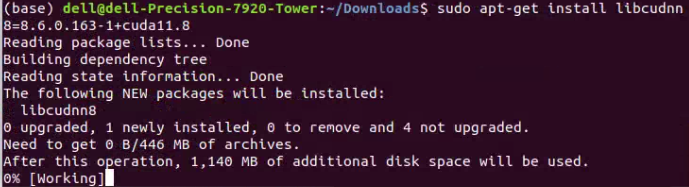
接下来,依次逐行输入如下所示的代码。其中,下面代码中的8.x.x.x这一部分,大家还是需要结合自己下载后获得安装包中具体的版本数字来修改;而同时X.Y这一部分,我们则需要根据前面选择的CUDA的版本来修改。例如,我前面下载的CUDA版本是11.8的,因此这个X.Y就是11.8。这三句代码的作用依次是:导入CUDA的GPG密钥、刷新存储库的元数据、安装运行时库。
sudo cp /var/cudnn-local-repo-*/cudnn-local-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get install libcudnn8=8.x.x.x-1+cudaX.Y
如下图第一行、第二行代码所示,就是我这里输入的上述第三句代码的具体内容。
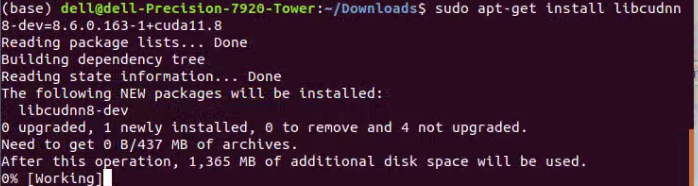
随后,我们继续在终端中输入如下的代码,同样记得修改自己的版本号。这句代码的作用是安装开发者库。
sudo apt-get install libcudnn8-dev=8.x.x.x-1+cudaX.Y
如下图所示,就是我这里输入的具体内容。
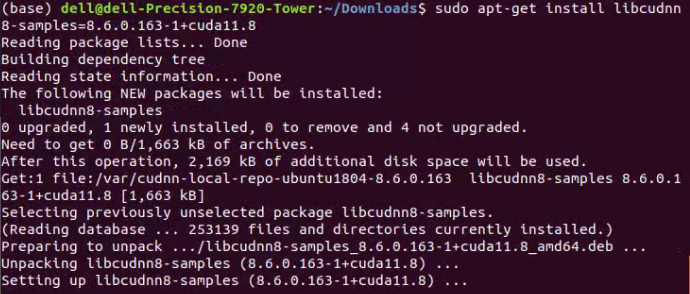
随后,我们继续在终端中输入如下的代码,同样记得修改自己的版本号。这句代码的作用是安装代码样例。
sudo apt-get install libcudnn8-samples=8.x.x.x-1+cudaX.Y
如下图所示,就是我这里输入的具体内容。
以上就是cuDNN的安装具体过程,接下来我们需要验证其是否安装正确。这一个验证过程稍微麻烦一些,但是其实流程也比较快。我们在终端中,依次逐行输入如下的代码即可。
cp -r /usr/src/cudnn_samples_v8/ $HOME
cd $HOME/cudnn_samples_v8/mnistCUDNN
sudo apt-get install libfreeimage3 libfreeimage-dev
make clean && make
./mnistCUDNN
如果大家运行完上述代码后,得到如下图所示的结果,出现Test passed!这个字样,就表明我们的cuDNN也已经配置完毕。

至此,cuDNN就已经成功配置了。
2.4 tensorflow库配置
接下来,我们终于到了最后一步,也就是tensorflow库的配置了。
我们在终端中,输入如下的代码即可。
pip install tensorflow
随后,将出现如下图所示的情况。这里大家需要注意一下,大家看一下下图紫色框内的字样,如果我们此时开始下载的tensorflow库是我们需要的版本,那么就没有问题;如果是我们当前无法使用的版本(也就是和CUDA、cuDNN版本不匹配的版本),那么就可以通过指定版本的方式重新下载tensorflow库。

完成tensorflow库的配置后,我们在Python中输入如下的代码,检验当前tensorflow库是否支持GPU运算。
import tensorflow as tf
print(tf.config.list_physical_devices("GPU"))
运行上述代码,如果得到如下图紫色框内所示的字样,则表明我们的tensorflow库已经配置完毕,且可以使用GPU加速运算了。

至此,大功告成。
欢迎关注:疯狂学习GIS






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结