您现在的位置是:首页 >技术教程 >[PyTorch][chapter 37][经典卷积神经网络-2 ]网站首页技术教程
[PyTorch][chapter 37][经典卷积神经网络-2 ]
1: VGG
2: GoogleNet
一 VGG
1.1 简介
VGGNet 是牛津大学计算机视觉组(Visual Geometry Group)和谷歌 DeepMind 一起研究出来的深度卷积神经网络,因而冠名为 VGG。VGG是一种被广泛使用的卷积神经网络结构,其在在2014年的 ImageNet 大规模视觉识别挑战(ILSVRC -2014)中获得了亚军,
其主要创新点:(相对alexNet)
1 是探索出了更小的卷积核 3*3, 1*1,降低了运算量,加快了模型训练速度
深度学习 1x1卷积核的作用_1*1卷积核的作用_高祥xiang的博客-CSDN博客
2 网络层次更深
1.2 网络结构
VGGNet以下6种不同结构,我们以通常所说的VGG-16(即下图D列)为例,展示其结构示意图
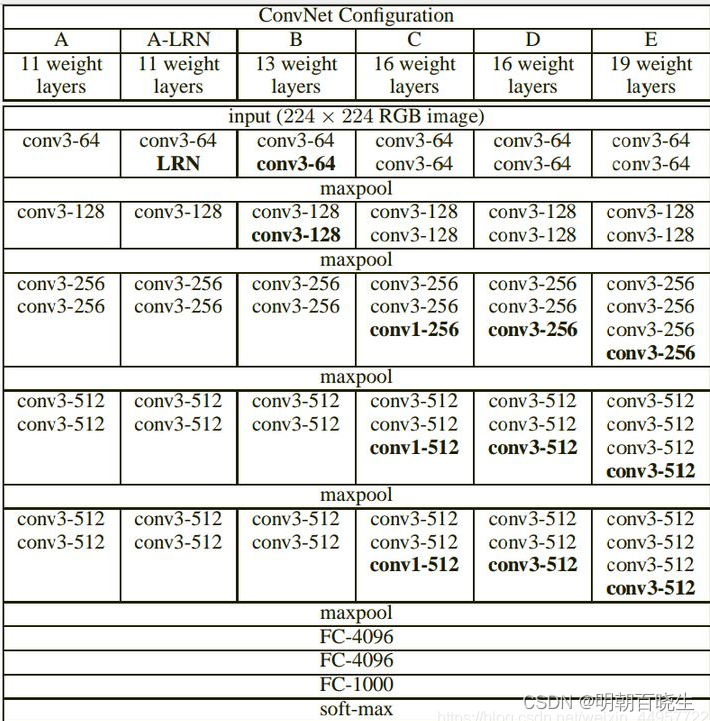
1.3 参数说明
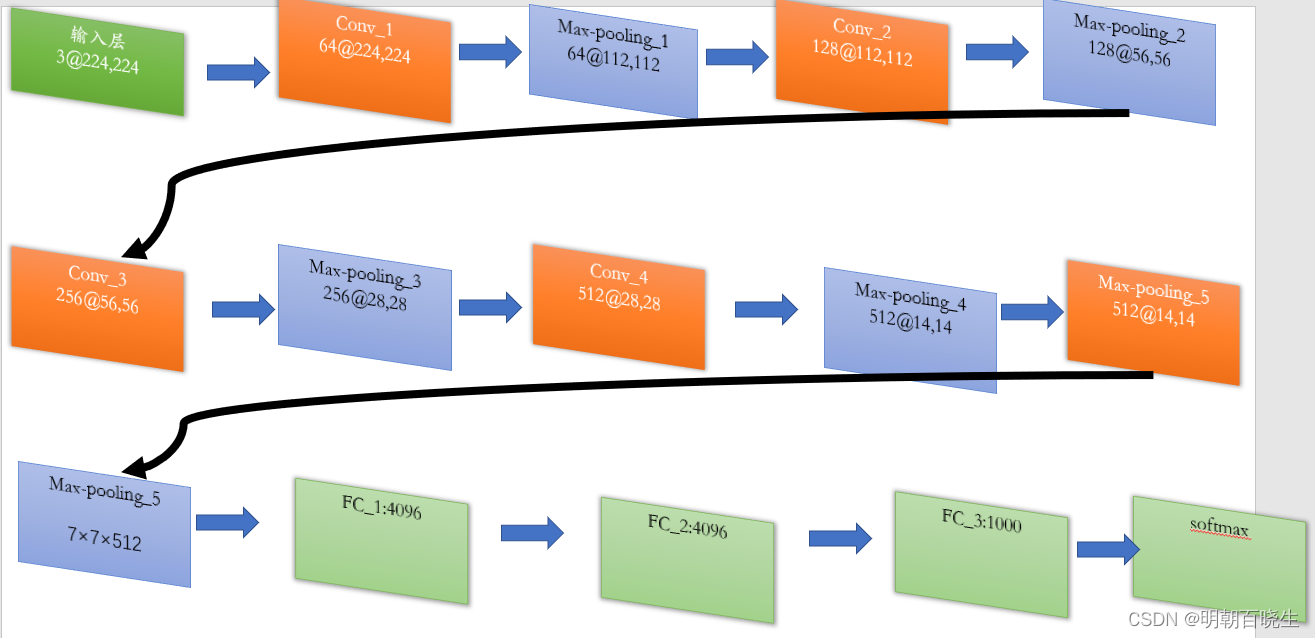
第1层输入层:
输入为3@224*224 的图片(RGB 通道为3, 宽高等于224)
第2层vgg block层:
输入为3@224*224,
