您现在的位置是:首页 >技术杂谈 >3. 自然语言处理NLP:具体用途(近义词类比词;情感分类;机器翻译)网站首页技术杂谈
3. 自然语言处理NLP:具体用途(近义词类比词;情感分类;机器翻译)
1. 近义词
方法一:在嵌入模型后,可以根据两个词向量的余弦相似度表示词与词之间在语义上的相似度。
方法二:KNN(K近邻)
2. 类比词
使用预训练词向量求词与词之间的类比关系。eg:man:woman; son:daughter
对于类比关系中的4个词,a:b :: c:d, 给定前三个词a、b、c,求第四个词d (vec(c) +vec(b) - vec(a) )
二、文本情感分类:使用循环神经网络
使用文本情感分类来分析作者的情绪
- 分类数据集,特到特征向量
”1“表示“正面”,“0”表示“负面”。
- 使用双向循环神经网络对特征进一步编码
- 将编码通过全连接层变为输出
三、文本情感分类:使用卷积层(textCNN)
可以将文本当成一维图像,从而可以用一维卷积神经网络来捕捉临近词之间的关联。
- 定义多个一维卷积核,并使用这些卷积核对输入分别做卷积计算,宽度不同的卷积核可能会捕捉到不同个数的相邻词的相关性。
- 对输出的所有通道分别做时序最大池化,再将这些通道的池化输出值连接为向量。
- 通过全连接层将连接后的向量变换为有关各类别的输出,这一步可以使用丢弃层应对过拟合。
相关模型:
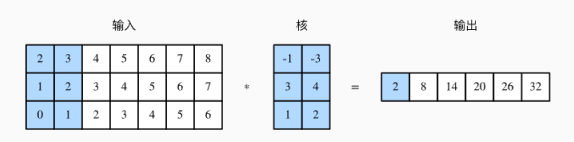
1. 一维卷积层:从输入数组的最左方开始,按从左到右的顺序,依次在输入数组上滑动。当滑动到某一位置时,窗口中输入子数组与核数组按元素相乘并求和,得到输出数组中相应位置的元素。0×1+1×2=2

2. 多输入通道的一维互相关运算
2×(−1)+3×(−3)+1×3+2×4+0×1+1×2=2。
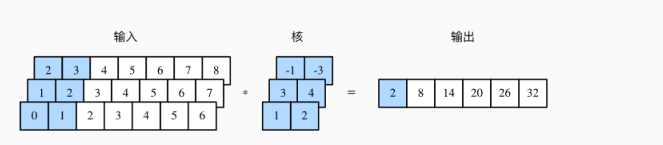
单输入通道的二维互相关运算
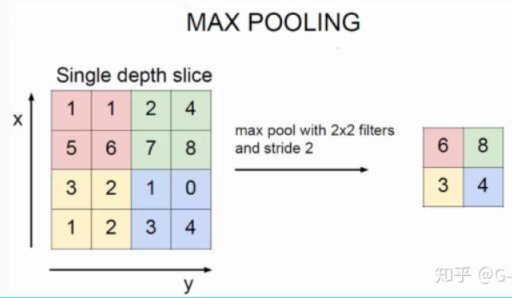
3. 时序最大池化层
池化(pooling)的本质是采样,选择某种方式进行压缩降维,以加快运算。
最大池化:求每个通道所有时间步中最大的数值。
时序最大池化层的输入在各个通道上的时间步数可以不同,主要目的是抓取时序中最重要的特征,通常能使模型不受人为添加字符的影响。
四、机器翻译(编码器与解码器(seq2seq);搜索;注意力机制)
1. 编码器与解码器(transformer;seq2seq)
输入和输出都可以是不定长序列,这时需要用到编码器-解码器(encoder-decoder)
编码器:把一个不定长的输入序列变换成一个定长的背景变量c。
解码器:将中间变量输出成条件概率。(输入为上一步的输出,以及背景变量c,并将它们与上一时间步的隐藏状态St-1变换为当前时间步的隐藏状态St)
最后最大化输出序列的条件概率,对输出序列损失的均值使用最小化损失函数.
2. 搜索
使用编码器-解码器预测不定长的序列。
贪婪搜索:对于输出序列的每个时间步,从|y|个词中搜索出条件概率最大的词,核心思想是每次都选择局部最优解,但该算法并不能保证最后得出的结果是全局最优解。
穷举搜索:穷举所有的输出序列,输出条件概率最大的序列,但是计算开销很容易过大。
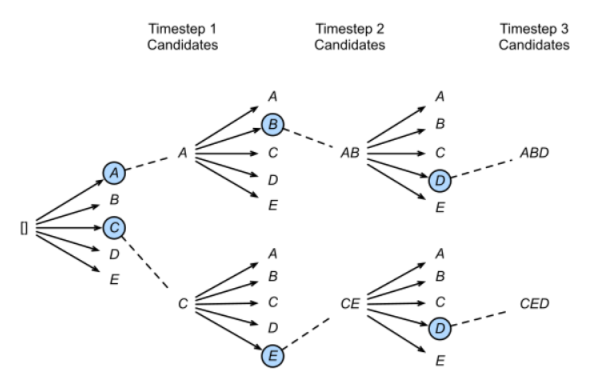
束搜索:通过灵活的束宽来衡量计算开销和搜索质量。
在每一个时间步,不再只保留当前分数最高的1个输出,而是保留num_beams个。当num_beams=1时集束搜索就退化成了贪心搜索。
下图是一个实际的例子,每个时间步有ABCDE共5种可能的输出,即,图中的num_beams=2,也就是说每个时间步都会保留到当前步为止条件概率最优的2个序列。
3. 注意力机制
用来自动学习和计算输入数据对输出数据的贡献大小。
解码器通过在各个时间步依赖的相同的背景变量来获取输入序列信息,当编码器为循环神经网络时,背景变量来自它最终时间步的隐藏状态。
注意力机制在于,解码器在每个时间步对输入的不同信息(背景变量)分配不同的注意力。解码器在每一时间步调整这些权重,即注意力权重。
关键的两点在于,如何计算背景变量c,以及如何用它来更新隐藏状态s。
引用:动手学机器学习 李沐





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结