您现在的位置是:首页 >技术教程 >AutoEncoder & GAN网站首页技术教程
AutoEncoder & GAN
简介AutoEncoder & GAN
AE
Auto-Encoder (AE) 是20世纪80年代晚期提出的,它是一种无监督学习算法,使用了反向传播算法,让目标值等于输入值。
- 是神经网络的一种,经过训练后能尝试将输入复制到输出。
- 三层网络结构:
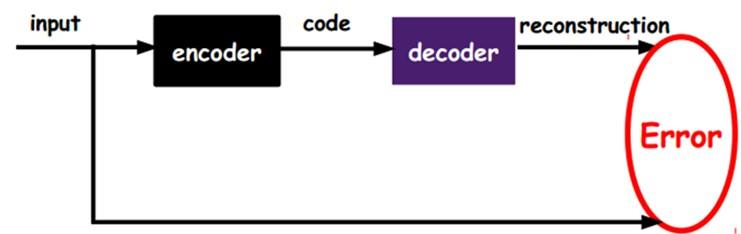
输入- 隐层- 输出 - 自编码网络的作用是:将输入样本压缩到隐藏层,再在输出端重建样本。其目标是使输出和输入之间尽量的小,即重构误差尽可能的小
- 自动编码器必须捕捉可以代表输入数据的最重要的因素;类似 PCA,找到可以代表原信息的主要成分。

