您现在的位置是:首页 >学无止境 >目标检测复盘 -- 5. YOLO v1-v3网站首页学无止境
目标检测复盘 -- 5. YOLO v1-v3
YOLO v1
论文思想
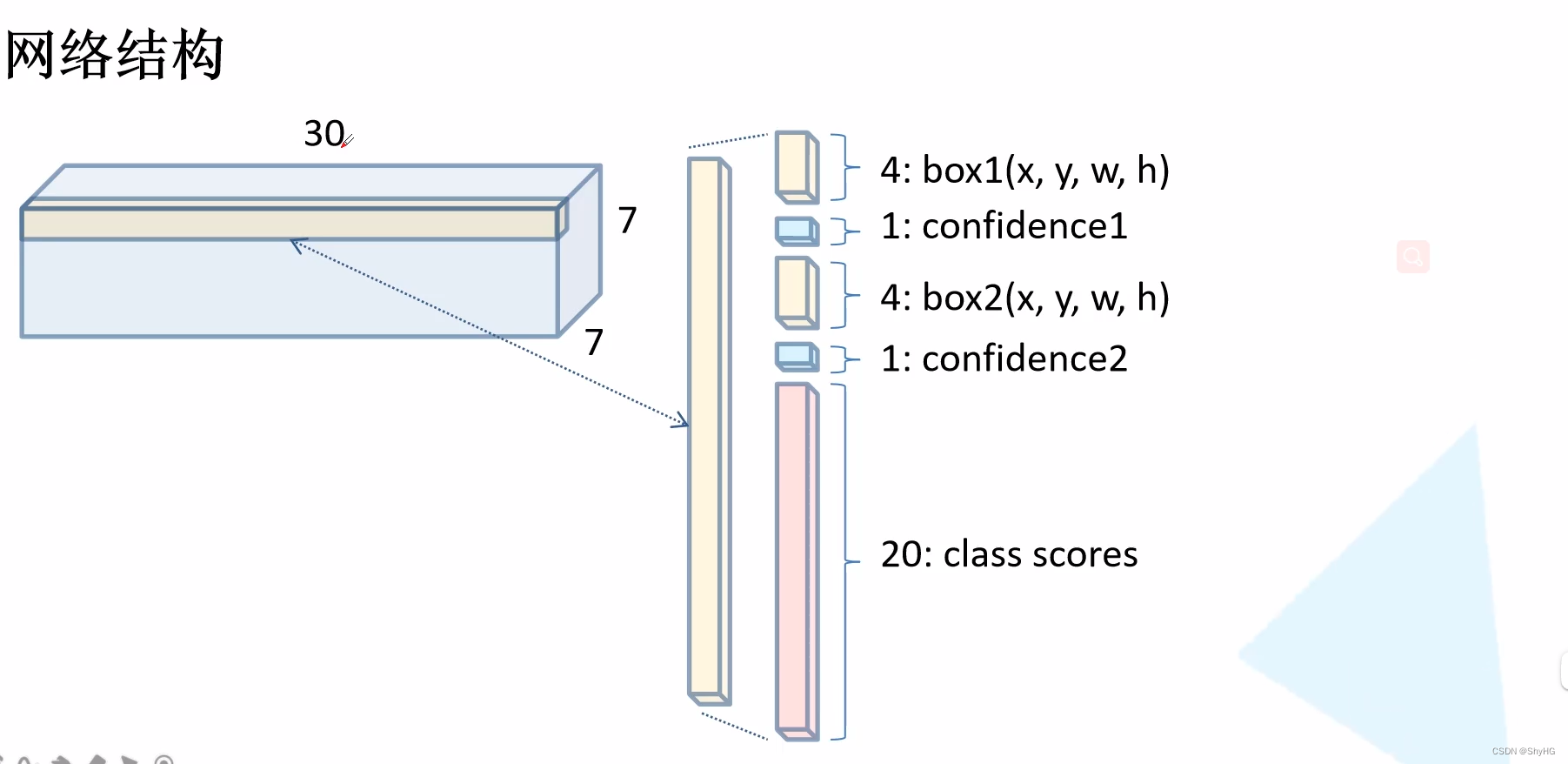
应该怎么理解呢?其实相比较于RCNN系列,YOLO系列没有RPN这种模块了,而是直接输出或者叫做直接回归出来结果,最终的输出是一个特征图,大小为7 * 7 * [ (4+1) * 2 + 20],这个尺寸又怎么理解呢?7*7是特征图大小,4是bounding box的x,y,w,h,1是confidence,*2的意思是每个pixel地方预测两个bounding box,最后的20代表20个类别得分(如下方网络结构那张图所示)
