您现在的位置是:首页 >技术教程 >Hudi Flink SQL代码示例及本地调试网站首页技术教程
Hudi Flink SQL代码示例及本地调试
前言
之前在Flink Hudi DataStream API代码示例中总结了Hudi Flink DataStream API的代码及本地调试,并且在文中提到其实大家用Table API更多一些,但是我感觉Table API调试源码可能会比较难一点,因为可能会涉及到SQL解析,不清楚Table API的入口在哪里。
但是在我总结的上篇文章Flink用户自定义连接器(Table API Connectors)学习总结中知道了其实Flink Table API读写Hudi是通过自定义实现了一个Hudi的Table API Connectors(‘connector’ = ‘hudi’),相关类为HoodieTableFactory、HoodieTableSink和HoodieTableSource,入口为HoodieTableFactory。
代码
GitHub地址:https://github.com/dongkelun/hudi-demo/tree/master/hudi0.13_flink1.15
package com.dkl.hudi.flink;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.hudi.configuration.FlinkOptions;
import static org.apache.hudi.examples.quickstart.utils.QuickstartConfigurations.sql;
public class HudiFlinkSQL {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, EnvironmentSettings.inBatchMode());
String tableName = "t1";
if (args.length > 0) {
tableName = args[0];
}
String tablePath = "/tmp/flink/hudi/" + tableName;
String hoodieTableDDL = sql(tableName)
.field("id int")
.field("name string")
.field("price double")
.field("ts bigint")
.field("dt string")
