您现在的位置是:首页 >技术杂谈 >Pytorch CIFAR10图像分类 ShuffleNet篇网站首页技术杂谈
Pytorch CIFAR10图像分类 ShuffleNet篇
Pytorch CIFAR10图像分类 ShuffleNet篇
文章目录
再次介绍一下我的专栏,很适合大家初入深度学习或者是Pytorch和Keras,希望这能够帮助初学深度学习的同学一个入门Pytorch或者Keras的项目和在这之中更加了解Pytorch&Keras和各个图像分类的模型。
他有比较清晰的可视化结构和架构,除此之外,我是用jupyter写的,所以说在文章整体架构可以说是非常清晰,可以帮助你快速学习到各个模块的知识,而不是通过python脚本一行一行的看,这样的方式是符合初学者的。
除此之外,如果你需要变成脚本形式,也是很简单的。
这里贴一下汇总篇:汇总篇
4. 定义网络(ShuffleNet)
ShuffleNet是旷视科技提出的一种计算高效的CNN模型,其和MobileNet和SqueezeNet等一样主要是想应用在移动端。所以,ShuffleNet的设计目标也是如何利用有限的计算资源来达到最好的模型精度,这需要很好地在速度和精度之间做平衡。
ShuffleNet的核心是采用了两种操作:pointwise group convolution和channel shuffle,这在保持精度的同时大大降低了模型的计算量。目前移动端CNN模型主要设计思路主要是两个方面:模型结构设计和模型压缩。ShuffleNet和MobileNet一样属于前者,都是通过设计更高效的网络结构来实现模型变小和变快,而不是对一个训练好的大模型做压缩或者迁移。接下来我们将详细讲述ShuffleNet的设计思路,网络结构及模型效果,最后使用Pytorch来实现ShuffleNet网络。
Channel Shuffle
ShuffleNet的核心设计理念是对不同的channels进行shuffle来解决group convolution带来的弊端。Group convolution是将输入层的不同特征图进行分组,然后采用不同的卷积核再对各个组进行卷积,这样会降低卷积的计算量。因为一般的卷积都是在所有的输入特征图上做卷积,可以说是全通道卷积,这是一种通道密集连接方式(channel dense connection)。而group convolution相比则是一种通道稀疏连接方式(channel sparse connection)。
使用group convolution的网络如Xception,MobileNet,ResNeXt等。Xception和MobileNet采用了depthwise convolution,这其实是一种比较特殊的group convolution,因此此时分组数恰好等于通道数,意味着每个组只有一个特征图。但是这些网络存在一个很大的弊端是采用了密集的1x1卷积,或者说是dense pointwise convolution,这里说的密集指的是卷积是在所有通道上进行的。所以,实际上比如ResNeXt模型中1x1卷积基本上占据了93.4%的乘加运算。那么不如也对1x1卷积采用channel sparse connection,那样计算量就可以降下来了。
除此之外,group convolution存在另外一个弊端,如图1-a所示,其中GConv是group convolution,这里分组数是3。可以看到当堆积GConv层后一个问题是不同组之间的特征图是不通信的,这就好像分了三个互不相干的路,大家各走各的,这目测会降低网络的特征提取能力。这样你也可以理解为什么Xception,MobileNet等网络采用密集的1x1卷积,因为要保证group convolution之后不同组的特征图之间的信息交流。但是达到上面那个目的,我们不一定非要采用dense pointwise convolution。如图1-b所示,你可以对group convolution之后的特征图进行“重组”,这样可以保证接下了采用的group convolution其输入来自不同的组,因此信息可以在不同组之间流转。这个操作等价于图1-c,即group convolution之后对channels进行shuffle,但并不是随机的,其实是“均匀地打乱”。
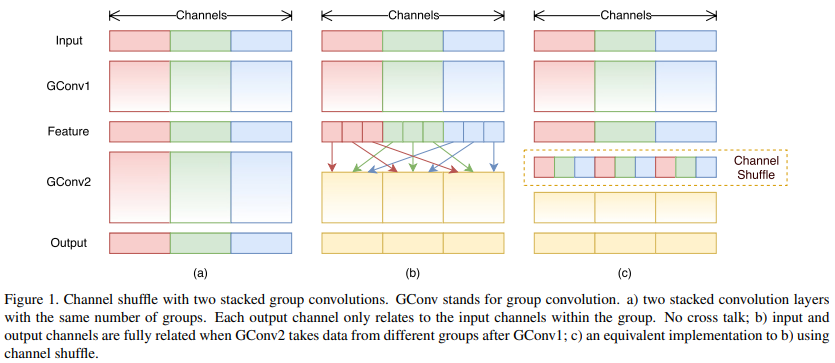
- 图a是简单的组卷积实现过程,这里存在的问题是输出通道只与输入的某些通道有关,降低通道组间的信息流动能力,降低了信息表达能力。
- 图b是将每个组中的特征图均匀混合,也就是混洗(Shuffle),这样可以更好地获取全局信息,图c是图b的等价效果。
网络单元 Shuffle Unit
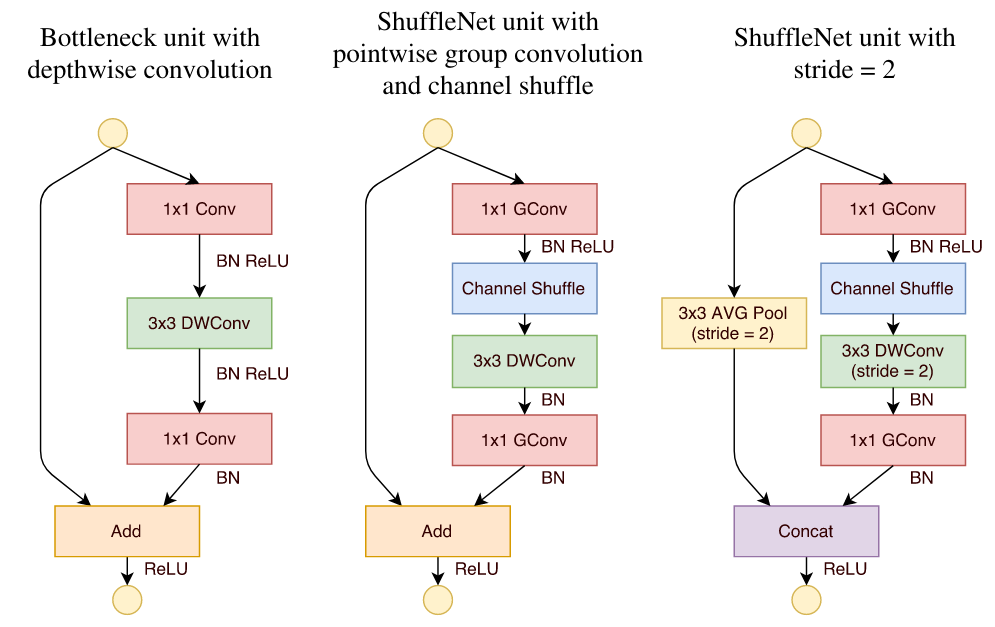
Channel Shuffle 的原理,就可以设计Shuffle Unit 了,其实很简单,ShuffleNet的基本单元是在一个残差单元的基础上改进而成的。
- 图a是ResNet中的bottleneck unit,但这里用 3×3 的DWConv代替原来的 3 × 3 Conv(主要是为了降低计算量);
- 图b将图a中的两端1×1Conv换成了Group Conv;同时在DWConv之前使用了Channel Shuffle,该单元没有对图像大小进行调整;还有就是,经过DWConv后不进行ReLU激活函数;
对于残差单元,如果stride=1时,此时输入与输出shape一致可以直接相加,而当stride=2时,通道数增加,而特征图大小减小,此时输入与输出不匹配。一般情况下可以采用一个1x1卷积将输入映射成和输出一样的shape。但是在ShuffleNet中,却采用了不一样的策略。
- 图c中的DWConv的步长设置为2,同时旁路连接中添加了一个步长为2的平均池化 3x3 avg pool,这样得到和输出一样大小的特征图,并在最后使用Concatenate相连两条分支(不是相加),这种设计在扩大了通道维度的同时并没有增加很多的计算量。(add是通道数值相加,concat是通道堆叠)
ShuffleNet 网络结构
基于上面改进的ShuffleNet基本单元,设计的ShuffleNet模型如表所示。类似与残差网络的方法,一开始使用简单的卷积和max pool,后面进行堆叠ShuffleNet的基本单元,和残差的设计理念是一样的。
其中 g g g 控制了group convolution中的分组数,分组越多,在相同计算资源下,可以使用更多的通道数,所以 g g g 越大时,采用了更多的卷积核。这里给个例子,当 g g g = 3 时,对于第一阶段的第一个基本单元,其输入通道数为24,输出通道数为240,但是其stride=2,那么由于原输入通过avg pool可以贡献24个通道,所以相当于左支只需要产生240-24=216通道,中间瓶颈层的通道数就为216/4=54。其他的可以以此类推。当完成三阶段后,采用global pool将特征图大小降为1x1,最后是输出类别预测值的全连接层。

首先我们还是得判断是否可以利用GPU,因为GPU的速度可能会比我们用CPU的速度快20-50倍左右,特别是对卷积神经网络来说,更是提升特别明显。
device = 'cuda' if torch.cuda.is_available() else 'cpu'
第一步我们需要构建我们的ShuffleBlock,里面就用到了我们的核心理念,Channel Shuffle,其实在程序上实现channel shuffle是非常容易的:
假定将输入层分为 g 组,总通道数为 g × n g×n g×n ,首先你将通道那个维度拆分为 ( g , n ) (g,n) (g,n) 两个维度,然后将这两个维度转置变成 ( n , g ) (n,g) (n,g) ,最后重新 reshape 成一个维度。如果你不太理解这个操作,你可以试着动手去试一下,发现仅需要简单的维度操作和转置就可以实现均匀的shuffle。利用channel shuffle就可以充分发挥group convolution的优点,而避免其缺点。
class ShuffleBlock(nn.Module):
def __init__(self, groups):
super(ShuffleBlock, self).__init__()
self.groups = groups
def forward(self, x):
'''Channel shuffle: [N,C,H,W] -> [N,g,C/g,H,W] -> [N,C/g,g,H,w] -> [N,C,H,W]'''
N,C,H,W = x.size()
g = self.groups
return x.view(N,g,C//g,H,W).permute(0,2,1,3,4).reshape(N,C,H,W)
然后跟残差一样的理念,我们设置我们的Bottleneck,对于stride = 2的情况就加入一个Avg pool,这样就可以得到我们的基本模块了
class Bottleneck(nn.Module):
def __init__(self, in_channels, out_channels, stride, groups):
super(Bottleneck, self).__init__()
self.stride = stride
mid_channels = out_channels//4
g = 1 if in_channels==24 else groups
self.conv1 = nn.Conv2d(in_channels, mid_channels, kernel_size=1, groups=g, bias=False)