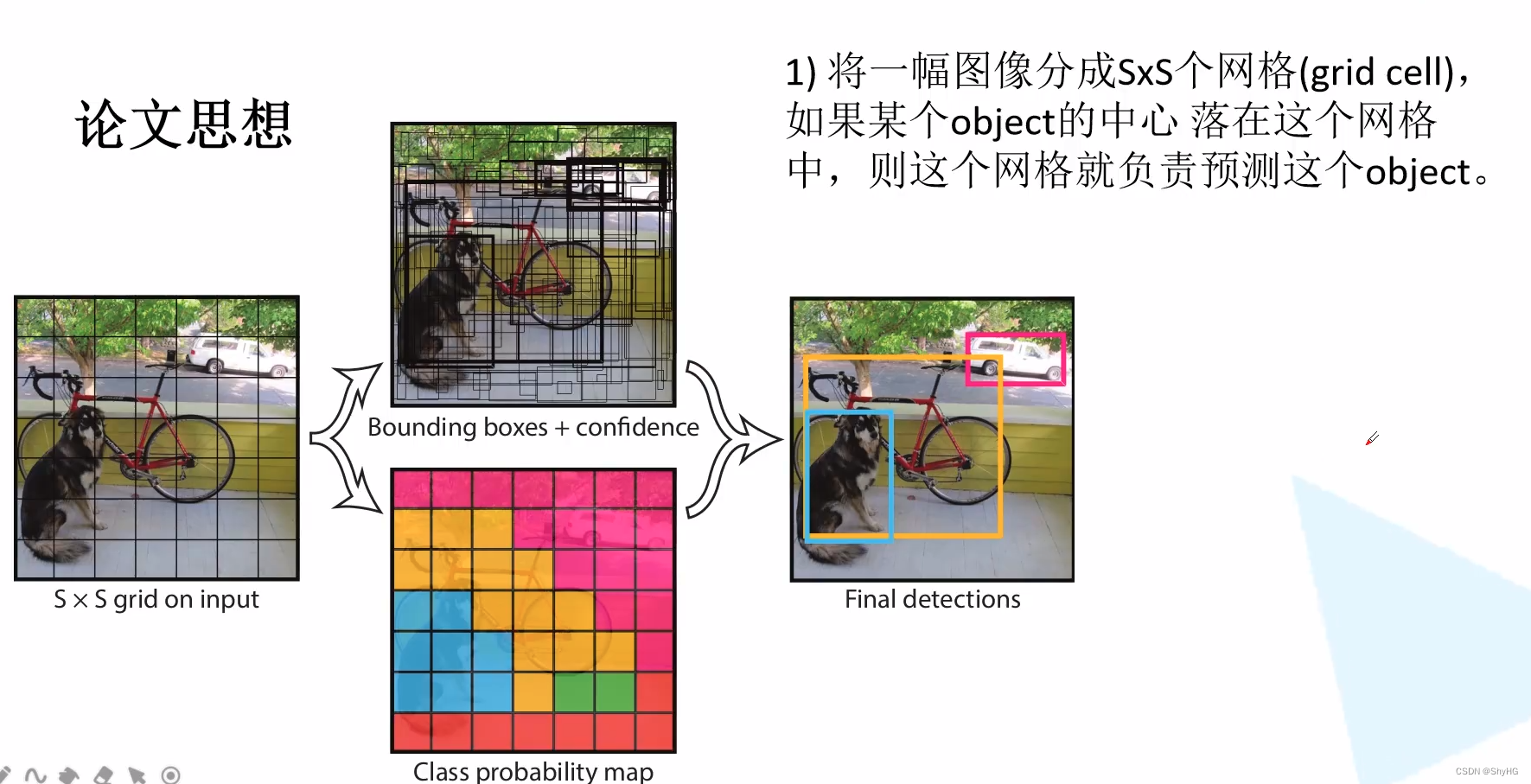
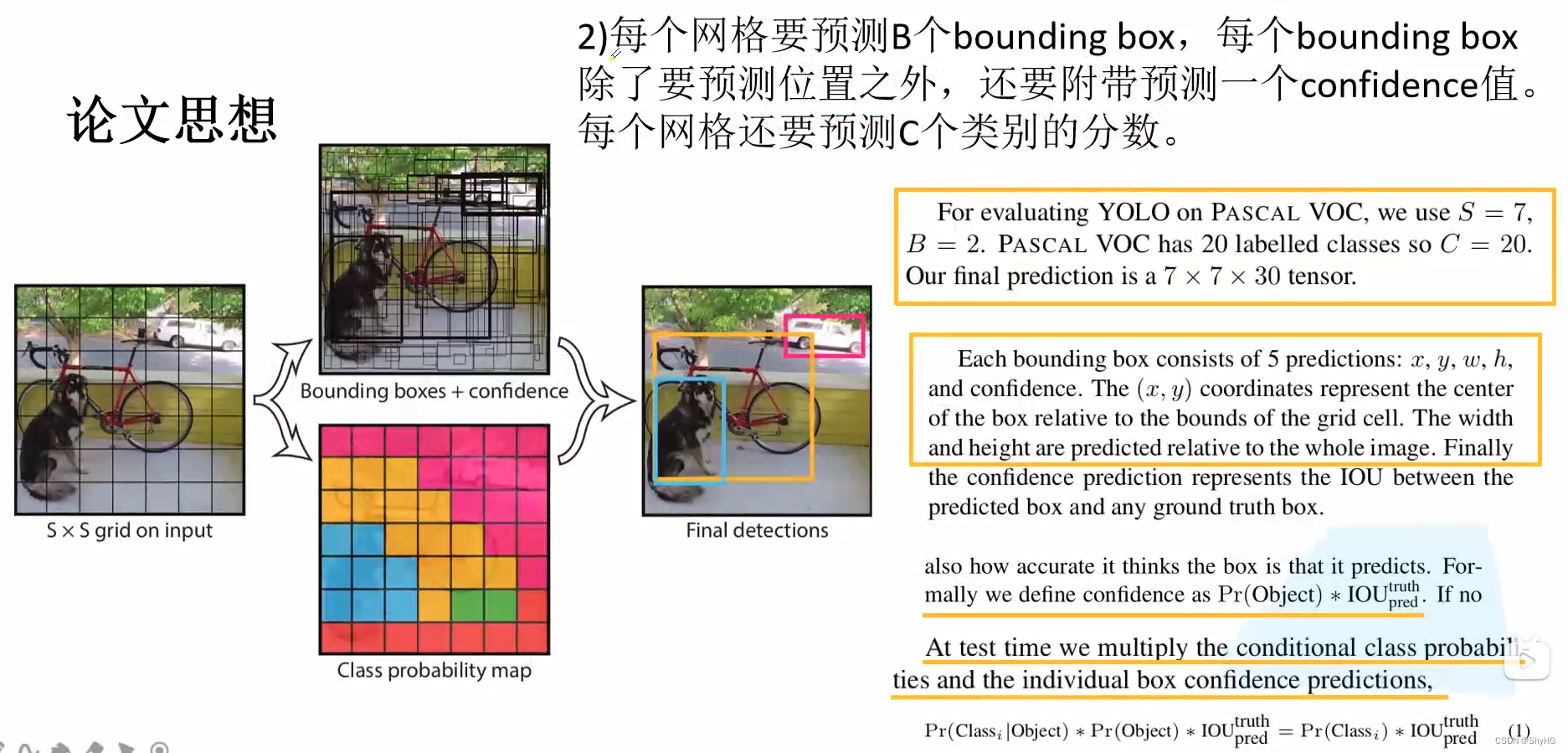
注意点
预测的xy值是限定在负责预测pixel的框的中间,是一个相对坐标,宽高也是一个相对值,相对整个图像而言,xywh都是0到1之间的一个数值,confidence在训练的时候值为 P r ( O b j e c t ) ∗ I O U p r e d t r u t h Pr(Object)* IOU_{pred} ^{truth} Pr(Object)∗IOUpredtruth,Pr那一项如果有目标则为1,没有目标则为0。
这里的网络输出的直接是bounding box的位置,YOLOv1是没有anchor概念的,不想Faster RCNN或者SSD最终的结果是对anchor的微调,这里直接的输出就是bounding box