欠完备 under-complete
从自编码器获得有用特征的一种方法是限制 h 的维度比 x 小,这种编码维度小于输入维度的自编码,称为:欠完备自编码器。
- 学习欠完备的表示将强制自编码器捕捉训练数据中最显著的特征
- 当解码器是线性的且Loss是均方误差,欠完备的自编码器会学习出与 PCA 相同的生成子空间。
过完备 over-complete

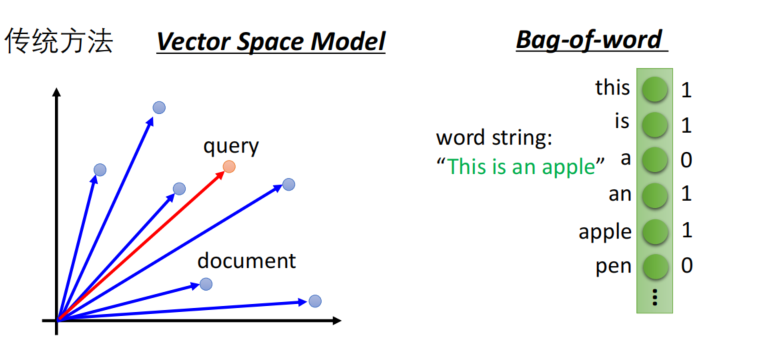
- 文本表示
- 传统是VSM向量空间,bag-of-words词袋模型,无语义信息
- Auto-encoder : 可以学习到语义特征
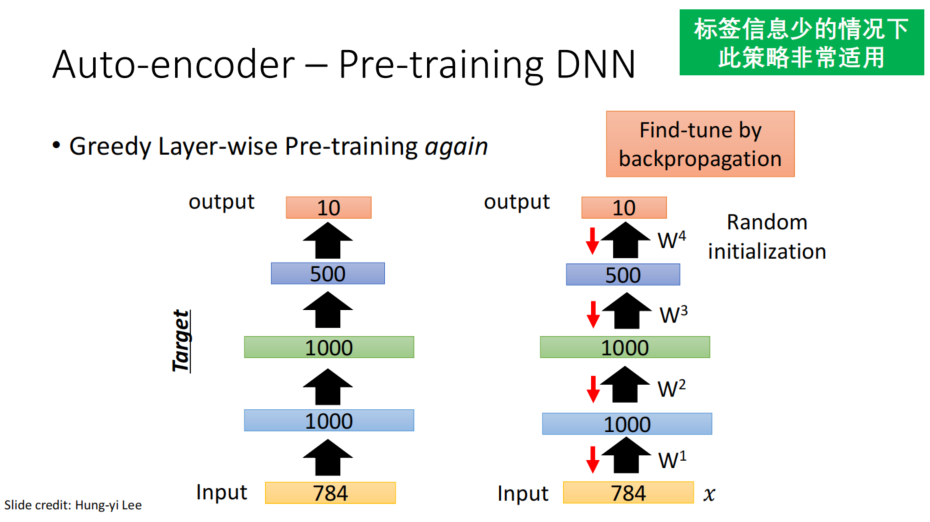
- 逐层预训练
CNN-AE