self.bn1 = nn.BatchNorm2d(mid_channels)
self.shuffle1 = ShuffleBlock(groups=g)
self.conv2 = nn.Conv2d(mid_channels, mid_channels, kernel_size=3, stride=stride, padding=1, groups=mid_channels, bias=False)
self.bn2 = nn.BatchNorm2d(mid_channels)
self.conv3 = nn.Conv2d(mid_channels, out_channels, kernel_size=1, groups=groups, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if stride == 2:
self.shortcut = nn.Sequential(nn.AvgPool2d(3, stride=2, padding=1))
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.shuffle1(out)
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
res = self.shortcut(x)
out = F.relu(torch.cat([out,res], 1)) if self.stride==2 else F.relu(out+res)
return out
基于网络结构表,我们就可以定义我们的ShuffleNet了,首先是1x1的卷积和BN层,后面两个就是不断的堆叠我们的Bottleneck层,最后根据网络结构的表的参数,得到我们最后的ShuffleNetG2和ShuffleNetG3了。
class ShuffleNet(nn.Module):
def __init__(self, cfg, num_classes=10):
super(ShuffleNet, self).__init__()
out_channels = cfg['out_channels']
num_blocks = cfg['num_blocks']
groups = cfg['groups']
self.conv1 = nn.Conv2d(3, 24, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(24)
self.in_channels = 24
self.layer1 = self._make_layer(out_channels[0], num_blocks[0], groups)
self.layer2 = self._make_layer(out_channels[1], num_blocks[1], groups)
self.layer3 = self._make_layer(out_channels[2], num_blocks[2], groups)
self.linear = nn.Linear(out_channels[2], num_classes)
def _make_layer(self, out_channels, num_blocks, groups):
layers = []
for i in range(num_blocks):
stride = 2 if i == 0 else 1
cat_channels = self.in_channels if i == 0 else 0
layers.append(Bottleneck(self.in_channels, out_channels-cat_channels, stride=stride, groups=groups))
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
# 根据表中的数据定义
def ShuffleNetG2(num_classes = 10):
cfg = {
'out_channels': [200,400,800],
'num_blocks': [4,8,4],
'groups': 2
}
return ShuffleNet(cfg, num_classes)
def ShuffleNetG3(num_classes = 10):
cfg = {
'out_channels': [240,480,960],
'num_blocks': [4,8,4],
'groups': 3
}
return ShuffleNet(cfg, num_classes)
net = ShuffleNetG2(num_classes=10).to(device)
summary查看网络
我们可以通过summary来看到,模型的维度的变化,这个也是和论文是匹配的,经过层后shape的变化,是否最后也是输出(batch,shape)
summary(net,(2,3,32,32))
---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 24, 32, 32] 72 BatchNorm2d-2 [-1, 24, 32, 32] 48 Conv2d-3 [-1, 44, 32, 32] 1,056 BatchNorm2d-4 [-1, 44, 32, 32] 88 ShuffleBlock-5 [-1, 44, 32, 32] 0 Conv2d-6 [-1, 44, 16, 16] 396 BatchNorm2d-7 [-1, 44, 16, 16] 88 Conv2d-8 [-1, 176, 16, 16] 3,872 BatchNorm2d-9 [-1, 176, 16, 16] 352 AvgPool2d-10 [-1, 24, 16, 16] 0 Bottleneck-11 [-1, 200, 16, 16] 0 Conv2d-12 [-1, 50, 16, 16] 5,000 BatchNorm2d-13 [-1, 50, 16, 16] 100 ShuffleBlock-14 [-1, 50, 16, 16] 0 Conv2d-15 [-1, 50, 16, 16] 450 BatchNorm2d-16 [-1, 50, 16, 16] 100 Conv2d-17 [-1, 200, 16, 16] 5,000 BatchNorm2d-18 [-1, 200, 16, 16] 400 Bottleneck-19 [-1, 200, 16, 16] 0 Conv2d-20 [-1, 50, 16, 16] 5,000 BatchNorm2d-21 [-1, 50, 16, 16] 100 ShuffleBlock-22 [-1, 50, 16, 16] 0 Conv2d-23 [-1, 50, 16, 16] 450 BatchNorm2d-24 [-1, 50, 16, 16] 100 Conv2d-25 [-1, 200, 16, 16] 5,000 BatchNorm2d-26 [-1, 200, 16, 16] 400 Bottleneck-27 [-1, 200, 16, 16] 0 Conv2d-28 [-1, 50, 16, 16] 5,000 BatchNorm2d-29 [-1, 50, 16, 16] 100 ShuffleBlock-30 [-1, 50, 16, 16] 0 Conv2d-31 [-1, 50, 16, 16] 450 BatchNorm2d-32 [-1, 50, 16, 16] 100 Conv2d-33 [-1, 200, 16, 16] 5,000 BatchNorm2d-34 [-1, 200, 16, 16] 400 Bottleneck-35 [-1, 200, 16, 16] 0 Conv2d-36 [-1, 50, 16, 16] 5,000 BatchNorm2d-37 [-1, 50, 16, 16] 100 ShuffleBlock-38 [-1, 50, 16, 16] 0 Conv2d-39 [-1, 50, 8, 8] 450 BatchNorm2d-40 [-1, 50, 8, 8] 100 Conv2d-41 [-1, 200, 8, 8] 5,000 BatchNorm2d-42 [-1, 200, 8, 8] 400 AvgPool2d-43 [-1, 200, 8, 8] 0 Bottleneck-44 [-1, 400, 8, 8] 0 Conv2d-45 [-1, 100, 8, 8] 20,000 BatchNorm2d-46 [-1, 100, 8, 8] 200 ShuffleBlock-47 [-1, 100, 8, 8] 0 Conv2d-48 [-1, 100, 8, 8] 900 BatchNorm2d-49 [-1, 100, 8, 8] 200 Conv2d-50 [-1, 400, 8, 8] 20,000 BatchNorm2d-51 [-1, 400, 8, 8] 800 Bottleneck-52 [-1, 400, 8, 8] 0 Conv2d-53 [-1, 100, 8, 8] 20,000 BatchNorm2d-54 [-1, 100, 8, 8] 200 ShuffleBlock-55 [-1, 100, 8, 8] 0 Conv2d-56 [-1, 100, 8, 8] 900 BatchNorm2d-57 [-1, 100, 8, 8] 200 Conv2d-58 [-1, 400, 8, 8] 20,000 BatchNorm2d-59 [-1, 400, 8, 8] 800 Bottleneck-60 [-1, 400, 8, 8] 0 Conv2d-61 [-1, 100, 8, 8] 20,000 BatchNorm2d-62 [-1, 100, 8, 8] 200 ShuffleBlock-63 [-1, 100, 8, 8] 0 Conv2d-64 [-1, 100, 8, 8] 900 BatchNorm2d-65 [-1, 100, 8, 8] 200 Conv2d-66 [-1, 400, 8, 8] 20,000 BatchNorm2d-67 [-1, 400, 8, 8] 800 Bottleneck-68 [-1, 400, 8, 8] 0 Conv2d-69 [-1, 100, 8, 8] 20,000 BatchNorm2d-70 [-1, 100, 8, 8] 200 ShuffleBlock-71 [-1, 100, 8, 8] 0 Conv2d-72 [-1, 100, 8, 8] 900 BatchNorm2d-73 [-1, 100, 8, 8] 200 Conv2d-74 [-1, 400, 8, 8] 20,000 BatchNorm2d-75 [-1, 400, 8, 8] 800 Bottleneck-76 [-1, 400, 8, 8] 0 Conv2d-77 [-1, 100, 8, 8] 20,000 BatchNorm2d-78 [-1, 100, 8, 8] 200 ShuffleBlock-79 [-1, 100, 8, 8] 0 Conv2d-80 [-1, 100, 8, 8] 900 BatchNorm2d-81 [-1, 100, 8, 8] 200 Conv2d-82 [-1, 400, 8, 8] 20,000 BatchNorm2d-83 [-1, 400, 8, 8] 800 Bottleneck-84 [-1, 400, 8, 8] 0 Conv2d-85 [-1, 100, 8, 8] 20,000 BatchNorm2d-86 [-1, 100, 8, 8] 200 ShuffleBlock-87 [-1, 100, 8, 8] 0 Conv2d-88 [-1, 100, 8, 8] 900 BatchNorm2d-89 [-1, 100, 8, 8] 200 Conv2d-90 [-1, 400, 8, 8] 20,000 BatchNorm2d-91 [-1, 400, 8, 8] 800 Bottleneck-92 [-1, 400, 8, 8] 0 Conv2d-93 [-1, 100, 8, 8] 20,000 BatchNorm2d-94 [-1, 100, 8, 8] 200 ShuffleBlock-95 [-1, 100, 8, 8] 0 Conv2d-96 [-1, 100, 8, 8] 900 BatchNorm2d-97 [-1, 100, 8, 8] 200 Conv2d-98 [-1, 400, 8, 8] 20,000 BatchNorm2d-99 [-1, 400, 8, 8] 800 Bottleneck-100 [-1, 400, 8, 8] 0 Conv2d-101 [-1, 100, 8, 8] 20,000 BatchNorm2d-102 [-1, 100, 8, 8] 200 ShuffleBlock-103 [-1, 100, 8, 8] 0 Conv2d-104 [-1, 100, 4, 4] 900 BatchNorm2d-105 [-1, 100, 4, 4] 200 Conv2d-106 [-1, 400, 4, 4] 20,000 BatchNorm2d-107 [-1, 400, 4, 4] 800 AvgPool2d-108 [-1, 400, 4, 4] 0 Bottleneck-109 [-1, 800, 4, 4] 0 Conv2d-110 [-1, 200, 4, 4] 80,000 BatchNorm2d-111 [-1, 200, 4, 4] 400 ShuffleBlock-112 [-1, 200, 4, 4] 0 Conv2d-113 [-1, 200, 4, 4] 1,800 BatchNorm2d-114 [-1, 200, 4, 4] 400 Conv2d-115 [-1, 800, 4, 4] 80,000 BatchNorm2d-116 [-1, 800, 4, 4] 1,600 Bottleneck-117 [-1, 800, 4, 4] 0 Conv2d-118 [-1, 200, 4, 4] 80,000 BatchNorm2d-119 [-1, 200, 4, 4] 400 ShuffleBlock-120 [-1, 200, 4, 4] 0 Conv2d-121 [-1, 200, 4, 4] 1,800 BatchNorm2d-122 [-1, 200, 4, 4] 400 Conv2d-123 [-1, 800, 4, 4] 80,000 BatchNorm2d-124 [-1, 800, 4, 4] 1,600 Bottleneck-125 [-1, 800, 4, 4] 0 Conv2d-126 [-1, 200, 4, 4] 80,000 BatchNorm2d-127 [-1, 200, 4, 4] 400 ShuffleBlock-128 [-1, 200, 4, 4] 0 Conv2d-129 [-1, 200, 4, 4] 1,800 BatchNorm2d-130 [-1, 200, 4, 4] 400 Conv2d-131 [-1, 800, 4, 4] 80,000 BatchNorm2d-132 [-1, 800, 4, 4] 1,600 Bottleneck-133 [-1, 800, 4, 4] 0 Linear-134 [-1, 10] 8,010 ================================================================ Total params: 887,582 Trainable params: 887,582 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.01 Forward/backward pass size (MB): 15.98 Params size (MB): 3.39 Estimated Total Size (MB): 19.38 ----------------------------------------------------------------
首先从我们summary可以看到,我们输入的是(batch,3,32,32)的张量,并且这里也能看到每一层后我们的图像输出大小的变化,最后输出10个参数,再通过softmax函数就可以得到我们每个类别的概率了。
我们也可以打印出我们的模型观察一下
ShuffleNet(
(conv1): Conv2d(3, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(24, 44, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(44, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shuffle1): ShuffleBlock()
(conv2): Conv2d(44, 44, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=44, bias=False)
(bn2): BatchNorm2d(44, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(44, 176, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn3): BatchNorm2d(176, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential(
(0): AvgPool2d(kernel_size=3, stride=2, padding=1)
)
)
(1): Bottleneck(
(conv1): Conv2d(200, 50, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn1): BatchNorm2d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shuffle1): ShuffleBlock()
(conv2): Conv2d(50, 50, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=50, bias=False)
(bn2): BatchNorm2d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(50, 200, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn3): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(2): Bottleneck(
