您现在的位置是:首页 >技术杂谈 >(2022,MaskedGAN)掩蔽的生成对抗网络是数据高效生成学习者网站首页技术杂谈
(2022,MaskedGAN)掩蔽的生成对抗网络是数据高效生成学习者
Masked Generative Adversarial Networks are Data-Efficient Generation Learners
公众号:EDPJ
目录
4.1 在 CIFAR-10、CIFAR-100 和 ImageNet 上使用 BigGAN 条件生成图像
4.2 使用 StyleGAN-v2 在 100-shot、AFHQ 和 FFHQ 上进行无条件图像生成
4.3 使用 TransGAN 和 GANformer 进行无条件图像生成
H. 与 ADA 和 DA 中使用的“剪切 (cutout)” 的比较
0. 摘要
本文表明,掩蔽的生成对抗网络 (MaskedGAN) ,是在训练数据有限时的稳健图像生成学习器。 MaskedGAN 的思想很简单:它随机屏蔽掉某些图像信息,以便在有限的数据下进行有效的 GAN 训练。 我们开发了两种沿着训练图像的正交维度工作的掩蔽策略,包括一种移位空间掩蔽,它在空间维度上用随机移位掩蔽图像,以及一种平衡谱掩蔽,它用自适应概率掩蔽某些图像谱带。 这两种掩蔽策略相互补充,共同鼓励从有限的训练数据中进行更具挑战性的整体学习,最终抑制 GAN 训练中的琐碎解决方案和失败。 虽然简单,但广泛的实验表明,MaskedGAN 在不同的网络架构(例如,包括 BigGAN 和 StyleGAN-v2 的 CNN 以及包括 TransGAN 和 GANformer 的 Transformer)和数据集(例如,CIFAR-10、CIFAR-100、ImageNet、100-shot、AFHQ、FFHQ 和 Cityscapes)。
1. 简介
琐碎解决方案在无监督学习中无处不在,在 Masked Autoencoders (MAE) 这种流行的无监督 representation 方法中,也是如此。 MAE 通过掩蔽和重建图像来工作,其中图像掩蔽是抑制琐碎解决方案并能够学习高级语义特征的核心设计。 例如,He 等人提出了一种用于 MAE 的高比率掩蔽策略:
- 它可以阻碍图像重建的捷径,例如,在没有高级理解的情况下,使用局部空间插值从相邻块中恢复掩蔽块;
- 它鼓励全局空间插值,这需要在全局范围内对 patch 间上下文信息进行建模,最终学习重要且有意义的 representation。
在这项工作中,我们探索了 GAN 图像掩蔽训练的想法,旨在用有限的训练数据开发强大的图像生成学习器。 通过将图像掩蔽视为抑制训练捷径的一种通用手段,我们假设 GAN 训练中的图像掩蔽应该在空间和谱维度上进行,以防止鉴别器仅关注易于区分的图像位置和谱。 换句话说,应用随机空间和谱掩蔽为鉴别器训练创造了更具挑战性的任务,这迫使鉴别器学习更全面的信息,而不是仅学习易于区分的信息。 另一方面,由于对鉴别器应用掩蔽会减慢它们的学习速度,因此同步减速生成器学习对于整体平衡和稳定的对抗性学习至关重要。
在这种动机的驱使下,我们设计了 MaskedGAN,这是一个强大的图像生成网络,可以在有限的训练数据下有效地学习。 MaskedGAN 的思想很简单:它随机屏蔽某些图像信息以抑制 GAN 训练中的琐碎解。 我们开发了两种沿着图像的正交维度工作的掩蔽策略。
- 第一个是移位空间掩蔽,它通过随机移位在空间维度上掩蔽图像。 直观地,沿空间维度的随机掩蔽强制鉴别器学习所有图像位置,而不是仅仅关注易于区分的位置。
