您现在的位置是:首页 >学无止境 >GAN在图像转译领域的应用-CycleGAN&Pix2Pix网站首页学无止境
GAN在图像转译领域的应用-CycleGAN&Pix2Pix
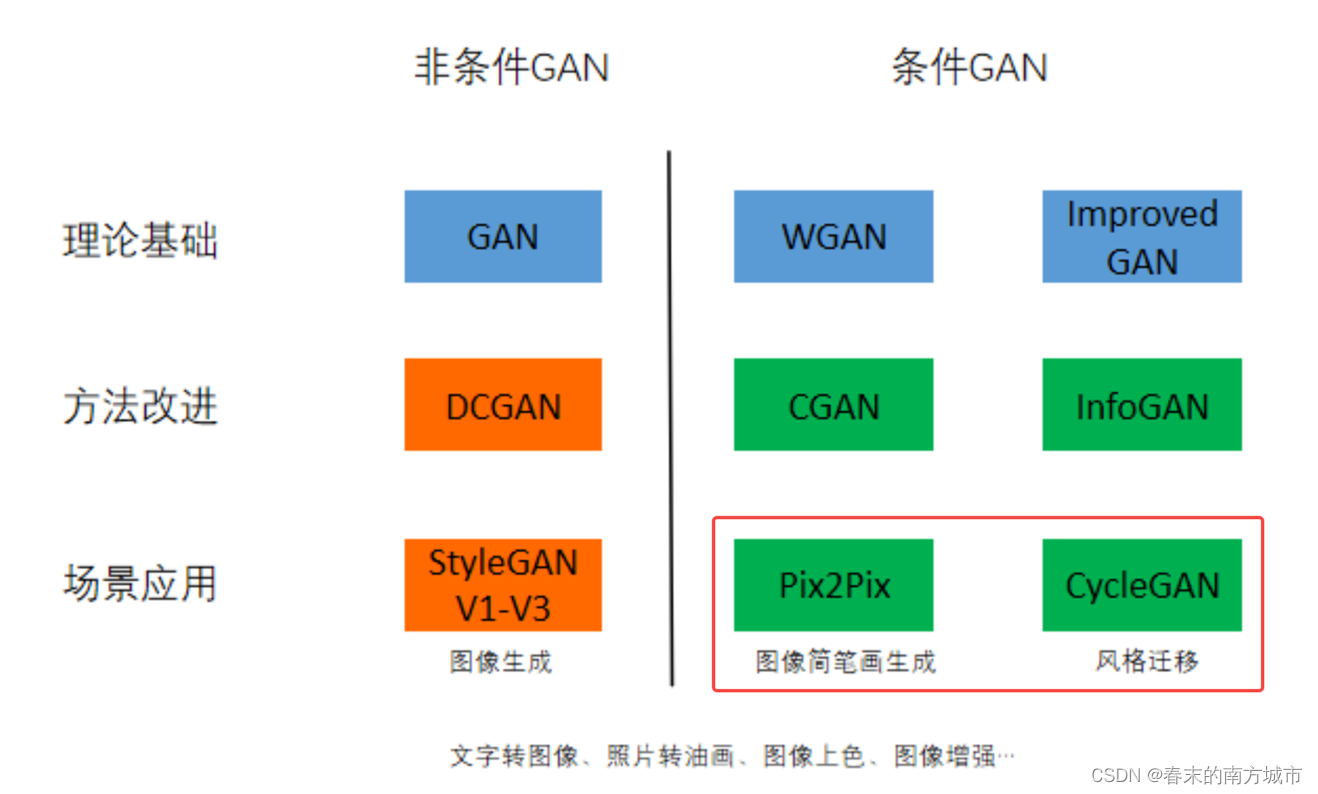
在之前的博客中向大家介绍了生成对抗网络GAN的相关概念以及条件GAN,DCGAN相关内容,需要的小伙伴可以点击以下链接了解~生成对抗网络GAN_生成对抗网络流程_春末的南方城市的博客-CSDN博客生成对抗网络Generative Adversarial Networks(GAN)包含生成模型(generative model)和判别模型(discriminative model)两个模型。生成模型的任务是生成和原始数据相似的实例,判别模型的任务是判断给定的实例是真实的还是伪造的。https://blog.csdn.net/xs1997/article/details/130277123?spm=1001.2014.3001.5501
生成对抗网络-Conditional GAN_春末的南方城市的博客-CSDN博客判别器的功能从一个变成两个,一是判断G生成的图片符合真实样本的程度,二是判断输入图片符合给定条件y的程度。输入为两个即潜在变量和控制条件。G的输入为z和y,y为条件,通常为一个数值或者one-hot向量(表示某种类别or。GAN是无监督的,输出是完全随机的,比如在人脸上训练好的网络,最后生成什么样的人脸是完全没办法控制的。在输入的时候加入了条件信息,可以根据条件信息指定生成某。特征),z为潜在向量。