卷积核: 由4个kernel size为3×3×3的filter,stride = 1,padding=same
输出:64@224*224的block层(指由conv构成的vgg-block)。
第3层Max-pooling层:
输入为64@224*224
池化:pool size=2,stride=2的减半池化
输出: 64@112×112
第4层vgg block层:
输入:64@112×112
卷积核:经128个3×3×64的filter卷积,
输出: 128@112×112。
第5层Max-pooling层:
输入为128@112×112×128,
池化:经pool size = 2,stride = 2减半池化后得到尺寸为
输出: 128@56×56
第6层vgg block层:
输入: 128@56×56
卷积核:256个3×3×128的filter卷积
输出: 256@56×56的block层。
第7层Max-pooling层:
输入: 256@56×56×256
池化:经pool size = 2,stride = 2减半池化
输出: 256@28×28
第8层vgg block层:
输入: 256@28×28
卷积核: 512个3×3×256的filter卷积
输出: 512@28×28
第9层Max-pooling层:
输入:512@28×28,
池化:经pool size = 2,stride = 2减半池化
输出:512@14×14。
第10层vgg block层:
输入: 512@14×14,
卷积核: 512个3×3×512的filter卷积,
输出 512@14×14。
第11层Max-pooling层:
输入: 512@14×14,
池化:pool size = 2,stride = 2减半池化后
输出: 512@7×7×512的池化层。
该层后面还隐藏了flatten操作,通过展平得到7×7×512=25088个参数后与之后的全连接层相连。
后面 接上FC_1,FC_2,FC_3, softmax
二 GoogleNet
GoogLeNet是2014年Christian Szegedy提出的一种全新的深度学习结构,在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。inception的提出则从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果
2.1 创新点
| 引入Inception结构,融合不同尺度的特征信息(height,width相同,在channel深度方面进行拼接) |
| 使用1x1的卷积核进行降维以及映射处理 |
| 添加两个辅助分类器帮助训练 |
| 丢弃全连接层,使用平均池化层,大大减少模型参数 |
2.2 1*1 卷积核
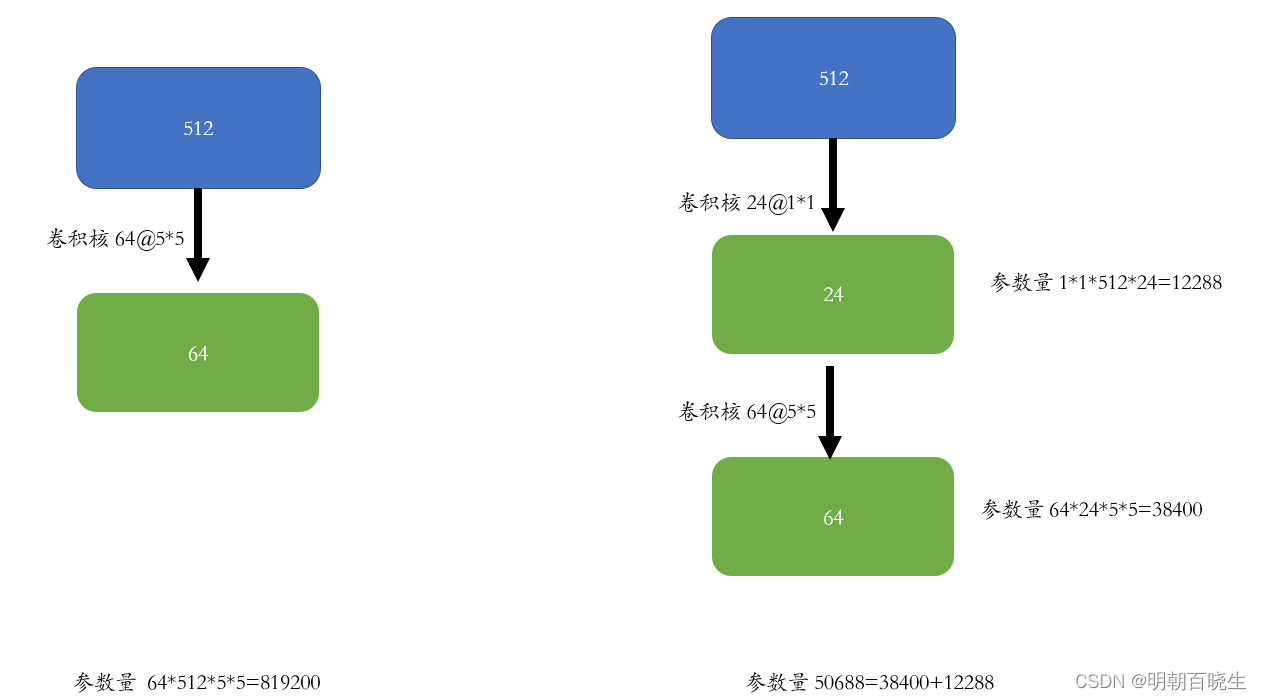