.option(FlinkOptions.PATH, tablePath)
// .option(FlinkOptions.READ_AS_STREAMING, true)
// .option(FlinkOptions.TABLE_TYPE, "COPY_ON_WRITE")
.partitionField("dt")
.pkField("id")
.end();
tableEnv.executeSql(hoodieTableDDL);
tableEnv.executeSql(String.format("insert into %s values (1,'hudi',10,100,'2023-05-28')", tableName));
tableEnv.executeSql(String.format("select * from %s", tableName)).print();
}
}
其实就是通过tableEnv.executeSql执行Flink SQL,其中创建Hudi表的SQL语句是利用Hudi源码中模块hudi-examples-flink里面的sql方法生成的,它会根据参数返回对应的创建Hudi表的SQL语句,示例:
String tableName = "t1";
String tablePath = "/tmp/flink/hudi/" + tableName;
String hoodieTableDDL = sql(tableName)
.option(FlinkOptions.PATH, tablePath)
.option(FlinkOptions.READ_AS_STREAMING, true)
.option(FlinkOptions.TABLE_TYPE, "COPY_ON_WRITE")
.end();
System.out.println(hoodieTableDDL);
输出
create table t1(
`uuid` VARCHAR(20),
`name` VARCHAR(10),
`age` INT,
`ts` TIMESTAMP(3),
`partition` VARCHAR(10),
PRIMARY KEY(uuid) NOT ENFORCED
)
PARTITIONED BY (`partition`)
with (
'connector' = 'hudi',
'read.streaming.enabled' = 'true',
'path' = '/tmp/flink/hudi/t1',
'connector' = 'hudi',