- 第二种是平衡谱掩蔽,将图像分解为谱空间中的多个波段,并以自适应概率掩蔽部分谱带。 沿谱维度的随机掩蔽鼓励鉴别器学习难以区分的波段(例如,捕捉形状和结构的高频波段),而不是主要学习简单波段(例如,捕捉颜色和亮度的低波段)。
这两种掩蔽策略相辅相成,通过鼓励更具挑战性的整体鉴别器从有限的训练数据中学习,共同抑制了琐碎的解决方案和训练失败。
MaskedGAN 也将这两种掩蔽策略应用于生成器训练。 不同的是,在生成器端,两个图像掩蔽操作通过稀疏化从鉴别器反向传播的训练信号来作用于输出。 这种设计通过保持判别器和生成器的相似学习速度来减慢生成器学习并稳定整体对抗性学习。 它确保 MaskedGAN 在特定条件下可以收敛到局部纳什均衡。
2. 相关工作
使用有限数据训练 GAN:最近,为了减轻对大量训练数据的需求,使用有限数据训练有效 GAN 的任务越来越受到关注。 大多数现有的努力都从两个角度解决了这一具有挑战性的任务。 第一个是数据增强,它通过大量人工的数据增强策略起作用,例如,采用不同类型的可鉴别增强(DA)来稳定 GAN 训练。 第二种是模型正则化,它通过标签翻转、网络协同训练、彩票假设等对鉴别器训练进行正则化来稳定 GAN 训练。
Masked Autoencoders (MAE) 最近极大地推进了无监督表示学习的研究。 尽管设计不同,但 MAE 本质上是一种去噪自动编码器 (denoising autoencoder,DAE),它通过破坏和重建输入信号来学习语义表示。 大多数现有工作可以被视为不同类型破坏下的广义 DAE,例如掩蔽图像像素、 patch 和区域,或掩蔽图像颜色通道。 例如,上下文编码器屏蔽不同形状的随机图像区域并学习重建它们。 颜色编码器屏蔽图像颜色通道并学习从灰度图像重建它们。 最近,MAE 训练屏蔽了随机图像块。 特别是,He 等人证明,各种图像掩蔽策略可以帮助抑制 MAE 训练中的琐碎解决方案,而更多的掩蔽有助于学习更好的表示。
3. 方法
3.1 任务定义
这项工作的重点是用有限的训练数据训练 GAN。 GAN 是一个无监督框架,旨在生成模拟给定目标分布的模型分布:生成器 G 学习在给定隐编 z 的情况下生成图像 G(z),而鉴别器 D 学习区分生成的图像 G(z) 和 真实图像 x。 通常,GAN 使用鉴别器损失 L_d 和生成器损失 L_g 交替优化,可定义为:
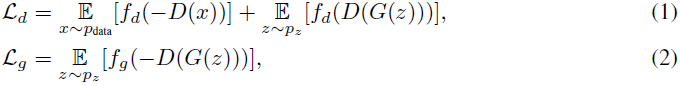
其中 p_data 表示提供的真实图像的分布,p_z 是先验分布(例如,高斯分布)。 符号 f_d 和 f_g 代表损失映射函数。
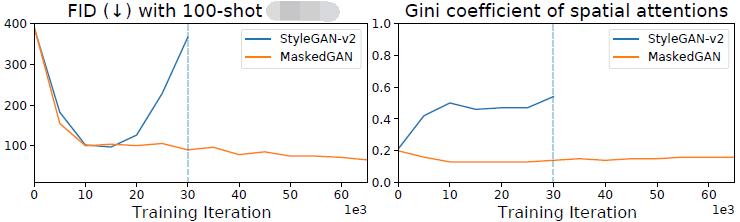
数据有限的 GAN 训练失败。 先前的研究表明,当只有有限的训练数据可用时,GAN 经常会出现生成失败,生成性能严重下降。 具体来说,在训练数据有限的情况下,鉴别器倾向于通过无意义的捷径进行鉴别,仅关注易于鉴别的图像位置和谱,而不是对图像的整体理解。 这可以在附录的图 1 中清楚地看到,其中鉴别器空间注意力的基尼系数在训练迭代过程中迅速增加(当只有有限的训练数据可用时)。请注意,基尼系数与平等性呈负相关,即当基尼系数从“0”增加到“1”时,鉴别器将更加不均匀地分配注意力到每个空间位置。 对于 GAN 的图像生成,大的基尼系数意味着鉴别器开始关注某些空间位置(容易鉴别)而忽略其他空间位置(难以鉴别),最终导致鉴别器过于自信和训练崩溃。
3.2 掩蔽的生成对抗网络
