您现在的位置是:首页 >技术教程 >Hadoop实验四Hive实践网站首页技术教程
Hadoop实验四Hive实践
实验四 Hive实践
实验四 Hive实践介紹
- 1.实验目的
- 2.实验原理
- 3.实验准备
- 4.实验内容
时长:4次课(4周)
1.实验目的
- 熟悉Hive命令,通过编写HiveQL脚本初步掌握更高层次的ETL操作。
- 联合使用MapReduce+Hive,计算目标数据信息。
- (选做)初步掌握UDF/UDAF等自定义精细化数据计算操作,为后续学习SparkSQL和类似计算框架类SQL使用做好准备。
2.实验原理
- Hive是一种常用的数据仓库工具,帮助不熟悉Java编程的用户,依靠熟练的SQL操作实现MR程序的编写。
- Hive组件内置了解释器、编译器和优化器,能够通过预置的MR程序模板将用户编写的HiveSQL操作“翻译”成MR程序,并交给集群执行计算。
- Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,它仅仅是一种纯逻辑操作;本质上看,Hive处理的就是HDFS上的数据,可以认为是map-reduce的一种包装。
- Hive也需要缓存元数据(Metastore ),且本次实验配合MySQL存储元数据;当然也可以直接使用Hive内嵌的Derby。
3.实验准备
- 完成实验一,搭建好伪分布式环境
- 完成实验二,确保HDFS可用
- 完成实验三,掌握MR程序的编写方法
4.实验内容
【实验项目】项目1、项目2、项目3必做;项目4,及后续项目选做;注意标红的思考题,并在实验报告中给出解答。
- 项目1:Hive安装配置
- 项目2:Hive操作实践——员工工资信息统计
- 项目3:MapReduce+Hive综合实践——搜狗日志查询分析
- 项目4:Hive Java API操作
- 项目5:UDF实践
- 项目6:视频数据统计实践(2023年)
【注】由于石老师的课程中已经介绍了HBase 的API编程,所以在2023年开始,本课程实验才会加入相关内容;本年度(2022)暂时不添加这部分。
项目1:Hive安装配置
【参考链接】(梁老师博客)( Mac安装MySQL5.7.24)
https://blog.csdn.net/qq_42881421/article/details/84330906
【准备工作】
1. 安装好hadoop2.7.3(Linux环境);

2. 安装好MySQL5.7(macOS系统下),推荐使用
或者 Xampp(macOS环境)参考 [Navicat通过1P连接Xampp数据库](https://blog.csdn.net/qq_42881421/article/details/84622058);
- 【参考】命令安装MySQL(macOS系统下):https://blog.csdn.net/wangws_sb/article/details/125660076(安装MySQL)
- 【参考】Navicat通过IP连接XAMPP数据库:https://blog.csdn.net/qq_42881421/article/details/84622058( 参考)
- 用Navicat IP的方式连接到mysql数据库,如果通过IP连接失败,
【参考】通过IP连接mysql:https://blog.csdn.net/qq_42881421/article/details/84147689(IP连接mysql) - 也可以直接使用内嵌数据库或者在Linux安装MySQL,直接使用Localhost访问

3. 并新建一个名为hive的数据库(可以自拟)

【注】
- mysql安装在macOS时,需要用IP地址来连接数据库,确保navicat可以用IP连接到数据库;当网络环境变化时,macOS IP会变化,这时要注意修改hive-site.xml中的mysql连接的IP地址。
- 为避免麻烦,可以将mysql安装在Ubuntu中,hive-site.xml配置为localhost
4.实验内容【大致步骤】
(1)… 官网下载hive安装文件,下载地址:Index of /dist/hive或者 Index of /apache/hive
(2) 将hive安装文件上传到Linux系统中~/usr/local/hive_ONE目录下,解压:
cd /usr/local/hive_ONE
tar -zxvf apache-hive-2.3.6-bin.tar.gz

(3) 创建软连接:
$ ln -s apache-hive-2.3.6-bin hive

(4) 配置系统级环境变量
nano /etc/profile
末位追加
export HIVE_HOME=/usr/local/hive_ONE/hive
export PATH=$HIVE_HOME/bin:$PATH

