您现在的位置是:首页 >学无止境 >Spark Streaming网站首页学无止境
Spark Streaming
1. 简介
(1) Spark streaming是spark体系中的一个面向流数据的流式实时计算框架;可以实现高吞吐量的,具备容错机制的实时流数据的处理;
(2) Spark core是核心的计算引擎,可以支持很多项目,streaming就是其中一个;Spakr streaming相对其他流式计算框架更具有优势,因为可以和spark其他组件结合使用;
(3) 支持多种数据源输入,也支持数据输出到多处;
Spark streaming接收kafka、Flume、HDFS、套接字等各种来源实时输入数据,进行处理,处理后结构数据可存储到文件系统、数据库,或显示在可视化图像中;Dashboards:类似图形接收界面

2.Spark core支持项目

(1) Spark core就是一个核心的计算引擎,这些项目都是基于此计算引擎基础上的;
(2) Spark streaming面向流式计算的;
(3) Spark sql dataframes类似于hive,sql语句的方式做一个大数据的统计和挖掘 ;
(4) MLlib是面向机器学习的一个组件或者服务;
(5) Graphx是面向图计算的;
(6) 结合使用,具有很灵活的扩展性。
3. Streaming与Storm的区别
Storm:数据呈水流状,最基本单位是tuple,来一个tuple处理一个;
Streaming:按照时间做了离散化(将接收的实时数据,按照一定时间间隔对数据进行拆分),本质也是批处理;
Streaming跟storm一样,任务开启就没有结束,类似进程一样;
Streaming无法实现毫秒级的流计算,而Storm可以实现毫秒级响应;
streaming的低延迟执行可以用于实时计算,相比storm,RDD数据集更容易做高效的容错处理;
Streaming采用的小批量处理的方式使得它可以同时兼任批量和实时数据处理的逻辑和算法,因此,方便了一些需要历史数据和实时数据联合分析的特定应用场合。
4.Dstream
(1) Spark开发,就是开发RDD,根据RDD的DAG图开发
Spark Core:RDD开发,针对RDD-DAG图
Spark Streaming:DStream开发,针对DStream-DStreamGraph图
(2) DStream:离散化数据流,代表了一系列连续的RDD,每一个RDD包含特定时间间隔数据;在内部实现上,Spark Streaming的输入数据按照时间片(如5秒)分成一段一段的DStream。每一段数据转换为Spark中的RDD,并且对DStream的操作都是最终转变为对相应的RDD的操作;
离散流:连续不断流入的数据,按时间处理,比如,连续一分钟内收集的数据作为一个单元,单元之间是相互独立的,就是把连续不断的数据流,切出不同的离散分片。把数据进行离散化处理;
(3) RDD的DAG是一个空间概念,DStream在RDD基础上加了时间维度;
(4) DStream各种操作是可以映射到内部RDD上进行的,对DStream的操作可以通过RDD的tansformation生成新的DStream。
DStream操作
DStream即是连续的RDD,任何对DStream的操作都会转变为对底层RDD的操作在同一个时间窗口内,DStream和RDD是一一对应的关系,就是可以把DStream看作是RDD时间维度上的封装(DStream=RDD+时间)
