您现在的位置是:首页 >技术杂谈 >LLM:LoRA: Low-Rank Adaptation of Large Language Models网站首页技术杂谈
LLM:LoRA: Low-Rank Adaptation of Large Language Models
随着模型规模的不断扩大,微调模型的所有参数(所谓full fine-tuning)的可行性变得越来越低。以GPT-3的175B参数为例,每增加一个新领域就需要完整微调一个新模型,代价和成本很高。
为解决微调大规模语言模型到不同领域和任务的挑战,已有多种方案,比如部分微调、使用adapters和prompting。但这些方法存在如下问题:
- Adapters引入额外的推理延迟 (由于增加了模型层数)
- Prefix-Tuning难于训练,且预留给prompt的序列挤占了下游任务的输入序列空间,影响模型性能
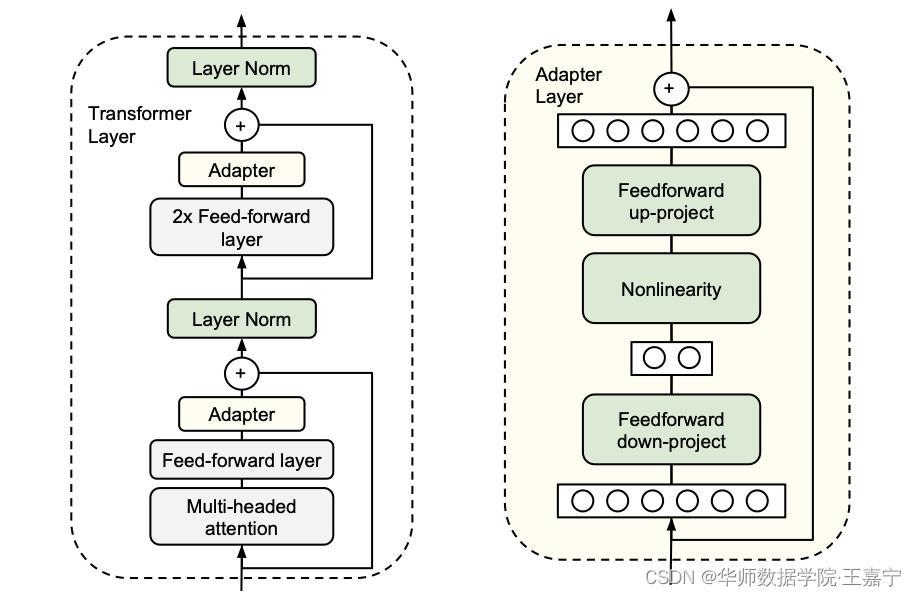
Adapter Layers
在transformer block后面添加参数很少的层或者norm层。这样做,虽然tuning时要更新的参数少了,但由于加了网络深度,对于latency不友好。
Prompt tuning/Prefix tuning
这个方法,一是很难优化,二是会降低下游能处理的序列长度。 Prefix-Tuning难于训练,模型性能也并非总是稳步提升。预留一些sequence做adaption会让处理下游任务的可用sequence长度变少,一定程度上会影响模型性能。

[参数有效性学习-Adapter和Prefix-Tuning 以及 UniPELT框架https://wjn1996.blog.csdn.net/article/details/120607050#t16]
LoRA的思路
paper:Armen Aghajanyan的Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning.
这篇文章尝试去回答一个问题:为什么用几千几百条样本就能去finetune一个百万量级的模型。
答案是:We empirically show that common pre-trained models have a very low intrinsic dimension; in other words, there exists a low dimension reparameterization that is as effective for fine-tuning as the full parameter space。即只有一些关键维度对finetune起效果。
这篇文章的作者还做了个实验:by optimizing only 200 trainable parameters randomly projected back into the full space, we can tune a RoBERTa model to achieve 90% of the full parameter performance levels on MRPC.将原始权重映射到一个很小的子集再映射回去,依然能训得很好。作者猜想:只需要更新低秩矩阵,在节省大量资源和时间的情况下,仍能获得不错的tuning效果。
考虑OpenAI对GPT模型的认知,GPT的本质是对训练数据的有效压缩,从而发现数据内部的逻辑与联系,LoRA的思想与之有相通之处,原模型虽大,但起核心作用的参数是低秩的,通过增加旁路,达到四两拨千斤的效果。
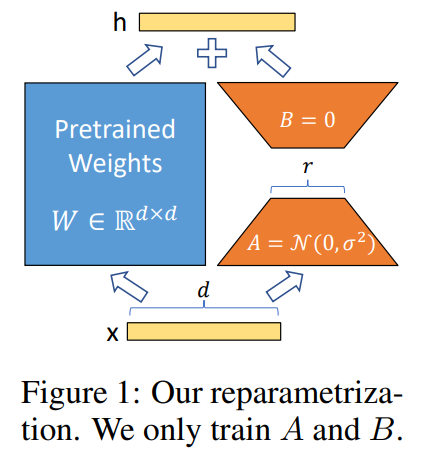
LoRA的思想也很简单,在原始PLM旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank 。训练的时候固定PLM的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将BA与PLM的参数叠加。
用随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵依然是0矩阵。