使其生效:
source /etc/profile
(5) 配置hive-site.xml(关键步骤) *发现没有直接生写,*注意电脑IP
进入hive的配置文件目录
cd /usr/local/hive_ONE/hive/conf
创建并编写 hive-site.xml
nano hive-site.xml
或者
gedit hive-site.xml
添加以下内容
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.0.133:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>asdfghjkl</value>
</property>
</configuration>
注意:
如果用sudo touch hive-site.xml创建文件需要修改权限才能编辑,命令如下:
sudo chmod 777 hive-site.xml
javax.jdo.option.ConnectionURL属性值的(192.168.0.133)位物理机的IP地址,请注意修改!
javax.jdo.option.ConnectionUserName值的(root)为数据库的用户名,注意修改!
javax.jdo.option.ConnectionPassword的值(asdfghjkl)数据库的密码,注意修改!
(6) 将MySQL驱动文件拷贝到hive安装目录的lib下
·下载MySQL驱动

·将文件传到Linux中/usr/local/hive_ONE/hive/lib目录下面

(7) 初始化MySQL:
schematool -dbType mysql -initSchema

(8)启动Hive(先启动Hadoop:HDFS和YARN…):
start-all.sh

(9)执行hive启动客户端:
hive

项目2:Hive操作实践——员工工资信息统计
【参考链接】
【准备工作】
已经完成项目1==>参考白书教材P193
实验内容【大致步骤】
1.启动Hadoop。
start-all.sh

2.新建emp.csv和dept.csv两个数据文件,并上传到HDFS中。
创建EMP.csv
$ nano EMP.csv
在其中添加:
7369,SMITH,CLERK,7902,1980/12/17,800,,20
7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
7521,WARD,SALESMAN,7698,1981/2/22,1250,500,30
7566,JONES,MANAGER,7839,1981/4/2,2975,,20
7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981/5/1,2850,,30
7782,CLARK,MANAGER,7839,1981/6/9,2450,,10
7788,SCOTT,ANALYST,7566,1987/4/19,3000,,20
7839,KING,PRESIDENT,,1981/11/17,5000,,10
7844,TURNER,SALESMAN,7698,1981/9/8,1500,0,30
7876,ADAMS,CLERK,7788,1987/5/23,1100,,20
7900,JAMES,CLERK,7698,1981/12/3,950,,30
7902,FORD,ANALYST,7566,1981/12/3,3000,,20
7934,MILLER,CLERK,7782,1982/1/23,1300,,10
然后创建dept.csv
$ nano dept.csv
在其中添加:
10,ACCOUNTING,NEW YORK
20,RESEARCH,DALLAS
30,SALES,CHICAGO
40,OPERATIONS,BOSTON

3.启动Hive。
hive

4.创建员工表(emp001)和部门表(depto01)。
创建员工表:
create table emp001(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int,deptno int) row format delimited fields terminated by ',';

创建部门表:
create table dept001(deptno int,dname string,loc string) row format delimited fields terminated by ',';

5.将HDFS中的emp.csv和dept.csv分别导入emp001和dept001。
load data inpath '/001/hive/emp.csv' into table emp001;

load data inpath '/001/hive/dept.csv' into table dept001;

6.查询表数据。
查询emp001表:
select * from emp001;

查询dept001表:
select * from dept001;

7.根据员工的部门号创建分区,表名emp_part+学号,如:emp_partoo1,并查看分区数据。
create table emp_part001(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int)partitioned by (deptno int)row format delimited fields terminated by ',';
往分区表中插入数据:指明导入的数据的分区(通过子查询导入数据)。
insert into table emp_part001 partition(deptno=10) select empno,ename,job,mgr,hiredate,sal,comm from emp001 where deptno=10;
insert into table emp_part001 partition(deptno=20) select empno,ename,job,mgr,hiredate,sal,comm from emp001 where deptno=20;
insert into table emp_part001 partition(deptno=30) select empno,ename,job,mgr,hiredate,sal,comm from emp001 where deptno=30;
查看emp_part001表的分区情况
show partitions emp_part001;

查看分区表在HDFS中存储时对应的目录
dfs -ls /user/hive/warehouse/emp_part001;

查询某个分区的数据,例如,查看deptno=10分区的数据:
dfs -cat /user/hive/warehouse/emp_part001/deptno=10/000000_0;

查看deptno=20分区的数据:
dfs -cat /user/hive/warehouse/emp_part001/deptno=20/000000_0;

查看deptno=30分区的数据:
dfs -cat /user/hive/warehouse/emp_part001/deptno=30/000000_0;

8.创建一个桶表,表名emp_bucket+学号,如:emp_bucketoo1,根据员工的职位(job)进行分桶。
设置开启桶表:
set hive.enforce.bucketing = true;