我们从图像掩蔽训练的角度解决了用有限数据训练 GAN 的挑战性任务。
偏移的空间掩蔽。在空间维度上屏蔽随机图像块,旨在迫使鉴别器学习所有图像位置,而不是仅仅关注易于区分的位置。 它首先生成一个随机的基于 patch 的掩蔽,然后对生成的掩蔽引入随机偏移,最后将偏移后的掩蔽应用于训练图像。 偏移操作允许沿着空间维度连续进行空间掩蔽:掩蔽的 patch 可以出现在任何可能的位置而不是固定的网格位置。 此功能对于需要沿空间维度生成的高保真度图像至关重要。
给定图像 x ∈ R^(H×W),首先生成一个随机的基于 patch 的空间掩蔽 m_spatial ∈ {0,1}^(H×W) 并在 m_spatial 上应用随机空间偏移 d ∈ [0,D] 以获得偏移后的空间掩蔽 m'_spatial。 移位空间掩蔽函数可以定义为:M_spatial(x) = x · m'_spatial。 在基于 patch 的掩蔽生成中,我们将网格大小设置为 N × N,即 patch 大小为 (H/N) × (W/N) 。 我们将随机移动范围 D 设置为 patch 大小的一半,这允许掩蔽的 patch 出现在任何可能的位置。 对于具有多个颜色通道的图像,每个通道都以相同的方式被掩蔽。
与 MAE 中空间掩蔽的关系。MAE 旨在将图像块编码为特征向量,这是一个下采样过程,不需要空间维度的高精度(即,块内的像素被认为是相同的)。 相反,GAN 的目标是将隐编码解码为高分辨率图像,这是一个上采样过程,需要空间维度的高保真度(即,patch 中的像素不应完全相同)。 因此,我们引入了一个额外的 “mask shift” 来允许被掩蔽的 patch 出现在任何图像位置(而不是像 MAE中的空间屏蔽那样只出现固定的网格位置),这有助于生成具有高保真度的图像空间维度。
平衡谱掩蔽在分解的谱空间中屏蔽图像的随机谱带,旨在鼓励鉴别器从所有谱带中学习,而不是只关注简单的波段(例如,低频段捕获颜色和亮度)。 具体来说,平衡谱掩蔽将图像分解为谱空间中的多个波段,并以自适应概率掩蔽一部分谱带,即如果一个谱带包含更多(或更少)的内容,则以更高(或更低)的概率被掩蔽。 平衡掩蔽对于谱掩蔽至关重要,因为图像内容通常沿谱维度分布不均匀。 具体来说,自然图像的内容在低频段周围分布非常密集,但在高频段非常稀疏。 因此,谱维度的均匀掩蔽是不平衡的并且不能很好地用于图像生成。
给定图像 x ∈ R^(H×W),我们首先使用傅立叶变换将其分解为多波段 representation
![]()
其中 C 表示谱带的数量。 然后可以通过对每个波段中的所有内容求和来计算每个波段中的图像内容 I_x ∈ R^C,即
![]()
然后进行归一化操作
![]()
利用计算出的 I′_x ,平衡谱掩模 m_spectral ∈ {0, 1}^C 可以通过掩蔽第 c 个波段来生成,掩蔽概率为
![]()
最后,平衡谱掩蔽函数可以定义为
![]()
损失函数。 我们将两种图像掩蔽策略应用于鉴别器和生成器训练,其中整体训练损失可以表示如下:
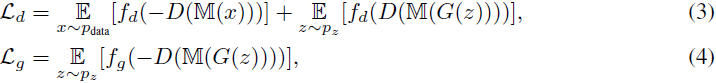
其中 M(·) = M_spectral ( M_spatial(·)) 是偏移空间掩蔽和平衡谱掩蔽的组合。
注意,这两种掩蔽策略在鉴别器和生成器训练中以不同的方式工作。 具体来说,通过在鉴别器训练中对输入图像应用图像掩蔽,我们可以创建一个具有挑战性的鉴别器任务,该任务迫使鉴别器学习更全面的信息,而不是仅学习易于区分的信息。 不同的是,在生成器训练中,图像掩蔽操作通过对从鉴别器反向传播的训练信号进行稀疏化而在输出端起作用。 一个主要的考虑是放慢生成器训练,使其具有与鉴别器相似的学习速度,从而进一步稳定鉴别器和生成器之间的整体对抗性学习。
