您现在的位置是:首页 >其他 >Python3实现基于ARIMA模型来预测茅台股票价格趋势网站首页其他
Python3实现基于ARIMA模型来预测茅台股票价格趋势

?♂️ 个人主页:@艾派森的个人主页
✍?作者简介:Python学习者
? 希望大家多多支持,我们一起进步!?
如果文章对你有帮助的话,
欢迎评论 ?点赞?? 收藏 ?加关注+

目录
ARIMA模型简介
ARIMA(Autoregressive Integrated Moving Average)模型是一种广泛使用的时间序列分析方法,它可以用于对未来的数据进行预测。
ARIMA模型由自回归模型(AR模型)、差分整合模型(I模型)和移动平均模型(MA模型)组成,因此也被称为ARIMA(p,d,q)模型。其中,p表示自回归阶数,d表示差分阶数,q表示移动平均阶数。
具体来说,ARIMA模型可以通过以下步骤进行建模:
-
数据预处理:对时间序列进行平稳性检验,如果不满足平稳性,则进行差分操作。
-
模型选择:根据样本自相关图(ACF)和偏自相关图(PACF)选择合适的p、d、q值。
-
参数估计:使用极大似然估计或最小二乘法对模型参数进行估计。
-
模型检验:对模型的残差进行自相关性和正态性检验,如果不符合要求则需要重新选择模型或调整参数。
-
模型预测:根据已有数据和已经估计好的参数进行未来数据的预测。
ARIMA模型在金融、经济、气象、交通等领域都有广泛应用,特别是在金融领域,ARIMA模型可以用于股票价格、汇率、利率等方面的预测。
ARIMA(p,d,q)阶数确定
| 模型 | ACF | PACF |
| AR(p) | 衰减趋于零(几何型或震荡型) | p阶后截尾 |
| MA(q) | q阶后截尾 | 衰减趋于零(几何型或震荡型) |
| ARMA(p,q) | q阶后衰减趋于零(几何型或震荡型) | p阶后衰减趋于零(几何型或震荡型) |