哪些参数应用LoRA
1 LoRA 已经被作者打包到了loralib中:pip install loralib
可以选择用loralib中实现的对应层来替换一些层。目前loralib只支持 nn.Linear、nn.Embedding 和 nn.Conv2d。
2 LoRA与Transformer的结合也很简单:可应用在attention层的 W_q, W_k, W_v, W_o 中的一个或多个。仅在QKV attention的计算中增加一个旁路,而不动MLP模块:We limit our study to only adapting the attention weights for downstream tasks and freeze the MLP modules (so they are not trained in downstream tasks) both for simplicity and parameter-efficiency.
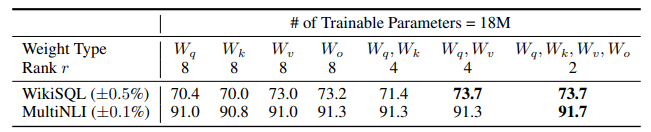
对一个参数用比较大的rank更新,不如对多个参数用很小的rank更新,证明low_rank更新的合理性。
WHAT IS THE OPTIMAL RANK r FOR LORA?
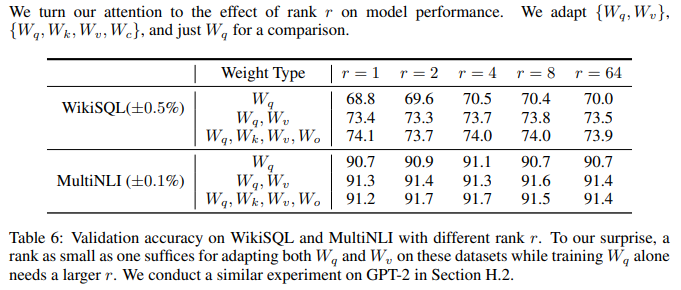
关于∆W

1, ∆W has a stronger correlation with W compared to a random matrix, indicating that ∆W amplifies some features that are already in W.
2,instead of repeating the top singular directions of W, ∆W only amplifies directions that are not
emphasized in W.
3, the amplification factor is rather huge: 21.5 ≈ 6.91/0.32 for r = 4.
参数减少量
On GPT-3 175B, we reduce the VRAM consumption during training from 1.2TB to 350GB.
With r = 4 and only the query and value projection matrices being adapted, the checkpoint size is reduced by roughly 10,000× (from 350GB to 35MB). (We still need the 350GB model during deployment; however, storing 100 adapted models only requires 350GB + 35MB * 100 ≈ 354GB as opposed to 100 * 350GB ≈ 35TB.)
两种部署方法
方法1:将pretrained checkpoint统一部署,将为了特定任务训练的 BA 单独部署。这样做,当下游任务很多时,存储空间不会增加很多。
方法2:将W_0+BA的值直接算出来部署,此时和pretrained模型具有一样的参数量和latency。在生产环境部署时,LoRA可以不引入推理延迟,只需要将预训练模型参数 W0 与LoRA参数进行合并(也就是所谓的模型合并)即可得到微调后的模型参数: W=W0+BA ,在生产环境中像以前一样进行推理,即微调前计算 h=W0x ,现在计算 h=Wx ,没有额外延迟。现在不少模型仅发布LoRA权重,需要本地与基模型进行模型合并才能使用的原理就在于此。
from:https://blog.csdn.net/pipisorry/article/details/130978244
ref: [LoRA: Low-Rank Adaptation of Large Language Models]
[LoRA: Low-Rank Adaptation of Large Language Models 简读 - 知乎]**
代码: GitHub - microsoft/LoRA: Code for loralib
[微软LoRA: Low-Rank Adaptation of Large Language Models 代码解读 - 知乎]






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结