您现在的位置是:首页 >技术杂谈 >Dropout层的个人理解和具体使用网站首页技术杂谈
Dropout层的个人理解和具体使用
Dropout层的作用
dropout 能够避免过拟合,我们往往会在全连接层这类参数比较多的层中使用dropout;在训练包含dropout层的神经网络中,每个批次的训练数据都是随机选择,实质是训练了多个子神经网络,因为在不同的子网络中随机忽略的权重的位置不同,最后在测试的过程中,将这些小的子网络组合起来,类似一种投票的机制来作预测,有点类似于集成学习的感觉。
关于dropout,有nn.Dropout和nn.functional.dropout两种。推荐使用nn.Dropout,因为一般情况下只有训练train时才用dropout,在eval不需要dropout。使用nn.Dropout,在调用model.eval()后,模型的dropout层和批归一化(batchnorm)都关闭,但用nn.functional.dropout,在没有设置training模式下调用model.eval()后不会关闭dropout。
这里关闭dropout等的目的是为了测试我们训练好的网络。在eval模式下,dropout层会让所有的激活单元都通过,而batchnorm层会停止计算和更新mean和var,直接使用在train训练阶段已经学出的mean和var值。同时我们在用模型做预测的时候也应该声明model.eval()。
注⚠️:为了进一步加速模型的测试,我们可以设置with torch.no_grad(),主要是用于停止autograd模块的工作,以起到加速和节省显存的作用,具体行为就是停止梯度gradient计算和储存,从而节省了GPU算力和显存,但是并不会影响dropout和batchnorm层的行为,这样我们可以使用更大的batch进行测试。
model.eval()下不启用 Batch Normalization 和 Dropout。
如果模型中有BN层(Batch Normalization)和Dropout,在测试时添加model.eval()。model.eval()是保证BN层能够用全部训练数据的均值和方差,即测试过程中要保证BN层的均值和方差不变。对于Dropout,model.eval()是利用到了所有网络连接,即不进行随机舍弃神经元。
下面一段话是关于BN层的解释:
 在训练过程中,Dropout的实现是让神经元以超参数p的概率停止工作或者激活被置为0,未被置为0的进行缩放,缩放比例为1/(1-p)
在训练过程中,Dropout的实现是让神经元以超参数p的概率停止工作或者激活被置为0,未被置为0的进行缩放,缩放比例为1/(1-p)
Dropout正则化
-
概念
-
每次迭代过程中,按照层,随机选择某些节点删除前向和后向连接
-
注意:对隐藏层的某一个节点给删掉 (dropout的时候,神经网络的输入和输出节点个数没有发生变化)
-
-
看成机器学习中的集成方法(ensemble technique)
-
删除一些神经元, 减少模型复杂度, 也减少了过拟合
-
-
被失活的神经元输出为0 其他神经元被放大 1/(1-rate)倍
-
只在网络训练时有效, 模型预测时无效
-
神经网络中独有的方法
-
重中之重:随机置零的是神经元,也就是forward里的self.linear(x)里的x
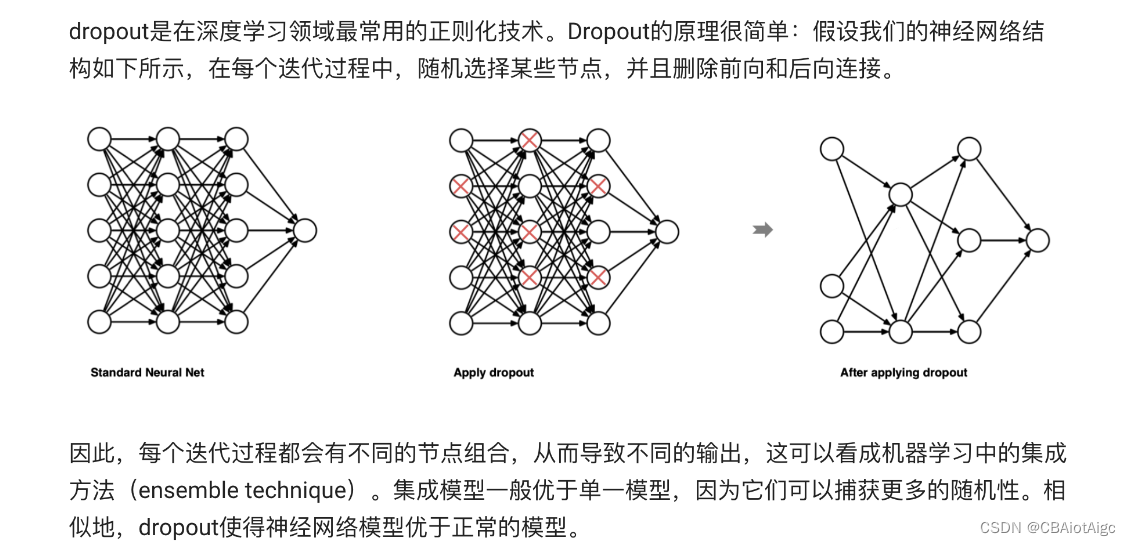
注意:Dropout只针对隐藏层来说的!!!
