您现在的位置是:首页 >技术交流 >7、Base批量装载-Bulk load(示例二:写千万级数据-mysql数据以ORCFile写入hdfs,然后导入hbase)网站首页技术交流
7、Base批量装载-Bulk load(示例二:写千万级数据-mysql数据以ORCFile写入hdfs,然后导入hbase)
Apache Hbase 系列文章
1、hbase-2.1.0介绍及分布式集群部署、HA集群部署、验证、硬件配置推荐
2、hbase-2.1.0 shell基本操作详解
3、HBase的java API基本操作(创建、删除表以及对数据的添加、删除、查询以及多条件查询)
4、HBase使用(namespace、数据分区、rowkey设计、原生api访问hbase)
5、Apache Phoenix(5.0.0-5.1.2) 介绍及部署、使用(基本使用、综合使用、二级索引示例)、数据分区示例
6、Base批量装载——Bulk load(示例一:基本使用示例)
7、Base批量装载-Bulk load(示例二:写千万级数据-mysql数据以ORCFile写入hdfs,然后导入hbase)
8、HBase批量装载-Bulk load(示例三:写千万级数据-mysql数据直接写成Hbase需要的数据,然后导入hbase)
文章目录
本文主要介绍Bulk load的用法,即MapReduce和bulk load的配合使用。
本文是介绍Bulk load用法的系列的第二篇。
本文前提依赖hbase可用、phoenix可用、mysql可用、hadoop是HA环境。
本文分为2个部分,即实现步骤和实现。
一、实现步骤
示例二:本示例包含
1、从mysql数据库中导出1260万(12606948)数据到ORC文件,并写入HDFS中
2、从HDFS中读取ORC数据文件,写成Hbase导入数据需要的格式
3、加载数据到Hbase中
4、通过phoenix客户端查询数据
5、hadoop环境是HA
二、实现
1、pom.xml
本pom.xml文件不仅仅是本示例的依赖,还有其他的项目的依赖,没有单独的拆分。
<?xml version="1.0"?>
<project
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"
xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.okcard</groupId>
<artifactId>bigdata-component</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<groupId>com.okcard</groupId>
<artifactId>hbase</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>hbase</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<!-- hadoop的通用包 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.5</version>
</dependency>
<!-- Xml操作相关 -->
<dependency>
<groupId>com.github.cloudecho</groupId>
<artifactId>xmlbean</artifactId>
<version>1.5.5</version>
</dependency>
<!-- 操作Office库 -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>4.0.1</version>
</dependency>
<!-- 操作JSON -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<!-- phoenix core -->
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
<!-- 解决打包 Failure to find org.glassfish:javax.el:pom:3.0.1-b08-SNAPSHOT in xxx -->
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- phoenix 客户端 -->
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-queryserver-client</artifactId>
<version>5.0.0-HBase-2.0</version>
<!-- 解决打包 Failure to find org.glassfish:javax.el:pom:3.0.1-b08-SNAPSHOT in xxx -->
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- HBase对mapreduce的支持 -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.1.0</version>
</dependency>
<!-- hadoop mr任务客户端 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.7.5</version>
</dependency>
<!-- 客户端 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.5</version>
</dependency>
<!-- hadoop权限认证相关 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.7.5</version>
</dependency>
<!-- 方便操作文件apache的工具类包 -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>org.apache.htrace</groupId>
<artifactId>htrace-core</artifactId>
<version>3.2.0-incubating</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>2.5.6</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>
<!-- ORC文件依赖 -->
<dependency>
<groupId>org.apache.orc</groupId>
<artifactId>orc-shims</artifactId>
<version>1.6.3</version>
</dependency>
<dependency>
<groupId>org.apache.orc</groupId>
<artifactId>orc-core</artifactId>
<version>1.6.3</version>
</dependency>
<dependency>
<groupId>org.apache.orc</groupId>
<artifactId>orc-mapreduce</artifactId>
<version>1.6.3</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
</dependencies>
</project>
2、将数据库中1260万数据导出成ORC文件
用到了User对象,由于是以user对象写出的数据,故需要实现hdfs要求的序列化。同时,在Hbase中解析也需要使用user,没有重复创建User,使用的是同一个User.java,Hbase解析中使用普通的User.Java即可,不需要序列化。
1)、java bean
package org.hbase.mr.largedata;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
import lombok.Data;
/**
* 实现Hadoop序列化接口Writable 从数据库读取/写入数据库的对象应实现DBWritable
*
* @author chenw
*/
@Data
public class User implements Writable, DBWritable {
private int id;
private String userName;
private String password;
private String phone;
private String email;
private String createDay;
@Override
public void write(PreparedStatement ps) throws SQLException {
ps.setInt(1, id);
ps.setString(2, userName);
ps.setString(3, password);
ps.setString(4, phone);
ps.setString(5, email);
ps.setString(6, createDay);
}
@Override
public void readFields(ResultSet rs) throws SQLException {
this.id = rs.getInt(1);
this.userName = rs.getString(2);
this.password = rs.getString(3);
this.phone = rs.getString(4);
this.email = rs.getString(5);
this.createDay = rs.getString(6);
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(id);