截尾:落在置信区间内(95%的点都符合该规则)
实战案例
本次案例使用的数据集是2016年到2023-5-8日茅台股票数据,旨在预测未来数十天的股票趋势。
加载数据
首先导入本次实验用到的第三方库和股票数据集
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import statsmodels.api as sm
import warnings
warnings.filterwarnings('ignore')
sns.set(font='SimHei')
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
# 股票数据的路径
stock_file = 'maotai_stock.csv'
# 导入数据集并将其转换为时间序列
df = pd.read_csv(stock_file, index_col='date', parse_dates=True)
df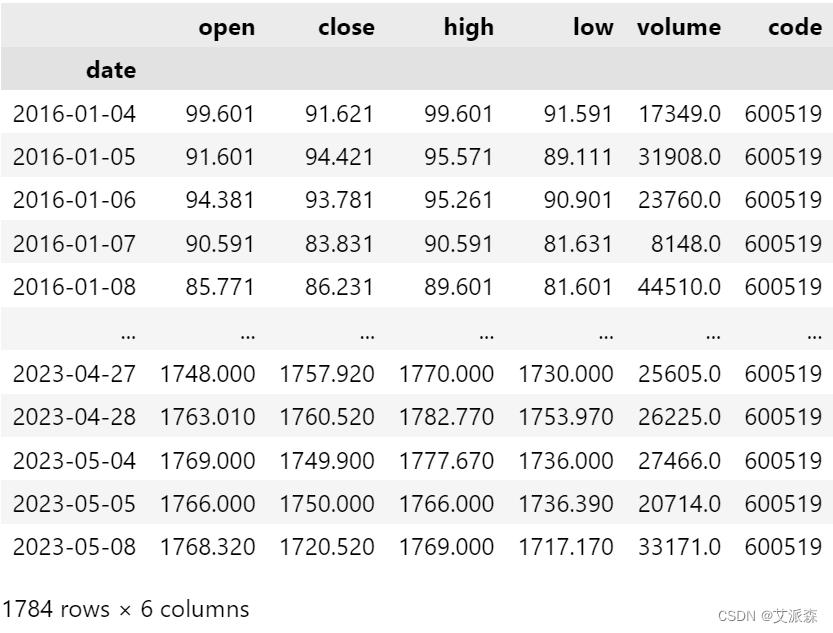
数据预处理
由于我们要分析预测的是收盘价,所以我们取出收盘价的数据并进行重采样,以周且指定周一为单位求平均值。然后指定2016-1月到2023-4月的数据作为训练数据。最后将训练数据进行可视化展示。
# 重点分析收盘价并预测,对原始数据进行重采样,以周且指定周一为单位求平均值
stock_week = df['close'].resample('W-MON').mean()
# 取出2016-1月到2023-4月的数据作为训练数据
stock_train = stock_week['2016-1':'2023-4']
# 做出折线图
stock_train.plot(figsize=(15,6))
plt.legend()
