您现在的位置是:首页 >技术教程 >【云原生|探索 Kubernetes 系列 7】探究 Pod 有什么用,为什么需要它网站首页技术教程
【云原生|探索 Kubernetes 系列 7】探究 Pod 有什么用,为什么需要它
前言
大家好,我是秋意零。
前一篇,我们介绍了如何从 0 到 1 搭建 Kubernetes 集群。现在我们可以正式了解,Kubernetes 核心特征了。今天我们来探究 Pod,为什么需要 Pod?
? 简介

文章目录
专栏
系列文章目录
【云原生|探索 Kubernetes-1】容器的本质是进程
【云原生|探索 Kubernetes-2】容器 Linux Cgroups 限制
【云原生|探索 Kubernetes 系列 3】深入理解容器进程的文件系统
【云原生|探索 Kubernetes 系列 4】现代云原生时代的引擎
【云原生|探索 Kubernetes 系列 5】简化 Kubernetes 的部署,深入解析其工作流程
正文开始:
- 快速上船,马上开始掌舵了(Kubernetes),距离开船还有 3s,2s,1s…

一、最小管理单元介绍
在 Kubernetes 中所有特征性服务,如:Pod、Service、Deployment、DaemonSet 等。像这些都是 Kubernetes 中的 API 对象,都提供了一个 API 接口,并可以通过这些对象接口实现调用,也就是我们常说的: “API 接口调用”。如果后期有需求的话,本专栏也会包含这部分的内容哦!!
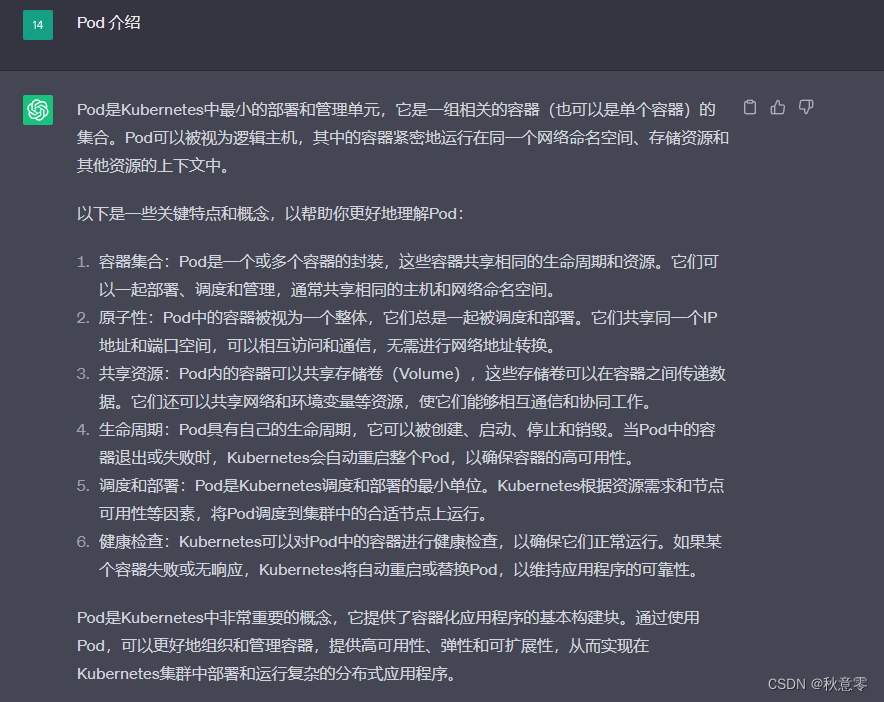
Pod 是 Kubernetes 中最小的 API 对象,或者说是最小的部署和管理单元。
下面我们看看,ChatGPT 详解介绍的 Pod:
二、为什么 Kubernetes 需要 Pod ?
回答这个问题之前,我们回忆一下我们在读本专栏第 1 篇文章时讲过的,容器的本质是进程。
- 如果模糊了可以跳转复习复习: 【云原生|探索 Kubernetes-1】容器的本质是进程
容器是进程,容器镜像就相当于 windows 系统中的 “.exe” 安装包,而 Kubernetes 就是操作系统。
- 我们在本专栏第 4 篇文章提到过:【云原生|探索 Kubernetes 系列 4】现代云原生时代的引擎(目录:四、Kubernetes 要解决的问题是什么?)