左图:
输入: channel 512
卷积核 64@5*5
输出: 64
参数量: 819200
右图:
输入: channel 512
卷积核1: 24@1*1
输出: 24
卷积核2: 64@5*5
输出: 64
参数量: 50688
降低了参数量
2.3 Inception结构
Inception结构的核心思想是将输入特征矩阵进行卷积,使得多个输出特征矩阵的高和宽相同,再将多个输出特征矩阵在深度方向进行拼接。而如图b则是引入了1x1卷积核进行降维(为了减少训练所需参数)的Inception结构。
最早版本的Inception 如下:
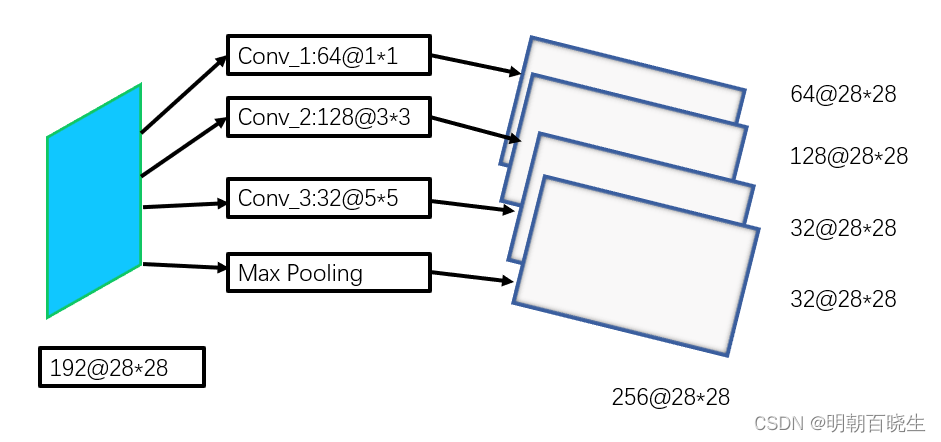
创新点
| 1 . 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合; |
| 2 串联改并联。 inception 结构之前的网络都是先 卷积 再 池化。 inception 结构 卷积和池化同时计算 |
| 3 把池化和卷积放在一层里面,Inception里面也嵌入了pooling。 |
| 4 最后把不同的feature map ,做了concate |
后面为了降低计算,又增加了在卷积核前面,又增加了1*1卷积核
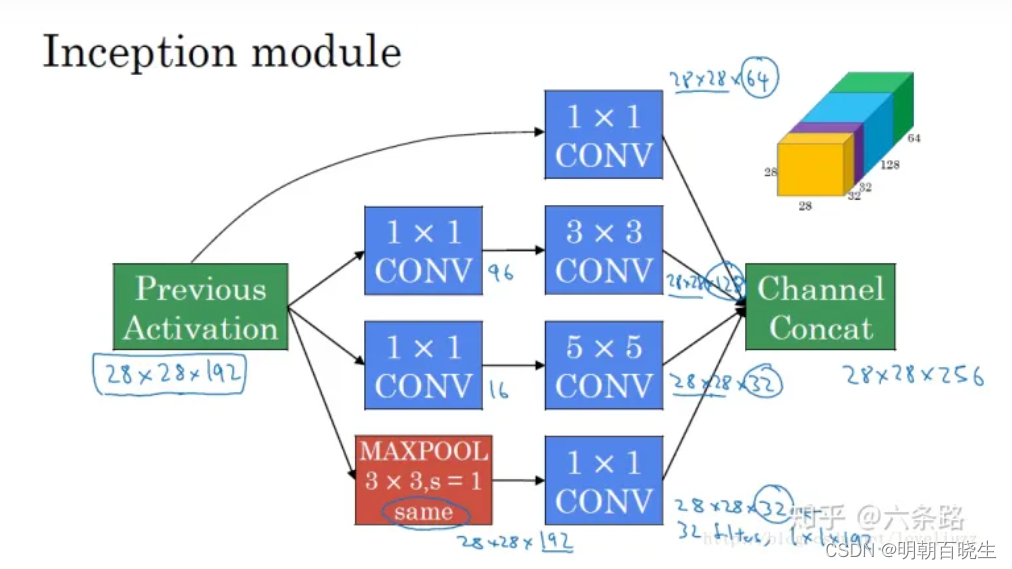
