您现在的位置是:首页 >其他 >当Windows里运行spark程序长时间不报错也不出结果(如何将scala程序打包放在虚拟机里运行)网站首页其他
当Windows里运行spark程序长时间不报错也不出结果(如何将scala程序打包放在虚拟机里运行)
当Windows里运行spark程序长时间不报错也不出结果
Windows内存不足也可能导致Spark程序长时间没有报错也没有输出结果的情况。Spark在处理大规模数据时需要大量的内存,如果可用内存不足,可能会导致程序运行缓慢或无法完成任务。
要确认内存是否是问题所在,可以执行以下操作:
- 检查内存使用情况:打开Windows任务管理器,切换到"性能"选项卡,查看"内存"部分。观察可用内存和已使用内存的情况。如果可用内存非常低或接近耗尽,那么内存可能是问题所在。
- 调整Spark内存配置:在Spark应用程序中,您可以通过调整内存相关的配置参数来优化内存使用。例如,
executor.memory参数控制每个执行器的内存分配,spark.driver.memory参数控制驱动程序的内存分配等。根据实际情况,适当增加内存分配可能有助于提高Spark程序的性能和稳定性。 - 增加系统内存:如果计算机内存确实不足,考虑增加系统内存。这可以通过添加更多的物理内存条或升级计算机的内存来实现。增加内存能够提供更大的工作空间,使Spark能够更有效地处理大规模数据。
或者将scala程序打包放在虚拟机里运行.
虚拟机里的虚拟内存通常可以超过本机的物理内存。虚拟内存是指虚拟机操作系统将硬盘空间用作扩展内存的一种机制。当虚拟机的物理内存不足时,操作系统可以将一部分内存中不常用的数据写入到硬盘上的虚拟内存中,从而释放物理内存供其他程序使用。
虚拟内存的大小可以根据虚拟机的配置进行设置,一般可以设置为大于物理内存的值。这使得虚拟机可以在物理内存不足的情况下仍然能够执行更多的任务,但这也可能导致性能下降,因为虚拟内存访问速度相对较慢。
值得注意的是,尽管虚拟机可以使用比物理内存更大的虚拟内存空间,但这并不意味着虚拟机可以在没有任何限制的情况下使用无限制的内存。虚拟内存的总大小仍然受限于宿主机的硬盘空间和虚拟机配置的限制。此外,过度使用虚拟内存可能会导致虚拟机性能下降,因为磁盘访问速度相对较慢。