来感受一下
我们在 Linux 机器上,安装 pstree 命令,需要执行以下指令:
# 1.查找 pstree 命令的依赖包
$ yum provides pstree
...
psmisc-22.20-17.el7.x86_64 : Utilities for managing processes on your system
...
$ yum install -y psmisc-22.20-17.el7.x86_64
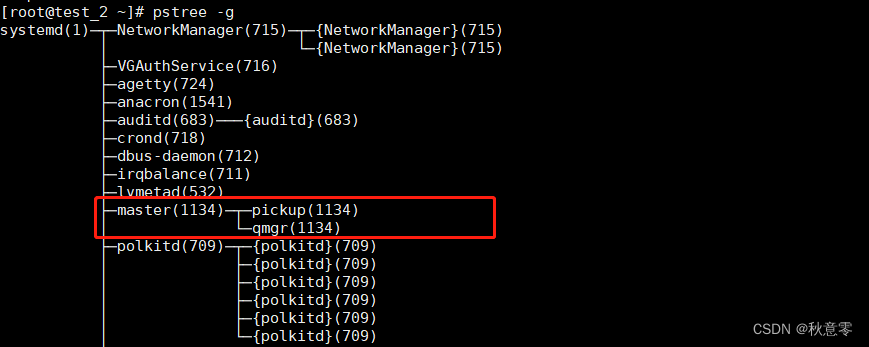
pstree 命令,以树状图形式显示进程信息:
我们发现操作系统中的进程,并不是单个独自运行的,而是以进程组的方式,相互协作组织在一起。
- 图中,我们可以看到,框出的地方:
master进程 id 是1134,而它还包含了两个进程pickup和qmgr进程 id 也是1134。它们同属于 1134 进程组,这些进程相互协作,共同完成 master 程序的职责。(好笑的是:我并不知道,master 这个进程的作用)
注意:上诉中,提到的
pickup和qmgr“进程” 其实是 Linxu 系统中的 “线程”。这些线程,可以共享文件、信号、数据内存、甚至部分代码,从而紧密协作共同完成一个程序的职责。
这样一来我们就能理解 Pod 了吧,Kubernetes 项目所做的,其实就是将 “进程组” 的概念映射到了容器技术中:
- Pod 里面包含了容器,Pod 里面的容器看作是 Pod 的线程,而 Pod 看作是一个进程组,运行在操作系统中,也就是我们这里的 Kubernetes 中。从而 Pod 成为 Kubernetes 操作系统中的 “一等公民”。
这么做的原因
在 Borg 项目的开发和实践过程中,工程师发现,他们部署的应用,一般都存在类似 “进程和进程组” 的关系,应用之间有着密切的协作关系,使得它们必须部署在同一台机器上。所以我们上图中的 master 进程和其 pickup 和 qmgr “子进程”,必须在同一台机器上,否则它们之间的 Socket 通信和文件交换,都会出现问题。
1.容器的 “单进程模型”:
- 单进程模型,这句话是说:不是只能运行一个进程,而是不具备管理多个进程的能力。因为容器的
PID=1的进程就是自己应用本身,其他的进程都是这个 PID=1 进程的子进程。所以PID=1的进程应用,一般是不会具有像操作系统里面的init (初始化)进程或者systemd 进程管理的功能。 - 举个例子,比如:现在容器中有个
PID=1的Web应用,然后你进入容器在里面安装启动了一个Nginx进程PID=3。当Nginx进程异常退出的时候,你是不知道的,退出后它的内存垃圾回收等工作,PID=1的Web 应用是不会理睬的,这种情况下PID=1的进程是被宿主机管理的,而其他进程就没有谁来管理了。
总结:容器不提倡单进程不是因为不能运行多个进程,而是因为没有 systemd 这种功能的 1 号进程来管理程序。
2.举个例子:
而由于,容器的 “单进程模型”,master 进程组必须被部署在不同的三个容器中,假设这三个容器,设置的内存配额都至少需要 1 GB。如果,我们的 Kubernetes 集群上有两个节点:node-1 上有 3 GB 可用内存,node-2 有 2.5 GB 可用内存。
-
这时,假设我要用 Docker Swarm 来运行这个
master程序。为了能够让这三个容器都运行在同一台机器上,我就必须在另外两个容器(pickup和qmgr)上设置一个affinity=master(与 master 容器有亲和性)的约束,即:pickup和qmgr它们俩必须和master容器运行在同一台机器上。- 亲和性:指和谁比较熟悉或者喜欢谁,它们俩就会靠近在一起。比如:小明和小红,小明喜欢小红,而开始它们被分配到了不同班级,这时候由于喜欢(亲和性)小红,小明就要求老师给他转到和小红一个班去。
-
然后,我们
docker run master、docker run pickup、docker run qmgr启动这三个容器。 -
这三个容器进入 Swarm 的调度队列,然后,
master和pickup容器都先后被调度到 node-2 上(这种情况是完全有可能的)。当 qmgr 容器被开始调度时,Swarm 都懵逼了:node-2 上本来 2.5 GB 的可用内存,运行了master和pickup容器现在就剩下 0.5 GB 了,不足以运行qmgr容器,可是,根据affinity=master的约束,qmgr容器又只能运行在 node-2 上。