out.writeUTF(userName);
out.writeUTF(password);
out.writeUTF(phone);
out.writeUTF(email);
out.writeUTF(createDay);
}
@Override
public void readFields(DataInput in) throws IOException {
id = in.readInt();
userName = in.readUTF();
password = in.readUTF();
phone = in.readUTF();
email = in.readUTF();
createDay = in.readUTF();
}
public String toString() {
return id + " " + userName + " " + password + " " + phone + " " + email + " " + createDay;
}
}
2)、ReadUserFromMysqlToOrcFile.java
该类是实现将mysql数据以ORC文件形式写入HDFS中
package org.hbase.mr.largedata.file;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.orc.OrcConf;
import org.apache.orc.TypeDescription;
import org.apache.orc.mapred.OrcStruct;
import org.apache.orc.mapreduce.OrcOutputFormat;
import org.hbase.mr.bank.BankRecordBulkLoad;
import org.hbase.mr.largedata.User;
import org.springframework.util.StopWatch;
/**
* 从mysql中读取user表数据,并写入orc文件
*
* @author chenw
*/
public class ReadUserFromMysqlToOrcFile extends Configured implements Tool {
private static final String SCHEMA = "struct<id:int,userName:string,password:string,phone:string,email:string,createDay:string>";
static String out = "hdfs://HadoopHAcluster//hbasetest/user/textuser/out";
@Override
public int run(String[] args) throws Exception {
OrcConf.MAPRED_OUTPUT_SCHEMA.setString(this.getConf(), SCHEMA);
Configuration conf = getConf();
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://192.168.10.44:3306/test", "root",
"root");
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(this.getClass());
job.setInputFormatClass(DBInputFormat.class);
DBInputFormat.setInput(job, User.class, "select id, user_Name,pass_word,phone,email,create_day from dx_user",
// 12606948 条数据
"select count(*) from dx_user ");
// DBInputFormat.setInput(job, User.class,
// "select id, user_Name,pass_word,phone,email,create_day from dx_user where user_name = 'alan2452'",
// "select count(*) from dx_user where user_name = 'alan2452'");
Path outputDir = new Path(out);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, outputDir);
job.setMapperClass(ReadUserFromMysqlToOrcFileMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(OrcStruct.class);
job.setOutputFormatClass(OrcOutputFormat.class);
job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
StopWatch clock = new StopWatch();
clock.start(BankRecordBulkLoad.class.getSimpleName());
// 1. 使用HBaseConfiguration.create()加载配置文件
System.setProperty("HADOOP_USER_NAME", "alanchan");
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://HadoopHAcluster");
conf.set("dfs.nameservices", "HadoopHAcluster");
conf.set("dfs.ha.namenodes.HadoopHAcluster", "nn1,nn2");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn1", "server1:8020");
conf.set("dfs.namenode.rpc-address.HadoopHAcluster.nn2", "server2:8020");
conf.set("dfs.client.failover.proxy.provider.HadoopHAcluster","org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
int status = ToolRunner.run(conf, new ReadUserFromMysqlToOrcFile(), args);
System.exit(status);
clock.stop();
System.out.println(clock.prettyPrint());
}
static class ReadUserFromMysqlToOrcFileMapper extends Mapper<LongWritable, User, NullWritable, OrcStruct> {
// 获取字段描述信息
private TypeDescription schema = TypeDescription.fromString(SCHEMA);
// 构建输出的Key
private final NullWritable outKey = NullWritable.get();
// 构建输出的Value为ORCStruct类型
private final OrcStruct outValue = (OrcStruct) OrcStruct.createValue(schema);
protected void map(LongWritable key, User value, Context context) throws IOException, InterruptedException {
Counter counter = context.getCounter("mysql_records_counters", "User Records");
counter.increment(1);
// 将所有字段赋值给Value中的列
outValue.setFieldValue(0, new IntWritable(value.getId()));
outValue.setFieldValue(1, new Text(value.getUserName()));
outValue.setFieldValue(2, new Text(value.getPassword()));
outValue.setFieldValue(3, new Text(value.getPhone()));
outValue.setFieldValue(4, new Text(value.getEmail()));
outValue.setFieldValue(5, new Text(value.getCreateDay()));
context.write(outKey, outValue);
}
}
}
3、解析ORC文件成爲Hbase導入所需的文件
即滿足Hbase導入需要的key-value格式
Mapper<NullWritable, OrcStruct, ImmutableBytesWritable, MapReduceExtendedCell>
package org.hbase.mr.largedata.file;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.RegionLocator;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.util.MapReduceExtendedCell;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.orc.mapred.OrcStruct;