(conv1): Conv2d(200, 50, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn1): BatchNorm2d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shuffle1): ShuffleBlock()
(conv2): Conv2d(50, 50, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=50, bias=False)
(bn2): BatchNorm2d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(50, 200, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn3): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(3): Bottleneck(
(conv1): Conv2d(200, 50, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn1): BatchNorm2d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shuffle1): ShuffleBlock()
(conv2): Conv2d(50, 50, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=50, bias=False)
(bn2): BatchNorm2d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(50, 200, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn3): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(200, 50, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn1): BatchNorm2d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shuffle1): ShuffleBlock()
(conv2): Conv2d(50, 50, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=50, bias=False)
(bn2): BatchNorm2d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(50, 200, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn3): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential(
(0): AvgPool2d(kernel_size=3, stride=2, padding=1)
)
)
(1): Bottleneck(
(conv1): Conv2d(400, 100, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn1): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shuffle1): ShuffleBlock()
(conv2): Conv2d(100, 100, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=100, bias=False)
(bn2): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(100, 400, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn3): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(2): Bottleneck(
(conv1): Conv2d(400, 100, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn1): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shuffle1): ShuffleBlock()
(conv2): Conv2d(100, 100, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=100, bias=False)
(bn2): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(100, 400, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn3): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(3): Bottleneck(
(conv1): Conv2d(400, 100, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn1): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shuffle1): ShuffleBlock()
(conv2): Conv2d(100, 100, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=100, bias=False)
(bn2): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(100, 400, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn3): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(4): Bottleneck(
(conv1): Conv2d(400, 100, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn1): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shuffle1): ShuffleBlock()
(conv2): Conv2d(100, 100, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=100, bias=False)
(bn2): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(100, 400, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn3): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(5): Bottleneck(
(conv1): Conv2d(400, 100, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn1): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shuffle1): ShuffleBlock()
(conv2): Conv2d(100, 100, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=100, bias=False)
(bn2): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(100, 400, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn3): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(6): Bottleneck(
(conv1): Conv2d(400, 100, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn1): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shuffle1): ShuffleBlock()
(conv2): Conv2d(100, 100, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=100, bias=False)
(bn2): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(100, 400, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn3): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(7): Bottleneck(
