您现在的位置是:首页 >技术交流 >聊聊开源的类ChatGPT工作——ChatGLM网站首页技术交流
聊聊开源的类ChatGPT工作——ChatGLM
这是”聊聊开源的类ChatGPT工作“的第二篇,写第一篇[7]的时候,当时恰巧MOSS开源,就顺手写了MOSS。但要问目前中文领域的“开源”的语言模型谁更强,公认的还是ChatGLM-6B(以下简称ChatGLM)。
下面是官方对ChatGLM的介绍:
ChatGLM-6B,结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。经过约 1T 标识符的中英双语训练,辅以监督微调、 反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 虽然规模不及千亿模型,但大大降低了用户部署的门槛,并且已经能生成相当符合人类偏好的回答。

Part1整体效果
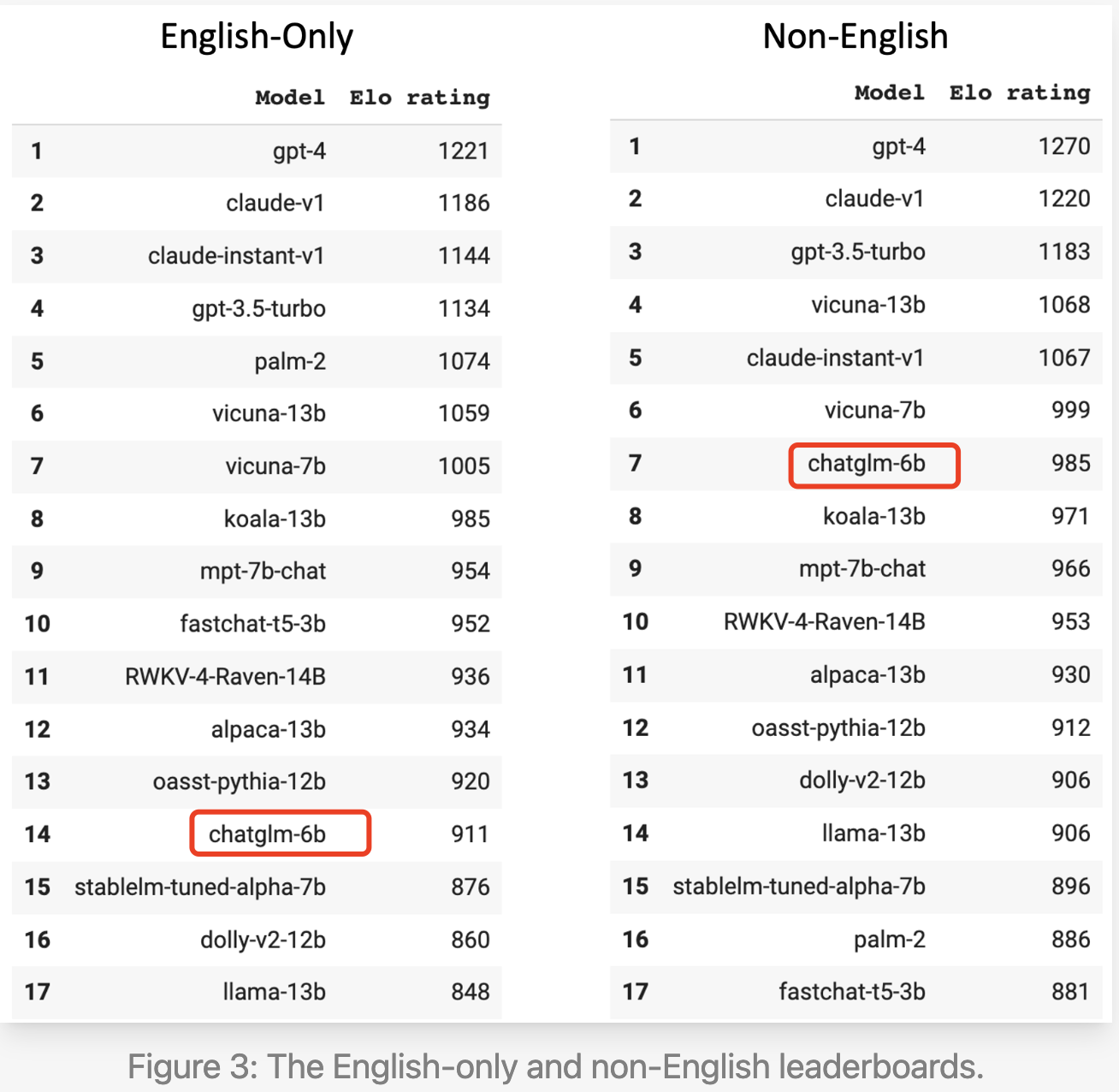
我们通过05-25更新的lmsys arena Leaderboard[1]可以看到:
-
在英文问题上,6b的规模排在第14,排在他前面且规模更小的只有fastchat-t5-3b,fastchat-t5-3b和vicuna都出自lmsys团队,采用真实用户数据——shareGPT,它对模型效果提升十分明显。
-
在非英文问题上,ChatGLM排名第7,规模比前面的模型都小,排在它前面的模型基座来自于Open AI、Anthropic和Meta(vicuna的基座是LLaMA)。
Part2基座