plt.title('Stock Close')
sns.despine()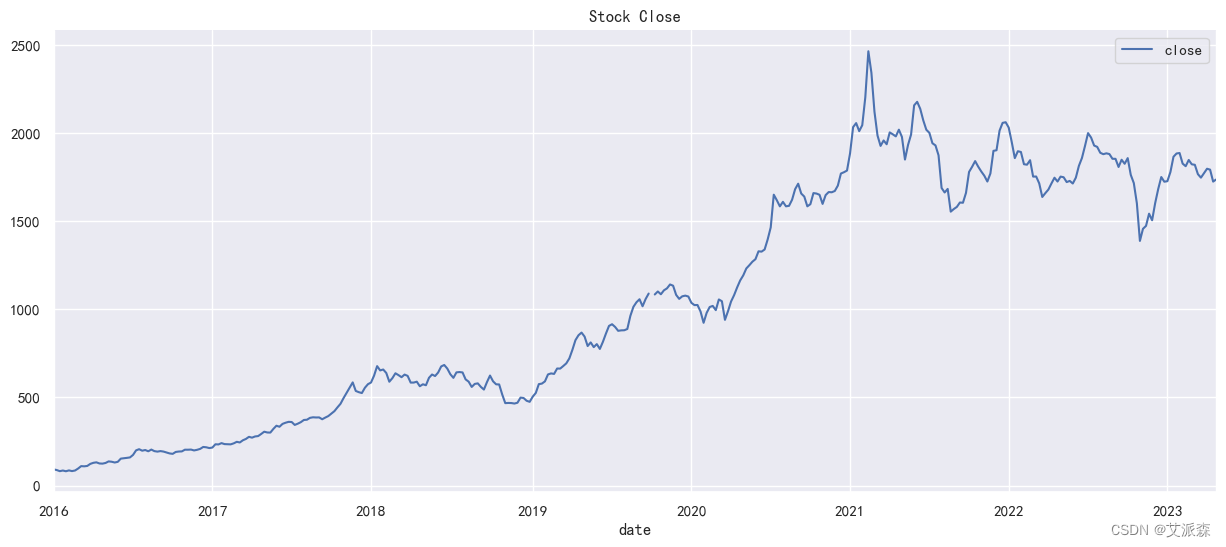
差分并确定参数d
这里我们对数据进行拆分的目的是保证数据的平稳性,因为通过上图我们发现原始数据波动的幅度很大,需要进行拆分操作。这里我们对数据先进行一阶拆分和二阶拆分并可视化展示。
# 将时间序列进行差分并确定参数d
# 一阶差分
stock_diff_1 = stock_train.diff()
stock_diff_1.dropna(inplace=True)
# 二阶差分
stock_diff_2 = stock_diff_1.diff()
stock_diff_2.dropna(inplace=True)
plt.figure(figsize=(12,6))
plt.subplot(2,1,1)
plt.plot(stock_diff_1)
plt.title('一阶差分')
plt.subplot(2,1,2)
plt.plot(stock_diff_2)
plt.title('二阶差分')
plt.show()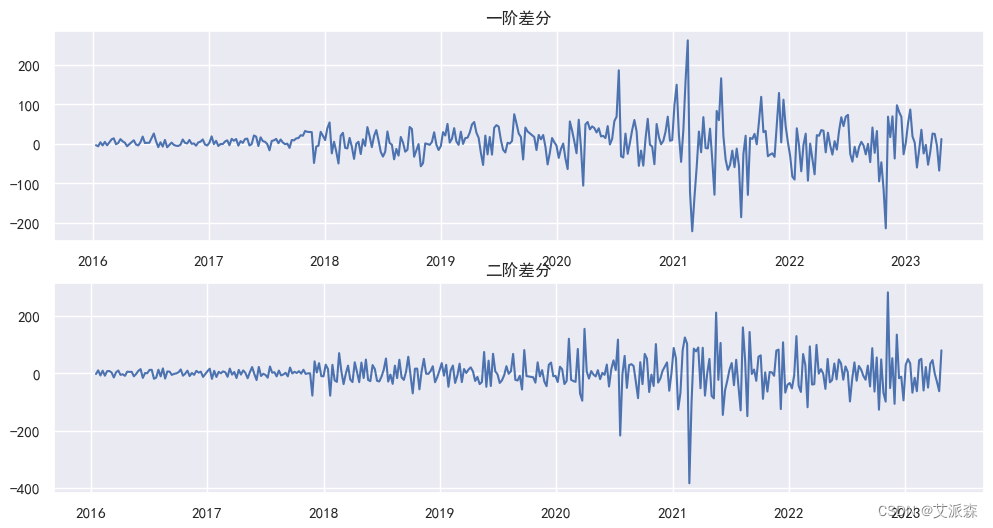
通过上图我们发现,一阶差分就已经由稳定的趋势了,到了二阶波动的幅度反而更大,所以这里我们直接确定参数d为1。
除了上面的方法,我们还可以使用下面的代码确定参数d:
# 将时间序列进行差分,直到其成为平稳序列
ts = df['close']
d = 0
while not sm.tsa.stattools.adfuller(ts)[1] < 0.05:
ts = ts.diff().dropna()
d += 1
print('参数d为:',d)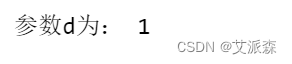