(conv1): Conv2d(400, 100, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn1): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shuffle1): ShuffleBlock()
(conv2): Conv2d(100, 100, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=100, bias=False)
(bn2): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(100, 400, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn3): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(400, 100, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn1): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shuffle1): ShuffleBlock()
(conv2): Conv2d(100, 100, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=100, bias=False)
(bn2): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(100, 400, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn3): BatchNorm2d(400, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential(
(0): AvgPool2d(kernel_size=3, stride=2, padding=1)
)
)
(1): Bottleneck(
(conv1): Conv2d(800, 200, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn1): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shuffle1): ShuffleBlock()
(conv2): Conv2d(200, 200, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=200, bias=False)
(bn2): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(200, 800, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn3): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(2): Bottleneck(
(conv1): Conv2d(800, 200, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn1): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shuffle1): ShuffleBlock()
(conv2): Conv2d(200, 200, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=200, bias=False)
(bn2): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(200, 800, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn3): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
(3): Bottleneck(
(conv1): Conv2d(800, 200, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn1): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shuffle1): ShuffleBlock()
(conv2): Conv2d(200, 200, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=200, bias=False)
(bn2): BatchNorm2d(200, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(200, 800, kernel_size=(1, 1), stride=(1, 1), groups=2, bias=False)
(bn3): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Sequential()
)
)
(linear): Linear(in_features=800, out_features=10, bias=True)
)
测试和定义网络
接下来可以简单测试一下,是否输入后能得到我们的正确的维度shape
test_x = torch.randn(2,3,32,32).to(device)
test_y = net(test_x)
print(test_y.shape)
torch.Size([2, 10])
定义网络和设置类别
net = ShuffleNetG2(num_classes=10)
5. 定义损失函数和优化器
pytorch将深度学习中常用的优化方法全部封装在torch.optim之中,所有的优化方法都是继承基类optim.Optimizier
损失函数是封装在神经网络工具箱nn中的,包含很多损失函数
这里我使用的是SGD + momentum算法,并且我们损失函数定义为交叉熵函数,除此之外学习策略定义为动态更新学习率,如果5次迭代后,训练的损失并没有下降,那么我们便会更改学习率,会变为原来的0.5倍,最小降低到0.00001
如果想更加了解优化器和学习率策略的话,可以参考以下资料
- Pytorch Note15 优化算法1 梯度下降(Gradient descent varients)
- Pytorch Note16 优化算法2 动量法(Momentum)
- Pytorch Note34 学习率衰减
这里决定迭代10次
import torch.optim as optim
optimizer = optim.SGD(net.parameters(), lr=1e-1, momentum=0.9, weight_decay=5e-4)
criterion = nn.CrossEntropyLoss()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', factor=0.94 ,patience = 1,min_lr = 0.000001) # 动态更新学习率
# scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[75, 150], gamma=0.5)
import time
epoch = 10
6. 训练及可视化(增加TensorBoard可视化)
首先定义模型保存的位置
import os
if not os.path.exists('./model'):
os.makedirs('./model')
else:
print('文件已存在')
save_path = './model/ShuffleNet.pth'
这次更新了tensorboard的可视化,可以得到更好看的图片,并且能可视化出不错的结果
# 使用tensorboard
from torch.utils.tensorboard import SummaryWriter
os.makedirs("./logs", exist_ok=True)
tbwriter = SummaryWriter(log_dir='./logs/ShuffleNet', comment='ShuffleNet') # 使用tensorboard记录中间输出
tbwriter.add_graph(model= net, input_to_model=torch.randn(size=(1, 3, 32, 32)))
如果存在GPU可以选择使用GPU进行运行,并且可以设置并行运算
if device == 'cuda':
net.to(device)
net = nn.DataParallel(net) # 使用并行运算
开始训练
我定义了一个train函数,在train函数中进行一个训练,并保存我们训练后的模型,这一部分一定要注意,这里的utils文件是我个人写的,所以需要下载下来
或者可以参考我们的工具函数篇,我还更新了结果和方法,利用tqdm更能可视化我们的结果。
from utils import plot_history
from utils import train
Acc, Loss, Lr = train(net, trainloader, testloader, epoch, optimizer, criterion, scheduler, save_path, tbwriter, verbose = True)