这里首先要提到ChatGLM团队先前的工作——GLM 130B。这是一份相当扎实的工作,[2]中还介绍他们在过程中碰到的问题和解决方案,对大模型训练十分有参考性。另外,值得一提的是,ChatGLM有别于类似GPT、LLaMA的单向解码器,它在上下文部分是双向的,而输出部分是单向的,通过下图可以清晰地看明白:

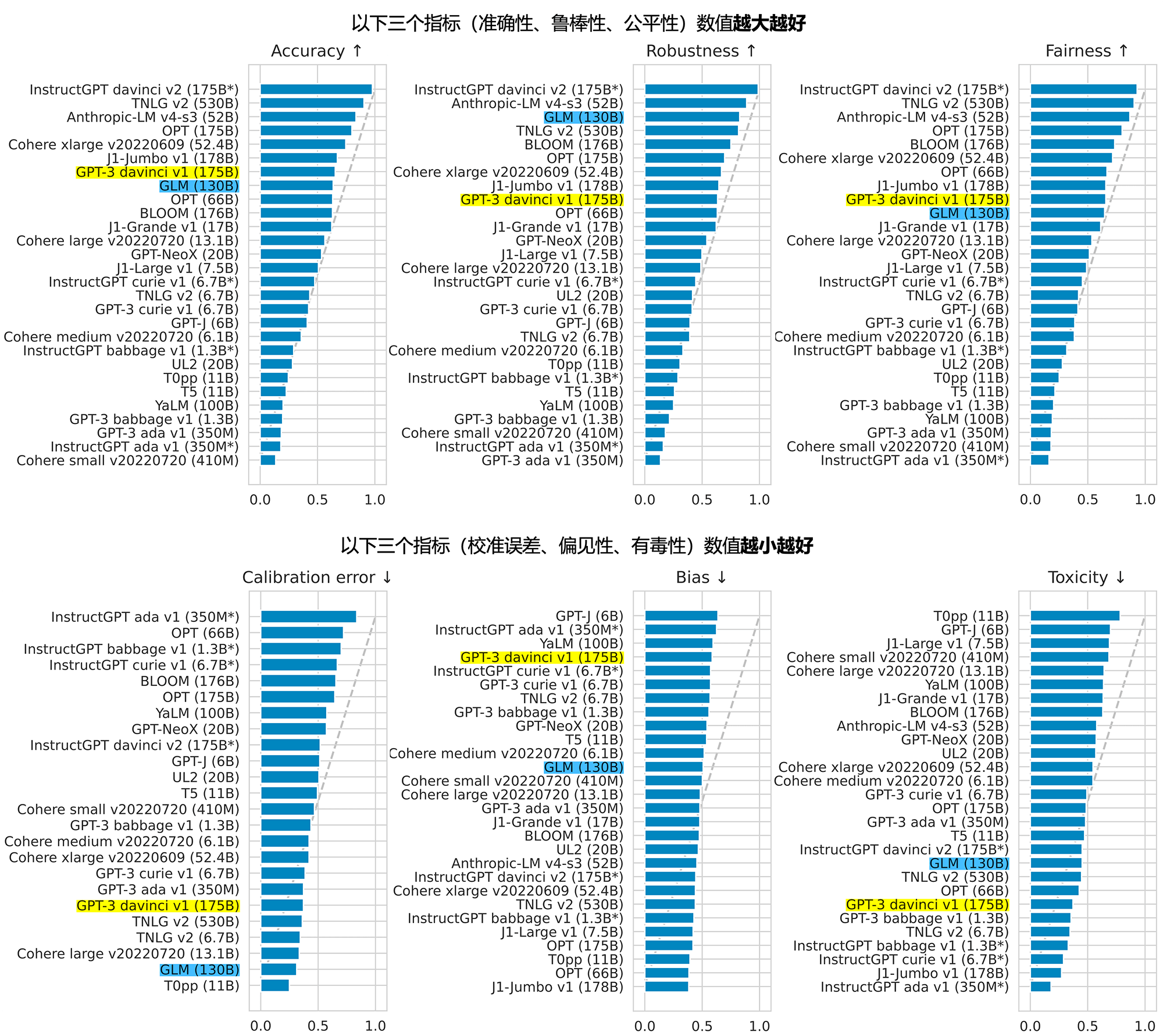
ChatGLM的官网[3]引用了HELM的大模型评估,可以看到GLM和GPT-3效果接近。但[2]中有提到,GLM在预训练过程中加入了指令数据,这无疑会提升模型在下游任务的表现,而GPT-3仅仅是做了文本的预训练。
现在我们回到ChatGLM,从官方的描述中我们可以知道:ChatGLM经过 1T 标识符的中英双语训练。有了GLM-130B的经验,在6B规模上做预训练便轻车熟路。值得注意的点是——1T标识符的中英双语,相信这是ChatGLM在中文上表现优异的重要原因,虽然说在英文习得的能力也能迁移到中文上,但迁移的过程中会损失多少,以及有些表达是只有在中文语境下才特有的。所以现在BELLE[4]、Linly[5]等开源工作都会选择在LLaMA的基础上进行包括中文的继续预训练。关键是,中文的优质数据是少于英文的,不知道这1T标识符的中英双语是多少个epoch的结果,如果只是1个epoch,那意味着ChatGLM的数据优势十分明显。数据是data-centric AI范式的关键。
Part3开源
按照原本的节奏,应该要介绍ChatGLM的SFT和RHLF相关的工作,尤其是官方明确提到——ChatGLM做了RHLF。但可惜的是这部分官方并没有开源。再看最近推出的VisualGLM[6],这似乎是该团队的风格——只开源了模型权重,更为关键的数据和代码并没有开源。