3.3 理论见解
掩蔽生成对抗网络 (MaskedGAN) 与随机近似理论有着内在的联系。
命题 1:MaskedGAN 可以建模为两个时间尺度更新规则的一个实例。
命题 2:MaskedGAN 在一定条件下收敛于局部纳什均衡。
附录中提供了命题 1 和命题 2 的证明。
4. 实验
4.1 在 CIFAR-10、CIFAR-100 和 ImageNet 上使用 BigGAN 条件生成图像
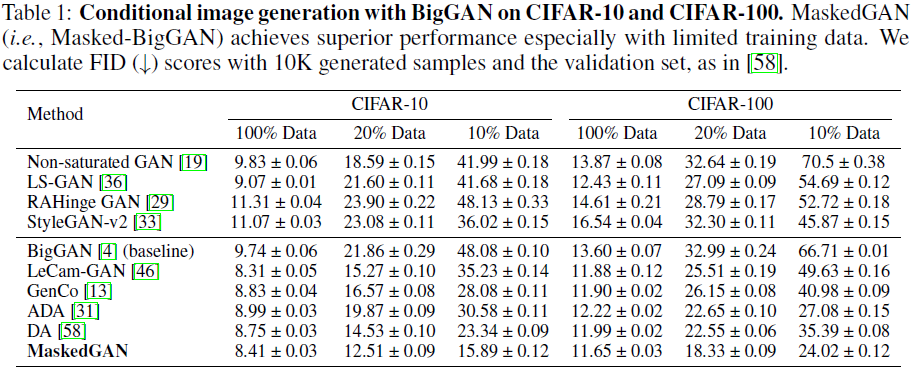
CIFAR-10 和 CIFAR-100。 表 1 报告了在 CIFAR-10 和 CIFAR-100 上使用基线 BigGAN 的类别条件图像生成结果。 所有模型都使用 100%、20% 或 10% 的训练数据(即 50K、10K 或 5K 图像)进行训练,并在验证集(10K 图像)上进行评估。 它表明,与最先进的方法相比,MaskedGAN(即 Masked-BigGAN)实现了优于 CIFAR-10 和 CIFAR-100 的性能。 结果取三次运行的平均值。

CIFAR-10 的消融研究。 我们使用广泛采用的 BigGAN 在 10% CIFAR-10 数据上进行消融研究,如表 2 所示。作为 MaskedGAN 的核心,我们检查了我们设计的偏移空间掩蔽和平衡谱掩蔽如何对数据有限图像生成的整体性能做出贡献 。 如表 2 所示,第一行中的基线 (BigGAN) 在训练数据有限的情况下表现不佳。 如第 2 行所示,在 GAN 训练中包括基本的空间掩蔽可以明显改善基线,而在空间掩蔽之上进一步引入随机移位可以明显改善 FID,如第 3 行所示。 另一方面,基本的谱掩蔽(以相同的概率掩蔽谱带)效果不佳,如第 4 行所示,因为图像内容通常沿谱维度分布不均匀。 然而,平衡谱掩蔽(包括第 5 行所示的建议的自适应概率)明显改善了 FID 中的图像生成(高于基线 19.30),表明平衡掩蔽策略对于有效的谱掩蔽至关重要。 此外,这两种图像掩蔽策略在正交维度(即空间和光谱维度)上工作,它们在数据受限的图像生成中相互补充。 我们可以清楚地观察到,结合这两种掩蔽策略(最后一行的 MaskedGAN)表现最好。
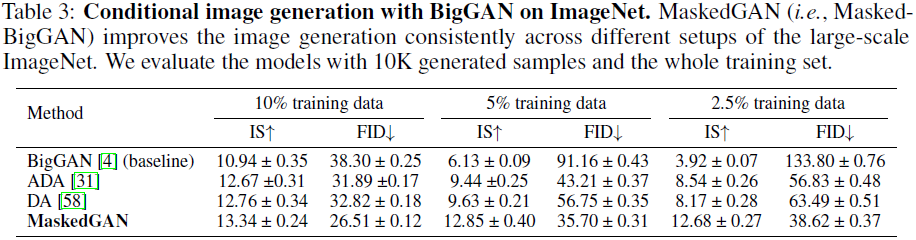
ImageNet。 表 3 报告了 BigGAN 在 ImageNet 上以 64×64 分辨率的类别条件生成结果。 这些模型使用不同数量的训练数据进行训练,包括约 10%(10 万张图像)、约 5%(5 万张图像)和约 2.5%(2.5 万张图像),并在整个训练集(约 120 万张图像)上进行评估。 实验表明,MaskedGAN 在非常多样化和大规模的 ImageNet 上有效地处理不同的数据设置。 结果取三次运行的平均值。
4.2 使用 StyleGAN-v2 在 100-shot、AFHQ 和 FFHQ 上进行无条件图像生成
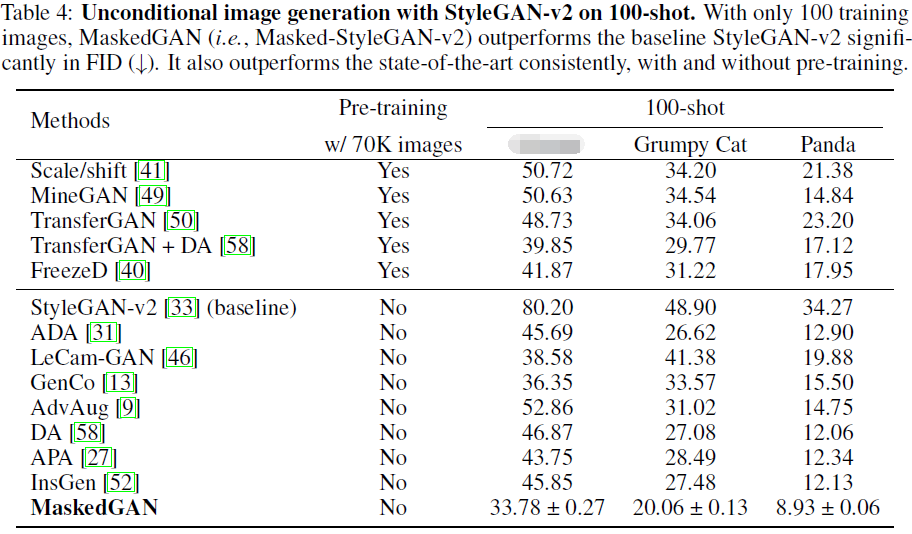
100-shot。 表 4 报告了在 100 个样本的数据集上使用 StyleGAN-v2 的无条件图像生成结果。 所有模型分别经过 100 多张人脸、Grumpy Cat 和 Panda 图像的训练和评估。 实验结果表明,所提出的 MaskedGAN 对仅有 100 张图像有效,即它比 StyleGAN-v2(基线)带来了显着的收益,并且明显优于最先进的方法。 此外,MaskedGAN 优于所有迁移学习方法,但不需要对大规模数据集进行预训练。 结果取三次运行的平均值。