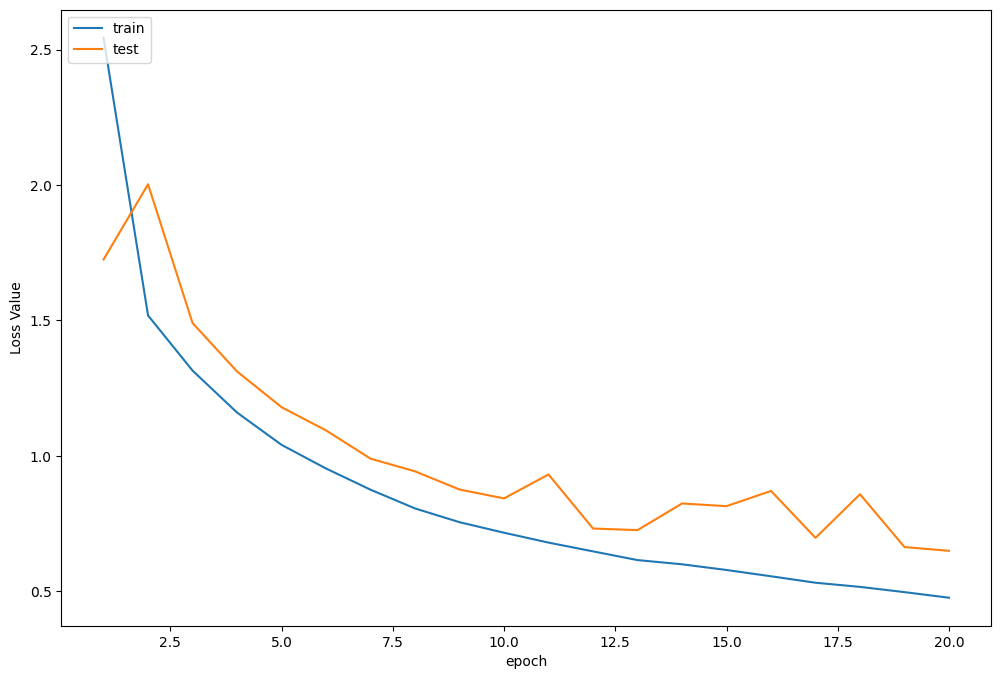
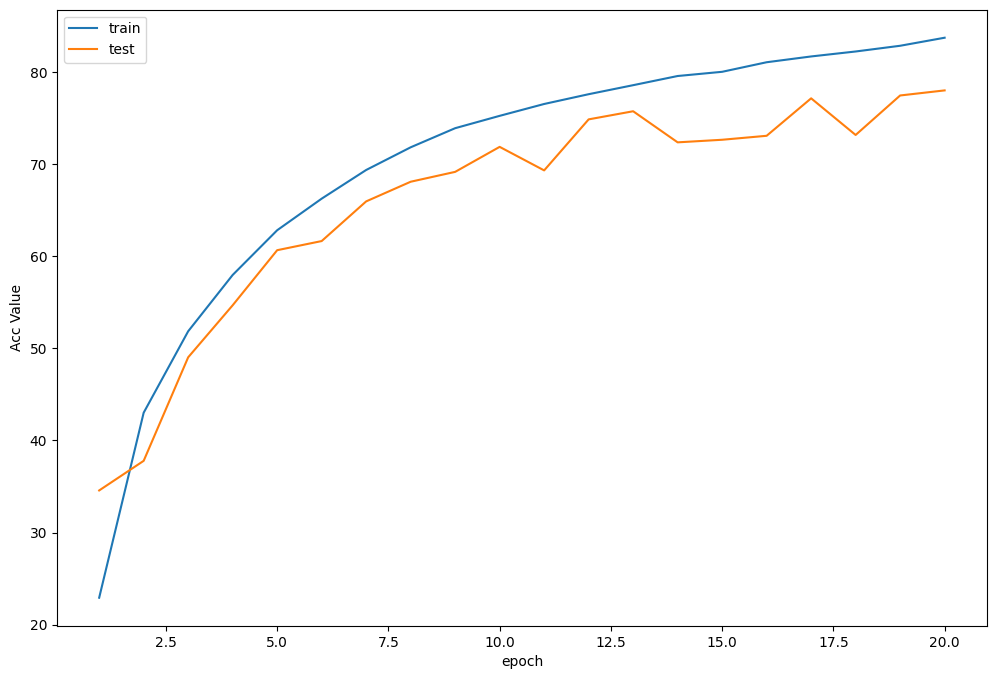
Train Epoch 1/20: 100%|██████████| 390/390 [00:32<00:00, 12.14it/s, Train Acc=0.229, Train Loss=2.54] Test Epoch 1/20: 100%|██████████| 78/78 [00:01<00:00, 45.67it/s, Test Acc=0.346, Test Loss=1.72] Epoch [ 1/ 20] Train Loss:2.543527 Train Acc:22.93% Test Loss:1.724631 Test Acc:34.58% Learning Rate:0.100000 Train Epoch 2/20: 100%|██████████| 390/390 [00:31<00:00, 12.22it/s, Train Acc=0.43, Train Loss=1.52] Test Epoch 2/20: 100%|██████████| 78/78 [00:01<00:00, 45.55it/s, Test Acc=0.378, Test Loss=2] Epoch [ 2/ 20] Train Loss:1.517884 Train Acc:43.01% Test Loss:2.002310 Test Acc:37.79% Learning Rate:0.100000 Train Epoch 3/20: 100%|██████████| 390/390 [00:33<00:00, 11.77it/s, Train Acc=0.519, Train Loss=1.31] Test Epoch 3/20: 100%|██████████| 78/78 [00:01<00:00, 44.93it/s, Test Acc=0.49, Test Loss=1.49] Epoch [ 3/ 20] Train Loss:1.314360 Train Acc:51.85% Test Loss:1.490109 Test Acc:49.03% Learning Rate:0.100000 Train Epoch 4/20: 100%|██████████| 390/390 [00:32<00:00, 12.02it/s, Train Acc=0.58, Train Loss=1.16] Test Epoch 4/20: 100%|██████████| 78/78 [00:01<00:00, 47.60it/s, Test Acc=0.547, Test Loss=1.31] Epoch [ 4/ 20] Train Loss:1.159399 Train Acc:57.97% Test Loss:1.311152 Test Acc:54.68% Learning Rate:0.100000 Train Epoch 5/20: 100%|██████████| 390/390 [00:32<00:00, 11.83it/s, Train Acc=0.628, Train Loss=1.04] Test Epoch 5/20: 100%|██████████| 78/78 [00:01<00:00, 46.65it/s, Test Acc=0.607, Test Loss=1.18] Epoch [ 5/ 20] Train Loss:1.040222 Train Acc:62.82% Test Loss:1.179275 Test Acc:60.66% Learning Rate:0.100000 Train Epoch 6/20: 100%|██████████| 390/390 [00:31<00:00, 12.24it/s, Train Acc=0.663, Train Loss=0.953] Test Epoch 6/20: 100%|██████████| 78/78 [00:01<00:00, 47.93it/s, Test Acc=0.616, Test Loss=1.09] Epoch [ 6/ 20] Train Loss:0.952787 Train Acc:66.25% Test Loss:1.093483 Test Acc:61.65% Learning Rate:0.100000 Train Epoch 7/20: 100%|██████████| 390/390 [00:32<00:00, 11.92it/s, Train Acc=0.694, Train Loss=0.875] Test Epoch 7/20: 100%|██████████| 78/78 [00:01<00:00, 45.46it/s, Test Acc=0.66, Test Loss=0.989] Epoch [ 7/ 20] Train Loss:0.874572 Train Acc:69.36% Test Loss:0.989161 Test Acc:65.96% Learning Rate:0.100000 Train Epoch 8/20: 100%|██████████| 390/390 [00:32<00:00, 11.87it/s, Train Acc=0.718, Train Loss=0.805] Test Epoch 8/20: 100%|██████████| 78/78 [00:01<00:00, 47.33it/s, Test Acc=0.681, Test Loss=0.942] Epoch [ 8/ 20] Train Loss:0.805317 Train Acc:71.83% Test Loss:0.942337 Test Acc:68.09% Learning Rate:0.100000 Train Epoch 9/20: 100%|██████████| 390/390 [00:33<00:00, 11.48it/s, Train Acc=0.739, Train Loss=0.755] Test Epoch 9/20: 100%|██████████| 78/78 [00:01<00:00, 47.49it/s, Test Acc=0.692, Test Loss=0.875] Epoch [ 9/ 20] Train Loss:0.754513 Train Acc:73.90% Test Loss:0.875162 Test Acc:69.16% Learning Rate:0.100000 Train Epoch 10/20: 100%|██████████| 390/390 [00:33<00:00, 11.73it/s, Train Acc=0.752, Train Loss=0.716] Test Epoch 10/20: 100%|██████████| 78/78 [00:01<00:00, 47.51it/s, Test Acc=0.719, Test Loss=0.842] Epoch [ 10/ 20] Train Loss:0.715658 Train Acc:75.24% Test Loss:0.842443 Test Acc:71.88% Learning Rate:0.100000 Train Epoch 11/20: 100%|██████████| 390/390 [00:32<00:00, 11.85it/s, Train Acc=0.765, Train Loss=0.679] Test Epoch 11/20: 100%|██████████| 78/78 [00:01<00:00, 46.04it/s, Test Acc=0.693, Test Loss=0.931] Epoch [ 11/ 20] Train Loss:0.679201 Train Acc:76.53% Test Loss:0.930786 Test Acc:69.32% Learning Rate:0.100000 Train Epoch 12/20: 100%|██████████| 390/390 [00:32<00:00, 11.95it/s, Train Acc=0.776, Train Loss=0.647] Test Epoch 12/20: 100%|██████████| 78/78 [00:01<00:00, 47.52it/s, Test Acc=0.749, Test Loss=0.731] Epoch [ 12/ 20] Train Loss:0.646786 Train Acc:77.59% Test Loss:0.731182 Test Acc:74.86% Learning Rate:0.100000 Train Epoch 13/20: 100%|██████████| 390/390 [00:33<00:00, 11.73it/s, Train Acc=0.786, Train Loss=0.615] Test Epoch 13/20: 100%|██████████| 78/78 [00:01<00:00, 48.19it/s, Test Acc=0.757, Test Loss=0.725] Epoch [ 13/ 20] Train Loss:0.614621 Train Acc:78.57% Test Loss:0.725260 Test Acc:75.74% Learning