您现在的位置是:首页 >技术杂谈 >【Stata】teffects和psmatch命令区别联系 | ATE/ATU/ATT实际计算原理网站首页技术杂谈
【Stata】teffects和psmatch命令区别联系 | ATE/ATU/ATT实际计算原理
这里主要是做个学习记录。
参考链接来自: https://www.ssc.wisc.edu/sscc/pubs/stata_psmatch.htm 很经典的一篇帖子
以下主要是对用到的stata命令和过程做个记录
(以下内容需要一点点的psm基础,包括ate、atu、att,psm处理流程等。在这篇内容里没有解释。)
倾向性得分匹配
首先这个teffects和psmatch都可用来做PSM的。具体PSM是什么,简单来说就是将一堆变量,转换为一维变量。用一个变量,P-score,来代替多个变量。有点类似我们打分时的综合评分表,从不同维度打分,但最后用某种加权方式得到一个总分。
下面的图片来自我个人笔记截图。内容多来自山大陈强教授(计量经济学领域的大佬)

teffects
早期用stata处理PSM时多用psmatch命令。但是有学者表示psmatch有缺点,就是标准误有问题。所以stata12之后的版本官方推出了命令teffects。采取了学者的方法,优化了标准误计算。

stata命令
以下命令来自开头的参考链接。代码块是Python,但是内容是stata命令哈。要在stata里面跑的。
(其实stata推出了和jupyter notebook合作的插件还是啥,可以用python写命令。但我没研究)
1 导入数据
use http://ssc.wisc.edu/sscc/pubs/files/psm, replace
这是导入这个链接里面的stata文件。*.dta格式一般是
里面y是结果变量。t是区别控制组control和对照组treatment。x1和x2是协变量,也就是对y也可能有影响的变量。
举个例子,研究六一八大促对显示器销量(y)的影响,x1和x2可能是外观设计和做工材料等等。t=0和t=1表示不搞促销和搞促销的显示器。
(这里的数据对举的例子不一定恰当)
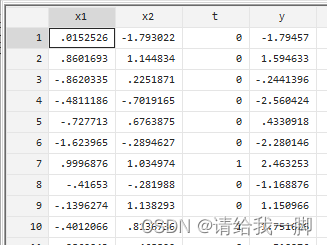
2 psmatch命令
ttest y, by(t) //双样本t检验
psmatch2 t x1 x2, out(y) //默认只计算ATT,probit模型