网络结构

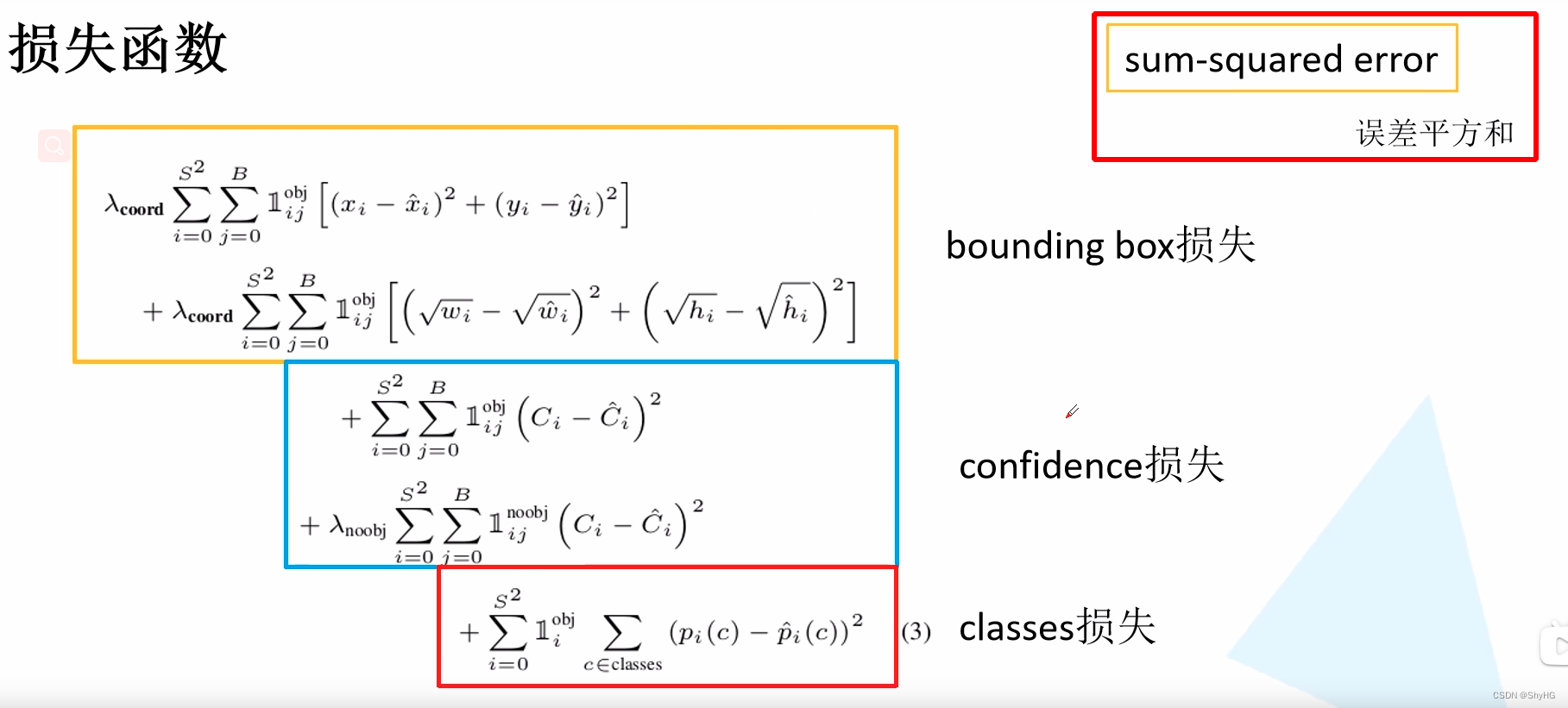
损失函数
损失函数,注意这里主要采用误差平方和作为loss,为了让小目标更敏感,这里对数据进行了开方,这样小目标更敏感,大目标相对没那么敏感
YOLOv1存在的问题:
- 对群体性的小目标检测效果比较差(因为每个cell有两个bounding box,且属于同一个类别,最后选择confidence高的留下来)
- 对于训练集没有出现过的目标的长宽比效果比较差(没有anchor的原因,直接回归有更大
的定位误差)

YOLO v2
YOLOv2进行了很多尝试,最终的效果相比YOLOv1也提升了很多
Better部分
- BN,能够加速模型收敛,也起到了正则化的作用,所以可以移除掉dropout方法