Rate:0.100000 Train Epoch 14/20: 100%|██████████| 390/390 [00:36<00:00, 10.63it/s, Train Acc=0.796, Train Loss=0.599] Test Epoch 14/20: 100%|██████████| 78/78 [00:01<00:00, 46.52it/s, Test Acc=0.724, Test Loss=0.824] Epoch [ 14/ 20] Train Loss:0.599098 Train Acc:79.57% Test Loss:0.823643 Test Acc:72.37% Learning Rate:0.100000 Train Epoch 15/20: 100%|██████████| 390/390 [00:33<00:00, 11.58it/s, Train Acc=0.8, Train Loss=0.578] Test Epoch 15/20: 100%|██████████| 78/78 [00:01<00:00, 47.83it/s, Test Acc=0.726, Test Loss=0.814] Epoch [ 15/ 20] Train Loss:0.578047 Train Acc:80.02% Test Loss:0.813756 Test Acc:72.65% Learning Rate:0.100000 Train Epoch 16/20: 100%|██████████| 390/390 [00:35<00:00, 10.95it/s, Train Acc=0.811, Train Loss=0.555] Test Epoch 16/20: 100%|██████████| 78/78 [00:01<00:00, 46.78it/s, Test Acc=0.731, Test Loss=0.87] Epoch [ 16/ 20] Train Loss:0.554816 Train Acc:81.06% Test Loss:0.869965 Test Acc:73.08% Learning Rate:0.100000 Train Epoch 17/20: 100%|██████████| 390/390 [00:33<00:00, 11.50it/s, Train Acc=0.817, Train Loss=0.531] Test Epoch 17/20: 100%|██████████| 78/78 [00:01<00:00, 47.13it/s, Test Acc=0.771, Test Loss=0.697] Epoch [ 17/ 20] Train Loss:0.530995 Train Acc:81.69% Test Loss:0.696719 Test Acc:77.14% Learning Rate:0.100000 Train Epoch 18/20: 100%|██████████| 390/390 [00:34<00:00, 11.36it/s, Train Acc=0.822, Train Loss=0.516] Test Epoch 18/20: 100%|██████████| 78/78 [00:01<00:00, 48.65it/s, Test Acc=0.732, Test Loss=0.858] Epoch [ 18/ 20] Train Loss:0.515668 Train Acc:82.23% Test Loss:0.857775 Test Acc:73.17% Learning Rate:0.100000 Train Epoch 19/20: 100%|██████████| 390/390 [00:33<00:00, 11.54it/s, Train Acc=0.829, Train Loss=0.496] Test Epoch 19/20: 100%|██████████| 78/78 [00:01<00:00, 47.36it/s, Test Acc=0.775, Test Loss=0.663] Epoch [ 19/ 20] Train Loss:0.496287 Train Acc:82.85% Test Loss:0.662742 Test Acc:77.45% Learning Rate:0.100000 Train Epoch 20/20: 100%|██████████| 390/390 [00:32<00:00, 11.95it/s, Train Acc=0.837, Train Loss=0.476] Test Epoch 20/20: 100%|██████████| 78/78 [00:01<00:00, 48.77it/s, Test Acc=0.78, Test Loss=0.649] Epoch [ 20/ 20] Train Loss:0.475645 Train Acc:83.72% Test Loss:0.648839 Test Acc:78.00% Learning Rate:0.100000
训练曲线可视化
接着可以分别打印,损失函数曲线,准确率曲线和学习率曲线
plot_history(epoch ,Acc, Loss, Lr)
损失函数曲线
准确率曲线
学习率曲线
可以运行以下代码进行可视化
tensorboard --logdir logs
7.测试
查看准确率
correct = 0 # 定义预测正确的图片数,初始化为0
total = 0 # 总共参与测试的图片数,也初始化为0
# testloader = torch.utils.data.DataLoader(testset, batch_size=32,shuffle=True, num_workers=2)
for data in testloader: # 循环每一个batch
images, labels = data
images = images.to(device)
labels = labels.to(device)
net.eval() # 把模型转为test模式
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
outputs = net(images) # 输入网络进行测试
# outputs.data是一个4x10张量,将每一行的最大的那一列的值和序号各自组成一个一维张量返回,第一个是值的张量,第二个是序号的张量。
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0) # 更新测试图片的数量
correct += (predicted == labels).sum() # 更新正确分类的图片的数量
print('Accuracy of the network on the 10000 test images: %.2f %%' % (100 * correct / total))
Accuracy of the network on the 10000 test images: 77.95 %
可以看到ShuffleNet的模型在测试集中准确率达到77.95%左右
程序中的 torch.max(outputs.data, 1) ,返回一个tuple (元组)
而这里很明显,这个返回的元组的第一个元素是image data,即是最大的 值,第二个元素是label, 即是最大的值 的 索引!我们只需要label(最大值的索引),所以就会有_,predicted这样的赋值语句,表示忽略第一个返回值,把它赋值给 _, 就是舍弃它的意思;
查看每一类的准确率
# 定义2个存储每类中测试正确的个数的 列表,初始化为0
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
# testloader = torch.utils.data.DataLoader(testset, batch_size=64,shuffle=True, num_workers=2)
net.eval()
with torch.no_grad():
for data in testloader:
images, labels = data
images = images.to(device)
labels = labels.to(device)
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
#4组(batch_size)数据中,输出于label相同的,标记为1,否则为0
c = (predicted == labels).squeeze()
for i in range(len(images)): # 因为每个batch都有4张图片,所以还需要一个4的小循环
label = labels[i] # 对各个类的进行各自累加
class_correct[label] += c[i]
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %.2f %%' % (classes[i], 100 * class_correct[i] / class_total[i]))
Accuracy of airplane : 83.67 % Accuracy of automobile : 89.68 % Accuracy of bird : 67.94 % Accuracy of cat : 63.23 % Accuracy of deer : 78.08 % Accuracy of dog : 67.90 % Accuracy of frog : 87.50 % Accuracy of horse : 81.54 % Accuracy of ship : 77.48 % Accuracy of truck : 82.60 %