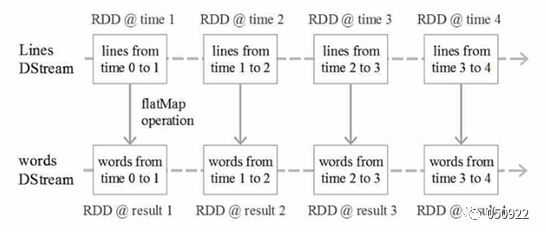
RDD的运行是有DAG图的,DStream也有自己的DAG图,叫做DStreamGraph
Spark Streaming程序中一般都会有若干个对DStream的操作。DStreamGraph就是由这些操作依赖关系构成。
5.DStream算子
对RDD操作,都是通过算子实现的,DStream的算子和RDD的算子不一样;
RDD算子:tansformation (转换) 和action(行动)
DStream算子:tansformation (转换)和oupput(输出)
RDD是要实现数据操作,要行动算子
DStream是保证数据传输,要输出算子
5.1 Transformation:转换算子
(1) Spark支持RDD进行各种转换,因为DStream是由RDD组成的SparkStreaming提供了一个可以在DStream上使用的转换集合,这些集合和RDD上可用的转换类似
(2) 转换应用到DStream的每个RDD
(3) Spark Streaming提供了reduce和count这样的算子,但不会直接触发DStream计算
(4) Map、flatMap、join、reduceByKey
5.2 Output:执行算子或者输出算子
(1) Print:直接输出
(2) saveAsObjectFile、 saveAsTextFile、 saveAsHadoopFiles:直接存储,将一批数据输出到Hadoop文件系统中,用批量数据的开始时间戳来命名;
(3) forEachRDD:额外操作,允许用户对DStream的每一批量数据对应的RDD本身做任意操作;
Streaming处理后的数据,不止可以直接存磁盘,还可以输出到SQL、kafka、Hbase等再处理,这时候就要用到forEachRDD算子。
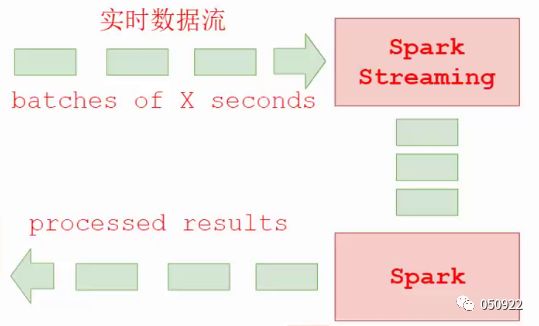
6. Spark Streaming处理数据流程
Spark Streaming目的:将连续的数据持久化、离散化,然后进行批量处理
数据持久化:接收到的数据暂存
离散化:按时间窗口,对数据分片,形成处理单元
分片处理:分批处理
Spark Streaming的基本原理是将实时输入数据流以时间片(秒级,可以设置)为单位进行拆分,然后经spark引擎以类似批处理的方式处理每个时间片数据。
(1) 针对小数据块的RDD构建DAG图;
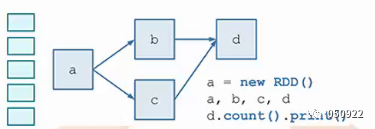
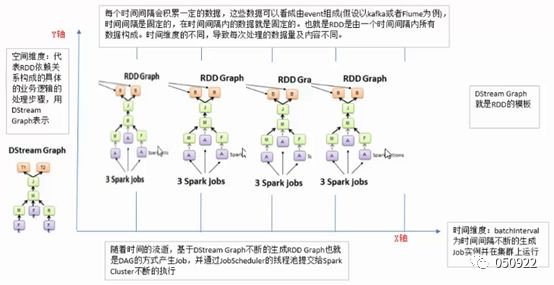
(2) 数据来自大数据流,数据流有时间概念,按时间窗口的方式,连续对Data进行切片处理;
小方块代表一个数据,虚线与虚线之间代表数据窗口,比如说一分钟,五分钟等,在时间创建内,把小数据积累起来,构成大的批量数据文件,多个小数据块DAG汇聚成的大数据流DAG;
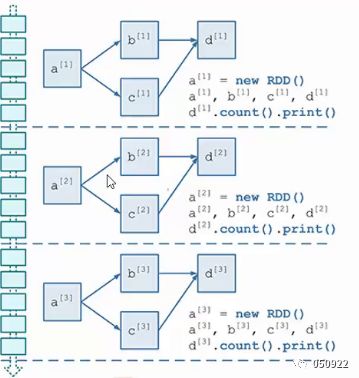
(3) 处理的数据是小批量的,很多小批量数据集汇集成大批量数据,才形成流式处理,虽然是流式计算框架,但本质上还是批处理思路。所以说spark streaming与基于spark core基础之上的。
Spark Streaming将接收到的实时流数据,按照一定时间间隔,Spark Streaming把数据拆分成小数据块,交给spark Engine引擎处理,最终得到一批批的结果;