得出的结果也是1,跟上面的方法一样。
做出ACF、PACF图确定参数q和p
# 做出ACF图确定参数q
sm.graphics.tsa.plot_acf(stock_diff_1)
plt.title('ACF')
plt.show() 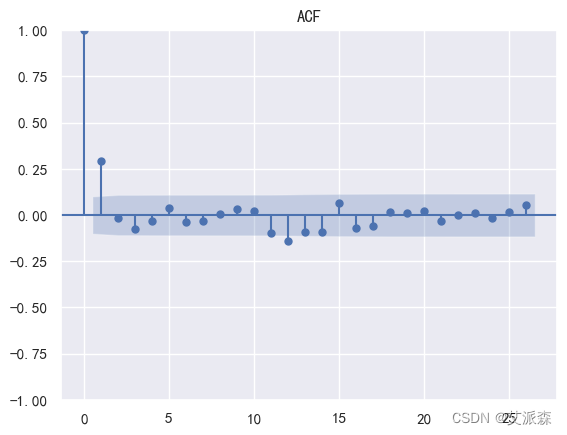
# 做出PACF图并确定参数p
sm.graphics.tsa.plot_pacf(stock_diff_1)
plt.title('PACF')
plt.show()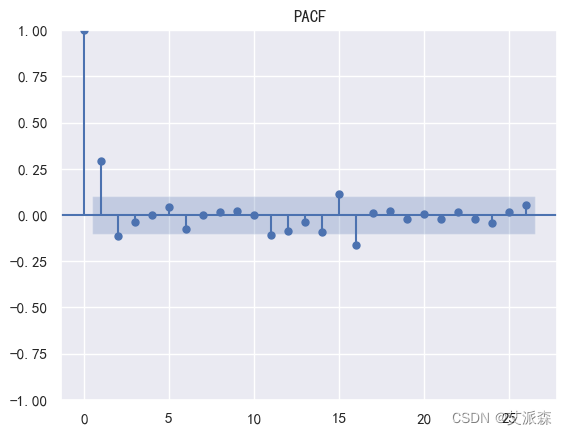
通过观察上面两个图,我们可以确定参数 p和q都为1是最佳的。
除了观察图形,我们也可以使用下面代码进行确定参数p/q:
# 根据AIC和BIC的值来确定参数
train_result = sm.tsa.arma_order_select_ic(stock_train,ic=['aic','bic'],trend='c',max_ar=4,max_ma=4)
print('AIC',train_result.aic_min_order)
print('BIC',train_result.bic_min_order)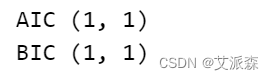
这里如果BIC和AIC的值不一样,你两个结果都试试,看看哪个参数组合训练的模型效果最好。这里AIC和BIC的结果都是(1,1),说明p=q=1是最佳的参数结果。
训练模型并预测
这里的order(p,d,q),将前面确定数值填进去即可,freq是为了和前面重采样保持一致。
# 拟合ARIMA模型
model = sm.tsa.ARIMA(stock_train, order=(1, 1, 1),freq='W-MON')