代码实现:
单纯调用Dropout:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
def dropout_test():
torch.random.manual_seed(0)
inputs = torch.randn(2, 5)
dropout = nn.Dropout(p=0.4)
print("dropout之前=>>>inputs", inputs)
out = dropout(inputs)
print("dropout之后=>>>inputs", out)
print("各个元素乘以 1 / (1-p)=>>>", inputs * 1 / (1 - 0.4))
if __name__ == '__main__':
dropout_test()
运行结果:
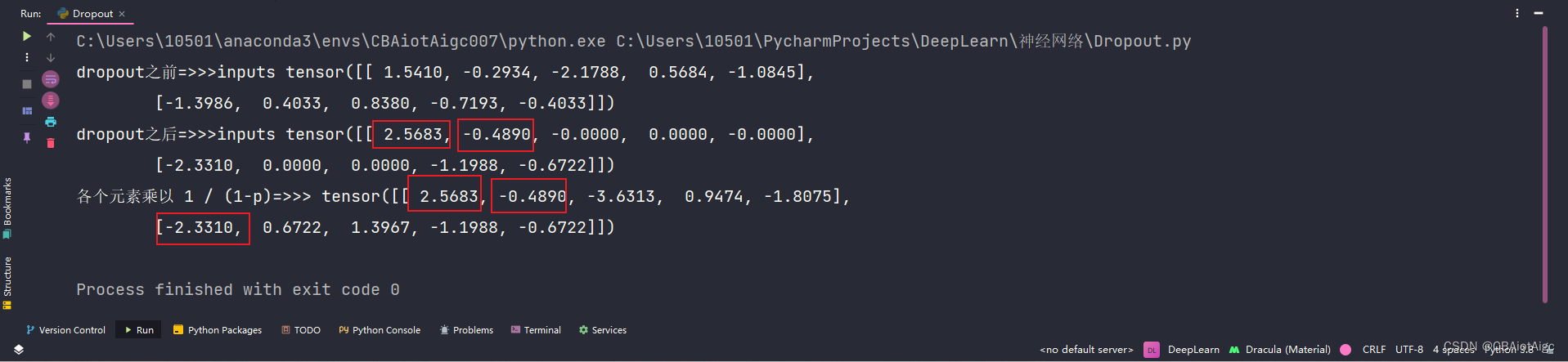
上图展示了“在训练过程中,Dropout的实现是让神经元以超参数p的概率停止工作或者激活被置为0,未被置为0的进行缩放,缩放比例为1/(1-p)”这句话的体现!!!
nn.Module类型的例子:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class LinearModule(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(in_features=3, out_features=5)
self.linear2 = nn.Linear(in_features=5, out_features=20)
self.out = nn.Linear(in_features=20, out_features=2)
self.dropout = nn.Dropout(p=0.2)
def forward(self, x):
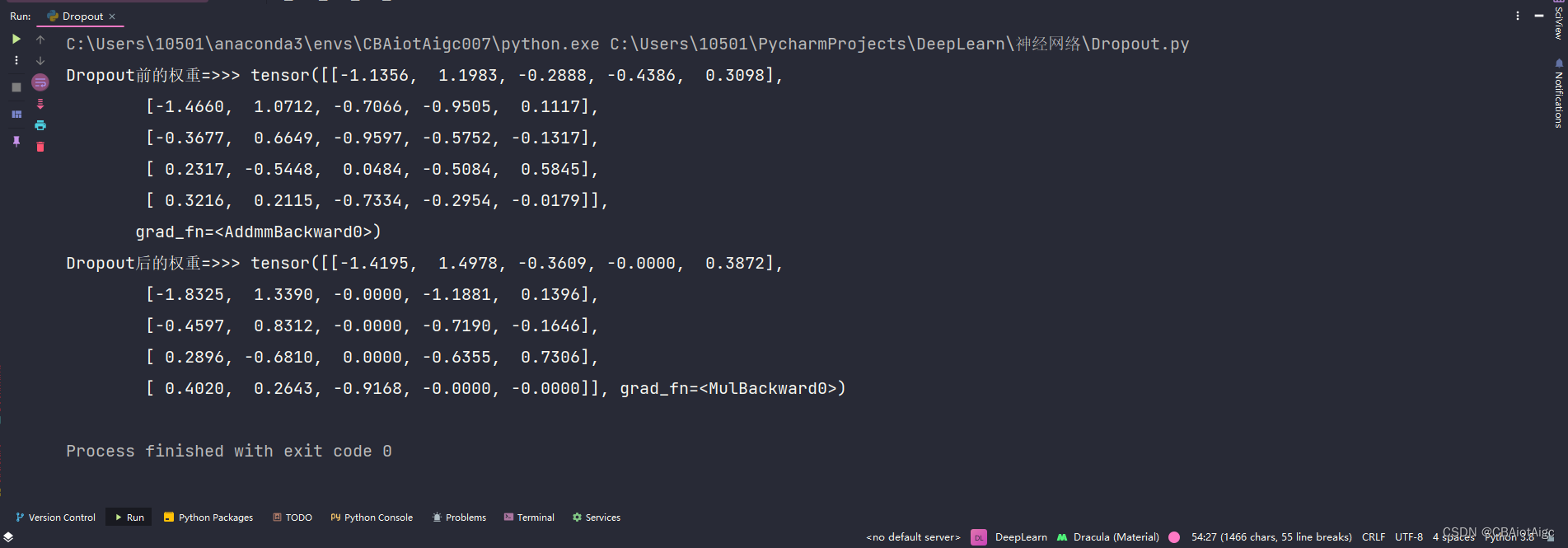
x = self.linear1(x)
print("Dropout前的权重=>>>", x)
x = self.dropout(x)
print("Dropout后的权重=>>>", x)
x = torch.relu(x)
x = self.linear2(x)
x = self.dropout(x)
x = torch.relu(x)
out = self.out(x)
return F.log_softmax(out, dim=1)
def train():
learning_rate = 0.1
inputs = torch.randn(5, 3, dtype=torch.float32)
label = torch.tensor([1, 0, 1, 0, 0], dtype=torch.int64)
model = LinearModule()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
criterion = nn.NLLLoss()
y_pred = model(inputs)
loss = criterion(y_pred, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if __name__ == '__main__':
train()
运行结果:






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结