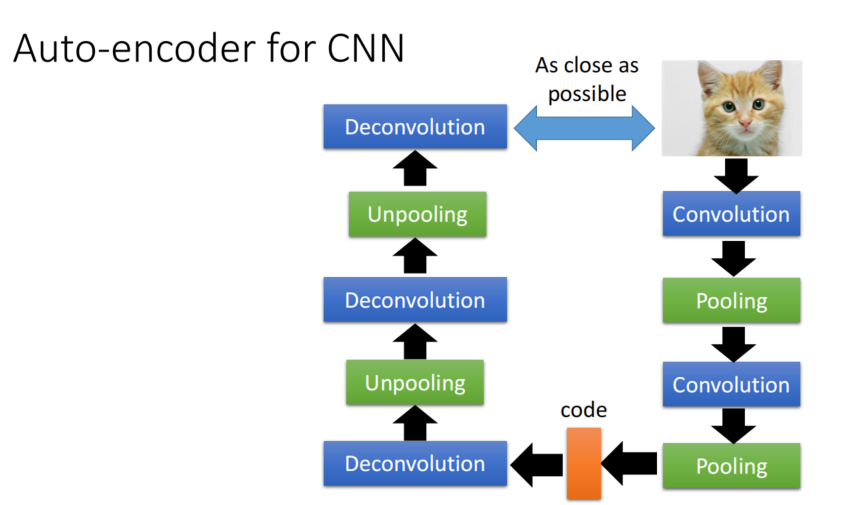
反卷积:
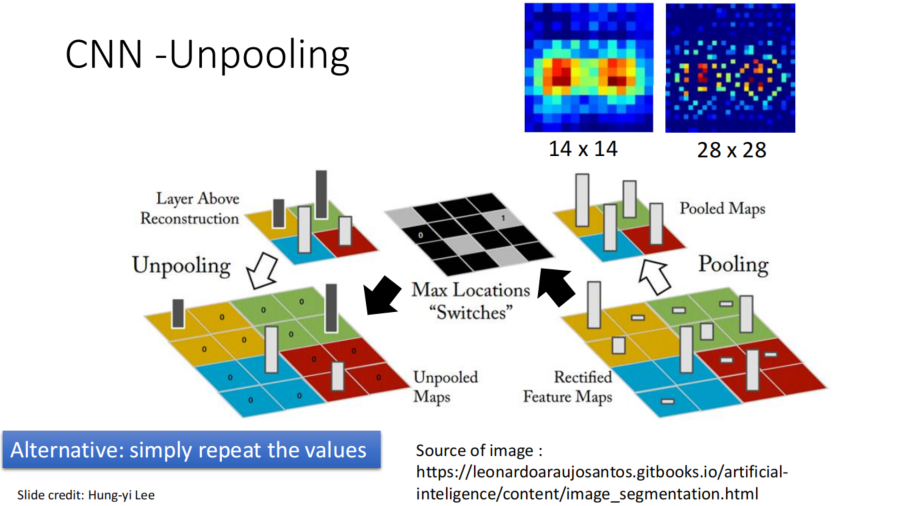
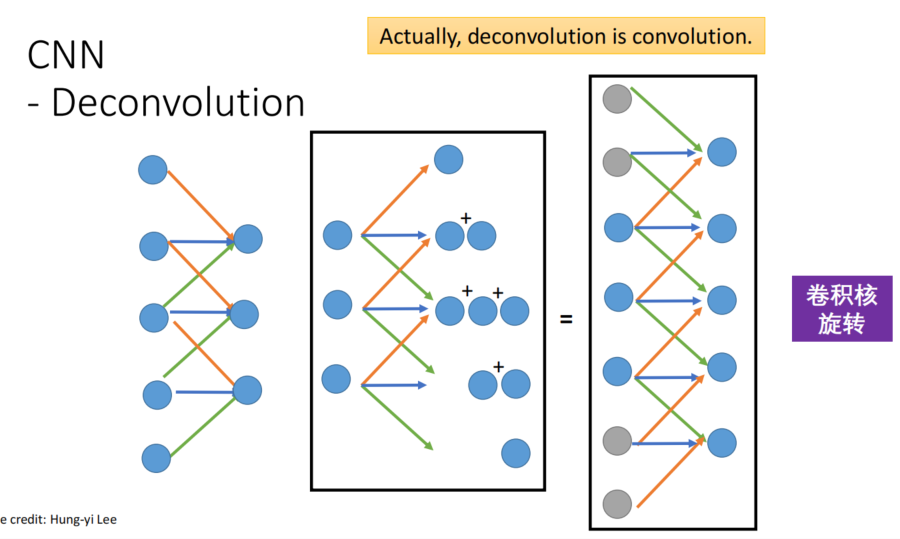
稀疏自编码
-
如果在AutoEncoder的基础上加上L1的约束,可以得到Sparse AutoEncoder
- L1约束主要是约束每一层中的节点中大部分都要为0,只有少数不为0,这就是Sparse名字的来源
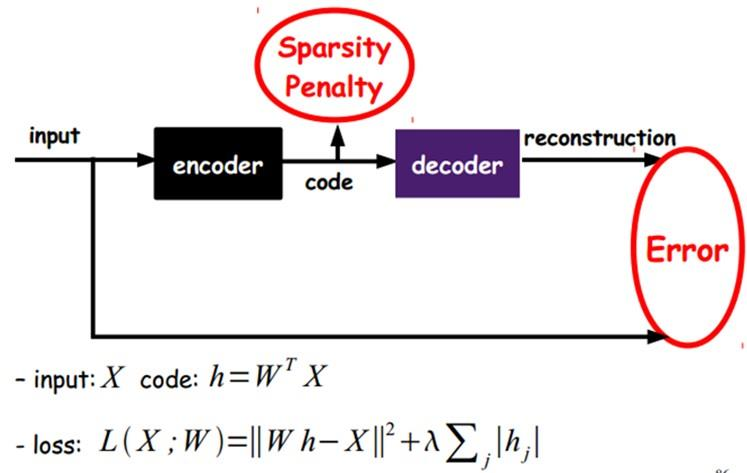
- L1约束主要是约束每一层中的节点中大部分都要为0,只有少数不为0,这就是Sparse名字的来源
-
核心思想:将隐层进行约束,使其变得稀疏
-
通过一个稀疏参数对输入到隐层的样本进行激励(筛选)