import org.apache.orc.mapreduce.OrcInputFormat;
import org.hbase.mr.largedata.User;
import org.springframework.util.StopWatch;
/**
* 将HDFS上的ORC文件解析成Hbase导入所需文件,即须与Hbase导入文件的key-value保持一致
* @author chenw
*
*/
public class UserBulkLoadTextToHbase extends Configured implements Tool {
static String in = "hdfs://HadoopHAcluster/hbasetest/user/textuser/out";
static String out = "hdfs://HadoopHAcluster/hbasetest/user/textuser/data";
TableName tableName = TableName.valueOf("USER:TEXTUSER");
public static void main(String[] args) throws Exception {
StopWatch clock = new StopWatch();
clock.start(UserBulkLoadTextToHbase.class.getSimpleName());
// 1. 使用HBaseConfiguration.create()加载配置文件
System.setProperty("HADOOP_USER_NAME", "alanchan");
Configuration configuration = HBaseConfiguration.create();
configuration.set("fs.defaultFS", "hdfs://HadoopHAcluster");
configuration.set("dfs.nameservices", "HadoopHAcluster");
configuration.set("dfs.ha.namenodes.HadoopHAcluster", "nn1,nn2");
configuration.set("dfs.namenode.rpc-address.HadoopHAcluster.nn1", "server1:8020");
configuration.set("dfs.namenode.rpc-address.HadoopHAcluster.nn2", "server2:8020");
configuration.set("dfs.client.failover.proxy.provider.HadoopHAcluster","org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
int status = ToolRunner.run(configuration, new UserBulkLoadTextToHbase(), args);
System.exit(status);
clock.stop();
System.out.println(clock.prettyPrint());
}
@Override
public int run(String[] args) throws Exception {
// 2. 创建HBase连接
Connection connection = ConnectionFactory.createConnection(getConf());
// 3. 获取HTable
Table table = connection.getTable(tableName);
Job job = Job.getInstance(getConf(), this.getClass().getName());
job.setJarByClass(this.getClass());
job.setMapperClass(UserBulkLoadTextToHbaseMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(MapReduceExtendedCell.class);
FileInputFormat.addInputPath(job, new Path(in));
job.setInputFormatClass(OrcInputFormat.class);
Path outputDir = new Path(out);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, outputDir);
RegionLocator regionLocator = connection.getRegionLocator(tableName);
HFileOutputFormat2.configureIncrementalLoad(job, table, regionLocator);
return job.waitForCompletion(true) ? 0 : 1;
}
/**
* 读取orc文件,并写成hbase文件
*
* @author chenw
*
*/
static class UserBulkLoadTextToHbaseMapper
extends Mapper<NullWritable, OrcStruct, ImmutableBytesWritable, MapReduceExtendedCell> {
User orcUser = new User();
protected void map(NullWritable key, OrcStruct value, Context context)
throws IOException, InterruptedException {
// 1、从orc文件中解析user
// SCHEMA ="struct<id:int,userName:string,password:string,phone:string,email:string,createDay:string>";
orcUser.setId(Integer.parseInt(value.getFieldValue("id").toString()));
orcUser.setUserName(value.getFieldValue("userName").toString());
orcUser.setPassword(value.getFieldValue("password").toString());
orcUser.setPhone(value.getFieldValue("phone").toString());
orcUser.setEmail(value.getFieldValue("email").toString());
orcUser.setCreateDay(value.getFieldValue("createDay").toString());
// 2、 从实体类中获取ID,并转换为rowkey,hbase中的字段设置为大写,为phoenix建索引奠定基础
String rowkeyString = String.valueOf(orcUser.getId() + "-" + orcUser.getUserName());
byte[] rowkeyByteArray = Bytes.toBytes(rowkeyString);
byte[] columnFamily = Bytes.toBytes("C1");
byte[] colId = Bytes.toBytes("ID");
byte[] colUserName = Bytes.toBytes("USERNAME");
byte[] colPassword = Bytes.toBytes("PASSWORD");
byte[] colPhone = Bytes.toBytes("PHONE");
byte[] colEmail = Bytes.toBytes("EMAIL");
byte[] colCreateDay = Bytes.toBytes("CREATEDAY");
// 3、 构建输出key:new ImmutableBytesWrite(rowkey)
ImmutableBytesWritable immutableBytesWritable = new ImmutableBytesWritable(rowkeyByteArray);
// 4、 使用KeyValue类构建单元格,每个需要写入到表中的字段都需要构建出来单元格
KeyValue kvId = new KeyValue(rowkeyByteArray, columnFamily, colId, Bytes.toBytes(orcUser.getId()));
KeyValue kvUserName = new KeyValue(rowkeyByteArray, columnFamily, colUserName,Bytes.toBytes(orcUser.getUserName()));
KeyValue kvPassword = new KeyValue(rowkeyByteArray, columnFamily, colPassword,Bytes.toBytes(orcUser.getPassword()));
KeyValue kvPhone = new KeyValue(rowkeyByteArray, columnFamily, colPhone, Bytes.toBytes(orcUser.getPhone()));
KeyValue kvEmail = new KeyValue(rowkeyByteArray, columnFamily, colEmail, Bytes.toBytes(orcUser.getEmail()));
