您现在的位置是:首页 >技术教程 >【解决】sklearn-LabelEncoder遇到没在编码规则里的新值网站首页技术教程
【解决】sklearn-LabelEncoder遇到没在编码规则里的新值
简介【解决】sklearn-LabelEncoder遇到没在编码规则里的新值
一、问题描述
问题:sklearn-LabelEncoder 遇到没在编码规则里的新值
二、解决方法
方法一:直接保存old_data和encoder_data和之间的映射关系,字典或者下面的csv格式里都可以。
for col in beat_sparse_cols: # sparse_feature encoder
lbe = LabelEncoder()
# 直接在原来的表上进行修改
beat_data[col] = lbe.fit_transform(beat_data[col])
# # method 2: save dict(selected), 为每个lbe保存一个对应的字典
name = "encoding_" + str(col) + "_dict"
locals()[name] = {}
for i in list(lbe.classes_):
# encoding[i] = lbe.transform([i])[0]
locals()[name][i] = lbe.transform([i])[0]
# save the lbe dict, note the index
df = pd.DataFrame(locals()[name], index = [0])
# df = pd.DataFrame(list(my_dict.items()), columns=['key', 'value']) # 否则默认保存的key是str
df.to_csv(save_dir + "/" + str(col) + "lbe_dict.csv", index = False)
然后在预测阶段编码设计对应的规则,如未见过的就设置为unknown或0:
for col in beat_sparse_cols:
lbe = LabelEncoder()
# all_path = "/home/andy/torch_rechub_n/beat_deepFM/saved_model_w"
name = col + "lbe_dict"
dict_temp = pd.read_csv(dict_path + "/" + name + ".csv")
locals()[name] = dict_temp.iloc[0].to_dict()
dict_temp = locals()[name]
new_name = col + "_encode"
if col == 'beatid':
beat_data['beatid'] = beat_data['beatid'].fillna(value = 0.0)
# 推理时: 训练中没看过的, str标记为unknown, int标记为nan
if beat_data[col].dtypes == float:
beat_data[col] = beat_data[col].apply(lambda x: NaN if np.isnan(x) else str(int(x)))
beat_data[col] = beat_data[col].apply(lambda x: dict_temp.get(str(x), 0))