-
添加一个额外的惩罚项来最优化目标函数
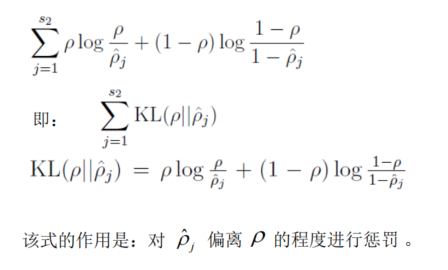

DAE
- 从破损数据中恢复干净的数据
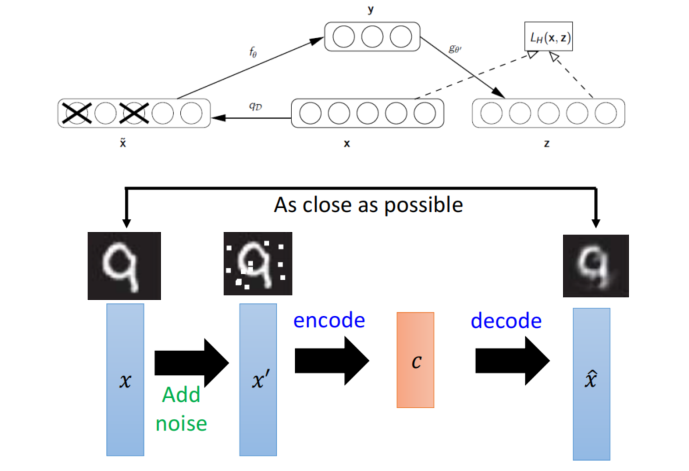
CAE
好的特征表示大致有2个衡量标准:
- 可以很好的重构出输入数据;
- 对输入数据一定程度下的扰动具有不变性。
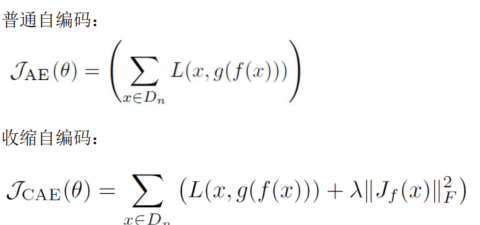
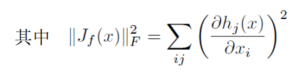
收缩自编码器学习的两种推动力:
- 收缩惩罚想要使学习到的特征在所有方向上不变(对所有方向都有收缩作用),
- 重构误差则想要能将学习到的特征重构回输入。