每一批数据,在Spark内核对应一个RDD实例;
DStream是Spark Streaming特有的数据类型,代表一系列连续的RDD,可以看做一组RDDs,即RDD的一个序列,相当于是在RDD的基础上做了对时间的依赖。
空间时间维度RDD:

这里的RDD与spark core的RDD不一样,这里的RDD带有时间维度;
上图是4个DStreamRDD,切片的处理逻辑都相同只是时间维度不一样。
7. DStream Graph
(1) 一系列tansformation操作的抽象
(2) 核心,最终也是要转换成RDD
Code----》DStream DAG----》DStream依赖
DAG:正向记录,反向执行
例如:c = a.join(b),d = c.filter()时,它们的DAG逻辑关系是a/bàc,càd,但在Spark Streaming在物理记录时却是反向的a/bßc,cßd

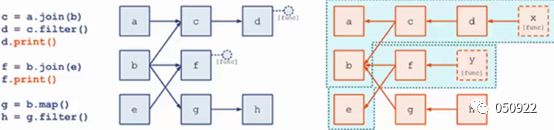
Dstream之间的转换所形成的依赖关系全部保存在DStreamGraph中,DStreamGraph对于后期生成RDDGraph至关重要;
DStreamGraph有点像简洁版的DAG scheduler,负责根据某个时间间隔生成一序列的JobSet,以及按照依赖关系序列化。
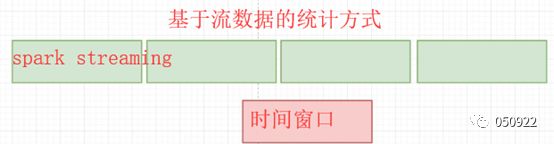
8.窗口操作
Spark提供了一组窗口操作,通过滑动窗口技术对大规模数据的增量更新进行统计分析;
时间窗口:基于流数据统计的方式,定时进行一定时间段内的数据处理(股票动态展示窗口)
基于窗口操作需要指定两个参数:
窗口总长度(window length)
滑动时间间隔(slide interval)
统计最近一个小时的PV(网页访问)量,要求每十分钟更新一次,可以把时间窗口设置为一个小时,每十分钟更新一次时间窗口
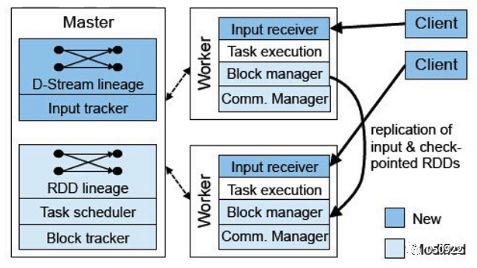
9.架构
master:记录DStream之间的依赖关系或者血缘关系,并负责任务调度以及生成新的RDD
worker:从网络接收数据,存储并执行RDD计算
Client:负责向spark streaming中灌入数据
10.工作原理
(1) 在Spark Streaming中,会有一个组件Receiver,作为一个长期运行的task跑在一个executor上;
(2) 每个receiver都会负责一个input DStream(比如从文件中读取数据的文件流比如套接字流,或者从kafka中读取的一个输入流等等);
(3) Spark Streaming通过inputDStream与外部数据源进行连接,读取相关数据。
11.两种模式
Receiver模式:Worker节点要两个以上,一个接收数据,一个处理数据,数据实时接收,实时处理(被动模式);
Direct模式:直连模式,定时检查输入源数据,一有数据变化就处理(主动模式)
11.1 Receiver模式
使用kafka的高层次ConsumerAPI来实现,receiver从kafka中获取数据都存储在Spark Executor的内存中,然后Spark Streaming启动的job会去处理那些数据。然而,在默认的配置下,这种方式可能会因为底层的失败而丢失数据,如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日记机制(WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)的预写日志中。所以,即使底层节点出现了失败也可以使用预写日志中的数据进行恢复。
11.2 Direct模式
Spark1.3中引入Direct方式,用来替代掉使用Receiver接收数据,这种方式会周期性地查询Kafka,获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。
12.作业提交
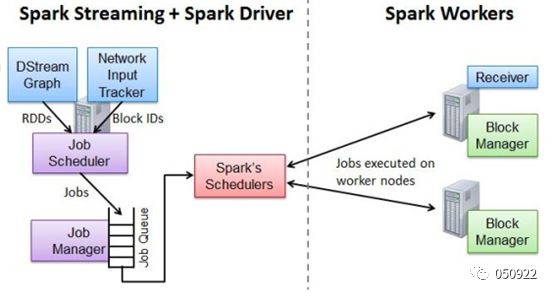
Network Input Tracker:跟踪每一个网络received数据,并且将其映射到相应的inputDStream上
Job Scheduler:任务队列,周期性的访问DStreamGraph并且生成Spark Job,将其交给Job Manager执行
Job Manager:获取任务队列,并执行Spark任务
13.容错-WAL
WAL:预写日记,操作会先写入日记,再写入内存。
实时的流式处理系统必须是7*24运行的,同时可以从各种各样的系统错误中恢复,在设计之初,Spark Streaing就支持driver和worker节点的错误恢复。
Worker容错:spark和rdd保证worker节点的容错性。sparkstreaming构建在spark之上,所以它的worker节点也是同样的容错机制;
Driver容错:依赖WAL持久化日志;
启动WAL需要完成配置:给streamingContext设置checkpoint的目录,该目录必须是HADOOP支持的文件系统,用来保存WAL和做Streaming的checkpoint
spark.streaming.receiver.writeAheadLog.enable设置为true;
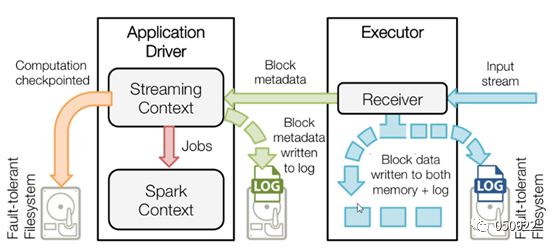
Receiver接收数据同时写入内存和磁盘,以备数据丢失,把数据以block metadata(数据块元数据)的方式通知driver,driver也会把元数据存入磁盘中,
Checkpointed是把处理过的数据加载到内存中,再加载就直接从内存中提取;
Block metadata:数据存储的位置、数据结构,确保application driver可以直接读取数据存储的真正位置。
当一个Driver失败重启后,恢复流程:
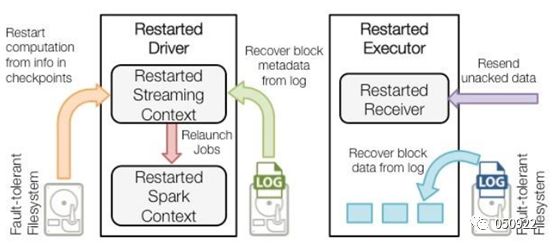
当driver重启,executor也会跟着重启,这时内存中所有东西都会被清空,这时executor就可以从本地磁盘恢复数据,driver也可以通过元数据恢复操作,必要时候也会从Filesystem恢复处理流程。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结