- 高分辨率,YOLOv1使用了224*224,v2使用了448*448的图片,使用大分辨率能够提升约4个点
- 使用基于achors的方法,v1由于定位偏差比较大,所以最终bounding box效果不好,再者,使用anchor也更容易收敛,主要是提高了模型的召回率(查全率)
- 使用kmeans方法生成priors,就是Faster RCNN中的anchor、SSD中的default box,带来了约5个点的提升

- 在Faster RCNN中的位置求解如下,坐着发现,在训练的早起,模型不是非常稳定,原因是生成的xy可以在图像中的任意位置,所以在YOLOv2中,对求解公式进行调整,最终结果是将预测的偏移量
t
x
t_x
tx限定在0到1之间,也就是限定在那个pixel上
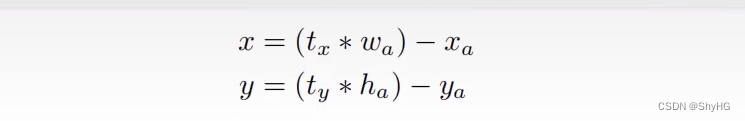
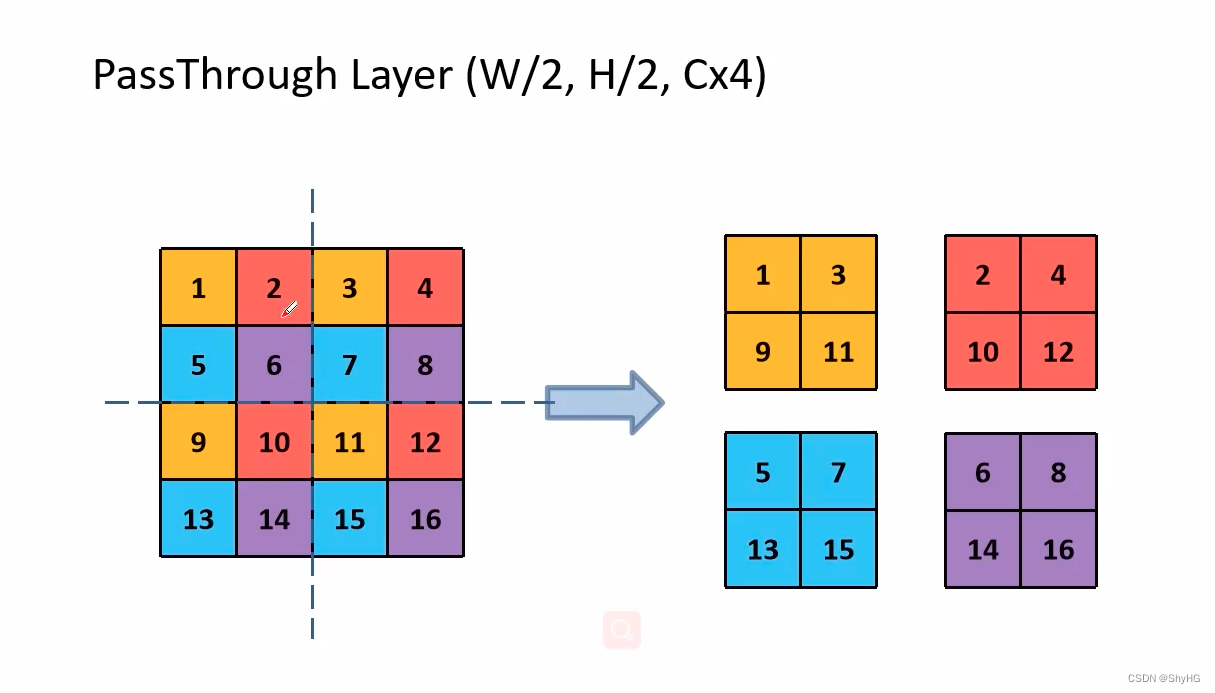
- 更精细的特征,最终的feature map的大小是13*13,YOLOv2将13*13和之前的26*26分辨率的特征图进行了融合(simply adding a passthrough layer,使用concat的方式),这样对小目标更友好,使用的paathrough方法如下,这个方法在很多模型中都很常见(YOLOv5的slice模块)
- 多尺度训练,每迭代10个batch,尺寸就变换一次,也可以提升模型的鲁棒性
Faster部分
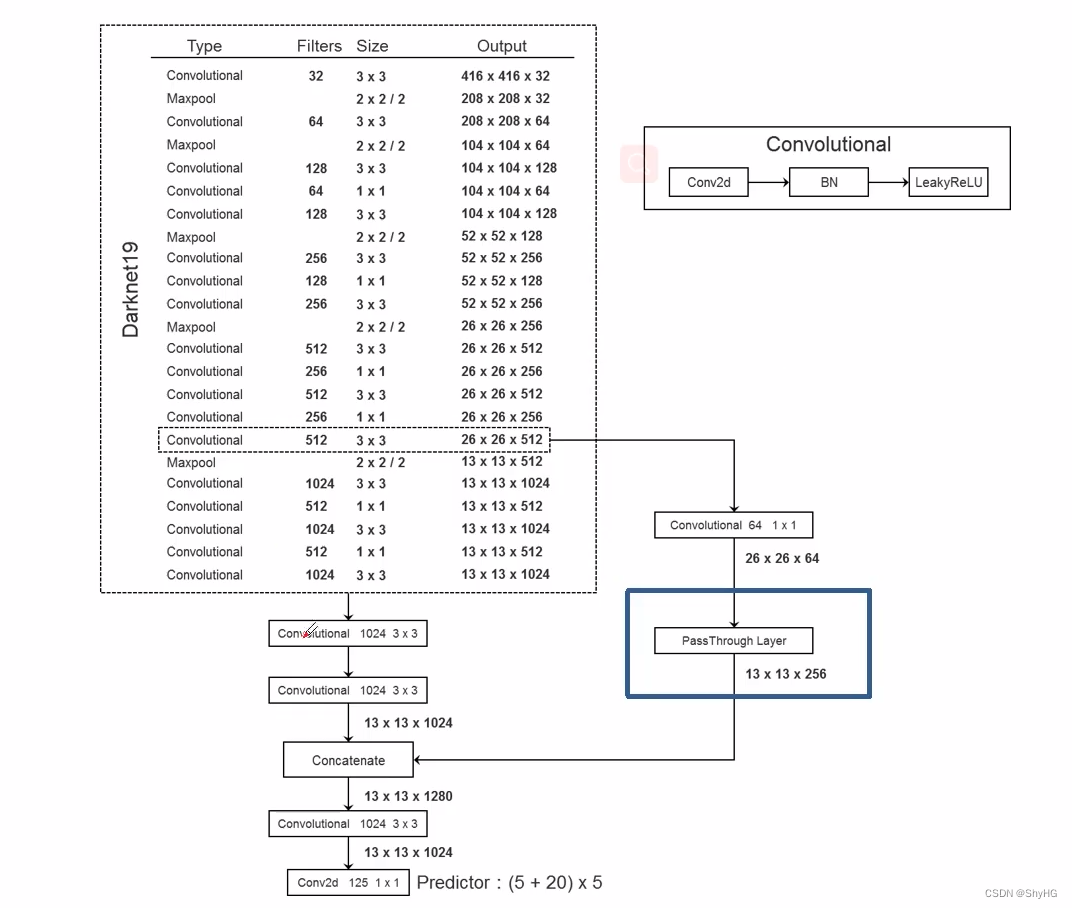