这无所谓好坏,从商业角度出发,如果模型效果没有好到open AI、Anthropic这种一骑绝尘的程度,开源一个效果打折的模型权重,我倒觉得这是一条不错的路径:
-
一是达到了很好PR的效果,能够吸引到更多的合作伙伴。
-
二是能够借助开源的力量,每个基于该模型的项目,都算是为官方探路,一旦发现不错的idea,便可使用自己手中还握着的效果更好的模型实践一遍,节约了很多试错成本。
所以,对于开源的工作,真的要致以最大的敬意,后人是在他们的肩膀上前进的。
至此,“聊聊开源的类ChatGPT工作”系列的第二篇就结束啦,希望下一篇聊什么?欢迎留言~
——2023.05.31
Reference
[1] Chatbot Arena Leaderboard Updates (Week 4) | LMSYS Org
[2] GLM-130B/README_zh.md at main · THUDM/GLM-130B · GitHub
[4] GitHub - LianjiaTech/BELLE: BELLE: Be Everyone's Large Language model Engine(开源中文对话大模型)
[5] GitHub - CVI-SZU/Linly: Chinese-LLaMA基础模型;ChatFlow中文对话模型;中文OpenLLaMA模型;NLP预训练/指令微调数据集
[7] 聊聊开源的类ChatGPT工作——MOSS






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结