学习的过程中,重构误差的推动力使数据中的变化方向(即流形切平面的方向)能够抵抗收缩
作用,体现在其对应的 Jacobian 矩阵中的奇异值很大;
而抵抗不了收缩作用的方向则对应于数据中不变的方向(正交于流形的方向),
其在 Jacobian 矩阵中的梯度则会变得很小。
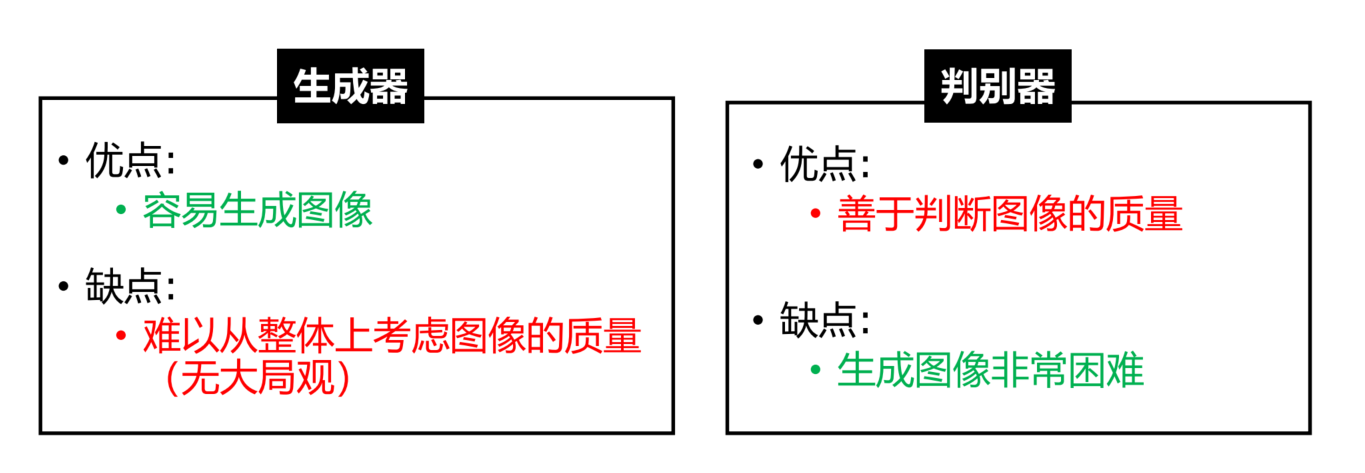
GAN
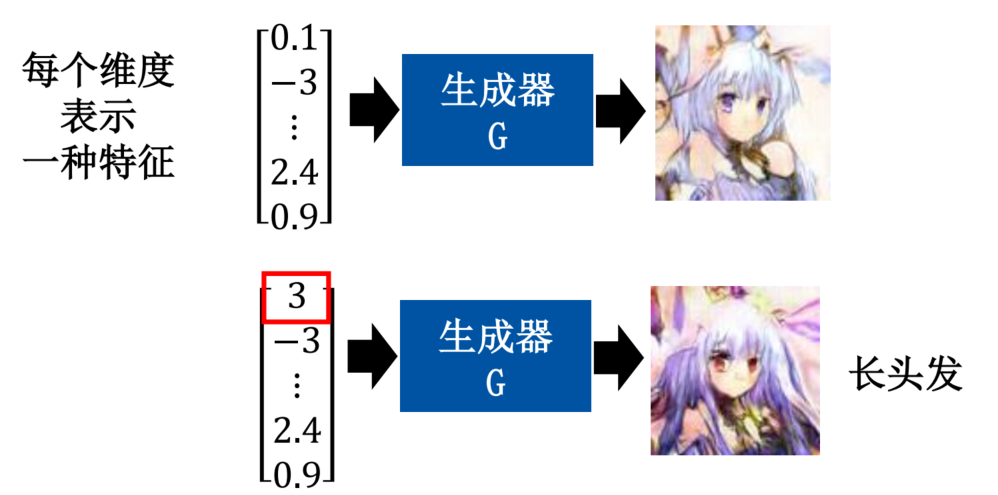
- 但是你不知道哪一个维度代表着什么

-
固定生成器G,更新判别器D
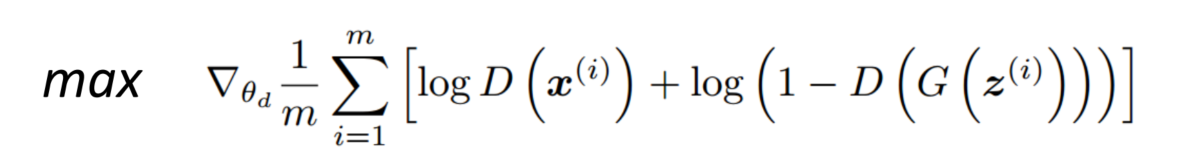
-
更新生成器G,固定判别器D
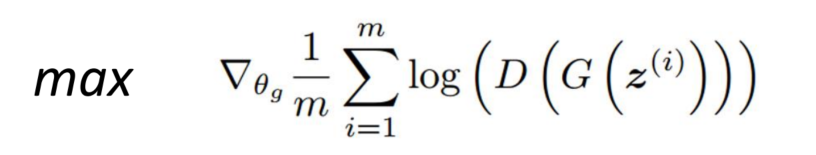