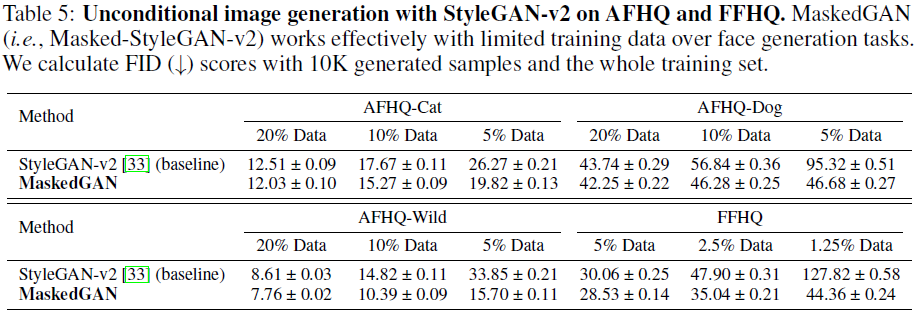
AFHQ 和 FFHQ。 表 5 显示了在 AFHQ 和 FFHQ 上使用 StyleGAN-v2 的无条件图像生成结果。 对于 AFHQ,模型使用不同数量的训练数据进行训练,包括 ~20%(1000 张图像)、~10%(500 张图像)和~5%(250 张图像),并在整个训练集(5000 张图像)上进行评估。 对于 FFHQ,模型使用 ~10%(7K 图像)、~5%(3.5K 图像)和~2.5%(1.75K 图像)数据进行训练,并在整个训练集(70K 图像)上进行评估。 可以观察到,MaskedGAN 在动物和人脸生成任务的有限训练数据下有效地工作。 结果取三次运行的平均值。
4.3 使用 TransGAN 和 GANformer 进行无条件图像生成
我们使用最近的基于 transformer 的架构(包括 TransGAN 和 GANformer)评估 MaskedGAN。 具体来说,TransGAN 是第一个纯粹使用 transformer 进行图像生成的作品。 GANformer 采用二分结构来计算软注意力,从而规避了标准转换器中的计算限制并改进了图像生成。
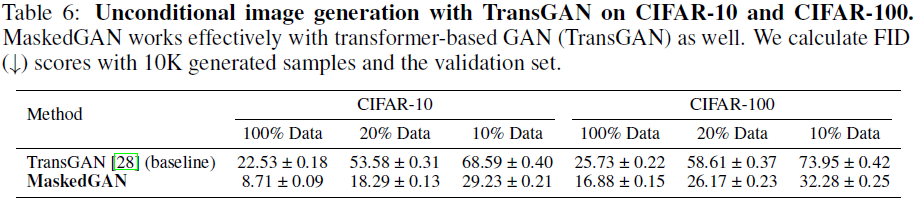
CIFAR-10 和 CIFAR-100 与 TransGAN。 表 6 报告了在 CIFAR-10 和 CIFAR-100 上使用 TransGAN 的无条件图像生成。 这些模型使用 100%、20% 或 10% 的训练数据(即 50K、10K 或 5K 图像)进行训练,并在整个训练集(50K 图像)上进行评估。 我们可以观察到我们的图像屏蔽策略也可以有效地与基于 transformer 的 GAN 一起使用。 三个运行获得结果。

在 Cityscapes 上使用 GANformer。 表 7 报告了在 Cityscapes 上使用 GANformer 的无条件图像生成。 这些模型使用约 5%、约 2.5% 或约 1.25% 的训练数据(即 1.25K、0.63K 或 0.31K 图像)进行训练,并在整个训练集(即约 25K 图像)上进行评估。 实验表明,我们的图像屏蔽策略在场景生成任务中始终比基线 GANformer 带来显着收益。 三个运行获得结果。
4.4 讨论
跨不同 GAN 架构的泛化:我们通过使用四种具有代表性的 GAN 架构对其进行评估来检查所提出的 MaskedGAN 的泛化,包括两种基于 CNN 的架构(即 BigGAN 和 StyleGAN-v2)和两种基于 Transformer 的架构(即 TransGAN 和 GANformer)。 表 1-7 中的实验结果表明,我们的 MaskedGAN 在不同的 GAN 架构上一致地带来了明显的生成改进。
跨不同生成任务的泛化:我们从图像生成任务的角度研究了所提出的 MaskedGAN 的泛化。 具体来说,我们对使用 CIFAR-10、CIFAR-100 和 ImageNet 的对象生成任务、使用 100-shot AFHQ 和 FFHQ 的人脸生成任务以及使用 Cityscapes 的场景生成任务进行了广泛的评估。 表 1-7 中的实验结果表明,所提出的 MaskedGAN 在不同的生成任务中始终如一地实现了卓越的生成。