KeyValue kvCreateDay = new KeyValue(rowkeyByteArray, columnFamily, colCreateDay,Bytes.toBytes(orcUser.getCreateDay()));
// 5、使用context.write将输出输出
// 构建输出的value:new MapReduceExtendedCell(keyvalue对象)
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvId));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvUserName));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvPassword));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvPhone));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvEmail));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvCreateDay));
}
}
}
4、创建hbase表
在hbase shell命令下
1)、創建namespace
create_namespace "USER"
2)、創建表
create "USER:TEXTUSER", { NAME => "C1", COMPRESSION => "GZ"}, { NUMREGIONS => 6, SPLITALGO => "HexStringSplit"}
--- 可以查看数据量
hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'USER:TEXTUSER'
-- 或
count 'USER:TEXTUSER'
5、加载数据文件到Hbase
生成ORC文件可以在本地的Eclipse中执行,解析ORC文件在Hadoop环境中执行
1)、打包
mvn package clean -Dmaven.test.skip=true
mvn package -Dmaven.test.skip=true
执行。加载数据文件到Hbase后,会自动删除列蔟下的数据文件
hadoop jar hbase-0.0.1-SNAPSHOT.jar org.hbase.mr.largedata.file.UserBulkLoadTextToHbase
2)、导入Hbase
#hbase集群中任何一个机器上执行
hbase org.apache.hadoop.hbase.tool.LoadIncrementalHFiles /hbasetest/user/textuser/data USER:TEXTUSER
#Hbase shell客户端执行
scan 'USER:TEXTUSER', {LIMIT => 3, FORMATTER => 'toString'}
hbase(main):004:0> scan 'USER:TEXTUSER', {LIMIT => 3, FORMATTER => 'toString'}
ROW COLUMN+CELL
1000000054-alan13256 column=C1:CREATEDAY, timestamp=1665400322587, value=2021-12-27 00:00:00.0
1000000054-alan13256 column=C1:EMAIL, timestamp=1665400322587, value=alan.chan.chn@163.com
1000000054-alan13256 column=C1:ID, timestamp=1665400322587, value=;��6
1000000054-alan13256 column=C1:PASSWORD, timestamp=1665400322587, value=256835
1000000054-alan13256 column=C1:PHONE, timestamp=1665400322587, value=13977776789
1000000054-alan13256 column=C1:USERNAME, timestamp=1665400322587, value=alan13256
1000000117-alan450672 column=C1:CREATEDAY, timestamp=1665400322587, value=2021-12-25 00:00:00.0
1000000117-alan450672 column=C1:EMAIL, timestamp=1665400322587, value=alan.chan.chn@163.com
1000000117-alan450672 column=C1:ID, timestamp=1665400322587, value=;��u
1000000117-alan450672 column=C1:PASSWORD, timestamp=1665400322587, value=12037
1000000117-alan450672 column=C1:PHONE, timestamp=1665400322587, value=13977776789
1000000117-alan450672 column=C1:USERNAME, timestamp=1665400322587, value=alan450672
1000000402-alan437180 column=C1:CREATEDAY, timestamp=1665400322587, value=2021-12-28 00:00:00.0
1000000402-alan437180 column=C1:EMAIL, timestamp=1665400322587, value=alan.chan.chn@163.com
1000000402-alan437180 column=C1:ID, timestamp=1665400322587, value=;�˒
1000000402-alan437180 column=C1:PASSWORD, timestamp=1665400322587, value=243547
1000000402-alan437180 column=C1:PHONE, timestamp=1665400322587, value=13977776789
1000000402-alan437180 column=C1:USERNAME, timestamp=1665400322587, value=alan437180
3 row(s)
Took 0.1448 seconds
6、创建phoenix视图
CREATE view USER.TEXTUSER
(
ID varchar primary key,
C1.username varchar,
C1.password varchar,
C1.phone varchar,
C1.email varchar,
C1.createday varchar
);
0: jdbc:phoenix:server2:2118> CREATE view USER.TEXTUSER
. . . . . . . . . . . . . . > (
. . . . . . . . . . . . . . > ID varchar primary key,
. . . . . . . . . . . . . . > C1.username varchar,
. . . . . . . . . . . . . . > C1.password varchar,
. . . . . . . . . . . . . . > C1.phone varchar,
. . . . . . . . . . . . . . > C1.email varchar,
. . . . . . . . . . . . . . > C1.createday varchar
. . . . . . . . . . . . . . > );
No rows affected (7.495 seconds)
7、验证
#phoenix客户端查询
0: jdbc:phoenix:server2:2118> select * from user.textuser limit 10 offset 0;
+------------------------+-------------+-----------+--------------+------------------------+------------------------+
| ID | USERNAME | PASSWORD | PHONE | EMAIL | CREATEDAY |
+------------------------+-------------+-----------+--------------+------------------------+------------------------+