创建桶表 :
create table emp_bucket001(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int,deptno int)clustered by (job) into 4 buckets row format delimited fields terminated by ',';

通过子查询插入数据:
insert into emp_bucket001 select * from emp001;

查询分桶数据:
dfs -ls /user/hive/warehouse/emp_bucket001;

9.查询员工信息:员工号 姓名薪水。
select empno,ename,sal from emp001;

10.多表查询。
select dept001.dname,emp001.ename from emp001,dept001 where emp001.deptno=dept001.deptno;

11.做报表,根据职位给员工涨工资,把涨前、涨后的薪水显示出来。
按如下规则涨薪,PRESIDENT涨1000元,MANAGER涨800元,其他人员涨400元

select empno,ename,job,sal,
case job when 'PRESIDENT' then sal+1000
when 'MANAGER' then sal+800
else sal+400
end
from emp001;

项目3:MapReduce+Hive综合实践一一搜狗日志查询分析
【参考链接】
https://blog.csdn.net/qq_42881421/article/details/84899795(梁老师博客)
【准备工作】
已经完成项目1、2 ==>参考白书教材P284
【模式实战场景】:从搜狗实验室下载搜索数据进行分析
下载的数据包含6个字段,数据格式说明如下:
访问时间 用户ID[查询词」该URL在返回结果中的排名 用户点击的顺序号 用户点击的URL
【注意】
1.字段分隔符:字段分隔符是个数不等的空格:
2.字段个数:有些行有6个字段,有些达不到6个字段。
实验内容【大致步骤】
MR数据清洗可能多花费时间,实验内核是通过数据分析,找到隐含在数据中的规律/价值(数据挖掘)
1.下载数据源
打开搜狗实验室链接 (搜狗实验室链接)
下载精简版
下载后文件如下:

2.上传下载文件至HDFS
2.1将下载的文件通过FileZilla工具上传到Linux系统

2.2解压SogouQ.reduced.targz并上传到HDFS
解压:
tar -zxvf SogouQ.reduced.tar.gz

可以用tail命令查看解压文件最后3行的数据:
tail -3 SogouQ.reduced
查询词为中文,这里编码按UTF-8查出来是乱码,编码时指定为‘GBK’可避免乱码。数据格式如前面的说明:
访问时间 用户ID [查询词] 该URL在返回结果中的排名 用户点击的顺序号 用户点击的URL

上传至HDFS:
hdfs dfs -put SogouQ.reduced /

3.数据清洗
因为原始数据中有些行的字段数不为6,且原始数据的字段分隔符不是Hve表规定的逗号,,所以需要对原始数据进行数据清洗。
通过编写MaoReduce程序宗成数据清洗:(打包运行)
(1)将不满足6个字段的行删除
(2)将字段分隔符由不等的空格变为逗号!分隔符
·IntelliJ IDEA中项目Hadoop中新建Maven模块:hadoop_4_3
目录结构如下:

·修改pom.xml文件
设置主类:在“< project/>”一行之前添加如下语句:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!-- main()所在的类,注意修改为包名+主类名 -->
<mainClass>com.Zongheshiyan.App</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
·添加依赖:在 “< /dependencies>”一行之前添加如下语句:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>
·新建SogouMapper类:

·编写代码:
SogouMapper.java
package com.Zongheshiyan;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
// k1 , v1, k2 , v2
public class SogouMapper extends Mapper<LongWritable,Text,Text,NullWritable> {
/**
* 在任务开始时,被调用一次。且只会被调用一次。
*/
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
}
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
//避免乱码
//数据格式:20111230000005 57375476989eea12893c0c3811607bcf 奇艺高清 1 1 http://www.qiyi.com/
String data = new String(v1.getBytes(),0,v1.getLength(),"GBK");
//split("\s+") \s+为正则表达式,意思是匹配一个或多个空白字符,包括空格、制表、换页符等。
//参考:http://www.runoob.com/java/java-regular-expressions.html
String words[] = data.split("\s+");
//判断数据如果不等于6个字段,则退出程序
if(words.length != 6){
return;//return语句后不带返回值,作用是退出该程序的运行 https://www.cnblogs.com/paomoopt/p/3746963.html
}
//用逗号代替空白字符
String newData = data.replaceAll("\s+",",");
//输出
context.write(new Text(newData),NullWritable.get());
}
/**
* 在任务结束时,被调用一次。且只会被调用一次。
*/
protected void cleanup(Context context) throws IOException, InterruptedException {
super.cleanup(context);
}
}
App.java
package com.Zongheshiyan;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 数据清洗器 主类
*
*/
public class App
{
public static void main( String[] args ) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(App.class);
//指定map输出
job.setMapperClass(SogouMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//指定reduce的输出
job.setOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//指定输入、输出
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//提交job,等待结束
job.waitForCompletion(true);
}
}
·打包:

打包成功:

查看打包成功的jar包:

·运行jar包:
在运行jar包之前,确保开启了hadoop所有进程
start-all.sh

同时也把mr历史服务器进程打开:
mr-jobhistory-daemon.sh start historyserver

运行jar包:
hadoop jar hadoop_4_3-1.0-SNAPSHOT.jar /SogouQ.reduced /output_4_3

查看输出结果:
hdfs dfs -ls /output_4_3

查看输出文件最后10行数据:
hdfs dfs -tail /output_4_3/part-r-00000

4.创建hive表
进入hive命令行:
hive

创建hive表 :
create table sogoulog_1(accesstime string,useID string,keyword string,no1 int,clickid int,url string) row format delimited fields terminated by ',';

5.将MapReduce清洗后的数据导入Hive
load data inpath '/output_4_3/part-r-00000' into table sogoulog_1;

6.使用SQL查询满足条件的数据(只显示前10条)
select * from sogoulog_1 where no1=2 and clickid=1 limit 10;

【注】有余力的同学可以考虑做分析结果的可视化
【思考题】
【思考题1】对于Hve:什么是内部表?什么是托管表?什么是管理表?什么是外部表?这些概念有和区别和联系?
答:
内部表(托管表):在 Hive 中创建的表,数据和元数据都由 Hive 管理,存储在 Hive Warehouse Directory。删除表时,数据也会被删除。
外部表:在 Hive 中创建的表,数据存储在独立于 Hive 的位置上,可以是 HDFS、S3、HBase 等。删除表时,只删除元数据,不删除底层存储的数据。
托管表(管理表):是内部表的另一种称呼,数据和元数据都由 Hive 管理。
内部表和外部表的区别:内部表数据由 Hive 管理,删除表时数据也会被删除;外部表数据存储在独立位置,删除表时只删除元数据。
托管表和管理表的区别:指同一类型的表,由 Hive 管理和维护,数据和元数据都由 Hive 控制,这两个术语可以互换使用。
外部表与外部数据源的交互:外部表可与外部数据源交互,例如其他系统生成的数据文件。
管理表的操作:管理表可以通过 Hive 命令和操作进行数据的加载、插入、删除等操作。外部表的数据操作需要在底层存储系统上进行。
【思考题2】项目2中的loaddata操作后,数据和数据表被转移到那个目录下了?
答:
默认情况下,Hive Warehouse Directory的位置是在HDFS中的/user/hive/warehouse目录下。在该目录下,每个Hive表都有一个对应的子目录,其中包含表的数据文件和元数据信息。如果你在Hive中创建了一个名为"emp001"的表,并使用loaddata操作加载数据,则数据和数据表将被存储在Hive Warehouse Directory的相应位置,即/user/hive/warehouse/emp001目录下。

【思考题3】在最后一步操作中,我们对数据做了修改,为何再次查询数据却没有变化?
答:
`SELECT empno, ename, job, sal,
CASE job
WHEN 'PRESIDENT' THEN sal + 1000
WHEN 'MANAGER' THEN sal + 800
ELSE sal + 400
END AS new_salary
FROM emp001;
这个查询使用了 CASE 表达式来计算一个新的薪水字段,但并没有对表中的数据进行实际修改。查询语句只是根据已有的数据进行计算,并将计算结果作为新的字段返回。这种查询不会改变表中原来的内容。
【思考题4】 Hive在MysQL中存放的元数据有哪些,能否根据自己MysQL中真实存放的Hive元数据逐一举例说明
答: 元数据包括数据库中的表、列和索引,文件系统中的文件和目录,网络中的资源和连接,以及软件应用程序中的对象和配置等
下面是MySQL中的表:
查询某个表的内容