这就是成组调度没有被处理成功的例子。而 Kubernetes 就把这个问题完美解决了:因为 Pod 是 Kubernetes 中最小的调度单元,这就说明 Kubernetes 是按照 Pod 而不是容器资源需求来调度计算的。
所以,像上面的 master 、pickup 、 qmgr 这三个容器。在 Kubernetes 中,我们会将他们组成一个 Pod。这个 Pod 要求的内存资源是 3 GB,在调度的时候 Kubernetes 就直接会将它调度到 node-1 节点(3 GB)上,而不会考虑 node-2 节点(2.5GB)上。
这样它们之间就能进行文件交换、使用 localhost 或者 Socket 文件进行本地通信、会发生非常频繁的远程调用、需要共享某些 Linux Namespace(比如,一个容器要加入另一个容器的 Network Namespace)等等。像这样容器间的紧密协作,我们可以称为 “超亲密关系”。
也意味着,不是所有容器都应该属于一个 Pod。比如:Wordpres 系统,一个 Web 前端和 Mysql 后端,它们之间有访问关系,但是没有必要做成一个 Pod ,适合做两个 Pod。
三、容器设计模式
如果只是处理 “超亲密关系” 调度问题,那么就可以不使用 Pod 啊?为什么 Kubernetes 中最小的单元还是 Pod 呢?
那就是 Pod 还有一个更重要的意义:容器设计模式。
为了理解这一层含义,我就必须先给你介绍一下 Pod 的实现原理。
Pod 实现原理
Pod 是一个逻辑概念,我们看不见摸不着。Kubernetes 真是处理的,还是宿主机中的 Namespace 和 Cgroups,所以隔离环境不是什么 Pod。
Pod 又是怎么定义和创建的呢?:
-
Pod 其实是一组共享了网络(Network Namespace)和卷(Volume)的容器组成的。
- 这样的话就是,包含有 A、B 两个容器的 Pod,就等于一个容器(A)共享另一个容器(B)的网络和卷的操作。
$ docker run --net=B --volumes-from=B --name=A image-A
这样的话,容器 A 就依赖于容器 B,所以对应在 Pod 中它们的关系就是拓扑关系,而不是对等关系了。
为了打破这种, 容器 A 依赖于容器 B 的拓扑关系,Pod 中最开始就创建了一个中间容器,叫 Infra 容器。这个 Infra 容器,在 Pod 生命周期中是第一个创建的容器,这样像 A 和 B 或者其它容器只需要加入这个 Infra 容器提供网络(Network Namespace)和卷,就可以与之关联起来了,也就组成了我们的 Pod,所以 Pod 中的容器使用的是同一个 Linxu Namespace 。如下图所示:
-
Infra 容器一定要占用极少的资源,所以它使用的是一个非常特殊的镜像,k8s.gcr.io/pause。这个镜像是一个用汇编语言编写的、永远处于 “暂停” 状态的容器,解压后的大小也只有 100~200 KB 左右。
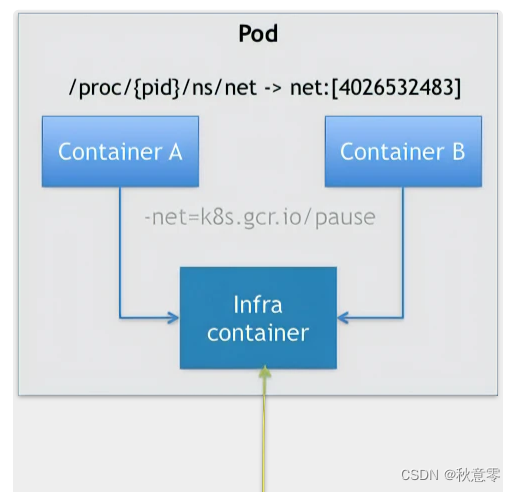
共享网络
由于,Pod 中的容器 A 和容器 B 是加入的在 Infra 容器中的,所以:
- 他们之间可以直接使用 localhost 进行通信;
- 一个 Pod 只有一个 IP 地址,也就是这个 Pod 的 Network Namespace 对应的 IP 地址,所以 Pod IP 和 容器 IP 是一样的。
- 当然,其他的所有网络资源,都是一个 Pod 一份,并且被该 Pod 中的所有容器共享;
- Pod 的生命周期只跟 Infra 容器一致,而与容器 A 和 B 无关。
而对于同一个 Pod 里面的所有用户容器来说,它们的进出流量,也可以认为都是通过 Infra 容器完成的。如果你要为 Kubernetes 开发一个网络插件时,应该重点考虑的是如何配置这个 Pod 的 Network Namespace,而不是每一个用户容器如何使用你的网络配置,这是没有意义的。
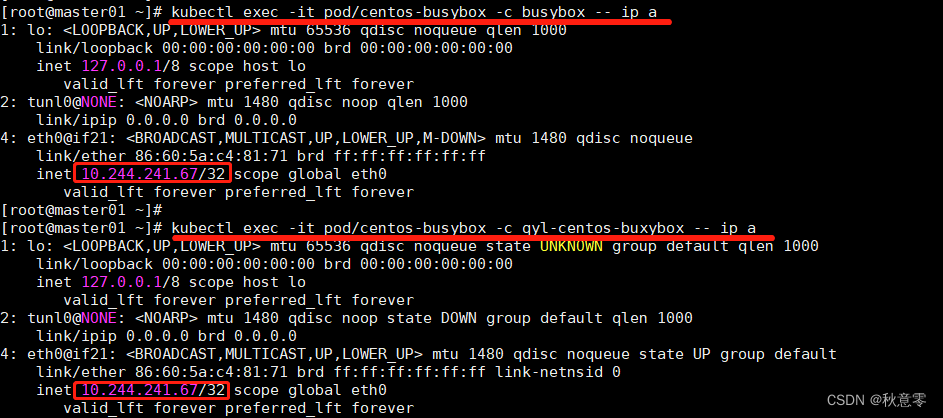
所以 Pod IP 和 容器 IP 是一样的,验证过程:
- 1.首先创建一个 Pod,当中包含一个 busybox 和一个 centos 容器
# 以 yaml 格式打印输出出来,一般用于生成模板
[root@master01 ~]# kubectl run qyl-centos --image=centos -oyaml --dry-run
W0530 18:08:54.937948 30966 helpers.go:663] --dry-run is deprecated and can be replaced with --dry-run=client.
