您现在的位置是:首页 >技术交流 >DATAX数据同步工具网站首页技术交流
DATAX数据同步工具
1:DATAX概览
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
1.1:DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题
1.1:支持的数据源插件
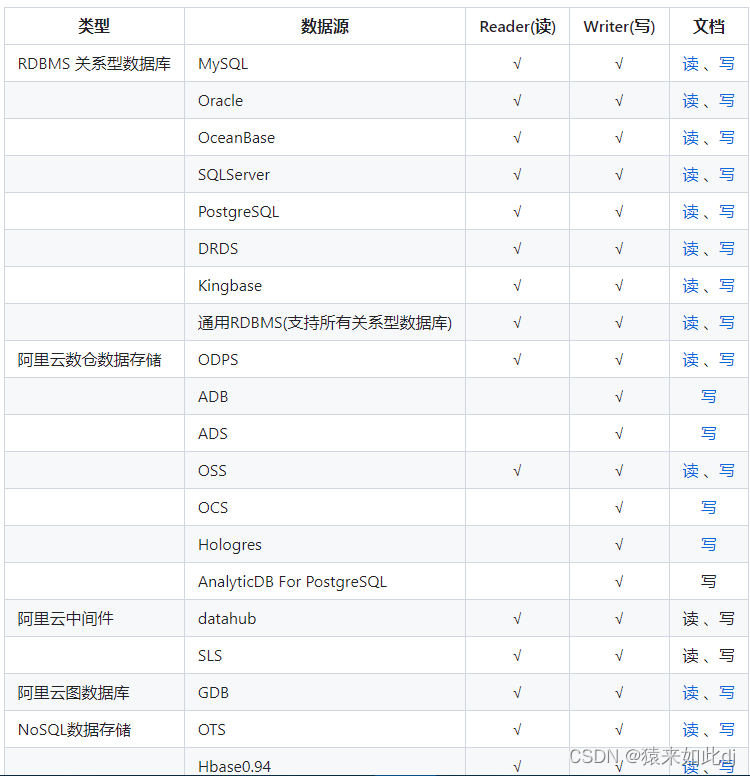
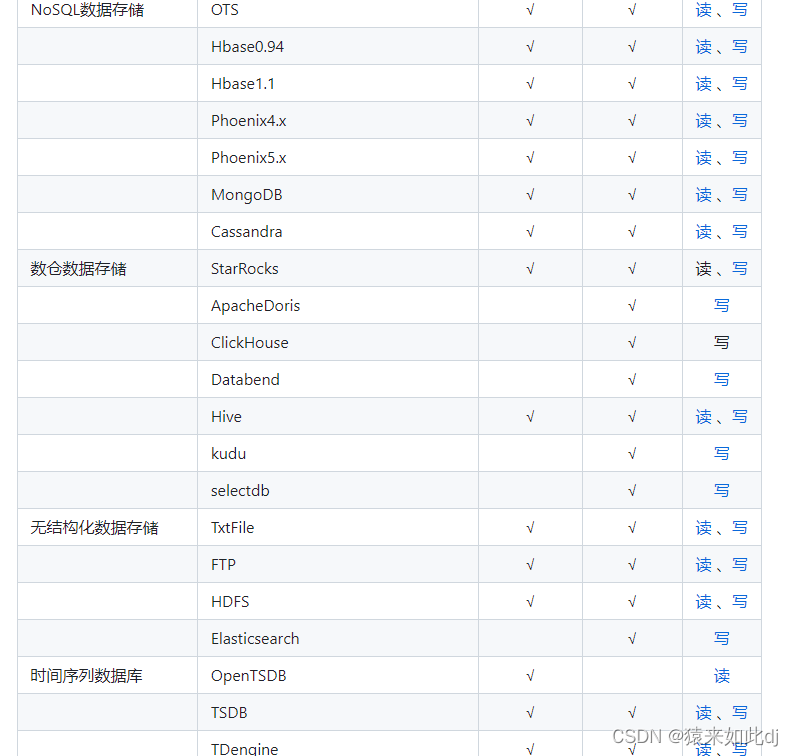
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库(其他所有的关系型数据库可以使用此通用插件,如达梦神通等国产数据库不需要重新开发插件)、NOSQL、大数据计算系统都已经接入,目前支持数据如下图,详情请点击:DataX数据源参考指南
并且对于不满足的插件支持扩展:
datax插件开发指南-https://github.com/alibaba/DataX/blob/master/dataxPluginDev.md
1.3:核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。
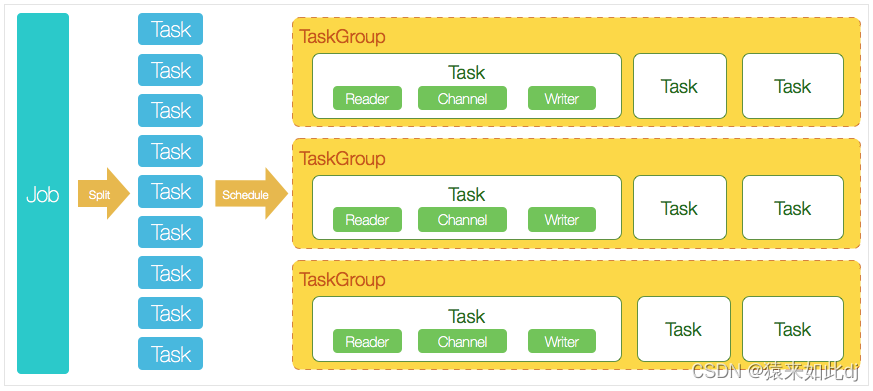
核心模块介绍:
1、DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
2、DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
3、切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
4、每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
5、DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
1、DataXJob根据分库分表切分成了100个Task。
2、根据20个并发,DataX计算共需要分配4个TaskGroup。
3、4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
1.4:数据同步原理
datax任务以json文件进行定义,json结构主要如下。
1、setting对作业执行的设置包括限流、content包括reader和writer的配置,主要是对数据库的连接地址url,user,password,对表及字段的配置。
2、reader查询的结果会作为writer写入的数据源,根据配置的字段表名自动转换为insert语句插入数据,同时支持全量同步和增量同步(通过数据查询时的时间等字段实现,时间可以通过执行脚本时-q进行传参)