else:
# beat_data[col] = beat_data[col].apply(lambda x: np.nan if np.isnan(x) else str(int(x)))
# beat_data[col] = beat_data[col].apply(lambda x: dict_temp.get(str(x), 'unknown'))
beat_data[col] = beat_data[col].apply(lambda x: dict_temp.get(str(x), 0))
方法二:将测试集中的所有新内容(即不属于任何现有类)映射到<unknown> ,然后显式地将相应的类添加到LabelEncoder :
# train and test are pandas.DataFrame's and c is whatever column
le = LabelEncoder()
le.fit(train[c])
test[c] = test[c].map(lambda s: '<unknown>' if s not in le.classes_ else s)
le.classes_ = np.append(le.classes_, '<unknown>')
train[c] = le.transform(train[c])
test[c] = le.transform(test[c])
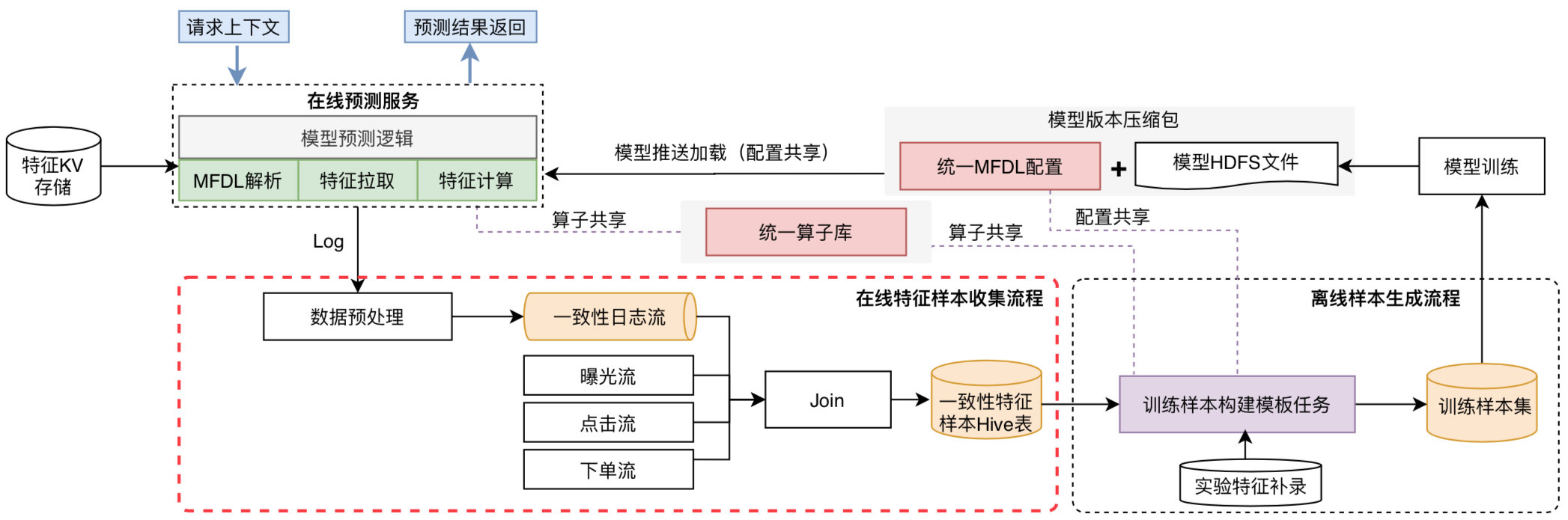
方法三:线上、线下在配置文件、算子上使用统一,如某团通过模板化 + 配置化生成样本构建流程:
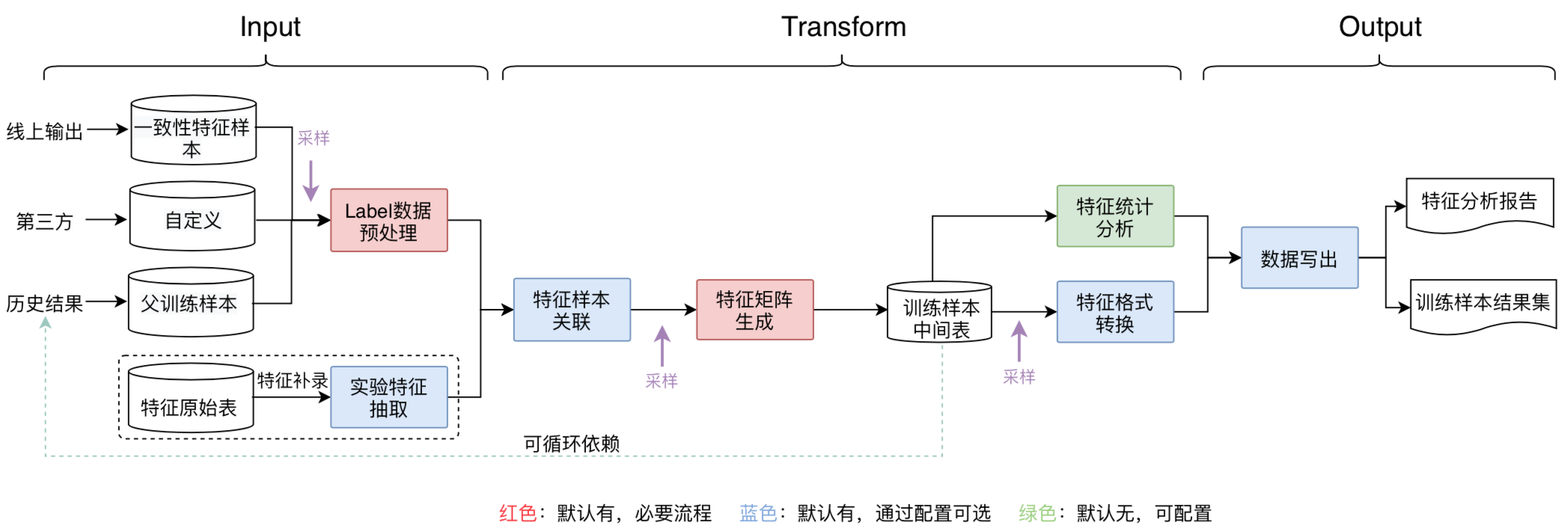
- 打通线上线下配置:线下生成训练样本时,用户先定义特征MFDL配置文件,在模型训练后,通过平台一键打包功能,将MFDL配置文件以及训练输出的模型文件,打包、上传到模型管理平台,通过一定的版本管理及加载策略,将模型动态加载到线上服务,从而实现线上、线下配置一体化。
- 提供一致性特征样本:通过实时收集在线Serving输出的特征快照,经过一定的规则处理,将结果数据输出到Hive表,作为离线训练样本的基础数据源,提供一致性特征样本,保障在线、离线数据口径一致。
- 统一特征算子库:上文提到可以通过特征补录方式添加新的实验特征,补录特征如果涉及到算子二次加工,平台既提供基础的算子库,也支持自定义算子,通过算子库共用保持线上、线下计算口径一致。
Reference
[1] sklearn-LabelEncoder 遇到没在编码规则里的新值的解决办法
[2] https://stackoom.com/question/1QM33
[3] How to Set the Same Categorical Codes to Train and Test data? Python-Pandas
[4] https://www.qiniu.com/qfans/qnso-51308994
[5] feast特征库:https://docs.feast.dev/getting-started/architecture-and-components/overview
[6] 某团外卖特征平台的建设与实践
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结