'table.type' = 'COPY_ON_WRITE'
)
如果不指定字段的话,会有官方文档示例中几个默认字段,默认主键为uuid,默认为分区表,分区字段为partition
hoodieTableDDL = sql(tableName)
.field("id int")
.field("name string")
.field("price double")
.field("ts bigint")
.field("dt string")
.option(FlinkOptions.PATH, tablePath)
.noPartition()
.pkField("id")
.end();
System.out.println(hoodieTableDDL);
可以通过field方法指定表的字段,pkField指定表的主键,noPartition设置表为非分区表,partitionField指定表的分区字段
create table t1(
id int,
name string,
price double,
ts bigint,
dt string,
PRIMARY KEY(id) NOT ENFORCED
)
with (
'connector' = 'hudi',
'path' = '/tmp/flink/hudi/t1',
'connector' = 'hudi'
)
本地运行调试
运行结果
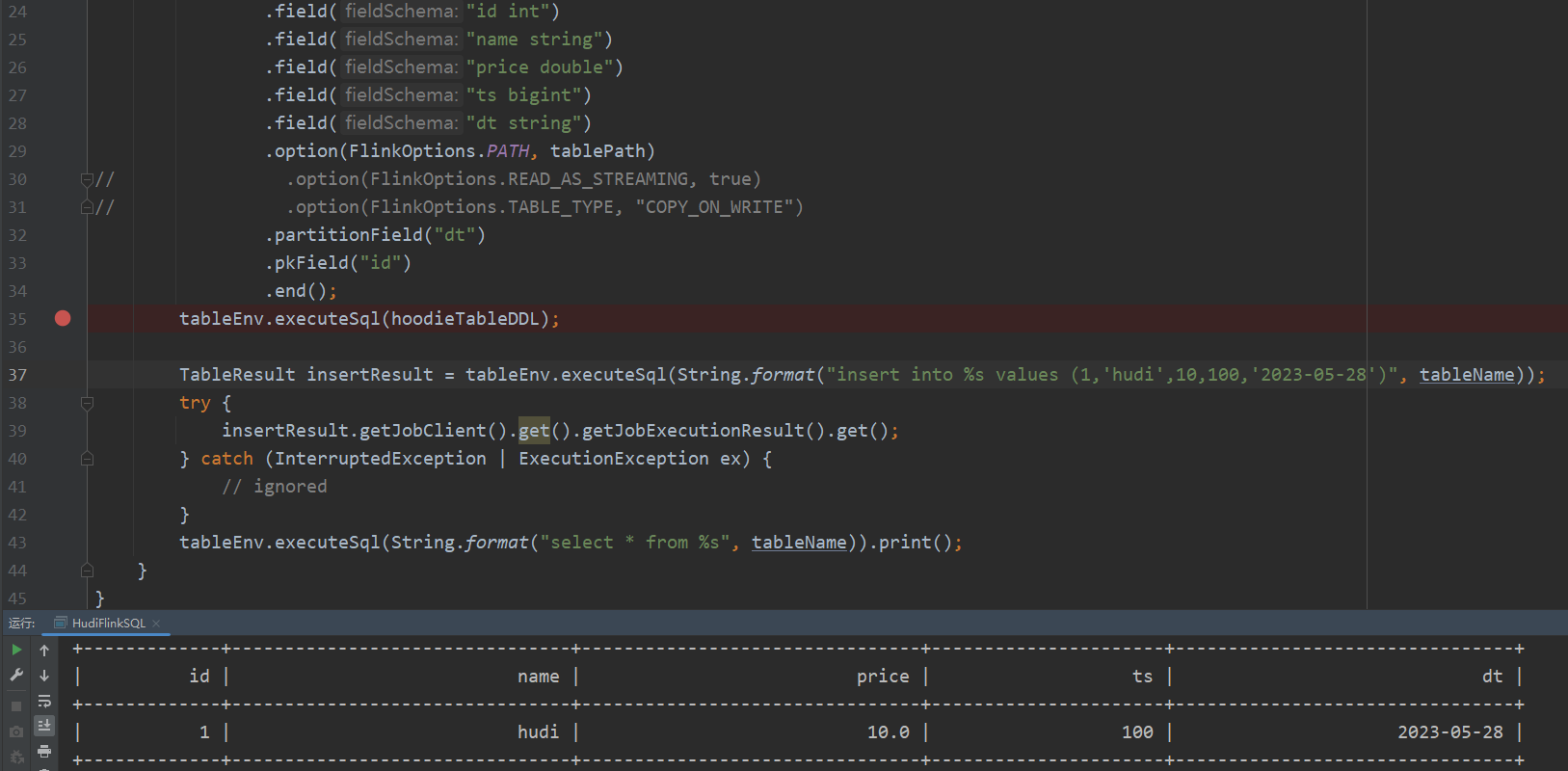
调试
我们根据开头提到的文章Flink用户自定义连接器(Table API Connectors)学习总结可知入口为HoodieTableFactory,其中sink的入口为createDynamicTableSink,source的入口为createDynamicTableSource
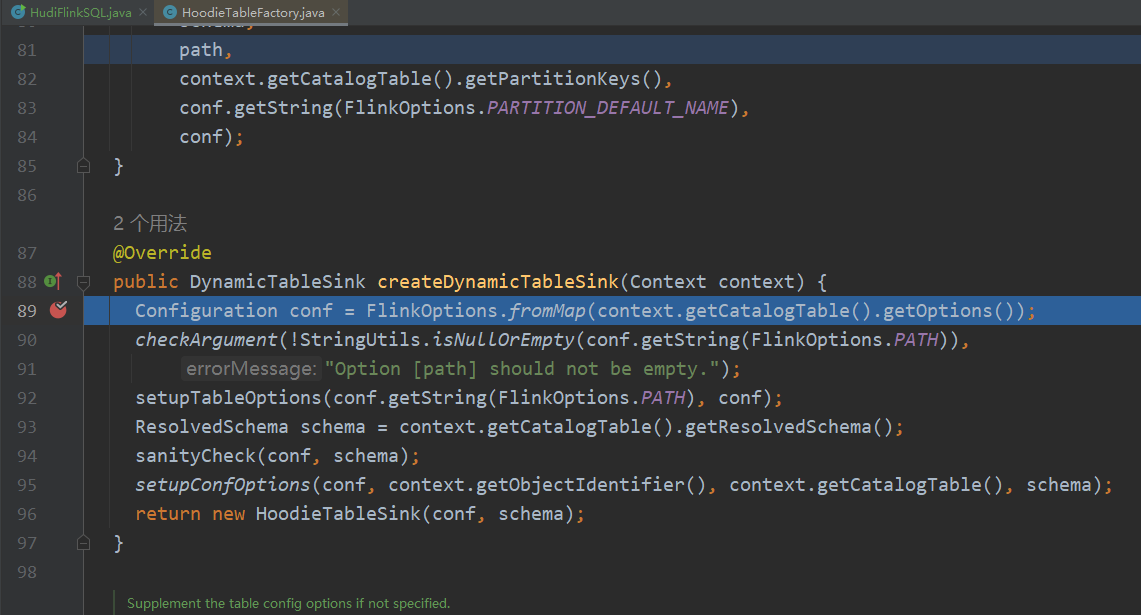
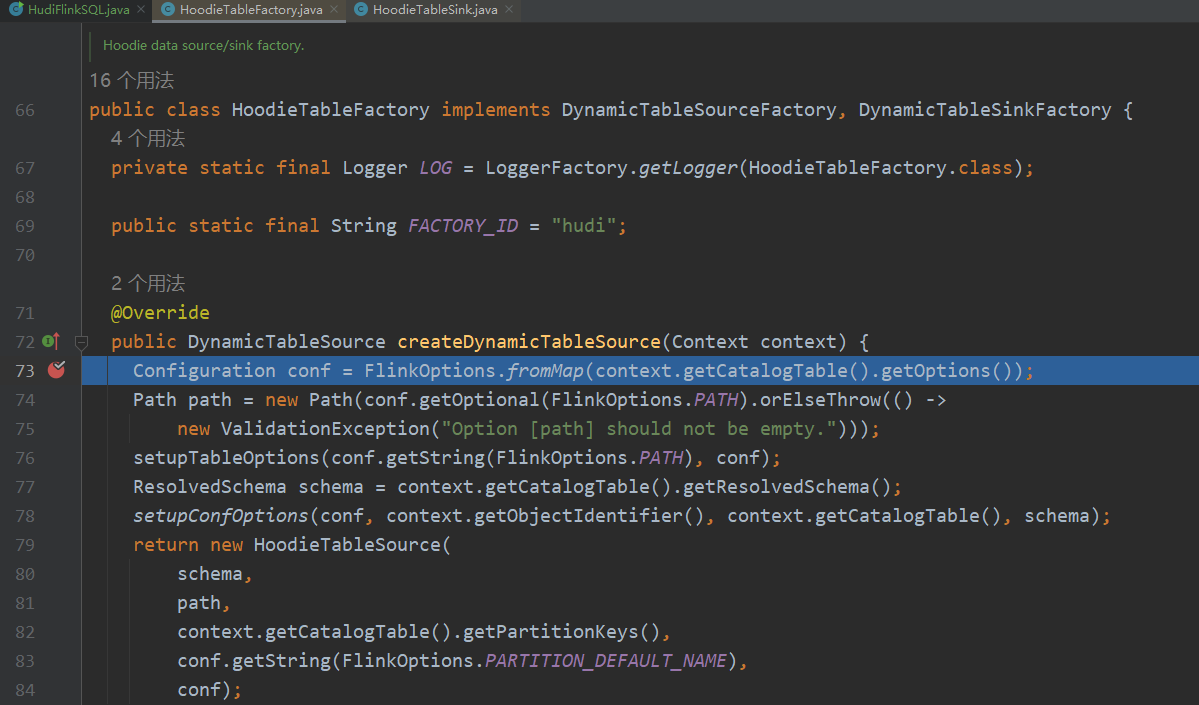
本地调试源码的时候可能会遇到在Idea中源码下载不下来的情况,我们可以直接去官网下载对应的源码jar包,然后放到自己本地的仓库中,方便我们调试的时候阅读源码。比如hudi-flink对应的源码的下载地址:https://repo1.maven.org/maven2/org/apache/hudi/hudi-flink/0.13.0/hudi-flink-0.13.0-sources.jar,然后将hudi-flink-0.13.0-sources.jar放到路径 m2
epositoryorgapachehudihudi-flink�.13.0 中就可以了
我们发现Table API的入口和DataStream API的入口差不多,DataStream API的入口是在
HoodiePipeline的sink和source方法里,而这两个方法也是也是分别调用了HoodieTableFactory的createDynamicTableSink和createDynamicTableSource
/**
* Returns the data stream sink with given catalog table.
*
* @param input The input datastream
* @param tablePath The table path to the hoodie table in the catalog
* @param catalogTable The hoodie catalog table
* @param isBounded A flag indicating whether the input data stream is bounded
*/
private static DataStreamSink<?> sink(DataStream<RowData> input, ObjectIdentifier tablePath, ResolvedCatalogTable catalogTable, boolean isBounded) {
FactoryUtil.DefaultDynamicTableContext context = Utils.getTableContext(tablePath, catalogTable, Configuration.fromMap(catalogTable.getOptions()));
HoodieTableFactory hoodieTableFactory = new HoodieTableFactory();
return ((DataStreamSinkProvider) hoodieTableFactory.createDynamicTableSink(context)
.getSinkRuntimeProvider(new SinkRuntimeProviderContext(isBounded)))
.consumeDataStream(input);
}
/**
* Returns the data stream source with given catalog table.