| 1000000054-alan13256 | alan13256 | 256835 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 1000000117-alan450672 | alan450672 | 12037 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 1000000402-alan437180 | alan437180 | 243547 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 1000000504-alan61609 | alan61609 | 572447 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 1000000600-alan4646 | alan4646 | 385328 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 1000000764-alan784307 | alan784307 | 487422 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 1000000801-alan843250 | alan843250 | 823528 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 100000101-alan44825 | alan44825 | 245584 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 1000001254-alan93950 | alan93950 | 136182 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 1000001554-alan66194 | alan66194 | 145151 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
+------------------------+-------------+-----------+--------------+------------------------+------------------------+
10 rows selected (0.038 seconds)
0: jdbc:phoenix:server2:2118> select count(*) from user.textuser;
+-----------+
| COUNT(1) |
+-----------+
| 12606948 |
+-----------+
1 row selected (27.625 seconds)
0: jdbc:phoenix:server2:2118> select * from user.textuser where id = '1000000054-alan13256';
+-----------------------+------------+-----------+--------------+------------------------+------------------------+
| ID | USERNAME | PASSWORD | PHONE | EMAIL | CREATEDAY |
+-----------------------+------------+-----------+--------------+------------------------+------------------------+
| 1000000054-alan13256 | alan13256 | 256835 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
+-----------------------+------------+-----------+--------------+------------------------+------------------------+
1 row selected (0.112 seconds)
0: jdbc:phoenix:server2:2118> select * from user.textuser where id like '%alan66194' limit 10 offset 0;
+-----------------------+------------+-----------+--------------+------------------------+------------------------+
| ID | USERNAME | PASSWORD | PHONE | EMAIL | CREATEDAY |
+-----------------------+------------+-----------+--------------+------------------------+------------------------+
| 1000001554-alan66194 | alan66194 | 145151 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 1007666086-alan66194 | alan66194 | 385075 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 1043676715-alan66194 | alan66194 | 88428 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 1047614567-alan66194 | alan66194 | 464386 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 1118250550-alan66194 | alan66194 | 614253 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 112636207-alan66194 | alan66194 | 728351 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 1153887738-alan66194 | alan66194 | 604027 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 1163389712-alan66194 | alan66194 | 736322 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 1182190352-alan66194 | alan66194 | 343481 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 1227886174-alan66194 | alan66194 | 425608 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
+-----------------------+------------+-----------+--------------+------------------------+------------------------+
10 rows selected (13.538 seconds)
8、存在的问题
1)、數據存儲分佈不均匀
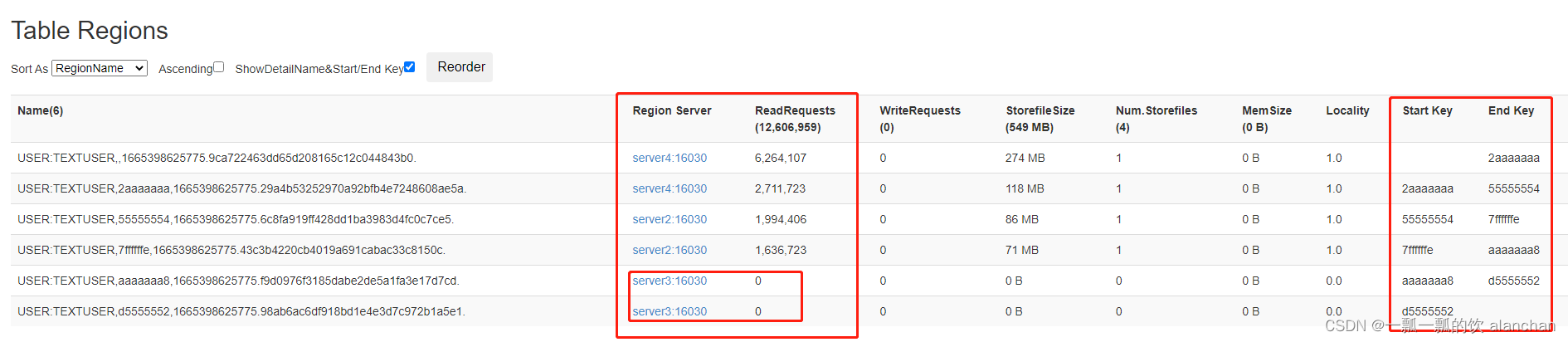
2)、創建表分區語句
create “USER:TEXTUSER”, { NAME => “C1”, COMPRESSION => “GZ”}, { NUMREGIONS => 6, SPLITALGO => “HexStringSplit”}
3)、rowkey的設置語句
String rowkeyString = String.valueOf(orcUser.getId() + “-” + orcUser.getUserName());
4)、原因
由於userID是順序生成的,username也是順序生成的,故存在分區數據存在熱點數據。
5)、解決方法
避免數據熱點出現,需要重新進行rowkey設計,避免因爲rowkey設計不當而造成的數據分區不均情況。
-
ROWKEY设计
之前rowkey=id-username,其中id是自增的,username是以alan+隨機數進行組合。如此出現了rowkey熱點,數據一半以上落入了server4。
为了确保数据均匀分布在每个Region,現重新設計rowkey。采用盡可能多的字段和不規律的字段組合的rowkey,即 rowkey = MD5Hash_id_userName_phone_createDay
以MD5Hash作为前缀,是爲了更加的分散rowkey。 -
代碼
以下代碼為示例性,不完整
static class UserBulkLoadTextToHbaseMapper
extends Mapper<NullWritable, OrcStruct, ImmutableBytesWritable, MapReduceExtendedCell> {
User orcUser = new User();
protected void map(NullWritable key, OrcStruct value, Context context) throws IOException, InterruptedException{
// 1、从orc文件中解析user
// 2、 从实体类中获取ID,并转换为rowkey,hbase中的字段设置为大写,为phoenix建索引奠定基础
// String rowkeyString = String.valueOf(orcUser.getId() + "-" + orcUser.getUserName());
// byte[] rowkeyByteArray = Bytes.toBytes(rowkeyString);
// rowkey = MD5Hash_id_userName_phone_createDay
byte[] rowkeyByteArray = getRowkey(orcUser);
byte[] columnFamily = Bytes.toBytes("C1");
byte[] colId = Bytes.toBytes("ID");
byte[] colUserName = Bytes.toBytes("USERNAME");