https://blog.csdn.net/xs1997/article/details/130278117?spm=1001.2014.3001.5501 这次主要向大家介绍GAN的一些新奇好玩的应用,比如风格迁移,简笔画生成,图像上色等等,一起探究这些应用实现的背后原理是什么以及GAN是如何设计的,ok,接下来进入正题。
GAN内容回顾
GAN
首先简单回顾一下GAN的基本内容,输入噪声z分布到生成器中,然后生成器生成假的样本,假的样本和真实的样本同时输入到判别器中,判别器进行判别输入的图像是真的图像还是伪造的图像,生成器再根据判别器的反馈不断修正生成数据的分布,知道判别器无法判断输入的图像是真还是假,此时,训练过程达到平衡状态。
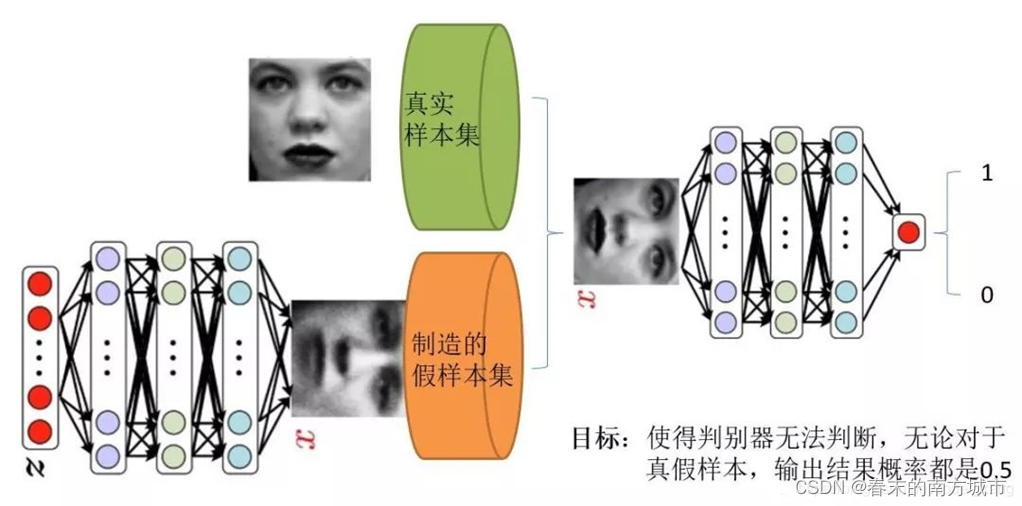
判别器训练
1.对生成器输入一段噪音,输出一个符合某一分布的假数据(如一组图片的分布);
2.从生成的分布中抽取一些数据,标记为0,从真实样本集中抽取一些数据,标记为1;
3.将数据喂给判别器进行训练,使判别器能够很好的分辨数据的真伪,判别器训练完成。
生成器训练
4.将生成器与判别器进行逻辑连接,生成器产生的假数据全部标记为1喂给判别器;
5.喂给网络的数据产生的误差,通过误差反向传播算法传递给训练器,修正生成器的参数;
6.不断训练判别器和生成器,直到判别器无法分辨假数据和真实数据。
CGAN
Conditional GAN是无监督的,输出是完全随机的,比如在人脸上训练好的网络,最后生成什么样的人脸是完全没办法控制的。CGAN在输入的时候加入了条件信息,可以根据条件信息指定生成某类具体的图像,所以CGAN是有监督的GAN。