YOLOv2使用darknet19作为骨干网络,包含19个卷积层,最终结构如下:
(注意,如果使用BN,那么卷积中的bias就不起任何作用)
模型最终输出为(4+1+20)* 5,5个bounding box,每个bounding box有4个尺寸参数和一个confidence再加上20个类,
至于正负样本以及损失函数,和YOLOV1一样,并没有做出改变
YOLO v3
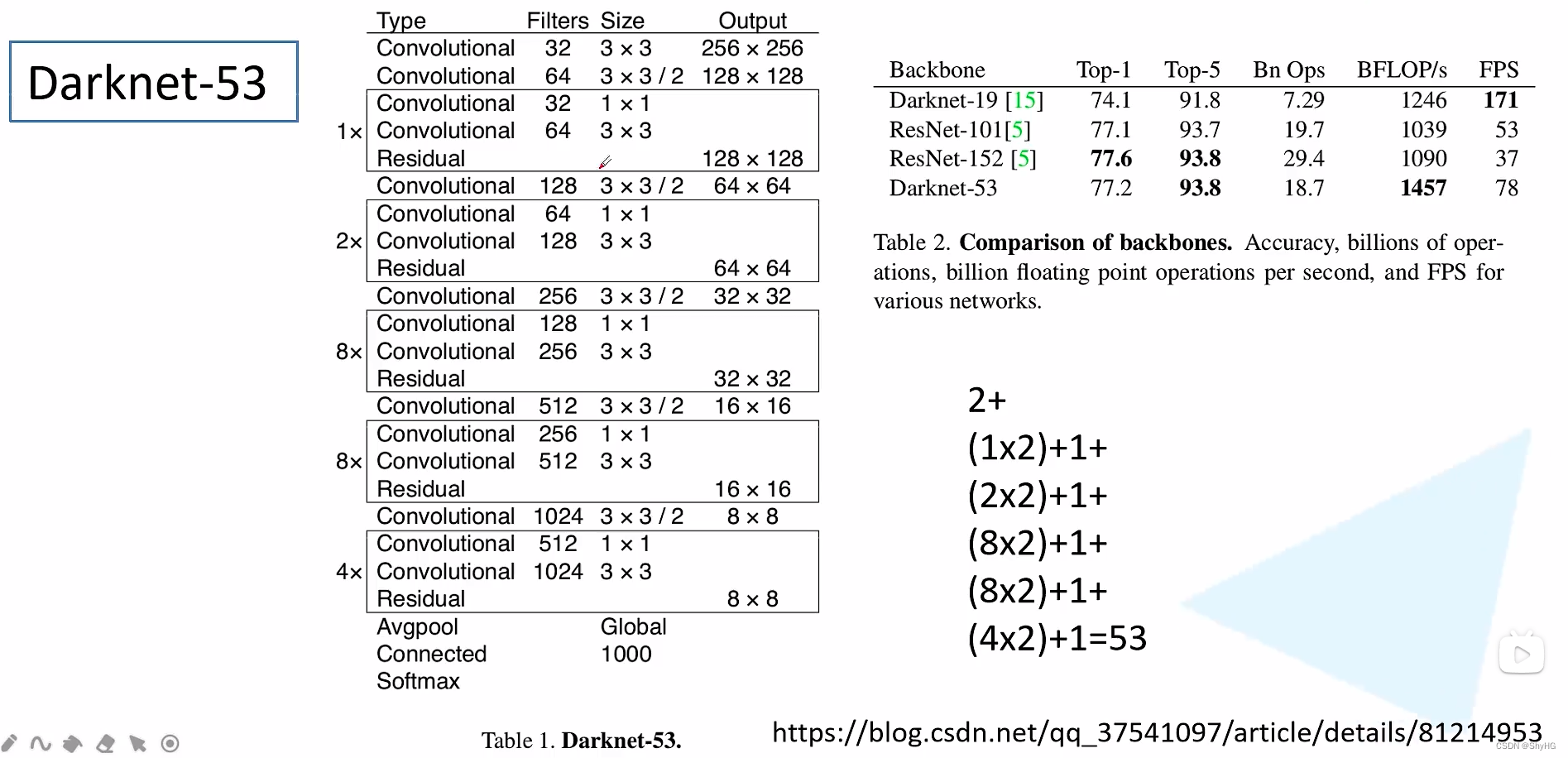
YOLO v3使用Darknet53作为backbone,结构如下:
图中发现,darknet53和resnet152相比,accuracy基本一致,但是速度翻倍,这里darknet53是没有最大池化层的,下采样是采用卷积的方式来进行的,darknet53卷积参数更少,所以更快