// 3、 构建输出key:new ImmutableBytesWrite(rowkey)
ImmutableBytesWritable immutableBytesWritable = new ImmutableBytesWritable(rowkeyByteArray);
// 4、 使用KeyValue类构建单元格,每个需要写入到表中的字段都需要构建出来单元格
KeyValue kvId = new KeyValue(rowkeyByteArray, columnFamily, colId, Bytes.toBytes(orcUser.getId()));
KeyValue kvUserName = new KeyValue(rowkeyByteArray, columnFamily, colUserName,Bytes.toBytes(orcUser.getUserName()));
// 5、使用context.write将输出输出
// 构建输出的value:new MapReduceExtendedCell(keyvalue对象)
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvId));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvUserName));
}
protected static byte[] getRowkey(User user) {
// rowkey = MD5Hash_id_userName_phone_createDay
StringBuilder rowkeyBuilder =new StringBuilder();
rowkeyBuilder.append(user.getId()).append("_").append(user.getUserName()).append("_").append(user.getPhone()).append("_").append(user.getCreateDay());
// 使用Bytes.toBytes将拼接出来的字符串转换为byte[]数组
// 使用MD5Hash.getMD5AsHex生成MD5值,并取其前8位
String md5AsHex = MD5Hash.getMD5AsHex(rowkeyBuilder.toString().getBytes());
String md5Hex8bit = md5AsHex.substring(0, 8);
return Bytes.toBytes(md5Hex8bit + "_" + rowkeyBuilder.toString());
}
}
- 驗證
#爲了保證環境的乾净,本次驗證是把原來的數據全部刪除做的。
1、disable “USER:TEXTUSER”
2、drop “USER:TEXTUSER”
3、修改後的代碼重新打包並上傳至hadoop的執行機器上
4、在hadoop的集群中執行
hadoop jar hbase-0.0.1-SNAPSHOT.jar org.hbase.mr.largedata.file.UserBulkLoadTextToHbase
5、在hbase的集群中執行
hbase org.apache.hadoop.hbase.tool.LoadIncrementalHFiles /hbasetest/user/textuser/data USER:TEXTUSER
6、在phoenix客戶端刪除原來創建的視圖
drop view user.textuser;
7、在phoenix客戶端創建新的視圖,執行
CREATE view USER.TEXTUSER
(
rk varchar primary key,
C1.id varchar,
C1.username varchar,
C1.password varchar,
C1.phone varchar,
C1.email varchar,
C1.createday varchar
);
--注意:本次創建的視圖將id給展示出來了,上面的例子中是將id作爲rowkey,但其本身的id沒有展示。
8、查詢數據驗證
0: jdbc:phoenix:server2:2118> select count(*) from user.textuser;
+-----------+
| COUNT(1) |
+-----------+
| 12606948 |
+-----------+
1 row selected (14.285 seconds)
0: jdbc:phoenix:server2:2118> select * from user.textuser limit 10 offset 0;
+-------------------------------------------------------------------+-------------+-------------+-----------+--------------+------------------------+------------------------+
| RK | ID | USERNAME | PASSWORD | PHONE | EMAIL | CREATEDAY |
+-------------------------------------------------------------------+-------------+-------------+-----------+--------------+------------------------+------------------------+
| 000000fd_918381146_alan82312_13977776789_2021-12-27 00:00:00.0 | 918381146 | alan82312 | 836314 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 00000280_1180368562_alan55153_13977776789_2021-12-28 00:00:00.0 | 1180368562 | alan55153 | 60528 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 00000480_744323608_alan137521_13977776789_2021-12-25 00:00:00.0 | 744323608 | alan137521 | 331676 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 00000881_986701072_alan497509_13977776789_2021-12-28 00:00:00.0 | 986701072 | alan497509 | 215848 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 000008f4_135235830_alan35114_13977776789_2021-12-27 00:00:00.0 | 135235830 | alan35114 | 477605 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
| 00000a92_410303526_alan70416_13977776789_2021-12-28 00:00:00.0 | 410303526 | alan70416 | 872724 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 00000cb5_1038678143_alan807323_13977776789_2021-12-28 00:00:00.0 | 1038678143 | alan807323 | 307677 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 0000105a_1026241491_alan6285_13977776789_2021-12-28 00:00:00.0 | 1026241491 | alan6285 | 363475 | 13977776789 | alan.chan.chn@163.com | 2021-12-28 00:00:00.0 |
| 000011c2_471466237_alan486814_13977776789_2021-12-25 00:00:00.0 | 471466237 | alan486814 | 378424 | 13977776789 | alan.chan.chn@163.com | 2021-12-25 00:00:00.0 |
| 00001251_1170378231_alan8566_13977776789_2021-12-27 00:00:00.0 | 1170378231 | alan8566 | 4626 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
+-------------------------------------------------------------------+-------------+-------------+-----------+--------------+------------------------+------------------------+
10 rows selected (0.025 seconds)
0: jdbc:phoenix:server2:2118> select * from user.textuser where id ='918381146';
+-----------------------------------------------------------------+------------+------------+-----------+--------------+------------------------+------------------------+