result = model.fit()预测的时候需要填写起始时间和终止时间,注意起始时间必须在训练数据中出现
# 使用该模型进行预测
forecast = result.predict(start='2022-01-10', end='2023-6-01')
forecast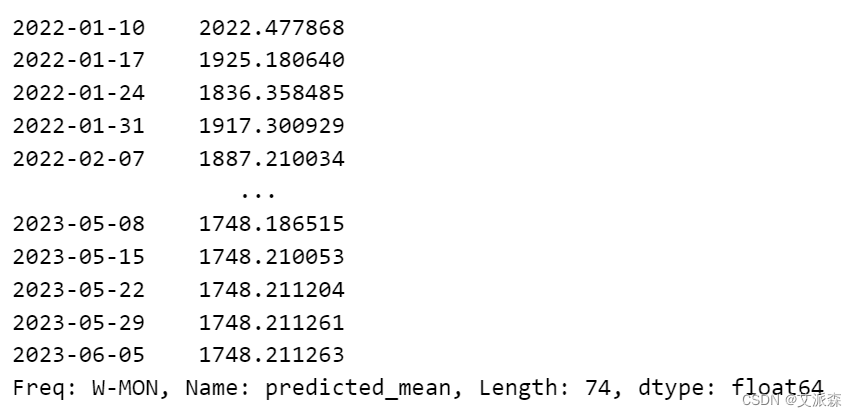
我们将预测的结果和真实值可视化出来:
plt.figure(figsize=(12,6))
plt.xticks(rotation=45)
plt.plot(forecast,label='预测值')
plt.plot(stock_train,label='真实值')
plt.legend()
plt.show()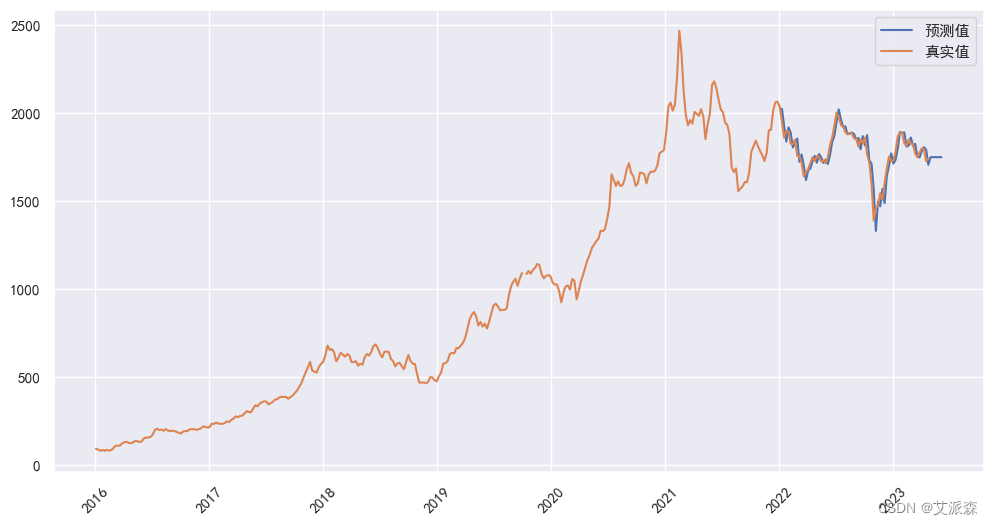
可以发现模型拟合的还不错,基本上与原趋势保持一致。
模型效果评估
这里我们直接调用plot_diagnostics()方法将模型的评估结果可视化展示
# 残差分析、正态分布、QQ图、相关系数
result.plot_diagnostics(figsize=(16,12))
plt.show()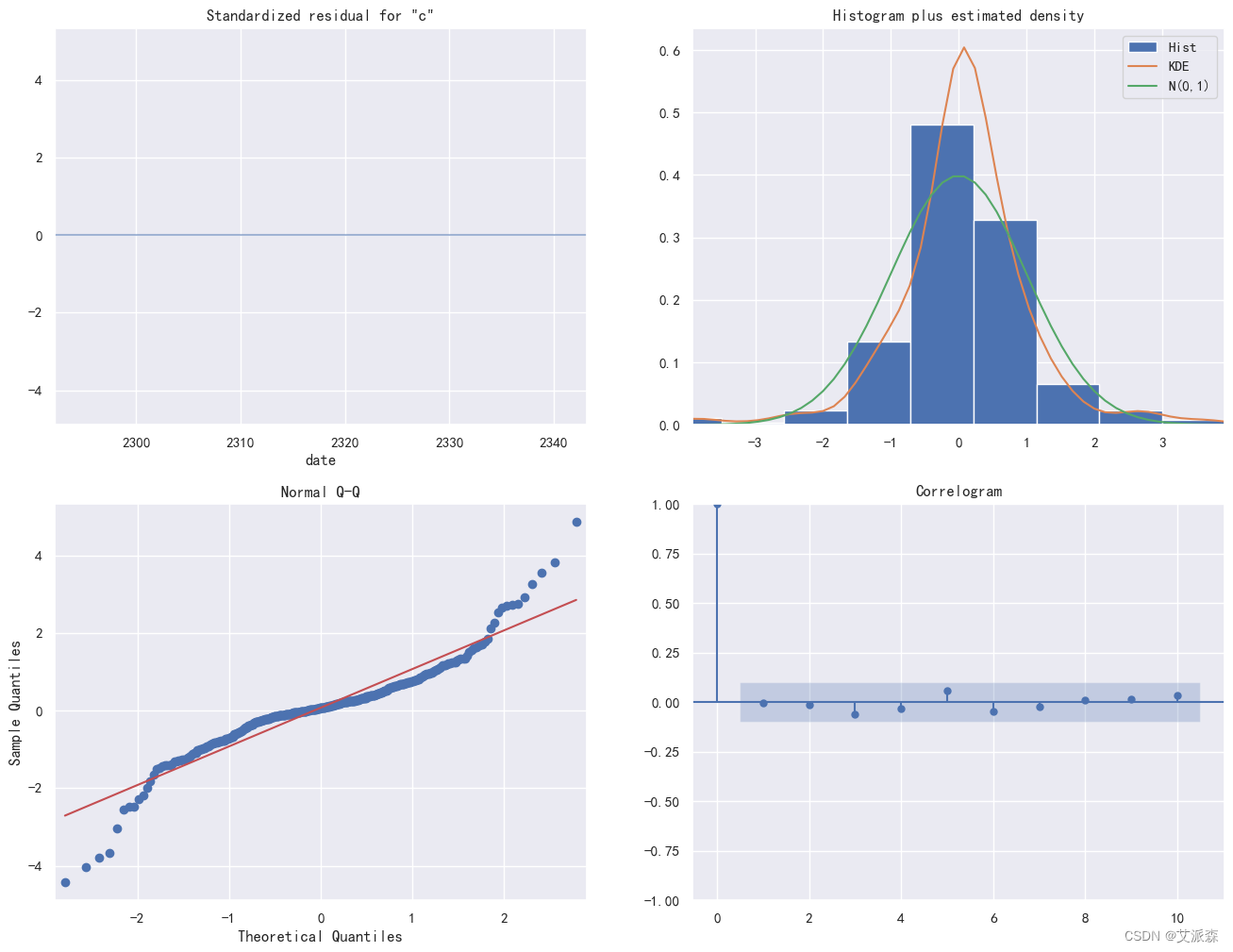
上左是残差分析图,可以发现模型残差为零。
上右是直方图和正太分布图,可以发现模型是近似于正太分布的。
下左是QQ图,可以发现除了两端少数极点,大部分数据都可以用一条直线拟合。
下右是相关系数图。
最后我们也可以使用summary()函数来查看模型的效果指标。
result.summary()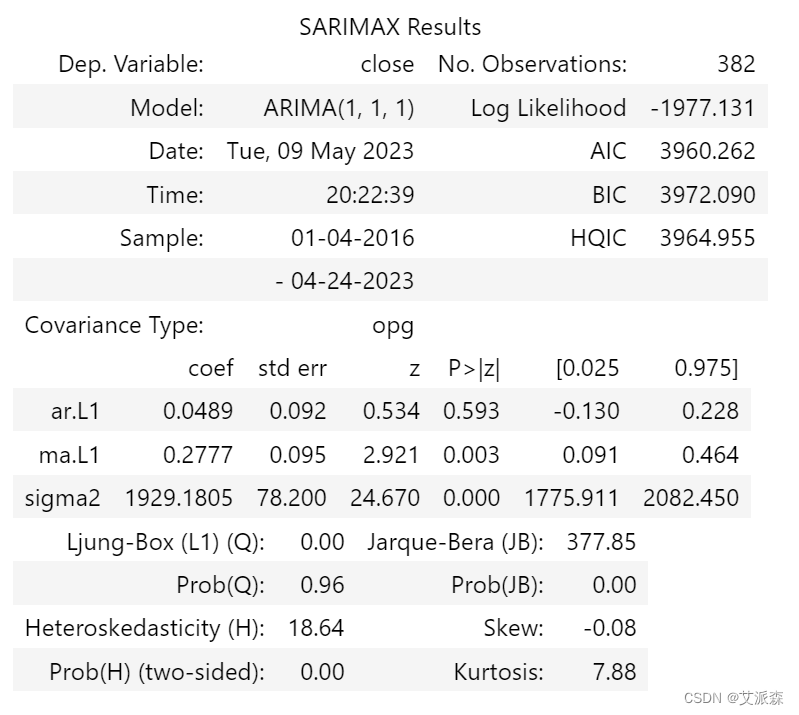






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结