YOLO v3的head,输出有3个head,三个尺度的预测
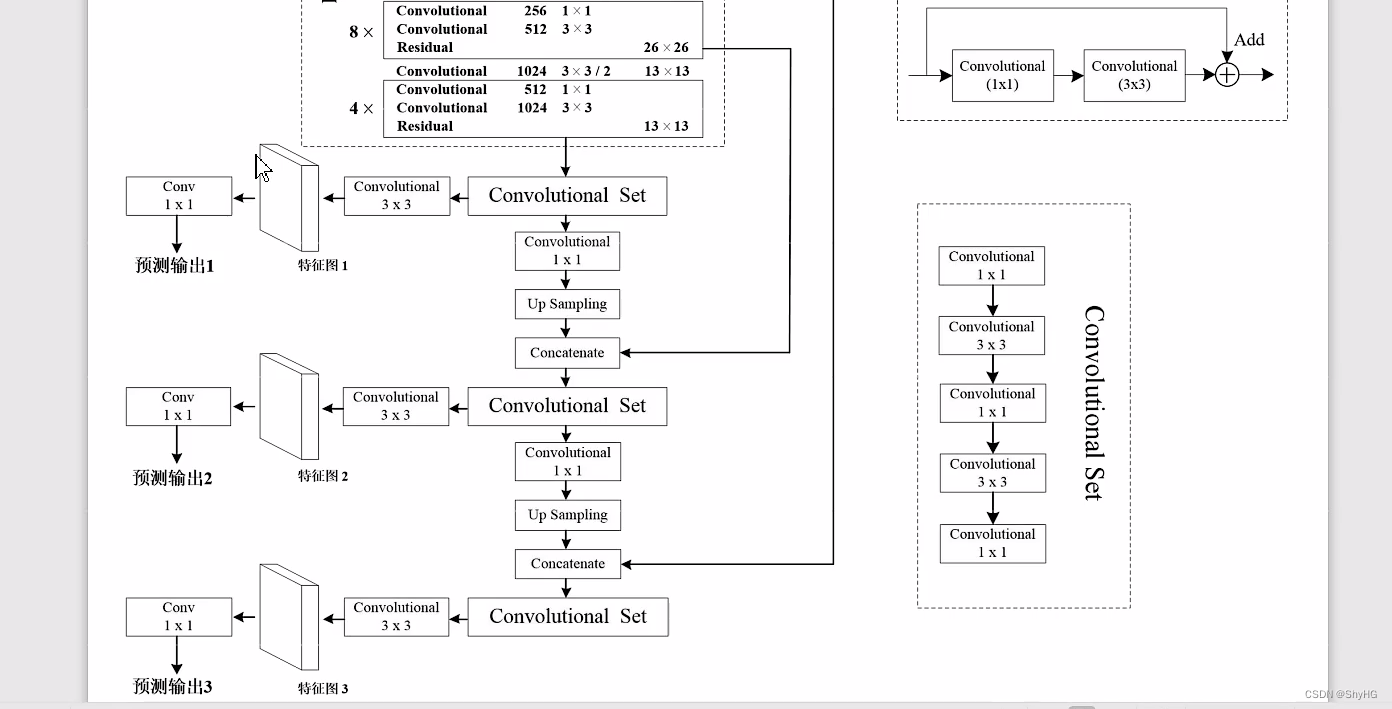
注意,这里边界框的预测和v2一样,是相对于网格的左上角坐标,而在FasterRCNN和SSD中,是相对于anchor中心点的偏移

样本匹配
一个GT分配一个正样本,对于那些大于一定阈值且不是最好的样本选择忽略。如果一个样本没有分配给GT的话,那么不计算样本的定位损失和类别损失,只计算objectness,也就是confidence的计算

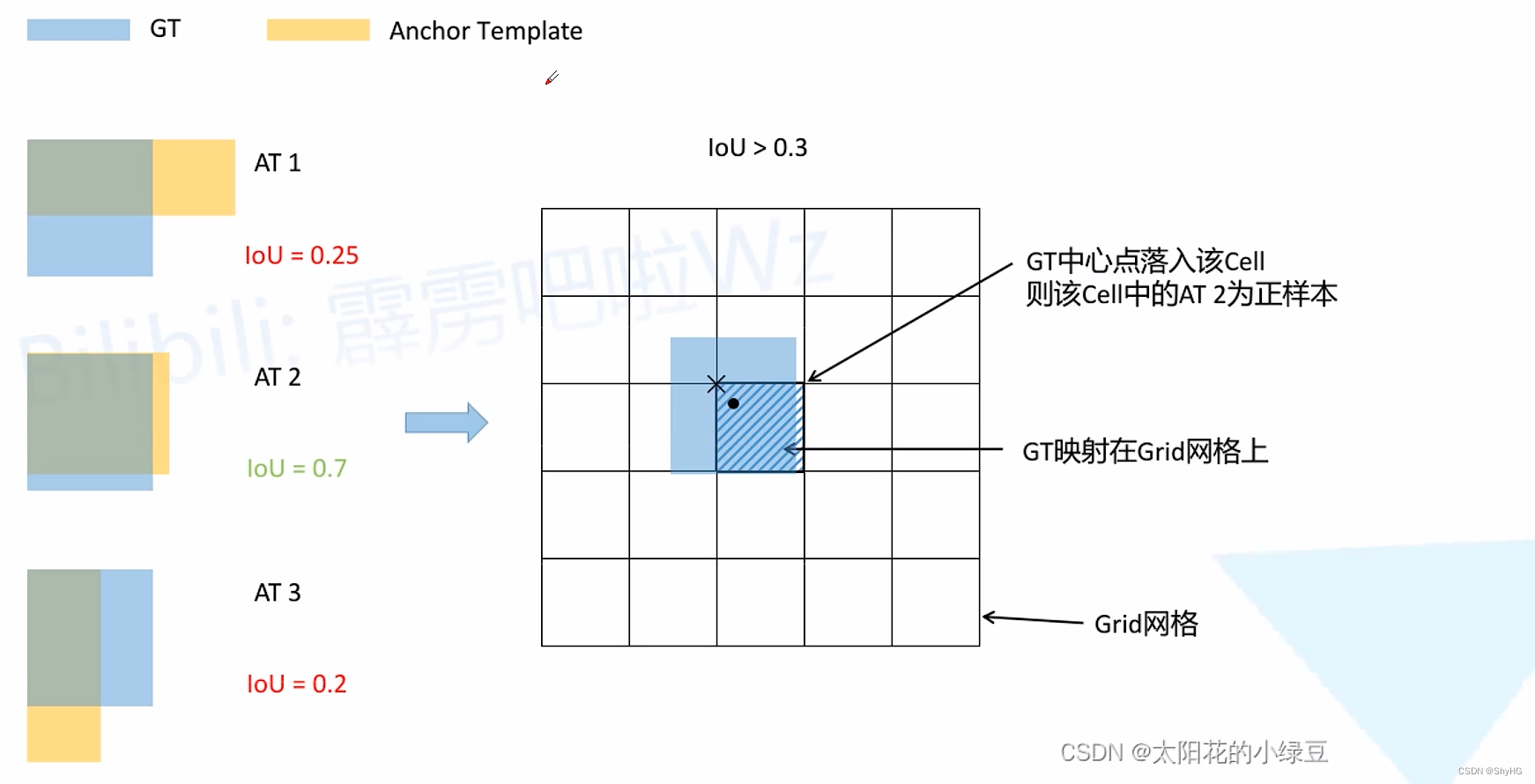
但是上面这种方法只有很少的样本参与到计算,不利于模型收敛,在u版的实现中,样本匹配策略如下:
有多个模板,当模板和gt的IOU大于某一阈值,则被认为是正样本,如果多个模板都满足要求,则将gt分配给多个anchor作正样本输入