输入为两个即潜在变量和控制条件。G的输入为z和y,y为条件,通常为一个数值或者one-hot向量(表示某种类别or特征),z为潜在向量。

判别器的功能从一个变成两个,一是判断G生成的图片符合真实样本的程度,二是判断输入图片符合给定条件y的程度。

DCGAN
原始GAN使用的是多层感知机作为D和G,深度卷积生成对抗网络-DCGAN是将CNN与GAN的一种结合,把GAN的G和D换成了两个CNN,利用CNN的特征提取能力来提高生成网络的学习效果。生成器输入一个向量,经过反卷积尺寸扩张,通道数减少,最后生成一张假图像。判别器D是一个分类器,会逐步将生成的图片压缩成特征向量,通过特征向量进行分类。
生成器网络:
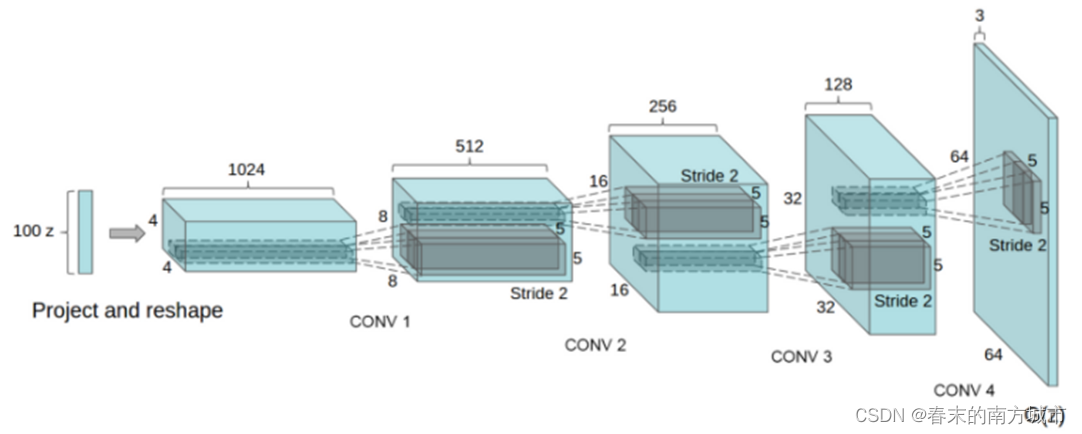 判别器网络:
判别器网络:

OK,接下来进入GAN的应用~
GAN的应用
CycleGAN

CycleGAN能做些什么呢,如上图,风景照片转化为莫奈映像派油画,莫奈映像派油画转化为风景照片,斑马转化成野马,野马转化为斑马,夏天转换为冬天,冬天转换为夏天等等这样一些非常好玩的应用都是通过CycleGAN来实现的,那它背后的原理是什么呢,接下来就和大家一起学习。 
CycleGAN由两个GAN组成了一个循环结构所以交CycleGAN,此外还包含了两个非常重要的损失函数cycle-consistency loss,因此我们可以简单理解为CycleGAN就是由两个GAN和两个循环一致性损失组成的一个循环结构。X由G生成假的Y’,DY判断图像是真还是假,同样,Y由F生成假的X’,DX判断图像是真还是假。两个GAN相互作用,保证了生成的图像与目标图像域的风格一致。此时,还不能保证生成的内容一致,比如X是输入一个橘子照片,生成了一个莫奈风格的苹果照片,此时DY判别器判别只要是莫奈风格的照片都可能会输出一个比较高的分数。但是它们的内容是不同的,这肯定不是我们期待的。因此,通过cycle-consistency loss,x由G生成的图像y,再通过另一个生成器F生成输入的图像x',如果能确保x和x'的内容尽可能接近,那么就可以保证图像生成的内容也尽可能的类似。通过这样一种方式,使得生成的图像既完成了风格之间的迁移,又保证了生成的内容的相似。
CycleGAN的损失函数同样由两个GAN的损失和两个cycle-consistency loss组成,由于形式是一样的,这里只介绍一个GAN的对抗损失。对抗损失可以保证生成器和判别器相互进化,进而可以保证生成器能产生更真实的图片。
对抗损失:
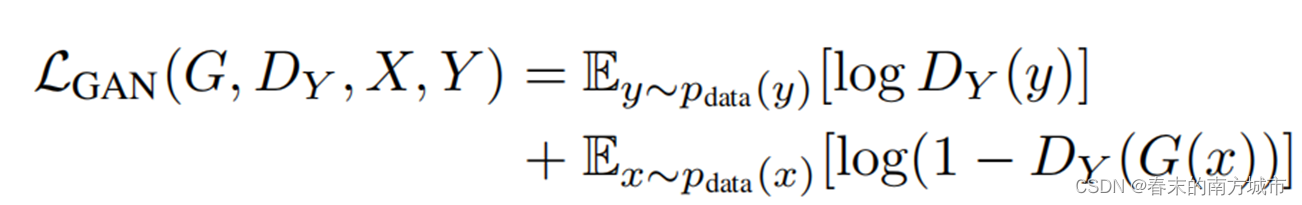
判别器D的目标是最大化后面这两项,DY(y)表示判别器判断y是真实图像的概率,因此是越大越好,DY(G(x))表示判别器判断G(x)是真实图像的概率,G(x)是生成的假图像,因此概率是越小越好,那么1-DY(G(x))这一项就是越大越好。因此生成器D的目标是最大化后面这两项。
生成器G和真实图像是没有关系的,之和生成图像有关,因此对于后面的第一项是不需要考虑的,生成器的目标是欺骗愚弄判别器,因此,对于生成器来说,DY(G(x))这一项是越大越好,那么1-DY(G(x))就是越小越好。
循环一致性损失:

该损失通过计算生成的图像与输入图像的L1范数,也就是逐元素作差取绝对值再求和,这样保证生成器的输出图像与输入图像只是风格不同,而内容相同。

所以总的目标函数就是由两个GAN的损失和cycle-consistency loss组成。
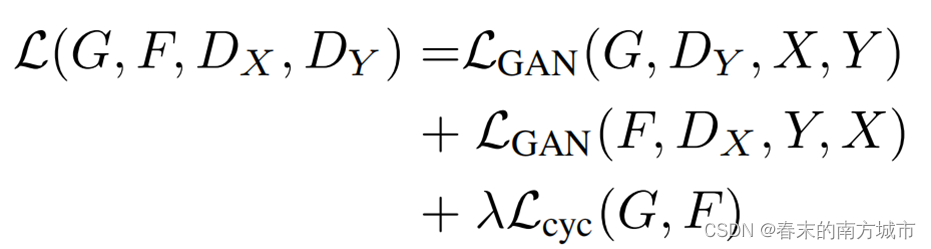
再来看一些CycleGAN的效果~

Pix2Pix
Pix2pix是基于cGAN实现图像翻译,因为cGAN可以通过添加条件信息来指导图像生成,因此在图像翻译中就可以将输入图像作为条件,学习从输入图像到输出图像之间的映射,从而得到指定的输出图像。而其他基于GAN来做图像翻译的,因为GAN算法的生成器是基于一个随机噪声生成图像,难以控制输出,因此基本上都是通过其他约束条件来指导图像生成,而不是利用cGAN,这是pix2pix和其他基于GAN做图像翻译的差异。

