您现在的位置是:首页 >技术交流 >SMESwin Unet:融合CNN和Transformer进行医学图像分割网站首页技术交流
SMESwin Unet:融合CNN和Transformer进行医学图像分割
SMESwin Unet: Merging CNN and Transformer for Medical Image Segmentation
摘要
视觉Transformer 是自去年以来医学图像分割领域最受欢迎的新范式,在定量指标上超过了传统的CNN。ViTs的显著优点是利用注意力层来对token之间的全局关系进行建模。然而,ViTs表达能力的提高也带来了相应的缺点:缺乏CNN的归纳偏差(局部性)、翻译不变性和视觉信息的层次结构。因此,训练有素的ViT比CNN需要更多的数据。由于医学成像领域的高质量数据总是有限的,我们提出了SMESwin-UNet。
本文方法
- 在通道交叉融合变换器(CCT)的基础上,我们通过设计一个具有CNN和ViTs的复合结构(名为MCCT)来融合多尺度语义特征和注意力图。
- 通过将像素级特征划分为区域级来引入超像素,以避免图像中无意义部分的干扰
- 我们使用外部注意力来考虑所有数据样本之间的相关性,这可能会进一步减少小数据集的限制
本文方法
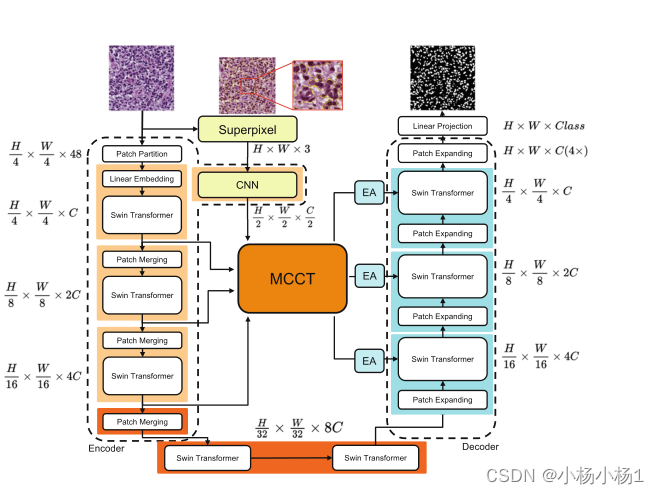
遵循Swin-Unet编码器-解码器架构。将输入图像x∈RH×W×3分割成分辨率为H4×
然后将贴片展平并传递到具有输出维度Ci的线性嵌入层中,得到原始嵌入序列e∈Rd×Ci。
变换后的patch token通过几个Swin Transformer块来提取全局信息和patch合并层,这可以减少采样并增加维度。解码器由Swin Transformer块和patch扩展层组成。
patch扩展层将以2倍分辨率的上采样执行上采样。特别地,最后一个patch扩展层执行4×上采样以将特征图恢复到输入分辨率。最后,这些上采样的特征通过线性投影层来输出像素级分割预测
Superpixel
我们通过超像素分割分支来减少原始输入图像中的无效信息。为了最大限度地降低模型的复杂性,我们使用简单线性迭代聚类(SLIC),它不需要任何超像素分割训练。关键步骤如下:
- 聚类中心 假设原始图像包括P个像素和N个超像素聚类。相邻聚类中心之间的距离近似于S=根号P/N ,在聚类中心初始化过程中,在窗口n×n的范围内,用最小梯度位置替换原始聚类中心
- 聚类阈值 对于来自图像i和j的两个像素,像素dlab的颜色相异性可以定义为:

其中Ds是聚类阈值,其中较大的值表示较高的像素相似性;m是控制聚类阈值的颜色区分和空间距离比例的平衡参数。SLIC利用聚类中心搜索2S×2S邻域:(1)如果像素的相似度高于聚类阈值,则像素应该聚类到相应的中心,以及(2)将聚类中心的符号标记分配给相应的像素。重复这个迭代过程直到收敛。
然后SLIC生成具有超像素分割的特征图,并在下一个跳过连接模块中将特征图传递给简单的CNN。
MCCT
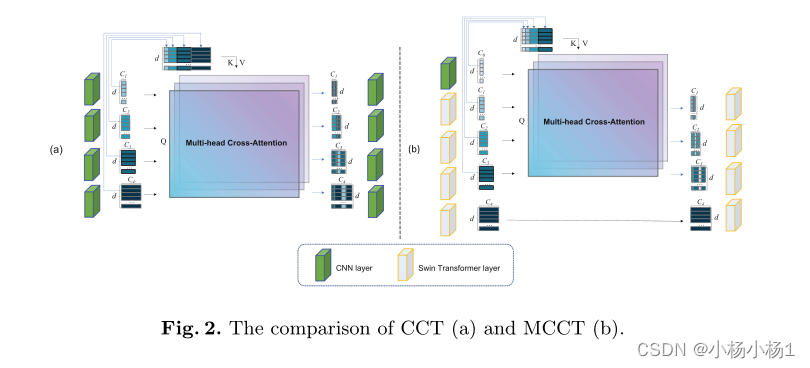
继UCTransnet中的CCT之后,提出了一种混合CNN和ViT的新型模块(MCCT)。MCCT比CCT具有更好的细节捕获能力,并且需要更少的计算
MCCT和CCT之间的两个主要区别是:
1)与CNN的一个新连接
2)删除了第四个连接。为了保持细节信息,我们对超像素特征图使用CNN层(d0)
对于来自CNN层的特征,CCT通过将编码器特征平坦化为大小为4×4的2D补丁来进行标记化,该2D补丁与来自变换器块的补丁标记具有相同的大小。在多头交叉注意中,我们使用令牌Ti∈R HW 作为查询,并使用T∑=Concat(T0,T1,T2,T3)作为key和值
然后,通过多层感知器对通道和依赖项进行编码,以细化特征
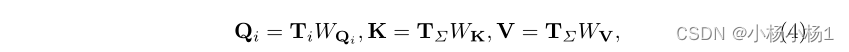
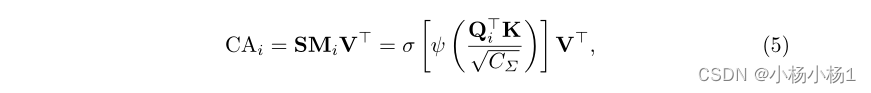





站长推荐
- U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - SpringSecurity实现前后端分离认证授权
 SpringSecurity实现前后端分离认证授权
SpringSecurity实现前后端分离认证授权