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: qyl-centos
name: qyl-centos
spec:
containers:
- image: centos
name: qyl-centos
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
[root@master01 ~]# cat busybox-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: centos-busybox
name: centos-busybox
spec:
containers:
- image: busybox
name: busybox
imagePullPolicy: IfNotPresent
command: [ "/bin/sh", "-c", "sleep 3600" ]
- image: centos
name: qyl-centos-buxybox
imagePullPolicy: IfNotPresent
command: [ "/bin/bash", "-c", "--" ]
args: [ "while true; do sleep 30; done;" ]
[root@master01 ~]# kubectl apply -f busybox-pod.yaml
pod/qyl-centos created
- 2.查看 Pod 和里面容器的 IP 地址一致。
kubectl get pod -o wide | grep centos-busybox
kubectl exec -it pod/centos-busybox -c busybox -- ip a
kubectl exec -it pod/centos-busybox -c qyl-centos-buxybox -- ip a

共享卷
Kubernetes 项目只要把所有 Volume 的定义都在 Pod 层级即可(和 Pod 是兄弟)。一个 Volume 对应的宿主机目录对于 Pod 来说就只有一个,Pod 里的容器只要声明挂载这个 Volume,就一定可以共享这个 Volume 对应的宿主机目录。
比如下面这个例子:
- debian-container 和 nginx-container 都声明挂载了 shared-data 这个 Volume。而 shared-data 是 hostPath 类型。所以,它对应在宿主机上的目录就是:/data。而这个目录,其实就被同时绑定挂载进了上述两个容器当中。
- 这也是为什么,nginx-container 可以从它的 /usr/share/nginx/html 目录中,读取到 debian-container 生成的 index.html 文件的原因。
cat > nginx.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: two-containers
spec:
volumes:
- name: shared-data
hostPath:
path: /data
containers:
- name: nginx-container
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
volumeMounts:
- name: shared-data
mountPath: /usr/share/nginx/html
- name: centos-container
image: couchbase/centos7-systemd
imagePullPolicy: IfNotPresent
volumeMounts:
- name: shared-data
mountPath: /pod-data
command: ["/bin/sh"]
args: ["-c", echo "Hello this is centos container" > /pod-data/index.html;sleep 3600]
EOF
[root@master01 ~]# kubectl get -f nginx.yaml -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
two-containers 2/2 Running 0 10s 10.244.241.72 master01 <none> <none>