项目心得体会
1.mysql初始密码登录报错:
ERROR 1045 (28000): Access denied for user ‘root’@‘localhost’ (using
password: YES)
原因:这通常表示MySQL服务器拒绝了使用提供的密码登录 ‘root’ 用户。
解决方案:
重置root密码:如果你忘记了root用户的密码或者密码不正确,你可以尝试重置密码。可以按照以下步骤进行:
·停止MySQL服务器。你可以使用以下命令停止MySQL服务器:
sudo service mysql stop
·启动MySQL服务器并跳过权限检查。使用以下命令启动MySQL服务器:
sudo mysqld_safe --skip-grant-tables &
·连接到MySQL服务器。打开一个新的终端窗口,使用以下命令连接到MySQL服务器:
mysql -u root
·在MySQL命令行提示符下,执行以下命令来更改root用户的密码:
FLUSH PRIVILEGES;
ALTER USER 'root'@'localhost' IDENTIFIED BY 'new_password';
注意:将 ‘new_password’ 替换为你想要设置的新密码。
退出MySQL命令行:exit
停止MySQL服务器:在第一个终端窗口中运行以下命令:sudo service mysql stop
启动MySQL服务器:再次运行以下命令以正常启动MySQL服务器:sudo service mysql start
2.运行schematool -dbType mysql -initSchema时报错:
显示schematool:未找到命令
原因分析:可能是因为你没有将Hive的可执行文件路径添加到系统的环境变量中。请按照以下步骤检查和解决该问题:
·确保已经正确安装和配置了Apache Hive和MySQL数据库。
·打开命令行终端或命令行界面。
·输入以下命令,查看Hive可执行文件的路径:which hive
如果命令没有返回可执行文件的路径,说明系统无法找到Hive的可执行文件。在这种情况下,你需要将Hive可执行文件的路径添加到系统的环境变量中。
·打开你的shell配置文件,如~/.bashrc(对于Bash)或~/.zshrc(对于Zsh)或~/etc/profile(系统)
·在文件的末尾添加以下行(假设Hive的可执行文件路径为/path/to/hive/bin,请将其替换为实际路径):
export PATH=/path/to/hive/bin:$PATH
·保存并关闭配置文件。
·在终端中运行以下命令,使配置文件的更改生效:
source ~/.bashrc
·现在再次尝试运行schematool -dbType mysql -initSchema命令,应该能够正常执行。
3.运行schematool -dbType mysql -initSchema时报错:
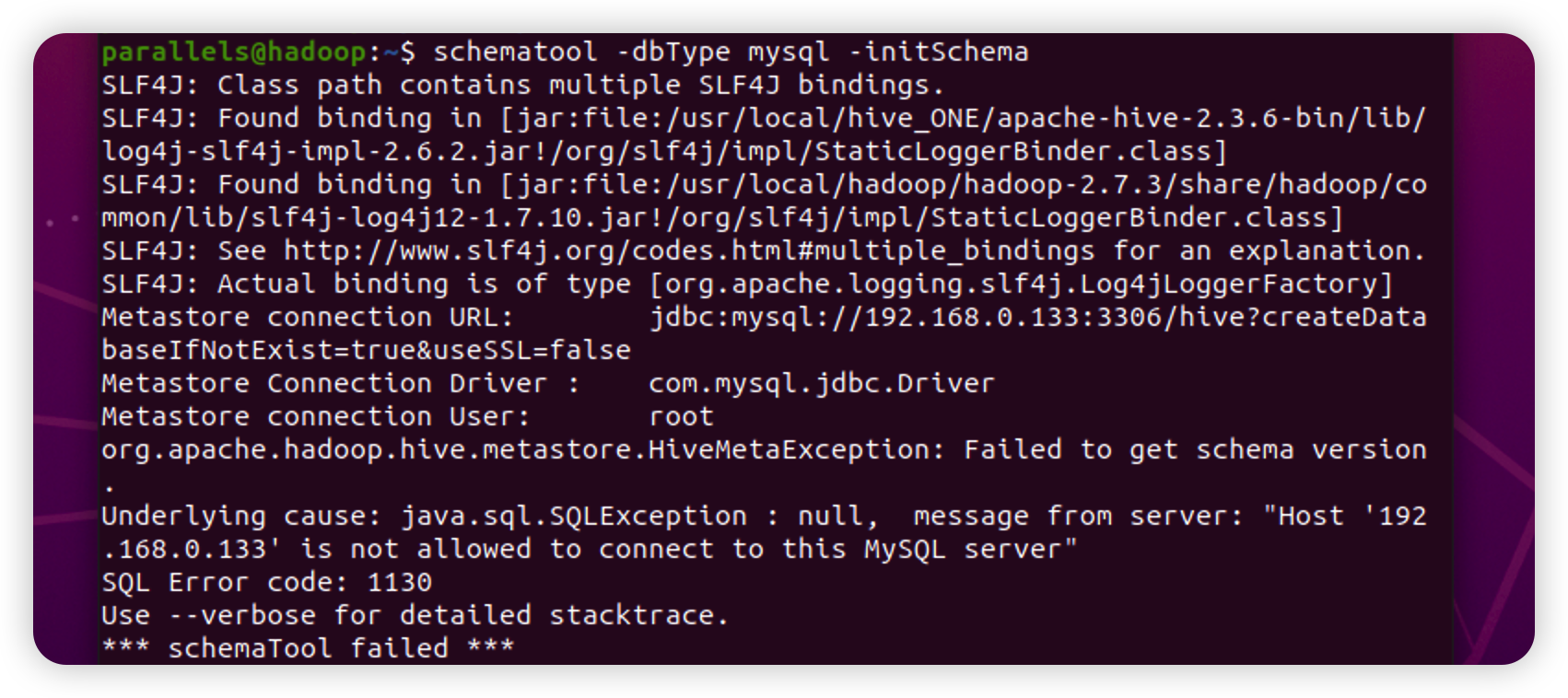
原因:是连接MySQL服务器时遇到了问题。错误消息指出,主机’192.168.0.133’不被允许连接到MySQL服务器,并且引发了"java.sql.SQLException"异常。
(1):主机访问权限问题
(2):连接参数错误:确认连接MySQL时使用的连接参数是正确的,包括URL、用户名和密码。请确保以下参数的正确性:
Metastore connection URL:
jdbc:mysql://192.168.0.133:3306/hive?createDatabaseIfNotExist=true&useSSL=false
Metastore Connection Driver: com.mysql.jdbc.Driver Metastore
connection User: root
解决方法:
·验证MySQL服务器配置:
登录到MySQL服务器,可以使用命令行工具如mysql,或者MySQL客户端工具。
确认MySQL服务器是否允许远程连接。执行以下查询语句:
SELECT host, user FROM mysql.user;
确保在结果中看到包含主机名和用户名的条目。
·检查MySQL服务器的访问控制列表(ACL)设置。执行以下查询语句:
SHOW GRANTS FOR 'root'@'192.168.0.133';
替换root和192.168.0.133为实际的用户名和主机名。确认结果中包含与连接相关的权限。
·如果没有允许连接的条目,可以执行以下命令添加访问权限:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'192.168.0.133' IDENTIFIED BY 'your_password' WITH GRANT OPTION;
替换root、192.168.0.133和your_password为实际的用户名、主机名和密码。
·确认连接参数:
确认连接MySQL时使用的连接参数是正确的,包括URL、用户名和密码。 Metastore connection
URL应该类似于:jdbc:mysql://192.168.0.133:3306/hive?createDatabaseIfNotExist=true&useSSL=false
Metastore Connection Driver应该是:com.mysql.jdbc.Driver Metastore
connection User应该是正确的用户名,例如:root 确认密码是正确的,并且具有适当的权限。
4.在3中执行代码GRANT ALL PRIVILEGES ON *.* TO 'root'@'192.168.0.133' IDENTIFIED BY 'your_password' WITH GRANT OPTION;报错:
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘OPTION;’ at line 1
mysql> GRANT ALL PRIVILEGES ON . TO ‘root’@‘192.168.0.133’ IDENTIFIED BY ‘your_password’ WITH GRANT OPTION;
Query OK, 0 rows affected, 1 warning (0.01 sec)
原因:在执行授权语句时出现了语法错误。错误信息提示你的MySQL服务器版本不支持使用WITH GRANT OPTION子句。在MySQL 8.0及以上版本中,不再支持使用WITH GRANT OPTION来授予GRANT权限。相反,可以使用GRANT OPTION来授予具有GRANT权限的用户。
解决方案:
·登录到MySQL服务器,并执行以下命令:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'192.168.0.133' IDENTIFIED BY 'your_password' WITH GRANT OPTION;
替换root、192.168.0.133和your_password为实际的用户名、主机名和密码。
· 如果MySQL服务器版本较低,不支持WITH GRANT OPTION子句,可以使用以下命令:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'192.168.0.133' IDENTIFIED BY 'your_password';
·然后,执行以下命令来刷新权限:
FLUSH PRIVILEGES;
至此在Linux中运行:
schematool -dbType mysql -initSchema
就成功啦!!






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结