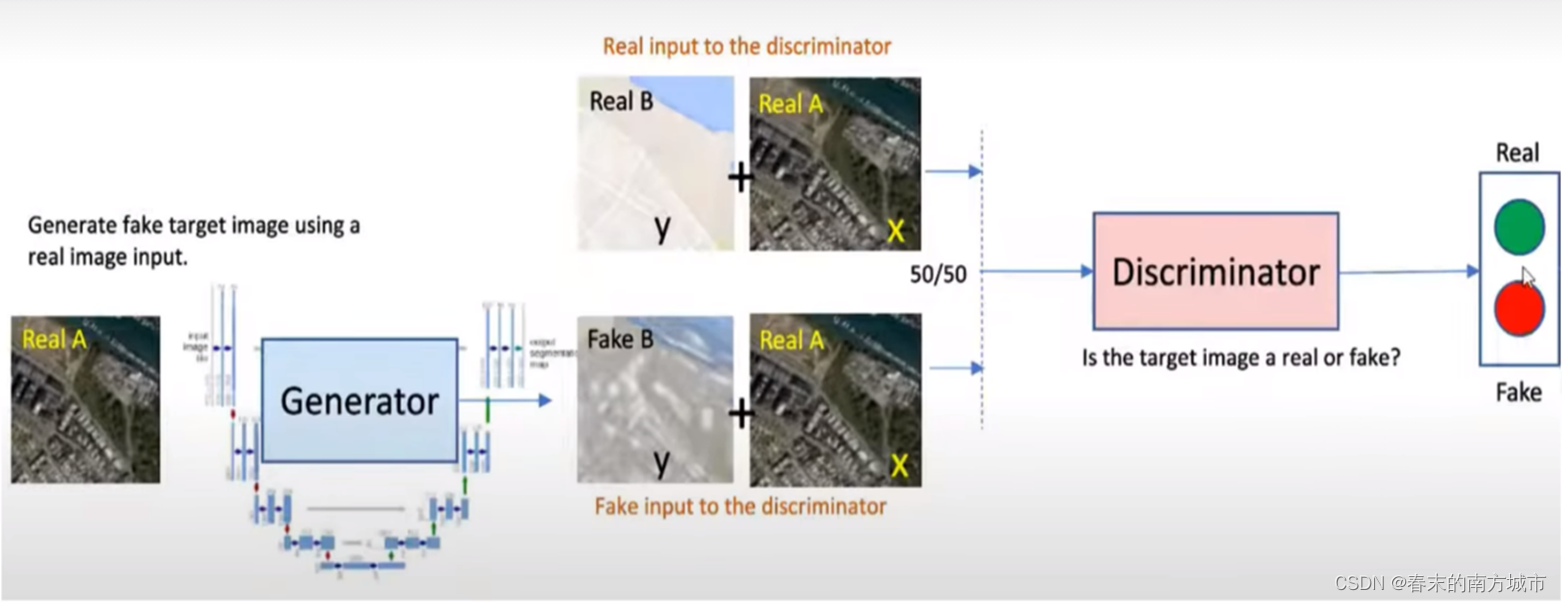
生成器采用U-Net,以图像对的形式输入,这是在图像分割领域应用非常广泛的网络结构,能够充分融合特征;而原本GAN中常用的生成器结构是encoder-decoder类型,采用skip-connection使得提取的特征不仅包含底层的斑块,颜色,边缘轮廓等信息,也包含高层的高级语义纹理信息。
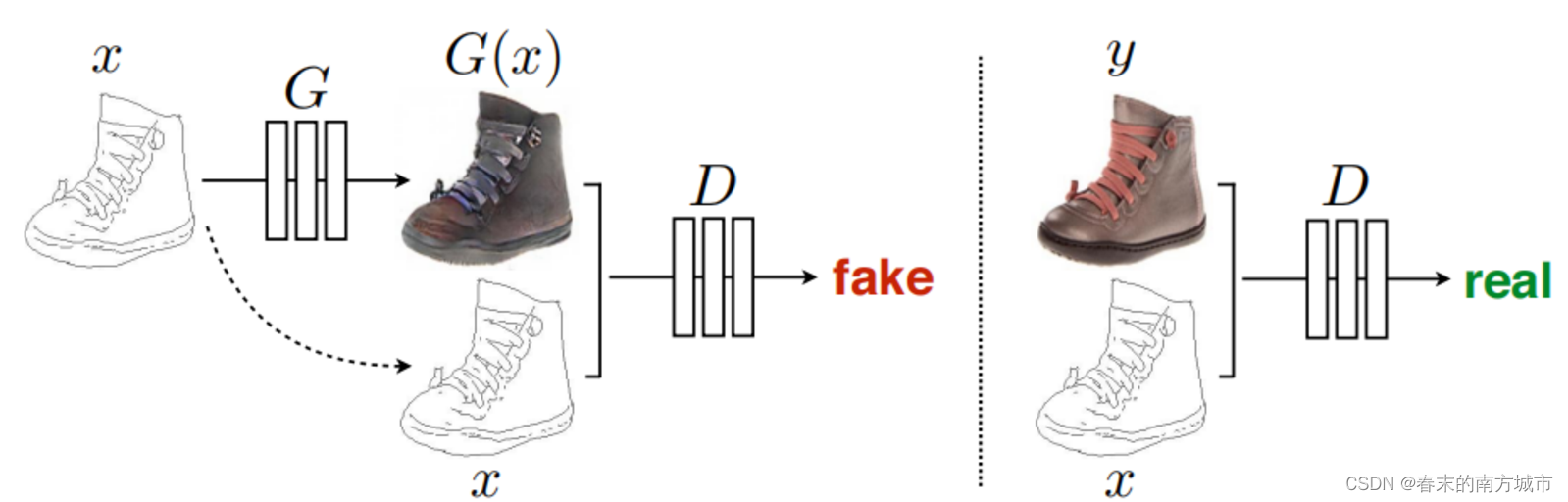
x作为生成器G的输入(随机噪声z在图中并未画出,去掉z不会对生成效果有太大影响,但假如将x和z合并在一起作为G的输入,可以得到更多样的输出)得到生成图像G(x),然后将G(x)和x基于通道维度合并在一起,最后作为判别器D的输入得到预测概率值,该预测概率值表示输入是否是一对真实图像,概率值越接近1表示判别器D越肯定输入是一对真实图像。另外真实图像y和x也基于通道维度合并在一起,作为判别器D的输入得到概率预测值。
目标函数:
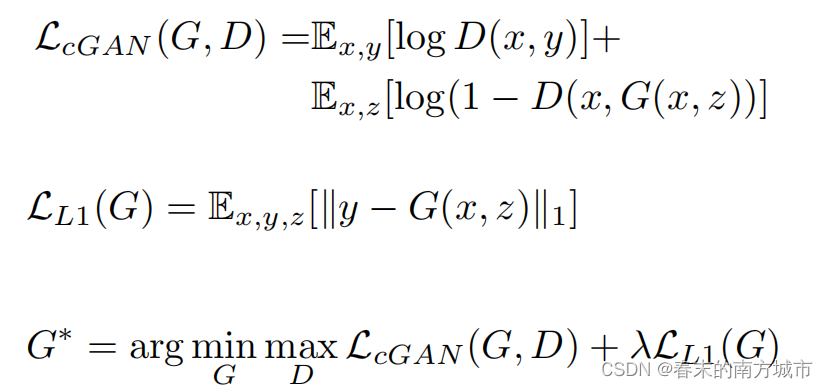
z表示随机噪声,判别器D的优化目标是第一个式子的值越大越好,而生成器G的优化目标是使得公式1的log(1-D(x,G(x,z))越小越好。用L1距离来约束生成图像G(x, z)和真实图像y之间的差异。可以看到,Pix2Pix的目标函数总体上和CycleGAN类似~
再来看一些Pix2Pix的效果~