*
* @param execEnv The execution environment
* @param tablePath The table path to the hoodie table in the catalog
* @param catalogTable The hoodie catalog table
*/
private static DataStream<RowData> source(StreamExecutionEnvironment execEnv, ObjectIdentifier tablePath, ResolvedCatalogTable catalogTable) {
FactoryUtil.DefaultDynamicTableContext context = Utils.getTableContext(tablePath, catalogTable, Configuration.fromMap(catalogTable.getOptions()));
HoodieTableFactory hoodieTableFactory = new HoodieTableFactory();
DataStreamScanProvider dataStreamScanProvider = (DataStreamScanProvider) ((ScanTableSource) hoodieTableFactory
.createDynamicTableSource(context))
.getScanRuntimeProvider(new ScanRuntimeProviderContext());
return dataStreamScanProvider.produceDataStream(execEnv);
}
源码调试
我们还可以直接在源码里进行调试,这样方便我们直接看到修改源码后的效果。直接在源码里进行调试可能配置环境会比较麻烦一点,每个版本也不太一样。比如我在hudi 0.13.0源码中模块hudi-examples-flink里进行调试,需要做如下修改:

详细的pom修改可以看我提到github上的commit:https://github.com/dongkelun/hudi/commit/558910d4cab189d0cbfa9c69332f3e4e74e56b41
这样我们就可以本地直接运行源码中的类:HoodieFlinkQuickstart,也可以直接修改源码查看效果:
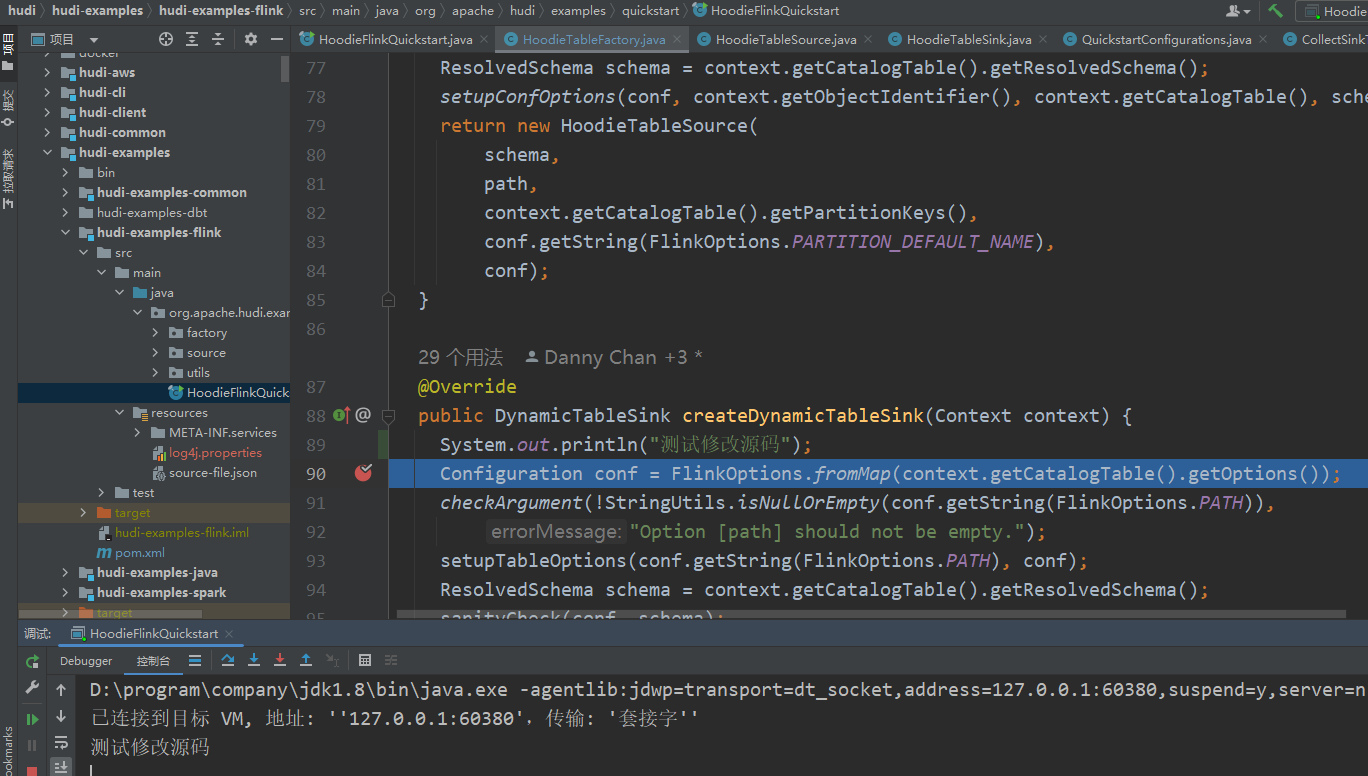
源码里的demo和测试用例比较全,我们可以多看一看多调试一下,利于提升对源码的理解。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结