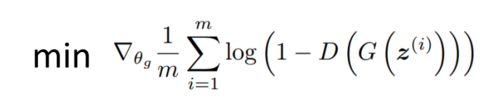
损失函数:
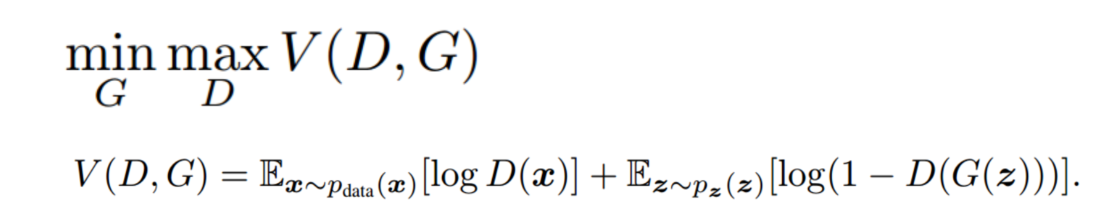
- 核心思想:生成的期望分布近似于真实分布
JS散度:

- JS散度存在问题
- 计算难度复杂度高,难以收敛
- 散度受数据分布影响较大
- 对维度敏感
- 散度不具有可加性
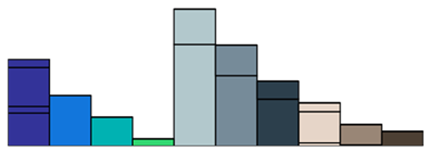
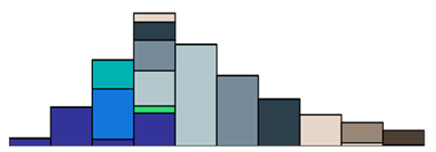
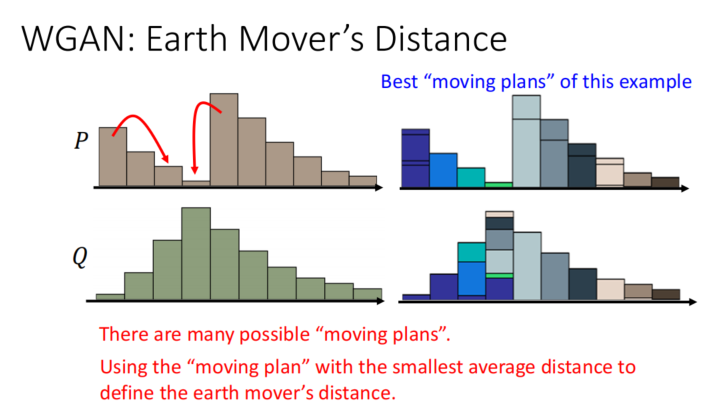
推土机距离
- 抽象乘土块,从初始分布到目标分布的最佳方案
Conditional GAN
Text → o → Image