总结
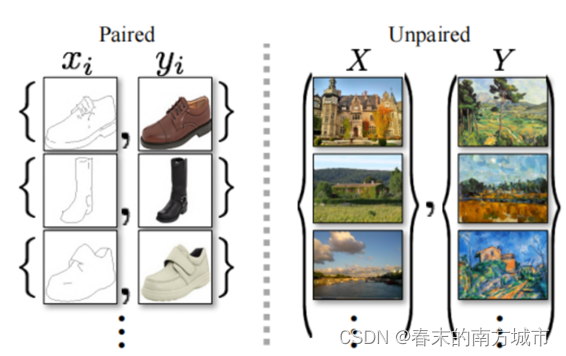
1.Pix2pix模型必须要求成对数据(paired data)。
2.CycleGAN利用非成对数据进行训练(unpaired data)。
3.Pix2Pix是有监督的条件GAN,CycleGAN是非条件GAN。
4.Pix2Pix通过CGAN的形式使得生成的图像和两个图像域内容保持一致。
5.CycleGAN通过cycle consistance loss来控制生成的图像和两个图像域内容保持一致。
OK,这次的分享就先到这,主要向大家介绍了一下CycleGAN和Pix2Pix的相关内容,GAN还有很好新奇好玩的应用,比如StyleGAN,AnimeGAN等等,在后续的分享中也会向大家介绍,也欢迎大家一起交流学习~






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结