您现在的位置是:首页 >技术教程 >【大数据hive】hive视图与物化视图使用详解网站首页技术教程
【大数据hive】hive视图与物化视图使用详解
目录
一、hive中的视图
使用过mysql视图的同学对视图的概念应该不陌生,视图就是一种虚拟表,可以临时存储查询的数据,hive中也提供了视图,hive中的视图具有下面的特点:
- Hive中的视图(view)是一种虚拟表,只保存定义,不实际存储数据;
- 通常从真实的物理表查询中创建生成视图,也可以从已经存在的视图上创建新视图;
- 创建视图时,将冻结视图的架构,如果删除或更改基础表,则视图将失败;
视图是用来简化操作的,不缓冲记录,也没有提高查询性能
二、hive视图语法与操作
2.1 数据准备
在test数据库下有下面的几张表

使用t_usa_covid19这张表,并且插入部分数据

2.2 创建视图
2.2.1 创建普通的视图
create view v_usa_covid19 as select count_date, county,state,deaths from t_usa_covid19 limit 10;创建成功后,可以使用 : show views 查看视图;

2.2.2 基于视图创建视图
以上面创建的视图的基础上再次创建一个视图
create view v_usa_covid19_from_view as select * from v_usa_covid19 limit 5;

2.3 查看视图定义
show create table 视图名称;

2.4 使用视图
当视图创建出来之后就可以基于视图查询数据了,比如使用第一个视图查询数据
select * from v_usa_covid19;就可以正常返回数据了;