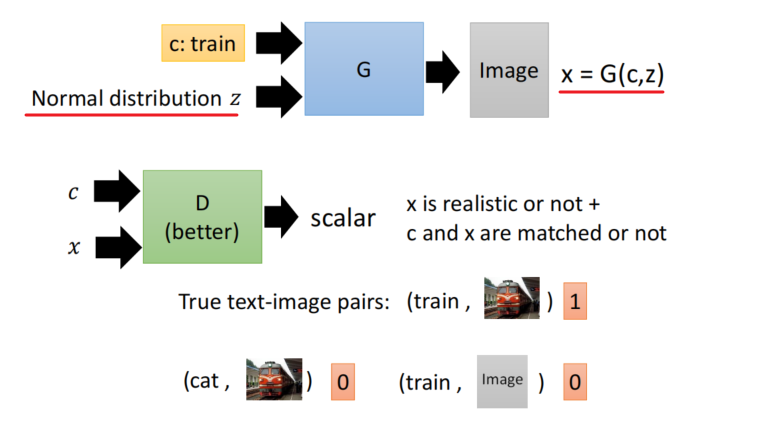
- Discriminator
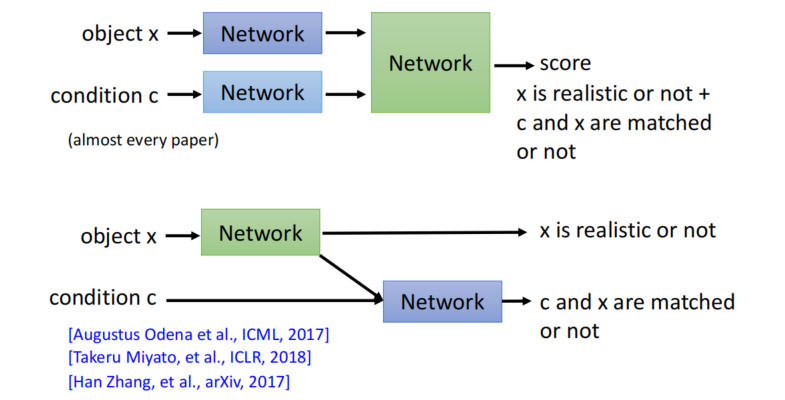
Image → o → Image
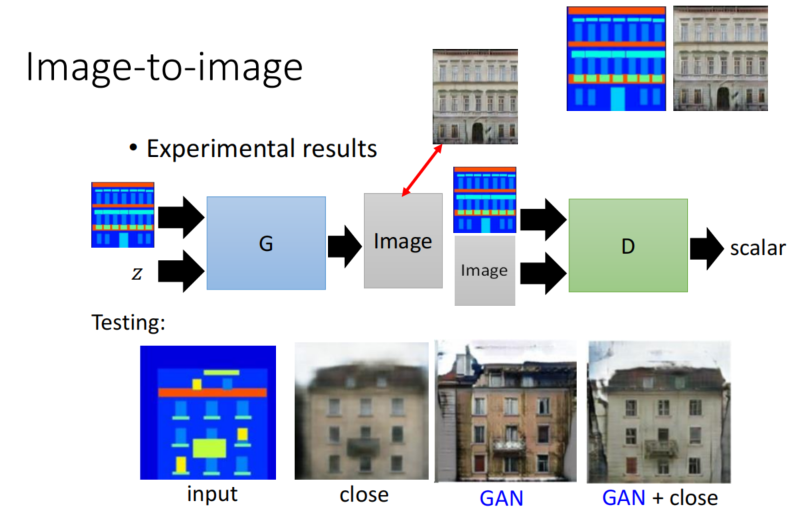
Unsupervised Conditional Generation
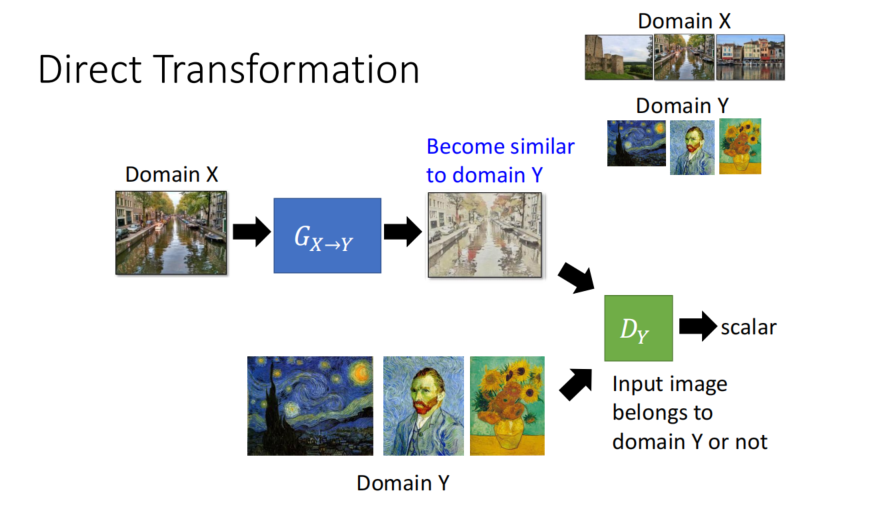
Approach 1: Direct Transformation
-
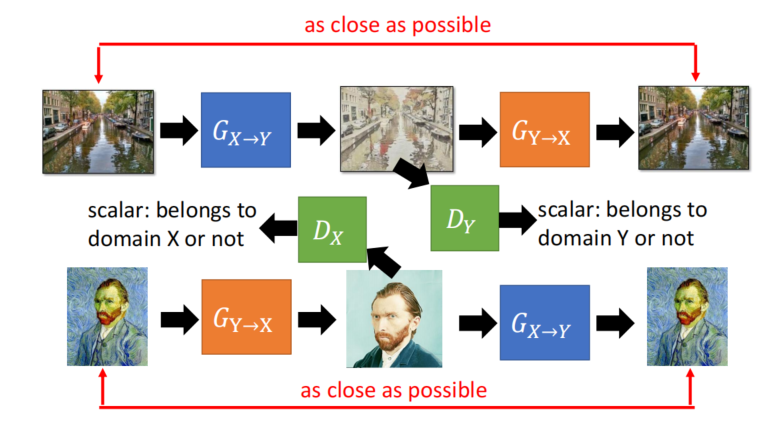
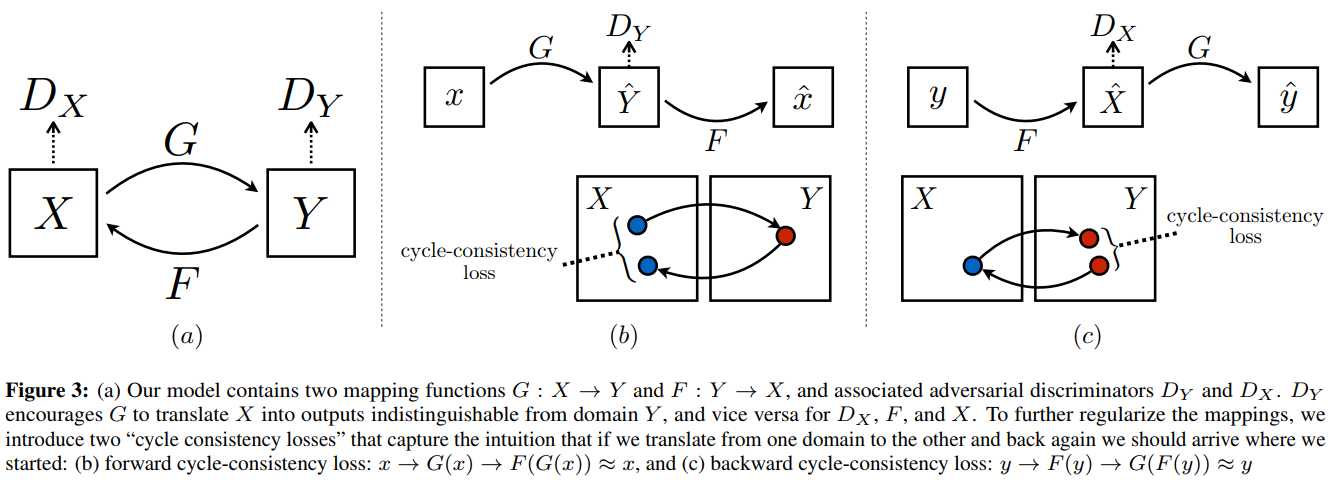