下图左边是双样本检验。右边是psmatch(默认用probit模型,只计算ATE)。不同颜色和形状的标记是一样的数。
可以看出,t=0也就是不促销的显示器销量为-0.4*,而t=1促销的平均销量为1.89*。差距2.314*。T值21.21*,根据t和p的对应表,p值接近99%,也就是0.01。结果显著。
最下方的图是psmatch处理后,会增加的变量。包括_pscore等等等等等。具体含义这里不解释。
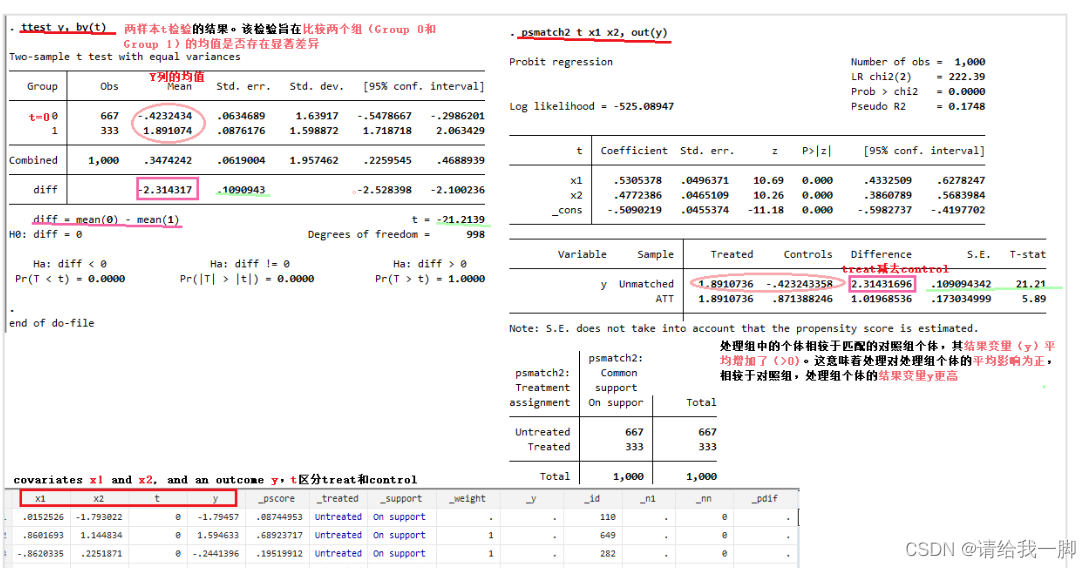
下面是之前整理的用psmatch处理psm的stata代码。
global xlist "x1 x2" //xlist表示一组协变量
****************3 估计倾向得分psmatch命令*************(陈强chapt28)(不推荐)
**数据随机排列,以计算倾向得分
drop tmp
set seed 1000 //定义种子
gen tmp=runiform() //生成随机数
sort tmp //把数据库随机整理
**du是自变量,poi_sum是因变量
**下为选择项
*ate会显示ATE、ATU和ATT的计算结果。即计算平均处理效应
*ties为所有倾向得分相同的并列个体。默认是按照排序选择一个。
*logit为采用逻辑模型估计倾向得分
*n(1)即neighbor(k),K邻近匹配,寻找p-score最近的k个不同组个体
*****7种匹配方法*******
*K邻近匹配
psmatch2 x $xlist, out(y) logit neighbor(1) ate ties
*卡尺匹配(radius即半径匹配,也就是卡尺匹配,caliiper(real)指定卡尺ε,为正实数)
psmatch2 x $xlist, out(y) radius caliper(0.1)
*卡尺内的k邻近匹配
psmatch2 x $xlist, out(y) neighbor(1) caliper(0.01)
*核匹配。kerneltype指定核函数。默认二次核(epan)。bwidth指定带宽。默认0.06
psmatch2 x $xlist, out(y) kernel kerneltype(type) bwidth(real)
*局部线性回归匹配。同核函数。默认三三核(tricubic kernel),默认带宽0.8
psmatch2 x $xlist, out(y) 11r kerneltype(type) bwidth(real)
*样条匹配
