您现在的位置是:首页 >其他 >CBAM: Convolutional Block Attention Module论文总结和代码实现网站首页其他
CBAM: Convolutional Block Attention Module论文总结和代码实现
论文:https://arxiv.org/pdf/1807.06521.pdf
中文版:CBAM: Convolutional Block Attention Module中文翻译
源码:https://github.com/Jongchan/attention-module
目录
卷积块注意模块(CBAM),一个简单而有效的用于前馈卷积神经网络的注意模块。
给定中间特征图,CBAM模块可以顺序地推导出两个独立维度的注意力图(通道和空间),然后将注意力乘到输入特征图上进行自适应特征细化。
一、论文的出发点
cnn基于其丰富的表征能力,极大地推动了视觉任务的完成,为了提高cnn网络的性能,最近的研究主要聚焦在网络的三个重要因素:深度、宽度和基数。除了这些因素,作者还研究了网络架构的一个不同方面——注意力。注意力研究的目标是通过使用注意机制来增加表现能力:关注重要的特征,并抑制不必要的特征。在本文中,作者提出了一个新的网络模块,名为“卷积块注意模块”(CBAM),该模块用来强调这两个主要维度上的有意义的特征:通道和空间轴,该模块实现方式是通过学习强调或抑制哪些信息,有效地帮助信息在网络中流动。
二、论文的主要工作
1. 提出了一种简单而有效的注意力模块(CBAM),可广泛应用于增强cnn的表示能力。
2. 作者验证了我们的注意模块的有效性,通过广泛的消融试验。
3. 通过插入CBAM,作者验证了在多个基准测试(ImageNet-1K, MS COCO,和VOC 2007)上,各种网络的性能都得到了极大的改善。
三、CBAM模块的具体实现
CBAM模块的整体结构图:
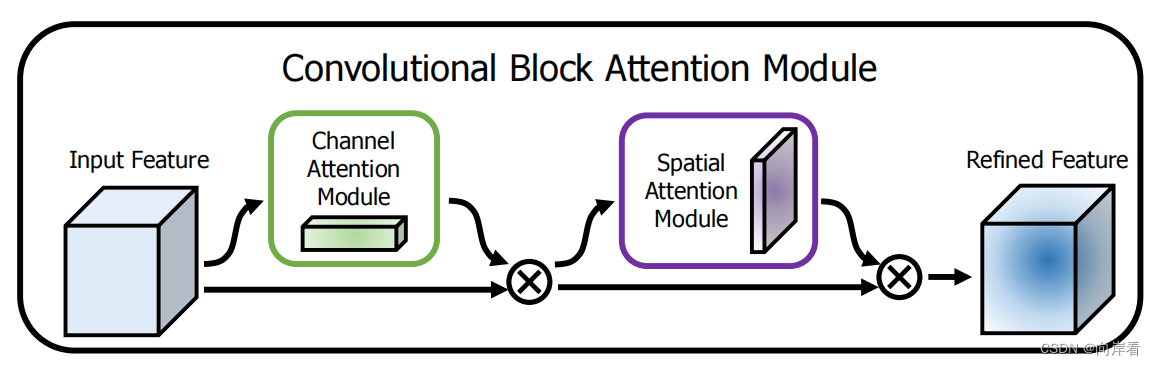
该模块有两个顺序子模块:通道(Channel)和空间(Spatial)。
1. Channel attention module
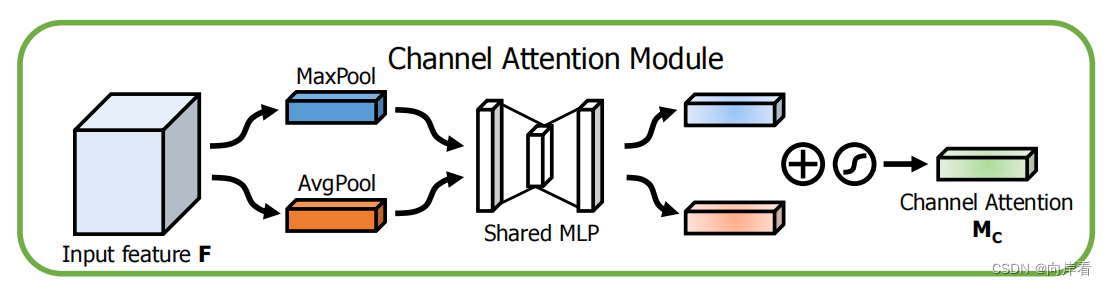
目的:利用特征的通道间关系生成通道注意图。
方法:通道维度不变,压缩输入特征图的空间维度。
步骤:
(1)AP和MP操作:首先通过使用AP(average pooling)和MP(max pooling)操作聚合特征图F的空间信息,生成特征向量、
。
(2)转发入共享网络Shared MLP:、
被转发到一个共享网络,共享网络由一个隐含层的多层感知器(MLP)组成,为了减少参数开销,隐含层的激活大小设置为
,在该模块中,输入的特征图先再通过一个全连接层将通道数压缩为原来的1/r倍,经过ReLU激活函数进行激活,再通过一个全连接层扩张到原通道数,输出得到两个激活后的特征向量。
(3)特征合并和进行softmax:将共享网络应用到每个特征向量后,使用按元素进行求和并通过softmax函数得到包含通道注意力的特征向量。原文中没有给予这个特征向量命名符,为了方便将其称之为s。
Channel attention module模块整体的算子公式如下所示:
![]()
σ是指sigmoid函数,,
。
最后将s与原特征图F相乘,得到特征图F',传递给Spatial attention module。
2. Spatial attention module
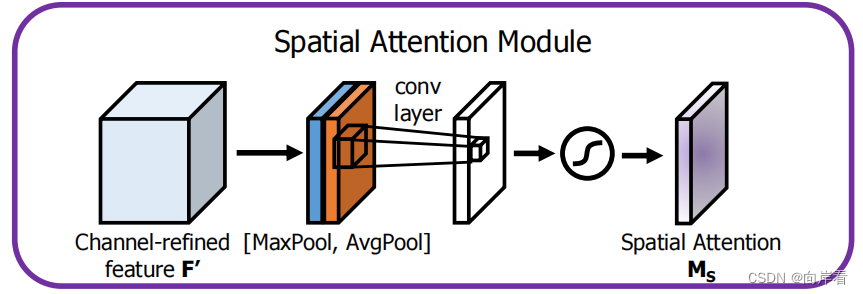
目的:利用特征间的空间关系生成空间注意图。
方法:空间维度不变,压缩通道维度。
步骤:
(1)AP和MP操作:首先特征图F'使用AP(average pooling)和MP(max pooling)操作得到两个1*H*W的特征图。
(2)拼接和卷积:将它们拼接在一起得到一个2*H*W的特征图,再通过一个7x7的卷积重新得到1*H*W的特征图。
(3)sigmoid:最后,通过一个sigmoid函数,得到包含空间注意力的特征图。原文中没有给予这个特征图命名符,为了方便将其称之为z。
Spatial attention module模块整体的算子公式如下所示:
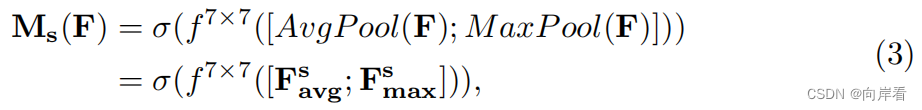
最后将z与F'进行相乘,就得到了原特征图大小且包含空间和通道注意力的特征图,进行输出。
重复该过程,进行端到端训练,得到最佳的空间和通道注意力。
四、实验
以ResNet作为主干特征提取网络,将CBAM嵌入ResBlock,嵌入位置如下:

实验1:寻找最佳的池化方法,使得通道注意力提取最佳。

实验2:寻找最佳的模块实验顺序。

实验3:寻找最佳的通道池化方法和卷积核大小,使得空间注意力提取最佳。
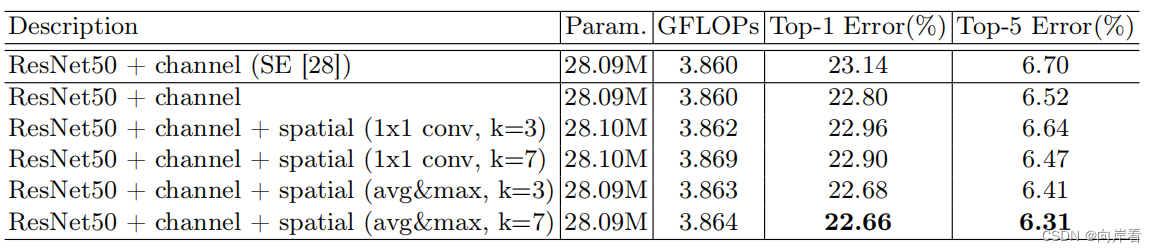
五、总结
CBAM模块可以顺序地推导出两个独立维度的注意力图(通道和空间),然后将注意力乘到输入特征图上进行自适应特征细化。CBAM模块中子模块Channel attention module与SE模块十分相似,都是经过池化层、全连接层,最后由softmax函数得到channel权重,并且提出了空间注意力提取的子模块,最终得到的特征图同时包含空间和通道注意力。
六、代码实现
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) # 7,3 3,1
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class CBAM(nn.Module):
def __init__(self, in_planes, ratio=16, kernel_size=7):
super(CBAM, self).__init__()
self.ca = ChannelAttention(in_planes, ratio)
self.sa = SpatialAttention(kernel_size)
def forward(self, x):
out = x * self.ca(x)
result = out * self.sa(out)
return result
if __name__ == '__main__':
x = torch.randn(1, 1024, 32, 32)
net = CBAM(1024)
out = net.forward(x)
criterion = nn.L1Loss()
loss = criterion(out, x)
loss.backward()
# 最终输出特征图V的size和损失值
print('out shape : {}'.format(out.shape))
print('loss value : {}'.format(loss))





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结