| RK | ID | USERNAME | PASSWORD | PHONE | EMAIL | CREATEDAY |
+-----------------------------------------------------------------+------------+------------+-----------+--------------+------------------------+------------------------+
| 000000fd_918381146_alan82312_13977776789_2021-12-27 00:00:00.0 | 918381146 | alan82312 | 836314 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
+-----------------------------------------------------------------+------------+------------+-----------+--------------+------------------------+------------------------+
1 row selected (18.297 seconds)
0: jdbc:phoenix:server2:2118> select * from user.textuser where id ='918381146';
+-----------------------------------------------------------------+------------+------------+-----------+--------------+------------------------+------------------------+
| RK | ID | USERNAME | PASSWORD | PHONE | EMAIL | CREATEDAY |
+-----------------------------------------------------------------+------------+------------+-----------+--------------+------------------------+------------------------+
| 000000fd_918381146_alan82312_13977776789_2021-12-27 00:00:00.0 | 918381146 | alan82312 | 836314 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
+-----------------------------------------------------------------+------------+------------+-----------+--------------+------------------------+------------------------+
1 row selected (21.486 seconds)
0: jdbc:phoenix:server2:2118> select * from user.textuser where rk = '00001251_1170378231_alan8566_13977776789_2021-12-27 00:00:00.0';
+-----------------------------------------------------------------+-------------+-----------+-----------+--------------+------------------------+------------------------+
| RK | ID | USERNAME | PASSWORD | PHONE | EMAIL | CREATEDAY |
+-----------------------------------------------------------------+-------------+-----------+-----------+--------------+------------------------+------------------------+
| 00001251_1170378231_alan8566_13977776789_2021-12-27 00:00:00.0 | 1170378231 | alan8566 | 4626 | 13977776789 | alan.chan.chn@163.com | 2021-12-27 00:00:00.0 |
+-----------------------------------------------------------------+-------------+-----------+-----------+--------------+------------------------+------------------------+
1 row selected (0.019 seconds)
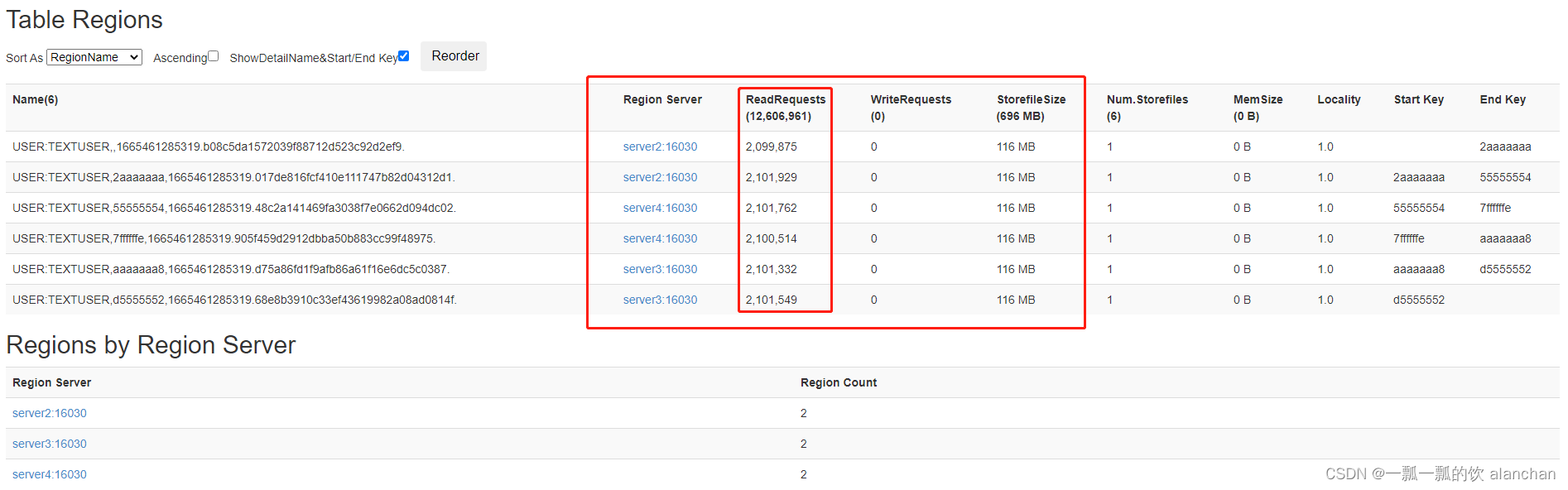
9、驗證數據在regionserver中是否分佈均匀,可見分佈非常均匀。見下圖
10、數據的應用
由上面查詢的結果可以看到,通過rowkey查詢非常快,但通過本身的id查詢則非常的慢。如此與我們設想一致,因爲hbase只針對rowkey有索引創建,但其他的字段并沒有索引創建。
爲了解決其他的字段查詢數據,可以使用hpoenix客戶端創建二級索引進行查詢。
- 源碼(UserBulkLoadTextToHbase.java)
本處只調整了rowkey的部分,其他的沒有變化,故下面是調整部分的代碼,其他的參考本文上面的部分。
package org.hbase.mr.largedata.file;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.RegionLocator;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.util.MD5Hash;
import org.apache.hadoop.hbase.util.MapReduceExtendedCell;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.orc.mapred.OrcStruct;
import org.apache.orc.mapreduce.OrcInputFormat;
import org.hbase.mr.largedata.User;
import org.springframework.util.StopWatch;
/**
* 将HDFS上的ORC文件解析成Hbase导入所需文件,即须与Hbase导入文件的key-value保持一致
* @author chenw
*
*/
public class UserBulkLoadTextToHbase extends Configured implements Tool {
static String in = "hdfs://HadoopHAcluster/hbasetest/user/textuser/out";
static String out = "hdfs://HadoopHAcluster/hbasetest/user/textuser/data";
TableName tableName = TableName.valueOf("USER:TEXTUSER");
public static void main(String[] args) throws Exception {
StopWatch clock = new StopWatch();
clock.start(UserBulkLoadTextToHbase.class.getSimpleName());
// 1. 使用HBaseConfiguration.create()加载配置文件
System.setProperty("HADOOP_USER_NAME", "alanchan");
Configuration configuration = HBaseConfiguration.create();
configuration.set("fs.defaultFS", "hdfs://HadoopHAcluster");
configuration.set("dfs.nameservices", "HadoopHAcluster");
configuration.set("dfs.ha.namenodes.HadoopHAcluster", "nn1,nn2");
configuration.set("dfs.namenode.rpc-address.HadoopHAcluster.nn1", "server1:8020");
configuration.set("dfs.namenode.rpc-address.HadoopHAcluster.nn2", "server2:8020");
configuration.set("dfs.client.failover.proxy.provider.HadoopHAcluster","org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
int status = ToolRunner.run(configuration, new UserBulkLoadTextToHbase(), args);
System.exit(status);