注意
视图是虚拟的,只能用于查询相关操作,不能向视图中插入数据
2.5 删除视图
drop 视图名

2.6 更改视图属性
给视图增加一个备注名称
alter view v_usa_covid19 set TBLPROPERTIES ('comment' = 'This is my view');2.7 更改视图定义
只查询指定的某些字段
alter view v_usa_covid19 as select county,deaths from t_usa_covid19 limit 5;
三、使用视图的好处
3.1 只将真实表中特定的列数据提供给用户,保护数据隐式
下面这个例子使用视图来限制数据访问可以用来保护信息不被随意查询
3.1.1 创建一个表
create table userinfo(firstname string, lastname string, ssn string, password string);
3.1.2 基于这个表创建一个视图
该视图只返回部分字段,比如密码比较隐私就不返回;
create view safer_user_info as select firstname, lastname from userinfo;
3.2 降低查询的复杂度,优化查询语句
如下为一个嵌套子查询语句
from (
select * from people join cart
on(cart.pepople_id = people.id) where firstname = 'join' ) a select a.lastname where a.id = 3;
利用视图,可以将内部的关联查询封装为一个视图
create view shorter_join as select * from people join cart n (cart.pepople_id = people.id) where firstname = 'join';
有了视图之后,就可以基于视图简化查询语句了
select lastname from shorter_join where id = 3;
四、hive物化视图
4.1 hive 物化视图概念
物化视图(Materialized View)是一个包括查询结果的数据库对像,可以用于预先计算并保存表连接或聚集等耗时较多的操作的结果。在执行查询时,就可以避免进行这些耗时的操作,而从快速的得到结果。
使用物化视图的目的就是通过预计算,提高查询性能,当然需要占用一定的存储空间。
4.1.1 hive物化视图特点
- Hive3.0开始尝试引入物化视图,并提供对于物化视图的查询自动重写机制(基于Apache Calcite实现);
- Hive的物化视图还提供了物化视图存储选择机制,可以本地存储在Hive,也可以通过用户自定义storage handlers存储在其他系统(如Druid);
- Hive引入物化视图的目的就是为了优化数据查询访问的效率,相当于从数据预处理的角度优化数据访问;
- Hive从3.0丢弃了index索引的语法支持,推荐使用物化视图和列式存储文件格式来加快查询的速度;
4.2 物化视图与视图的区别
- 视图是虚拟的,逻辑存在的,只有定义没有存储数据;
- 物化视图是真实的,物理存在的,里面存储着预计算的数据;
- 视图的目的是简化降低查询的复杂度,而物化视图的目的是提高查询性能;
物化视图能够缓存数据,在创建物化视图的时候就把数据缓存起来了,Hive把物化视图当成一张“表”,将数据缓存。而视图只是创建一个虚表,只有表结构,没有数据,实际查询的时候再去改写SQL去访问实际的数据表;
4.3 物化视图语法
完整语法树如下
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db_name.]materialized_view_name
[DISABLE REWRITE]
[COMMENT materialized_view_comment]
[PARTITIONED ON (col_name, ...)]
[CLUSTERED ON (col_name, ...) | DISTRIBUTED ON (col_name, ...) SORTED ON (col_name, ...)]
[
[ROW FORMAT row_format]
[STORED AS file_format]|
STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)]
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
AS SELECT ...;补充说明:
- 物化视图创建后,select查询执行数据自动落地,“自动”也即在query的执行期间,任何用户对该物化视图是不可见的,执行完毕之后物化视图可用;
- 默认情况下,创建好的物化视图可被用于查询优化器optimizer查询重写,在物化视图创建期间可以通过DISABLE REWRITE参数设置禁止使用;
- 默认SerDe和storage format为hive.materializedview.serde、 hive.materializedview.fileformat;
物化视图支持将数据存储在外部系统(如druid),如下述语法所示:
CREATE MATERIALIZED VIEW druid_wiki_mv
STORED AS 'org.apache.hadoop.hive.druid.DruidStorageHandler'
AS
SELECT __time, page, user, c_added, c_removed
FROM src;
目前支持物化视图的操作有drop和show操作,后续会增加其他操作
DROP MATERIALIZED VIEW [db_name.]materialized_view_name;
DESCRIBE [EXTENDED | FORMATTED] [db_name.]materialized_view_name;
当数据源变更(新数据插入inserted、数据修改modified),物化视图也需要更新以保持数据一致性,目前需要用户主动触发rebuild重构;
ALTER MATERIALIZED VIEW [db_name.]materialized_view_name REBUILD;
4.4 基于物化视图的查询重写
从上面的内容我们知道,物化视图创建后即可用于相关查询的加速,即:用户提交查询query,若该query经过重写后可以命中已经存在的物化视图,则直接通过物化视图查询数据返回结果,以实现查询加速。
是否重写查询使用物化视图可以通过全局参数控制,默认为true,如下设置;
hive.materializedview.rewriting=true
用户可选择性的控制指定的物化视图查询重写机制,语法如下:
ALTER MATERIALIZED VIEW [db_name.]materialized_view_name ENABLE|DISABLE REWRITE;
物化视图的查询重写过程
- 用户提交查询query
- 若该query经过重写后可以命中已经存在的物化视图
- 则直接通过物化视图查询数据返回结果,以实现查询加速
4.5 操作演示
前置操作,当前会话窗口执行下面的设置
set hive.support.concurrency = true; --Hive是否支持并发
set hive.enforce.bucketing = true; --从Hive2.0开始不再需要 是否开启分桶功能
set hive.exec.dynamic.partition.mode = nonstrict; --动态分区模式 非严格
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; --
set hive.compactor.initiator.on = true; --是否在Metastore实例上运行启动线程和清理线程
set hive.compactor.worker.threads = 1; --在此metastore实例上运行多少个压缩程序工作线程。
4.5.1 新建一张事务表 student_trans
CREATE TABLE student_trans (
sno int,
sname string,
sdept string)
clustered by (sno) into 2 buckets stored as orc TBLPROPERTIES('transactional'='true');
4.5.2 导入数据到student_trans中
insert overwrite table student_trans select num,name,dept from student;
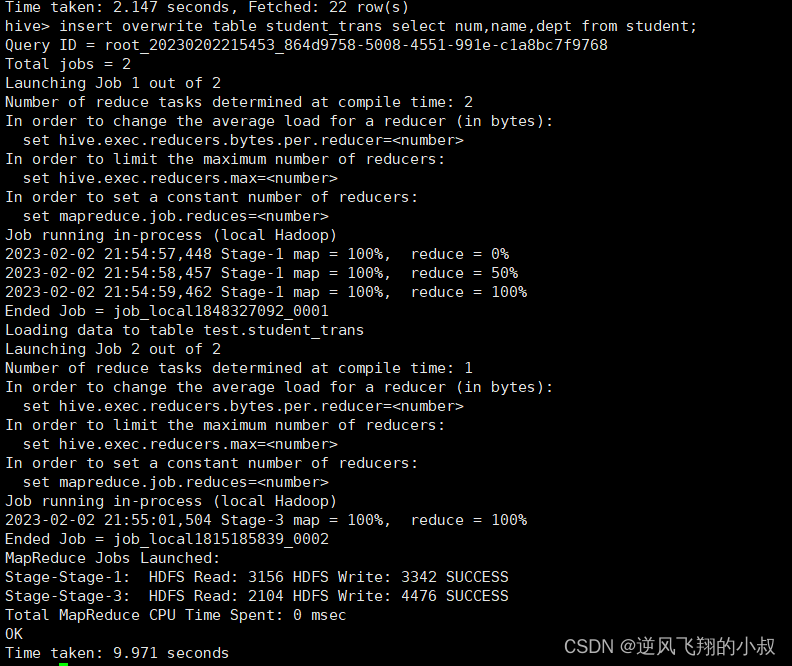
执行完成后检查表的数据
4.5.3 基于student_trans建立聚合物化视图
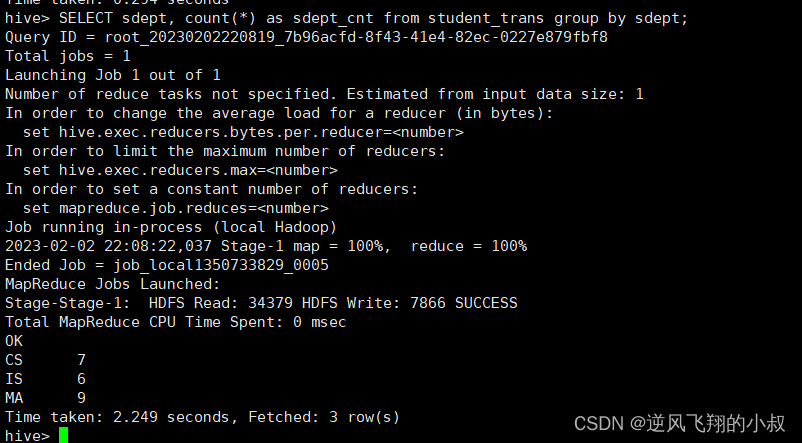
CREATE MATERIALIZED VIEW student_trans_agg AS SELECT sdept, count(*) as sdept_cnt from student_trans group by sdept;
从执行过程也可以看出,这里当执行CREATE MATERIALIZED VIEW,会启动一个MR对物化视图进行构建,执行完成后可以发现当下的数据库中有了一个物化视图;