不同数量训练样本的泛化:我们从训练样本数量的角度研究了所提出的 MaskedGAN 的泛化。 具体来说,我们在 CIFAR-10 和 CIFAR-100 上用 100%、20% 和 10% 的数据对 MaskedGAN 进行基准测试,在 ImageNet 上用 10%、5% 和 2.5% 的数据,在 AFHQ 上用 20%、10% 和 5% 的数据,FFHQ 和 Cityscapes 上使用 5%、2.5% 和 1.25% 的数据,以及只有 100 张图像的 100-shot 数据集。 表 1-7 中的实验表明,MaskedGAN 在不同数量的训练数据下始终如一地实现了卓越的性能。
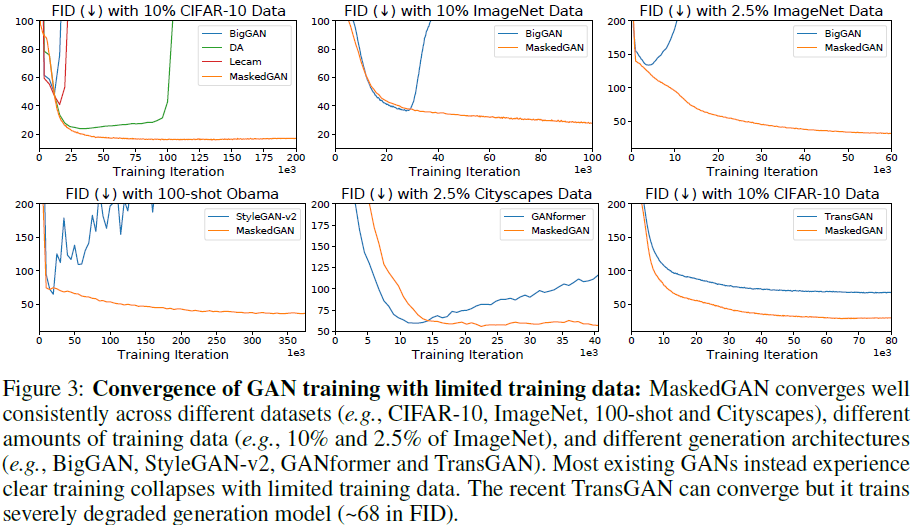
不同网络架构和数据集之间的收敛性比较:我们通过在各种网络架构(例如,基于 CNN 的 BigGAN 和 StyleGAN-v2 以及基于 Transformers 的 TransGAN 和 GANformer)和数据集(例如, CIFAR-10、ImageNet、100-shot 和 Cityscapes)。 图 3 提供了 FID 与训练迭代的折线图。 它清楚地表明,当只有有限的训练数据可用时,大多数最先进的 GAN 都会经历生成失败(或称为训练崩溃),生成性能严重下降。 此外,先前对数据受限生成的研究(例如,数据增强方法和模型正则化方法)可以在一定程度上提高性能,但仍然会遇到生成失败和训练崩溃的问题。 作为比较,MaskedGAN 在不同数量的训练数据、网络架构和数据集上收敛得很好。 MaskedGAN 良好的收敛性主要归功于两个因素:其图像掩蔽设计直接抑制了琐碎的解决方案和训练失败; 它使判别器和生成器保持相似的学习速度,确保网络在特定条件下收敛到局部纳什均衡。


我们在图 4 和图 5 中提供了定性说明,这表明 MaskedGAN 明显优于基线和最先进的模型。 具体来说,在训练数据有限的情况下,将所提出的图像掩蔽策略引入 GAN 训练有助于生成更逼真和高保真度的图像,尤其是在图像形状和结构方面。 由于篇幅限制,我们在附录中提供了额外的讨论和定性说明(包括与最新技术的比较)。
5. 结论
本文介绍了 MaskedGAN,这是一种强大的图像生成网络,可以在有限的训练数据下有效地学习。 MaskedGAN 引入了两种沿着训练图像的正交维度工作的图像掩蔽策略,即移位空间掩蔽和平衡光谱掩蔽。 这两种掩蔽策略相互补充,共同鼓励从有限的训练数据中进行更具挑战性的整体学习,最终抑制 GAN 训练中的琐碎解决方案和失败。 广泛的实验表明,MaskedGAN 在不同的网络架构(例如,包括 BigGAN 和 StyleGAN-v2 的 CNN 以及包括 TransGAN 和 GANformer 的 Transformer)和数据集(例如,CIFAR-10、CIFAR-100、ImageNet、100-shot、AFHQ)中始终如一地实现了卓越的性能 、FFHQ 和 Cityscapes)。 展望未来,我们将探索其他生成任务(例如多模态生成)中的数据屏蔽训练。
参考
Huang J, Cui K, Guan D, et al. Masked generative adversarial networks are data-efficient generation learners[J]. Advances in Neural Information Processing Systems, 2022, 35: 2154-2167.