Circle GAN
-
A领域的图1变成B领域的图2,通过判别器看,像不像B领域的图
-
为了确保图2和图1的内容是一致的,把图2变回A领域,看它想不想图1
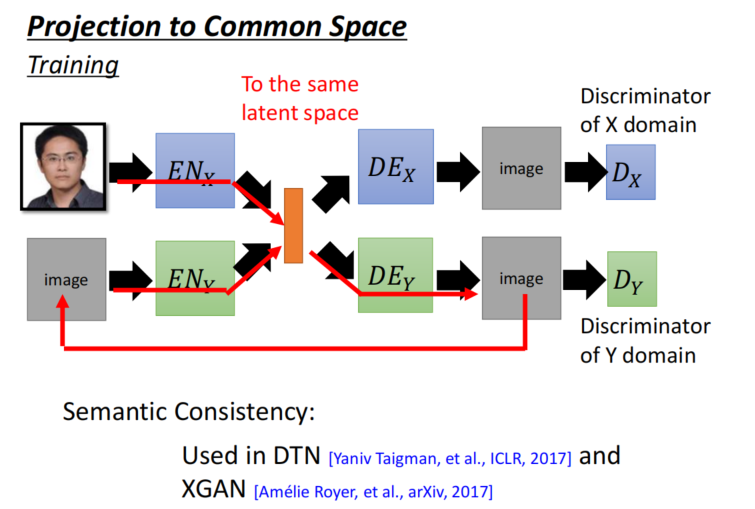
Approach 2: Projection to Common Space

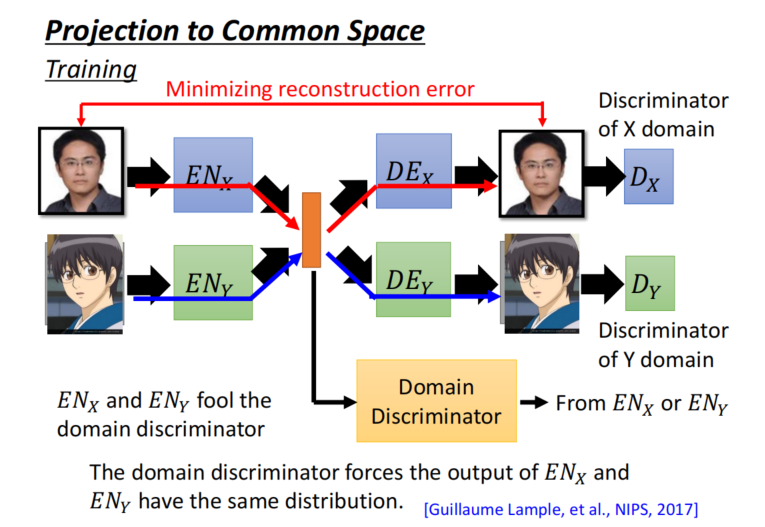
- Another Ideas : To the same latent space
循环一致性:
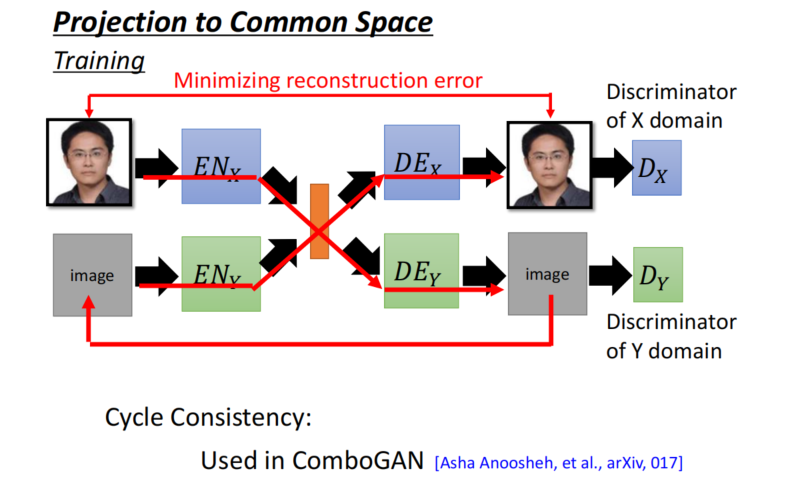
语义一致性:
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结