抽样测试并可视化一部分结果
dataiter = iter(testloader)
images, labels = dataiter.next()
images_ = images
#images_ = images_.view(images.shape[0], -1)
images_ = images_.to(device)
labels = labels.to(device)
val_output = net(images_)
_, val_preds = torch.max(val_output, 1)
fig = plt.figure(figsize=(25,4))
correct = torch.sum(val_preds == labels.data).item()
val_preds = val_preds.cpu()
labels = labels.cpu()
print("Accuracy Rate = {}%".format(correct/len(images) * 100))
fig = plt.figure(figsize=(25,25))
for idx in np.arange(64):
ax = fig.add_subplot(8, 8, idx+1, xticks=[], yticks=[])
#fig.tight_layout()
# plt.imshow(im_convert(images[idx]))
imshow(images[idx])
ax.set_title("{}, ({})".format(classes[val_preds[idx].item()], classes[labels[idx].item()]),
color = ("green" if val_preds[idx].item()==labels[idx].item() else "red"))
Accuracy Rate = 81.25%

8. 保存模型
torch.save(net,save_path[:-4]+'_'+str(epoch)+'.pth')
9. 预测
读取本地图片进行预测
import torch
from PIL import Image
from torch.autograd import Variable
import torch.nn.functional as F
from torchvision import datasets, transforms
import numpy as np
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = ShuffleNetG2(num_classes=10)
model = torch.load(save_path, map_location="cpu") # 加载模型
model.to(device)
model.eval() # 把模型转为test模式
并且为了方便,定义了一个predict函数,简单思想就是,先resize成网络使用的shape,然后进行变化tensor输入即可,不过这里有一个点,我们需要对我们的图片也进行transforms,因为我们的训练的时候,对每个图像也是进行了transforms的,所以我们需要保持一致
def predict(img):
trans = transforms.Compose([transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5),
std=(0.5, 0.5, 0.5)),
])
img = trans(img)
img = img.to(device)
# 图片扩展多一维,因为输入到保存的模型中是4维的[batch_size,通道,长,宽],而普通图片只有三维,[通道,长,宽]
img = img.unsqueeze(0) # 扩展后,为[1,3,32,32]
output = model(img)
prob = F.softmax(output,dim=1) #prob是10个分类的概率
print("概率",prob)
value, predicted = torch.max(output.data, 1)
print("类别",predicted.item())
print(value)
pred_class = classes[predicted.item()]
print("分类",pred_class)
# 读取要预测的图片
img = Image.open("./airplane.jpg").convert('RGB') # 读取图像
img

predict(img)
概率 tensor([[9.9983e-01, 1.6512e-07, 1.3221e-04, 7.2589e-07, 5.4374e-06, 3.2806e-08,
1.3370e-06, 1.8729e-07, 2.4432e-05, 1.0642e-06]], device='cuda:0',
grad_fn=<SoftmaxBackward0>)
类别 0
tensor([10.7432], device='cuda:0')
分类 plane
这里就可以看到,我们最后的结果,分类为plane,我们的置信率大概是99.8%,看起来是很不错的,置信度很高,说明预测的还是比较准确的。
读取图片地址进行预测
我们也可以通过读取图片的url地址进行预测,这里我找了多个不同的图片进行预测
import requests
from PIL import Image
url = 'https://dss2.bdstatic.com/70cFvnSh_Q1YnxGkpoWK1HF6hhy/it/u=947072664,3925280208&fm=26&gp=0.jpg'
url = 'https://ss0.bdstatic.com/70cFuHSh_Q1YnxGkpoWK1HF6hhy/it/u=2952045457,215279295&fm=26&gp=0.jpg'
url = 'https://ss0.bdstatic.com/70cFvHSh_Q1YnxGkpoWK1HF6hhy/it/u=2838383012,1815030248&fm=26&gp=0.jpg'
url = 'https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fwww.goupuzi.com%2Fnewatt%2FMon_1809%2F1_179223_7463b117c8a2c76.jpg&refer=http%3A%2F%2Fwww.goupuzi.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1624346733&t=36ba18326a1e010737f530976201326d'
url = 'https://ss3.bdstatic.com/70cFv8Sh_Q1YnxGkpoWK1HF6hhy/it/u=2799543344,3604342295&fm=224&gp=0.jpg'
# url = 'https://ss1.bdstatic.com/70cFuXSh_Q1YnxGkpoWK1HF6hhy/it/u=2032505694,2851387785&fm=26&gp=0.jpg'
response = requests.get(url, stream=True)
print (response)
img = Image.open(response.raw)
img

这里和前面是一样的
predict(img)
概率 tensor([[0.0227, 0.0007, 0.0323, 0.4136, 0.1379, 0.3642, 0.0113, 0.0127, 0.0033, 0.0012]], device='cuda:0', grad_fn=<SoftmaxBackward0>) 类别 3 tensor([2.3394], device='cuda:0') 分类 cat
我们也看到,预测正确了,预测的就是猫,不过置信度没有特别高,就是41.36%,不过我只迭代了20次,如果加强迭代,应该会得到更高的置信度,如果利用真实图片预测可能也会更好。
10.总结
ShuffleNet是一种轻量级的卷积神经网络架构,旨在提供高效的计算性能和较低的模型大小。以下是ShuffleNet的主要特点和优势:
- ShuffleNet使用分组卷积和通道重排等技术来减少模型的参数量和计算复杂度,从而实现高效的计算性能。
- ShuffleNet使用通道重排操作来增加特征的交互性,从而提高模型的表现能力。
- ShuffleNet在ImageNet数据集上取得了与其他轻量级模型相当的精度,但模型大小更小。
- ShuffleNet可用于移动设备和嵌入式设备等资源受限环境下,可以实现高效的计算和推理。
总之,ShuffleNet是一种高效的轻量级卷积神经网络架构,通过使用分组卷积和通道重排等技术来减少模型大小和计算复杂度,可以在资源受限的环境下实现高效的计算和推理。
顺带提一句,我们的数据和代码都在我的汇总篇里有说明,如果需要,可以自取
这里再贴一下汇总篇:汇总篇
参考文献






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结