附录
G. 与 MAE 中使用的掩蔽策略的比较
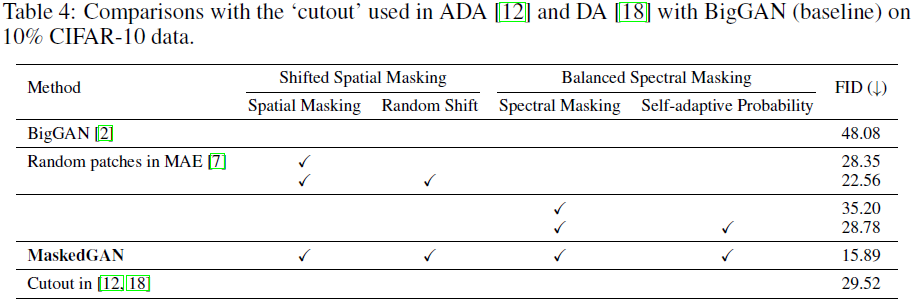
在本节中,我们将 MaskedGAN 与 Masked Autoencoders (MAE) 中使用的掩码策略进行比较。 表 4 报告了 BigGAN(基线)在 10% CIFAR-10 数据上的结果。 它表明直接在 GAN 上应用 MAE 掩蔽策略(表 4 中的“空间掩蔽”)可以在一定程度上提高性能(即,在 FID 中达到大约28)但不能达到最先进的性能。 主要原因是这些方法是为无监督 representation 学习而设计的,没有考虑生成或重建高保真图像。 作为比较,我们的 MaskedGAN(表 4 中倒数第二行)通过所提出的掩蔽策略明显产生了更好的性能(即,在 FID 中达到 ~15.8)并定义了用有限数据训练 GAN 的最新技术水平 . 这主要是因为 MaskedGAN 为 GAN 量身定制了几种掩蔽策略,例如用于空间掩蔽的“掩蔽移位”和“平衡谱掩蔽”,这对于高保真图像生成至关重要。
H. 与 ADA 和 DA 中使用的“剪切 (cutout)” 的比较
我们注意到 ADA 和 DA 将视觉识别中的海量数据增强技术引入到 GAN 训练中,例如颜色变换、添加噪声、剪切(cutout)等。在这些数据增强中,“剪切”操作看起来类似于 MAE 和我们的 MaskedGAN 中使用的基本空间掩蔽。 在本节中,我们进行实验来研究基本空间掩蔽(用于 MAE 和我们的 MaskedGAN)和“cutout”之间的关系。
表 4 报告了 BigGAN(基线)在 10% CIFAR-10 训练数据上的结果。它表明,与基本空间掩蔽(在 MAE 和我们的 MaskedGAN 中使用)相比,“剪切”操作产生了相似但稍低的性能,表明对于图像生成,基本空间掩蔽(即“随机 patch”)比“剪切”更合适。
主要原因是基本空间掩蔽(即在 MAE 和我们的 MaskedGAN 中使用的“随机补丁”)以统一的概率和固定的整体掩蔽率掩蔽每个图像位置/像素,最终导致无偏图像掩蔽和稳定的训练过程。 作为比较,“cutout”操作不能同时实现上述两个属性。
- 首先,如果我们在没有 padding 的情况下进行“剪切”,它会以较高的概率掩蔽中心位置/像素,同时以较低的概率掩蔽边缘位置/像素,从而导致图像掩蔽偏差和图像生成质量下降。
- 其次,如果我们用 padding 进行 'cutout',它可以以相同的概率屏蔽每个位置,但是它的屏蔽比率不固定且不稳定,即,当 cutout mask 从中心位置移动到角落位置时,整体屏蔽比率从 p_mask(剪切大小与整个图像之间的比率)下降到 0,这可能会使整体训练不稳定并导致性能下降。
尽管如此,表 4 中的结果表明,使用纯空间掩蔽只能在一定程度上提高性能,但不能达到最先进的性能。 在 MaskedGAN 中,进一步包括提议的“随机掩蔽移位”和“平衡谱掩码”可以明显提高性能,并定义了用有限数据训练 GAN 的最新技术水平。
此外,表 4 中的结果还表明,MaskedGAN 在不使用颜色变换和噪声添加等大量数据增强(如 ADA 和 DA 中)的情况下实现了最先进的性能。 它揭示了用有限数据训练 GAN 的关键点是防止琐碎的解决方案,例如,鼓励网络学习有用的和整体的知识,这可以通过简单的掩蔽策略来实现。 这些结果与 [7] 中的结论一致,后者表明图像掩蔽使任务变得困难,因此需要较少的增强来正则化训练。
[7] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. arXiv preprint arXiv:2111.06377, 2021.
I. 与其他所谓的 MaskedGAN 的关系
我们注意到有两个作品也被命名为“MaskedGAN”[17、13]。
- [17] 用于无监督单目深度和自我运动估计,它使用生成器产生一个“布尔掩码”来对目标图像执行相同的合成图像遮挡,旨在消除在无监督单目深度自我运动估计上遮挡的影响。
- [13] 用于面部编辑,它使用语义掩码(由 DeepLabV3 生成)来选择要编辑的区域。
- 显然,这两个作品与本文有细微的不同,例如,在主题/任务的角度和“面具”的概念上。
[17] Chaoqiang Zhao, Gary G Yen, Qiyu Sun, Chongzhen Zhang, and Yang Tang. Masked gan for unsupervised depth and pose prediction with scale consistency. IEEE Transactions on Neural Networks and Learning Systems, 32(12):5392–5403, 2020.