3、关于字段的映射默认名字一样的直接映射,如果不一样会报失败,可以利用 sql as进行列名转换
2:实战
1:作业json配置说明
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
},
"writer": {
}
}
]
}
}
详细的配置参看官网示例或者安装后在目录下执行./bin/datax.py -help
./bin/datax.py -help 查看具体使用
./bin/datax.py -p 给作业传参。内容用双引号包起来,并以-D开头
如:-p "-Dtableame=test_user",作业中取值则${tableName}
./bin/datax.py -j 设置作业jvm配置
如:-Xms1024m -Xmx1024m -XX:+HeapDumpOnOutOfMemoryError
./bin/datax.py jobName.json 执行同步作业,json是自己配置的文件
./bin/datax.pNy -r -w 查看数据源使用示例
如:./bin/datax.pNy -r 数据源reader -w 数据源writer
./bin/datax.pNy -r mysqlreader -w mysqlwriter
具体的数据源可以参看安装目录下plugin/或github源码下的目录
2:实战
streamwriter和streamreader是对内存数据的处理。可以利用streamwriter将前面数据源的结果打印到控制台,或者streamreader读数据入到数据源
2.1:mysql到streamwriter
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"splitPk": "db_id",
"connection": [
{
"table": [
"table"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/database"
]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print":true
}
}
}
]
}
}
3:datax和海豚调度DolphinScheduler
海豚调度中的任务类型包括海豚调度,可以直接进行配置,可以选择数据源或者自定义模板两种
1:数据源
会把此种配置最后转为json文件再调用datax.py去执行。
2:自定义模板,自定义模板就是和datax的.json配置一样,把配置写进行运行即可






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结