2.4 googLeNet——Inception V1结构
googlenet的主要思想就是围绕这两个思路去做的:
(1).深度,层数更深,文章采用了22层,为了避免上述提到的梯度消失问题,
googlenet巧妙的在不同深度处增加了两个loss来保证梯度回传消失的现象。
(2).宽度,增加了多种核
1x1,3x3,5x5,还有直接max pooling的,
但是如果简单的将这些应用到feature map上的话,concat起来的feature map厚度将会很大,
所以在googlenet中为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,
max pooling后分别加上了1x1的卷积核起到了降低feature map厚度的作用。

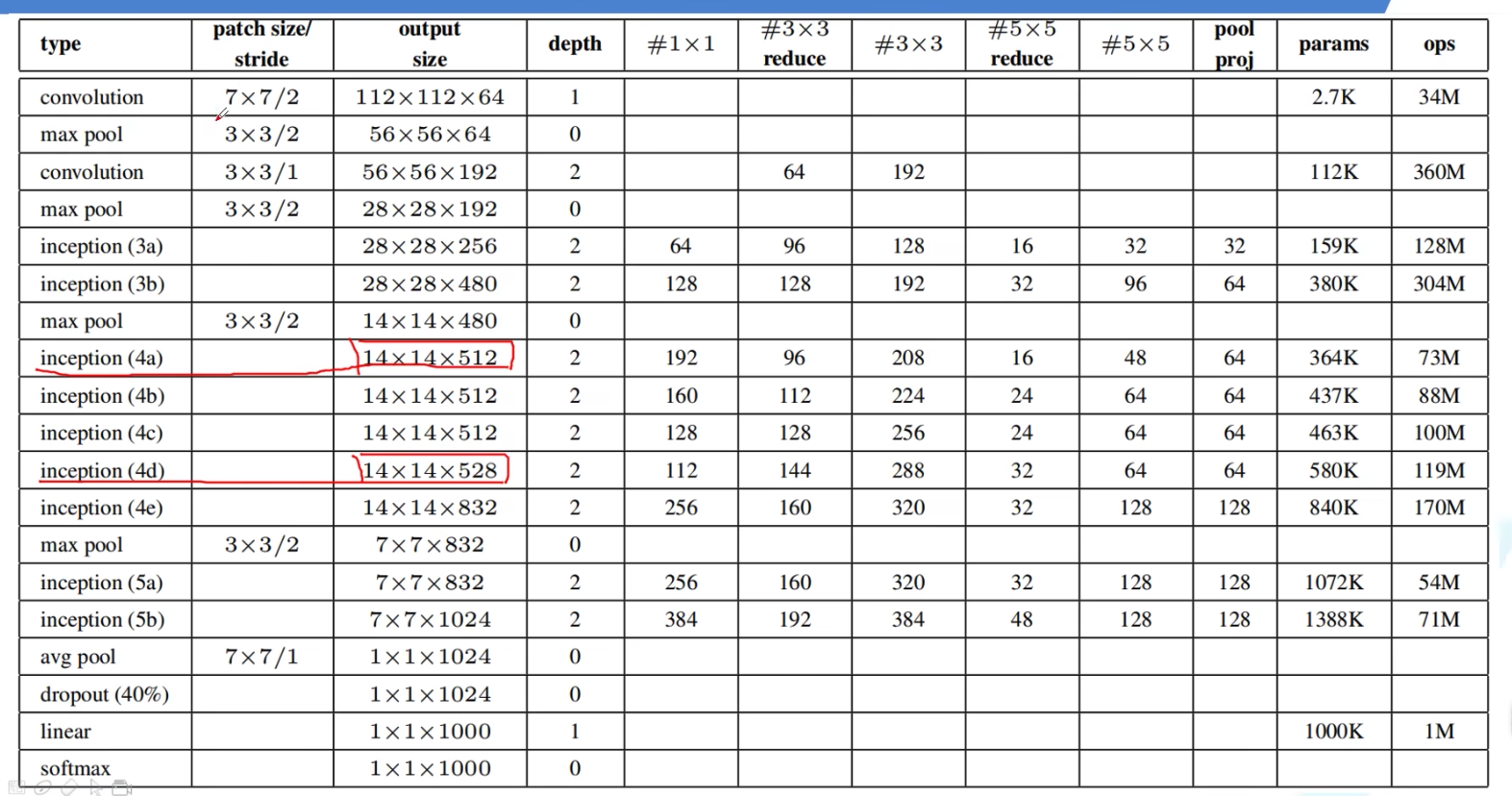
2.5 辅助分类器

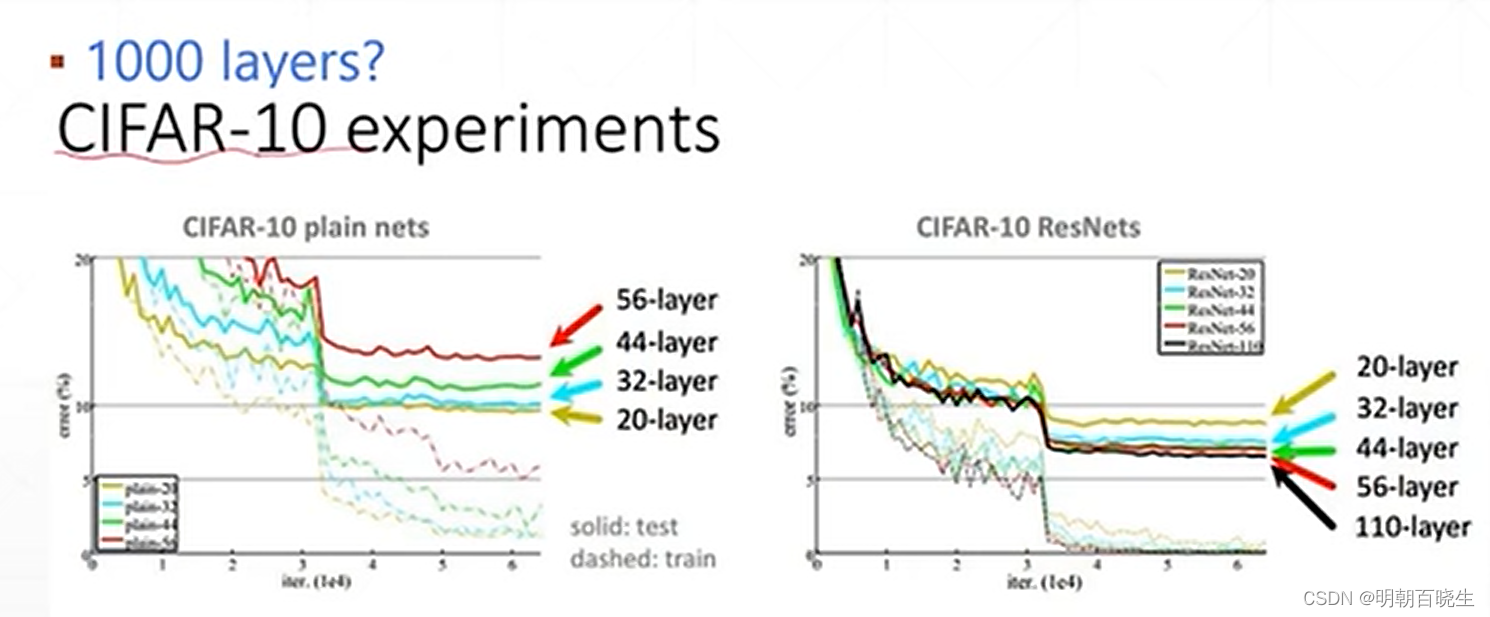
2.6 跟其它模型相比
通过下图可以看到,VGG,GoogleNet 在20层左右,再增加网络层次
已经对loss 的降低无法再优化,甚至会导致过拟合.
直到ResNets 出现。
参考:
5.1 GoogLeNet网络详解_哔哩哔哩_bilibili






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结