clock.stop();
System.out.println(clock.prettyPrint());
}
@Override
public int run(String[] args) throws Exception {
// 2. 创建HBase连接
Connection connection = ConnectionFactory.createConnection(getConf());
// 3. 获取HTable
Table table = connection.getTable(tableName);
Job job = Job.getInstance(getConf(), this.getClass().getName());
job.setJarByClass(this.getClass());
job.setMapperClass(UserBulkLoadTextToHbaseMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(MapReduceExtendedCell.class);
FileInputFormat.addInputPath(job, new Path(in));
job.setInputFormatClass(OrcInputFormat.class);
Path outputDir = new Path(out);
outputDir.getFileSystem(this.getConf()).delete(outputDir, true);
FileOutputFormat.setOutputPath(job, outputDir);
RegionLocator regionLocator = connection.getRegionLocator(tableName);
HFileOutputFormat2.configureIncrementalLoad(job, table, regionLocator);
return job.waitForCompletion(true) ? 0 : 1;
}
/**
* 读取orc文件,并写成hbase文件
*
* @author chenw
*
*/
static class UserBulkLoadTextToHbaseMapper
extends Mapper<NullWritable, OrcStruct, ImmutableBytesWritable, MapReduceExtendedCell> {
User orcUser = new User();
protected void map(NullWritable key, OrcStruct value, Context context) throws IOException, InterruptedException{
// 1、从orc文件中解析user
// SCHEMA ="struct<id:int,userName:string,password:string,phone:string,email:string,createDay:string>";
orcUser.setId(value.getFieldValue("id").toString());
orcUser.setUserName(value.getFieldValue("userName").toString());
orcUser.setPassword(value.getFieldValue("password").toString());
orcUser.setPhone(value.getFieldValue("phone").toString());
orcUser.setEmail(value.getFieldValue("email").toString());
orcUser.setCreateDay(value.getFieldValue("createDay").toString());
// 2、 从实体类中获取ID,并转换为rowkey,hbase中的字段设置为大写,为phoenix建索引奠定基础
// String rowkeyString = String.valueOf(orcUser.getId() + "-" + orcUser.getUserName());
// byte[] rowkeyByteArray = Bytes.toBytes(rowkeyString);
// rowkey = MD5Hash_id_userName_phone_createDay
byte[] rowkeyByteArray = getRowkey(orcUser);
byte[] columnFamily = Bytes.toBytes("C1");
byte[] colId = Bytes.toBytes("ID");
byte[] colUserName = Bytes.toBytes("USERNAME");
byte[] colPassword = Bytes.toBytes("PASSWORD");
byte[] colPhone = Bytes.toBytes("PHONE");
byte[] colEmail = Bytes.toBytes("EMAIL");
byte[] colCreateDay = Bytes.toBytes("CREATEDAY");
// 3、 构建输出key:new ImmutableBytesWrite(rowkey)
ImmutableBytesWritable immutableBytesWritable = new ImmutableBytesWritable(rowkeyByteArray);
// 4、 使用KeyValue类构建单元格,每个需要写入到表中的字段都需要构建出来单元格
KeyValue kvId = new KeyValue(rowkeyByteArray, columnFamily, colId, Bytes.toBytes(orcUser.getId()));
KeyValue kvUserName = new KeyValue(rowkeyByteArray, columnFamily, colUserName,Bytes.toBytes(orcUser.getUserName()));
KeyValue kvPassword = new KeyValue(rowkeyByteArray, columnFamily, colPassword,Bytes.toBytes(orcUser.getPassword()));
KeyValue kvPhone = new KeyValue(rowkeyByteArray, columnFamily, colPhone, Bytes.toBytes(orcUser.getPhone()));
KeyValue kvEmail = new KeyValue(rowkeyByteArray, columnFamily, colEmail, Bytes.toBytes(orcUser.getEmail()));
KeyValue kvCreateDay = new KeyValue(rowkeyByteArray, columnFamily, colCreateDay,Bytes.toBytes(orcUser.getCreateDay()));
// 5、使用context.write将输出输出
// 构建输出的value:new MapReduceExtendedCell(keyvalue对象)
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvId));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvUserName));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvPassword));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvPhone));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvEmail));
context.write(immutableBytesWritable, new MapReduceExtendedCell(kvCreateDay));
}
protected static byte[] getRowkey(User user) {
// rowkey = MD5Hash_id_userName_phone_createDay
StringBuilder rowkeyBuilder =new StringBuilder();
rowkeyBuilder.append(user.getId()).append("_").append(user.getUserName()).append("_").append(user.getPhone()).append("_").append(user.getCreateDay());
// 使用Bytes.toBytes将拼接出来的字符串转换为byte[]数组
// 使用MD5Hash.getMD5AsHex生成MD5值,并取其前8位
String md5AsHex = MD5Hash.getMD5AsHex(rowkeyBuilder.toString().getBytes());
String md5Hex8bit = md5AsHex.substring(0, 8);
return Bytes.toBytes(md5Hex8bit + "_" + rowkeyBuilder.toString());
}
}
}
实际使用过程中,可以直接根据rowkey查询(因为rowkey的生成规则是已知的,查询时可以构造rowkey进行查询),其他字段可以根据需要进行查询或创建二级索引进行查询。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结