[13] Martin Pernuš, Vitomir Štruc, and Simon Dobrišek. High resolution face editing with masked gan latent code optimization. arXiv preprint arXiv:2103.11135, 2021.
此外,我们还注意到有一项非常新的工作,名为“Maskgit:Masked generative image transformer”[3]。 [3] 基于 VQVAE [15],它分两个阶段使用预训练的码本生成图像:
- 它使用预训练的模型(例如 VQVAE [15] 和 DALL-E [14])将图像编码成“视觉 words”;
- 它训练一个自回归模型(例如,transformer)以根据先前生成的图像标记(或“视觉 words”)顺序生成图像标记(即自回归解码)。
[3] 提出了一种名为 MaskGIT 的双向变换器解码器,它通过关注各个方向的标记来学习预测随机屏蔽的标记,这可以通过根据先前生成的结果迭代地改进图像来改进第二阶段。 显然,[3] 与本文完全不同,我们专注于使用有限数据训练 GAN,而 [3] 专注于改进基于 VQVAE 的生成模型的第二阶段,而不考虑 GAN 或数据受限机制。 该声明与 [3] 中的声明一致,即“与 GAN 中使用的微妙的最小-最大优化不同,基于 VQVAE 的生成模型是通过最大似然估计来学习的”。
[3] Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. arXiv preprint arXiv:2202.04200, 2022.
[15] Ali Razavi, Aaron Van den Oord, and Oriol Vinyals. Generating diverse high-fidelity images with vq-vae-2. Advances in neural information processing systems, 32, 2019.
[14] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. In International Conference on Machine Learning, pages 8821–8831. PMLR, 2021.
S. 总结
S.1 核心思想
为了在训练数据有限时,稳健的进行图像生成学习器,本文提出了掩蔽的生成对抗网络 (MaskedGAN) 。 MaskedGAN 的思想很简单:随机屏蔽掉某些图像信息。
作者开发了两种沿掩蔽策略:
- 移位空间掩蔽,它在空间维度上用随机移位掩蔽图像。
- 平衡谱掩蔽,它用自适应概率掩蔽某些图像谱带。
- 这两种方法是正交的(空间维度和谱维度),可以同时用于提升模型性能。
其中 M(·) = M_spectral ( M_spatial(·)) 是偏移空间掩蔽和平衡谱掩蔽的组合。
S.2 流程
空间移位掩蔽:它通过随机移位在空间维度上掩蔽图像。 直观地,沿空间维度的随机掩蔽强制鉴别器学习所有图像位置,而不是仅仅关注易于区分的位置。
相比于不需要高精度空间维度的 MAE(把图像块编码为特征向量,块内像素被认为是相同的,mask 只出现在图像的固定位置),GAN 需要高保真的重建图像,因此需要随机移位来学习所有图像位置。
平衡谱掩蔽:将图像分解为谱空间中的多个波段,并以自适应概率掩蔽部分谱带。 沿谱维度的随机掩蔽鼓励鉴别器学习难以区分的波段(例如,捕捉形状和结构的高频波段),而不是主要学习简单波段(例如,捕捉颜色和亮度的低波段)。
图像内容通常沿谱维度分布不均匀:在低频段周围分布非常密集,但在高频段非常稀疏。因此,谱维度的均匀掩蔽是不平衡的并且不能很好地用于图像生成。所以需要自适应掩蔽策略。平衡谱掩蔽将图像分解为谱空间中的多个波段,并以自适应概率掩蔽一部分谱带,即如果一个谱带包含更多(或更少)的内容,则以更高(或更低)的概率被掩蔽。
先使用傅立叶变换把图像分解为多波段 representation,每个波段内容在所有波段内容之和中的占比就是该波段内容被掩蔽的概率。
S.3 分析
应用于生成器和鉴别器。
应用随机空间和谱掩蔽迫使鉴别器学习更全面的信息,而不是仅关注易于区分的图像位置和谱。
这两种掩蔽策略用于生成器。 不同的是,在生成器端,两个操作通过稀疏化从鉴别器反向传播的训练信号来作用于输出。 这种设计通过保持判别器和生成器的相似学习速度来减慢生成器学习并稳定整体对抗性学习。 它确保 MaskedGAN 在特定条件下可以收敛到局部纳什均衡。
与 ADA 和 DA 中的 cutout 的区别。掩蔽也可以被看作是一种数据增强方式。与 cutout 的区别在于
- 首先,如果在没有 padding 的情况下进行 “cutout ”,它会以较高的概率掩蔽中心位置/像素,同时以较低的概率掩蔽边缘位置/像素,从而导致图像掩蔽偏差和图像生成质量下降。
- 其次,如果用 padding 进行 “cutout ”,它可以以相同的概率屏蔽每个位置,但是它的屏蔽比率不固定且不稳定,即,当 cutout mask 从中心位置移动到角落位置时,整体屏蔽比率从 p_mask(cutout 大小与整个图像之间的比率)下降到 0,这可能会使整体训练不稳定并导致性能下降。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结