psmatch2 x $xlist, out(y) spline
3 teffects命令
use http://ssc.wisc.edu/sscc/pubs/files/psm, replace //重读数据
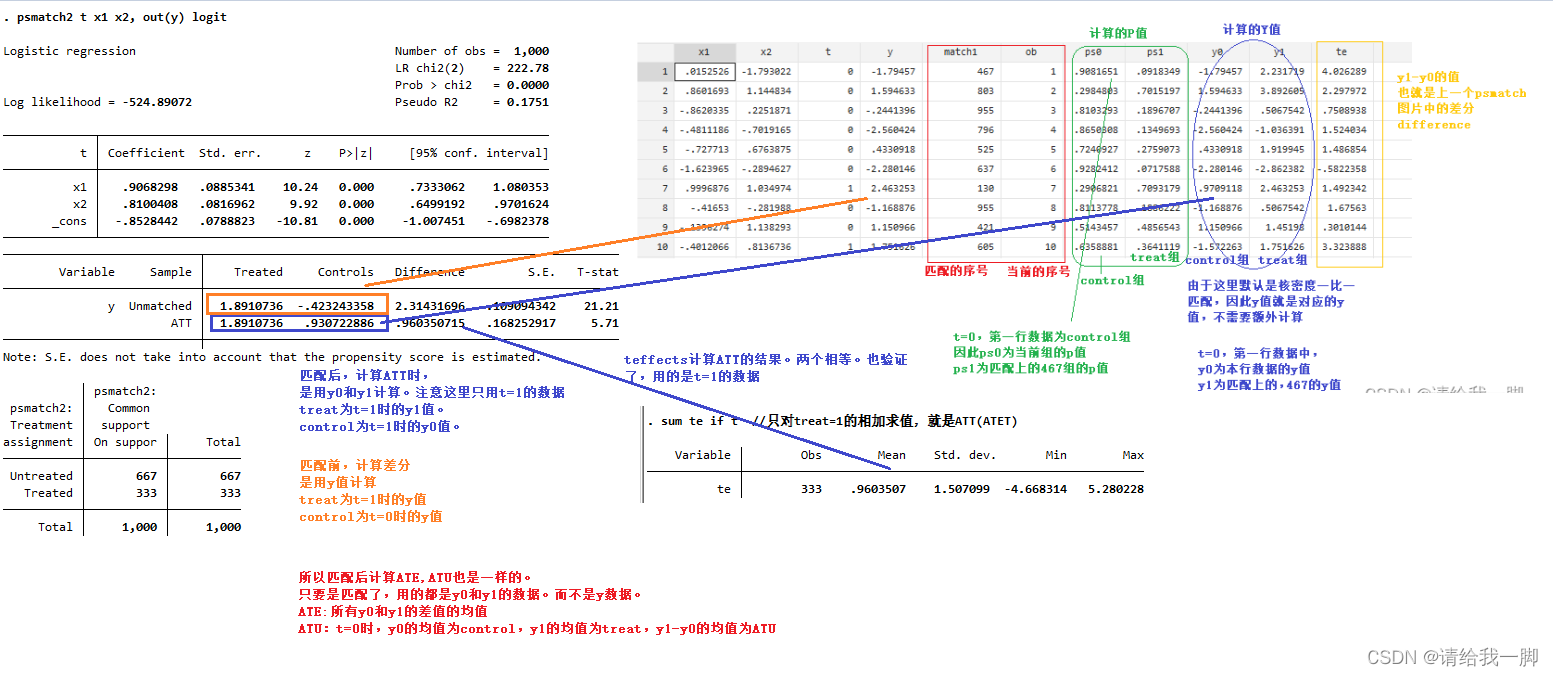
teffects psmatch (y) (t x1 x2), gen(match) //gen一列,显示每行匹配上的行号
gen ob=_n //生成序列,这样ob和match1两列表示匹配的号码
predict ps0 ps1, ps //predict…ps生成含p-score两列,ps0为control组,ps1为treat
predict y0 y1, po //po生成y的potential outcome。y0表示control,y1表示treat。
//如果第一行是control,y0就是其Y值,y1是其匹配的treat行的值
//如果是treat组,y0其匹配到的control的y值,y1是其Y值
predict te //没有其他命令的predict,生成treatment effect itself(就是y1-y0)
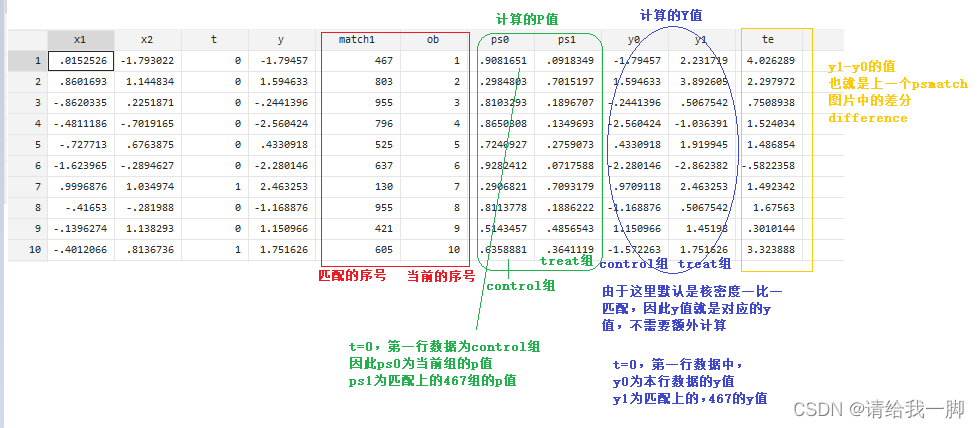
这里其实有一个问题:就是对每一行的p值,比如第一行,ps0和ps1怎么就相似或者接近了呢???
4 计算ATE/ATT/ATU
//这里是在前面 3 teffects命令基础上进行计算
sum te //(y1-y0)的值相加,生成的mean就是ATE
sum te if t //只对treat=1的相加求值,就是ATT(ATET)
//实际上,teffects命令只需要一行就够了
teffects psmatch (y) (t x1 x2)
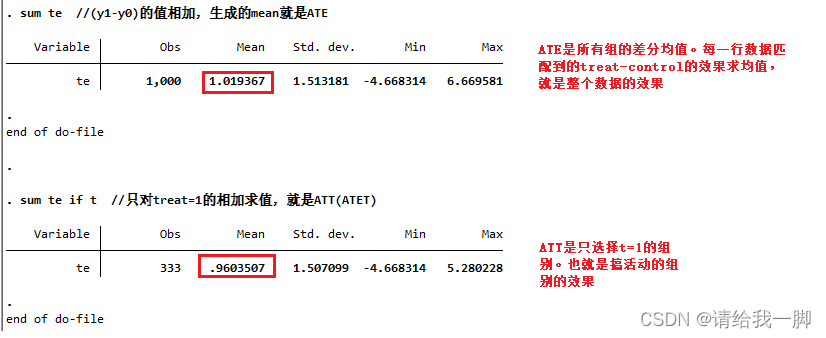
以上是给出了比较详尽的步骤显示PSM匹配,以及计算ATT的。
而如果直接用teffects命令计算。会是下面的截图。可以看见第一个值1.01*和上面截图中计算ATE的值是一样的。
注意的是这里多了一个AT ROBUST STD.ERR。就是改进后计算的标准误。
下面这个图,解释了,ATU/ATT/ATE这几个值到底是怎么计算出来的。
不管是psmatch还是teffects,都是一样的原理。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结