[root@master01 ~]# curl 10.244.241.72
Hello this is centos container
容器设计模式
Pod 这种 “超亲密关系” 思想,希望,当用户想在一个容器里跑多个功能并不相关的应用时,应该优先考虑它们是不是更应该部署在一个 Pod 中。
为了能够掌握这种思考方式,你就应该尽量尝试使用它来描述一些用单个容器难以解决的问题。
WAR 包与 Web 服务器
现在有一个 Java Web 应用 WAR 包,这个 WAR 一般是放在 Tomcat 的 webapps Web解析目录下,使其运行起来。
使用 Docker 有两种方式实现这个关系。
- 把 WAR 包直接放在 Tomcat 镜像的 webapps 目录下,做成一个镜像运行起来。但是,如果你要更新 WAR 包的内容,或者要升级 Tomcat 镜像,就要重新制作一个新的发布镜像,非常麻烦。
- 你压根儿不管 WAR 包,永远只发布一个 Tomcat 容器。不过,这个容器的 webapps 目录,就必须声明一个 Volume,不管是什么类型(分布式、本地存储都可以),只要将 Tomcat 容器的 webapps 目录挂载出去,之后只需要在外对这个 WAR 进行更新操作(就像上面的 Nginx 例子一样)而无需重新更新镜像那么麻烦。
注意:这里使用了 initContainers ,它是为了完成一些初始化工作(完成就退出,不完成就不会退出),比如这里是将 sample.war 拷贝在 Pod 卷里的 /app 目录下,这样 tomcat 只要使用这个共享卷就能看见这个 sample.war 包,并使用。
apiVersion: v1
kind: Pod
metadata:
name: javaweb-2
spec:
initContainers:
- image: geektime/sample:v2
name: war
command: ["cp", "/sample.war", "/app"]
volumeMounts:
- mountPath: /app
name: app-volume
containers:
- image: geektime/tomcat:7.0
name: tomcat
command: ["sh","-c","/root/apache-tomcat-7.0.42-v2/bin/start.sh"]
volumeMounts:
- mountPath: /root/apache-tomcat-7.0.42-v2/webapps
name: app-volume
ports:
- containerPort: 8080
hostPort: 8001
volumes:
- name: app-volume
emptyDir: {}
这样,我们就用这种 “组合” 方式,解决了 WAR 包与 Tomcat 容器之间耦合关系的问题。
这种 “组合” 操作,是容器设计模式最常用的一种模式,叫做:sidecar。
sidecar(边车) 模式:我们可以在一个 Pod 中,启动一个辅助容器,来完成一些独立于主进程(主容器)之外的工作。比如,这里的 initContainers 容器(不仅仅是使用 initContainers 也是可以是 containers 类型,如上面的 Nginx 例子 )。
容器的日志收集
现在有一个 Web 容器应用,需要不断地把日志文件输出到它的 /var/log 目录中。
- 这时,我们就可以将 Pod 声明的 Volume 挂载到该容器的 /var/log 目录上。
- 同时启动一个 sidecar 容器,因为共享卷的缘故,只要我挂载后,就能看到 Web 容器应用日志在 /var/log 目录上生成的日志。
- 接下来 sidecar 容器,将 /var/log 日志信息,转发到 Elasticsearch 或者数据库中存储起来,这样就完成了日志收集工作。
Pod 的另一个重要特性是,它的所有容器都共享同一个 Network Namespace。这就使得很多与 Pod 网络相关的配置和管理,也都可以交给 sidecar 完成,而完全无须干涉用户容器。这里最典型的例子莫过于 Istio 这个微服务治理项目了。
总结
重点说明了,Pod 的工作原理。
我们从最开始进程组来展开了 Pod 的好处;
接着阐述了 Pod 的工作原理Pod 其实就是共享了网络和卷一组容器;
最后阐述了容器设计模式的玩法,以及它的重要性。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结