正文: 近年来,Apache Spark已成为大数据处理和分析的主要工具之一。它提供了一个强大的分布式计算框架,支持多种编程语言,包括Scala。本指南将向您展示如何将Scala程序打包成可在Spark虚拟机中运行的JAR文件。
步骤一:构建Scala项目
首先,确保您的Scala程序是一个独立的项目,并且具有正确的依赖项管理。您可以使用构建工具如sbt(Scala Build Tool)或Maven来管理项目依赖关系。创建一个新的Scala项目,然后在项目配置文件中添加所需的依赖项。
步骤二:添加Spark依赖项
在构建配置文件(例如build.sbt或pom.xml)中添加Spark依赖项,以便能够在Spark集群中运行您的应用程序。根据您使用的构建工具和Spark版本,您可以在Spark官方文档中找到相应的依赖项信息。确保在配置文件中包含所有必要的Spark库和依赖项。
步骤三:编译项目
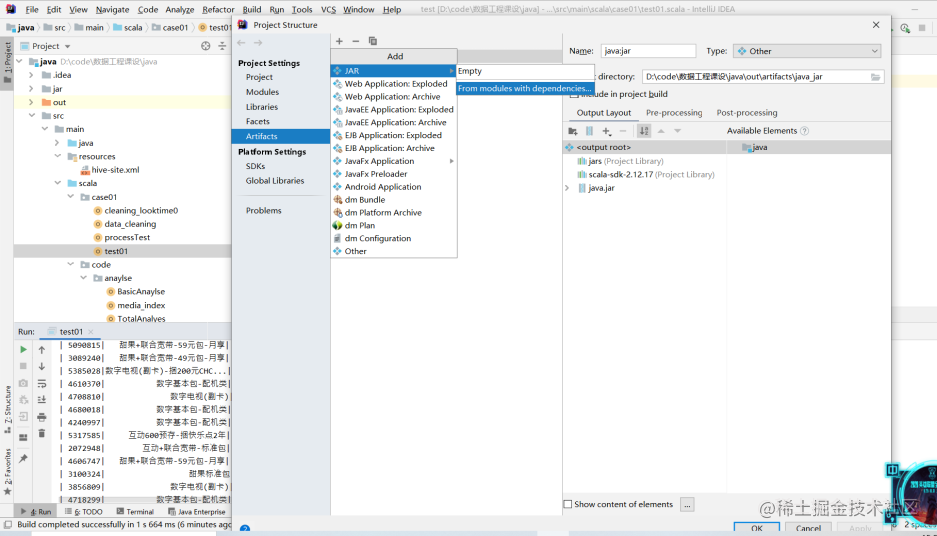
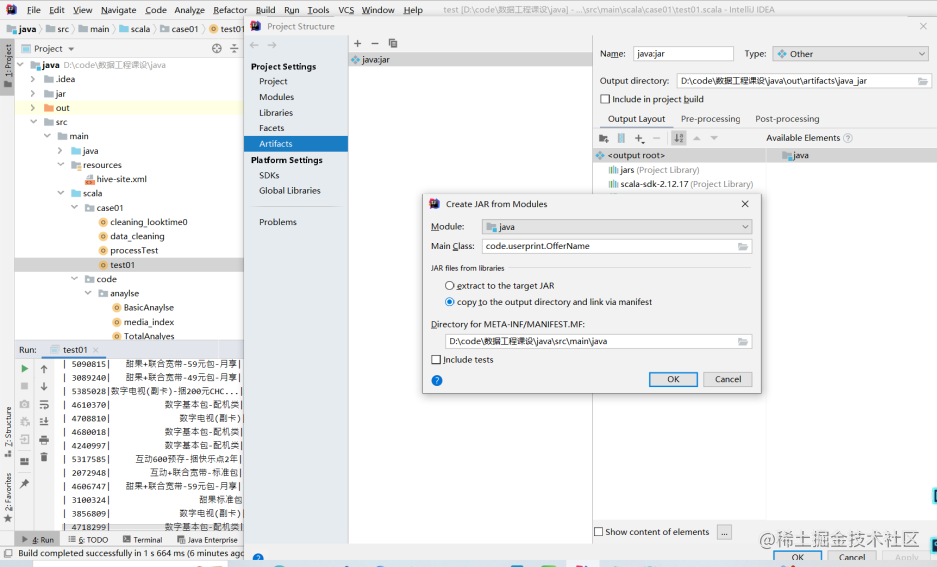
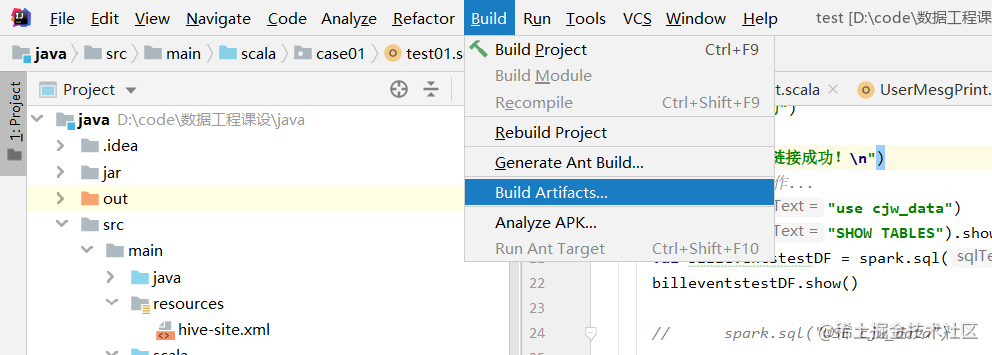
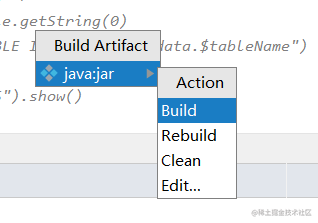
步骤四:上传JAR文件到Spark虚拟机
将生成的JAR文件上传到运行Spark的虚拟机或集群中。您可以使用scp或其他文件传输工具将JAR文件复制到目标机器上。确保将JAR文件放在可被Spark虚拟机访问的位置。
步骤五:启动Spark应用程序
使用Spark提供的spark-submit脚本来提交和运行您的应用程序。在命令行中,使用以下命令:
spark-submit --master spark://master:7077 --class code.userprint.OfferName /opt/scala.jar






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结