4.5.4 聚合查询原始表与查询物化视图对比
先删除上面的物化视图

对原始表student_trans查询
重新创建物化视图后再次查询

对比两者的查询过程不难看出,第一个查询执行了map-reduce任务,耗时2秒多,第二个查询,没有执行map-reduce任务,由于会命中物化视图,重写query查询物化视图,查询速度会加快(没有启动MR,只是普通的table scan),查询时间提升了一倍多,这要是在数据量非常大的情况下性能将是巨大的改善;
为了进一步验证上面的说法,可以使用explain进行执行计划的查看
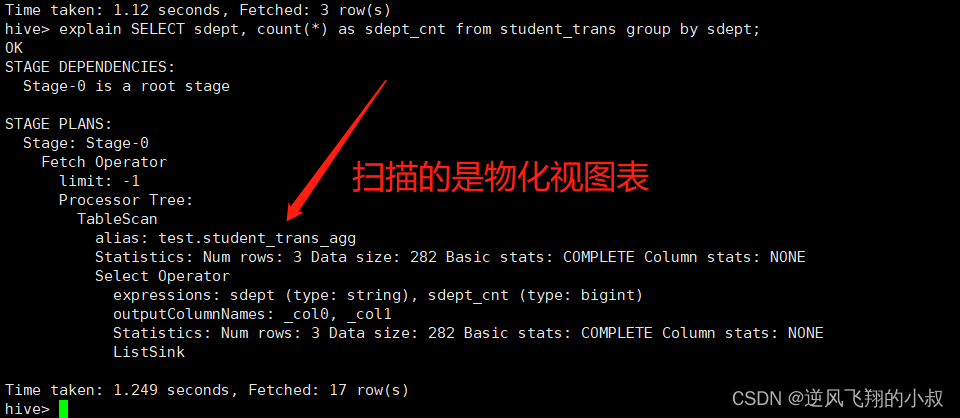
检查hdfs文件目录,可以发现也创建了一个物化视图表的数据目录

4.5.5 物化视图其他常用命令
#验证禁用物化视图自动重写
ALTER MATERIALIZED VIEW student_trans_agg DISABLE REWRITE;
#查看物化视图
show materialized views;
#删除物化视图
drop materialized view student_trans_agg;





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结