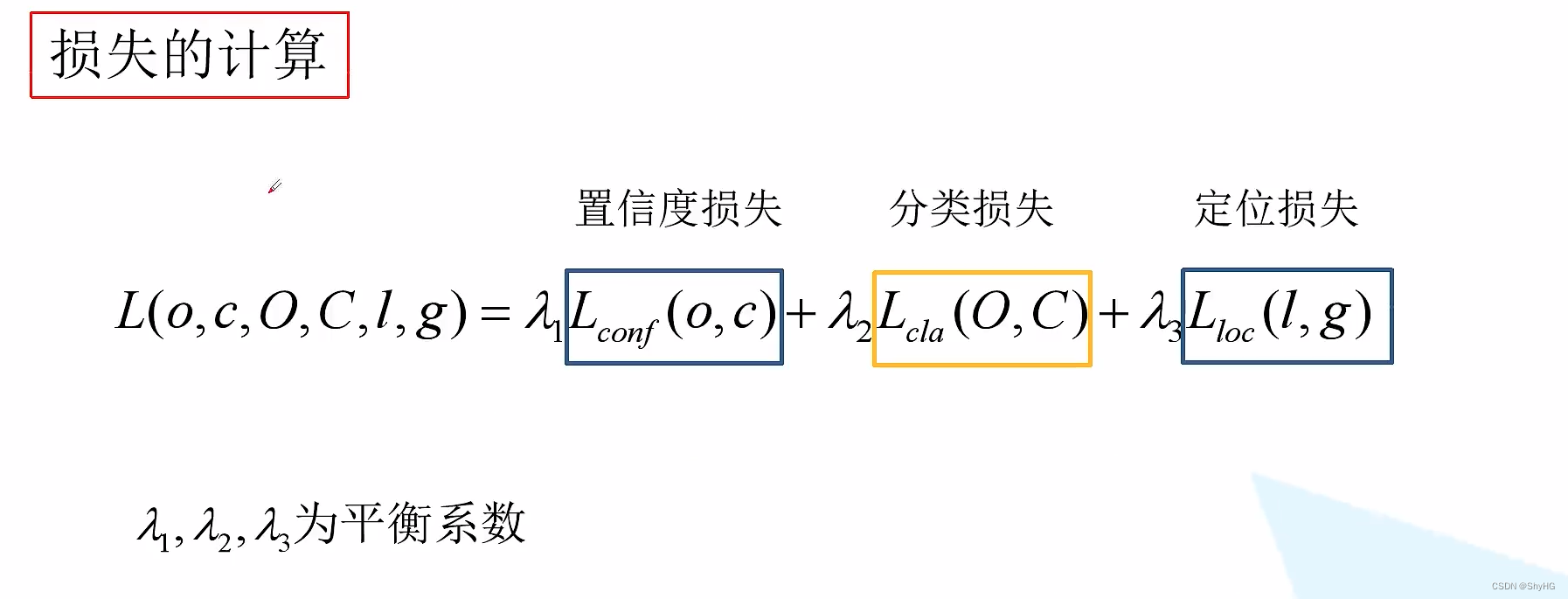
损失计算
三部分组成
置信度损失
逻辑回归使用二值交叉熵损失,

类别损失
也是二值交叉熵

类别损失的理解 ,注意图中的类别之和不为1,因为是binaray cross entropy,而不是sotmax cross entropy,所以和不为1

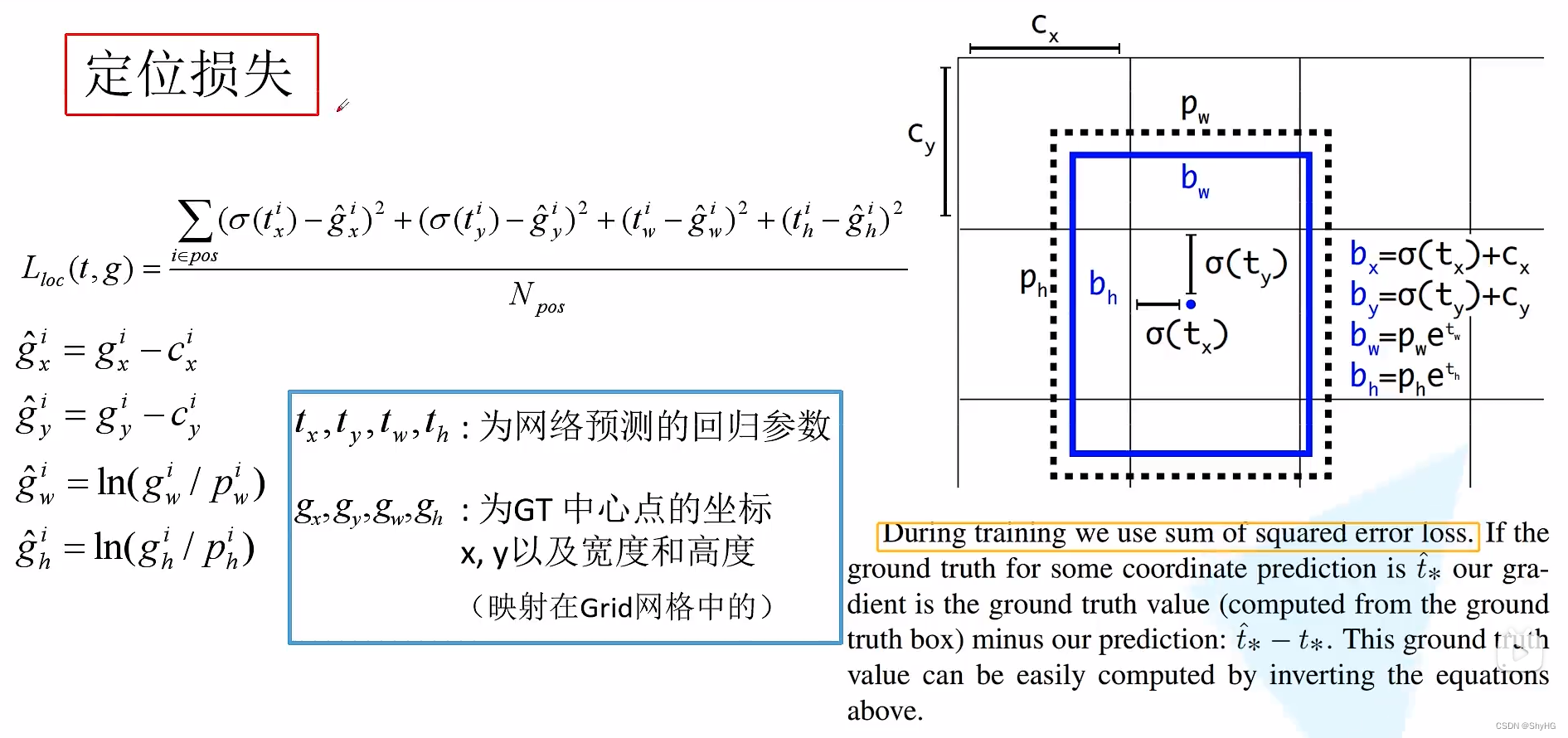
定位损失
需要经过转换,然后使用平方和作为loss,注意这里要把gt值转换成和预测值一样的量来进行loss计算,而不是直接使用xywh






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结